 电子发烧友App
电子发烧友App


AI加速的尴尬现状,不知你是否有感受?
独占式方案,非虚拟化使用,成本高昂。缺少异构加速管理和调度,方案难度大,供应商还容易被锁定。
对于AI开发者而言,虚拟化使用加速器计算资源,现有调度和管理软件,并不亲民。
所以现在,几位虚拟化计算领域的专家,初步打造完成了一套解决方案并正式在GitHub推出,面向开发者,免费下载和使用。
这就是刚上线的OrionAI计算平台。
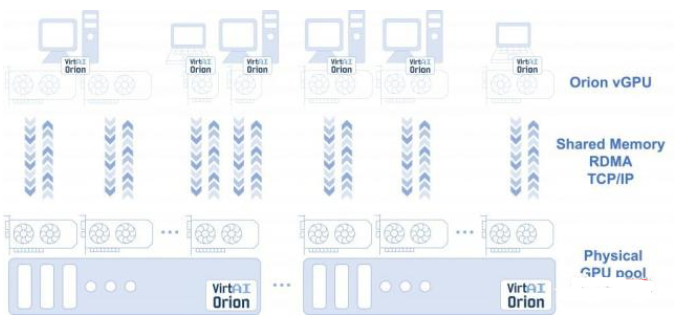
AI加速器虚拟化
整个OrionAI计算平台,包括AI加速器虚拟化软件,和异构加速器管理和调度软件等两大组件。
其中OrionAI加速器虚拟化软件,不仅支持用户使用和共享本地加速器资源,而且支持应用透明地使用远程加速器资源——无需修改代码。
从而打破资源调度的物理边界,构建更高效资源池。
异构加速器管理和调度软件,同样支持用户的应用无需修改代码,即可透明地运行在多种不同加速器之上。
最终,帮助用户更好利用多种不同加速器的优势,构建更高效的异构资源池。
刚上线的OrionAI计算平台社区版v1.0,支持英伟达GPU的虚拟化,供AI、互联网和公有云头部客户试用,开发者用户可免费下载和使用。
AI加速痛点
OrionAI计算平台因何出发?
方案打造者称,随着AI威廉希尔官方网站 的快速发展和普及,越来越多客户开始使用高性能的AI加速器,包括GPU, FPGA和AI ASIC芯片等。
同时,越来越多的客户需要高效的AI加速器虚拟化软件,来提高加速器资源的利用率,以及高效的异构加速器管理和调度软件,来更好地利用多种不同的加速器,提高性能,降低成本,避免供应商锁定。
但相应地面临开头提及的两大痛点。
首先,AI加速器价格偏高。
以知名的英伟达V100 GPU为例,价格在8万元人民币左右,高性能FPGA卡,价位也在5万元人民币。
其次,由于缺乏高效经济的AI加速器虚拟化解决方案,目前绝大部分企业,不得不独占式使用上述昂贵的加速器资源,导致资源利用率低,成本高。
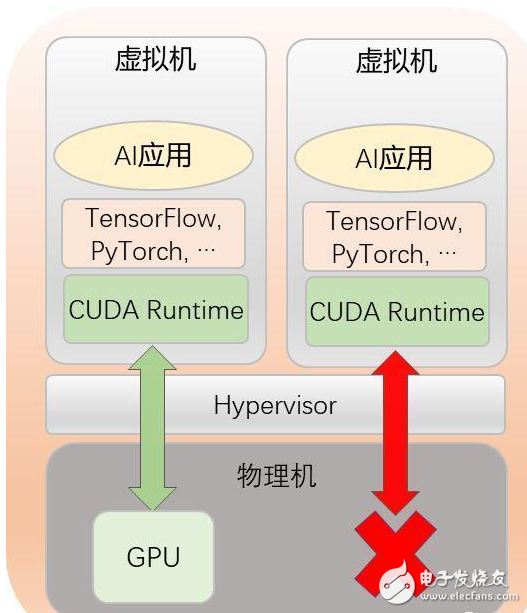
根据AWS在re:Invent 2018披露数据,AWS上GPU利用率只有10%~30%。
当物理机上只有一块GPU时,如果没有GPU虚拟化解决方案,用户就只能让一个虚拟机独占式地使用该GPU,导致该GPU无法被多个虚拟机共享。
于是几位加速虚拟化领域的老兵,决定试水,并最终推出了自己的方案:OrionAI计算平台v1.0。
方案详解
该平台支持用户通过多个虚拟机或者容器,来共享本地以及远程GPU资源。
使用OrionAI平台的典型场景有:
第一,多个虚拟机或容器共享本地的GPU。
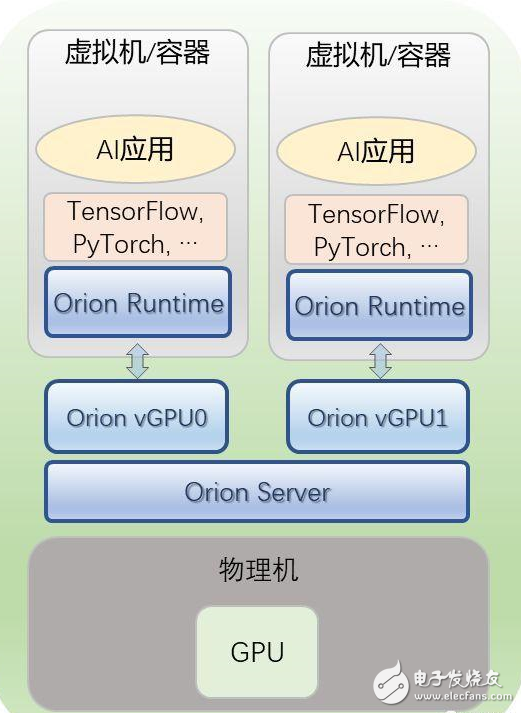
用户只需要将虚拟机或者容器中的CUDA运行环境(CUDA runtime),替换成Orion运行环境(Orion Runtime)即可。
而用户的AI应用和所使用的深度学习框架(TensorFlow,、PyTorch等)不需要任何改变,即可像在原生的CUDA运行环境下一样运行。
同时,用户需要在物理服务器上运行Orion服务(Orion Server),该服务会接管物理GPU,并且将物理GPU虚拟化成多个Orion vGPU。
用户在不同虚拟机上运行的AI应用会被分配到不同的Orion vGPU上。这样物理GPU的利用率就会得到显著提升。
第二,多个虚拟机或容器共享远程的GPU。
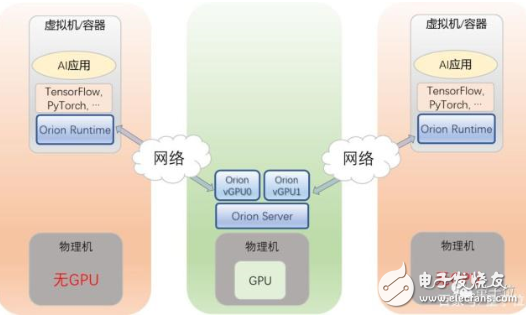
用户可以将虚拟机/容器,运行在没有GPU的服务器上,AI应用无需修改,就可以通过Orion Runtime来使用另外一台服务器上的Orion vGPU。
如此一来,用户的AI应用就可以被部署在数据中心中的任何一台服务器之上,用户的资源调配和管理,得到极大灵活性提升。
第三,单个虚拟机或容器,使用跨越多台物理服务器上的GPU。
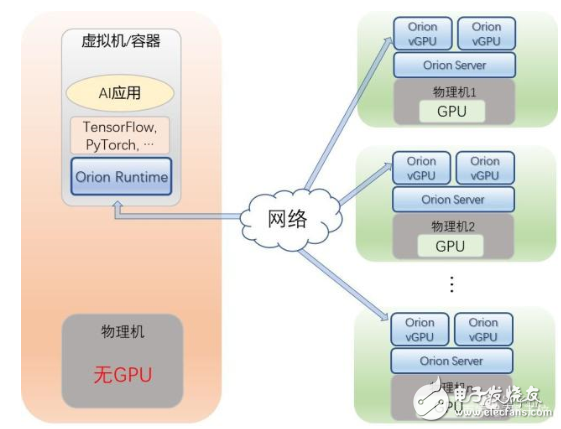
用户的虚拟机/容器通过Orion Runtime,无需修改AI应用和框架,就可以使用跨越多台物理机上的GPU资源。
目前现状是,AI应用可能需要64个GPU——甚至更多GPU来训练模型,但是今天还没有一台物理服务器能够完全满足。
通过Orion Runtime,应用无需修改就可以直接使用多台物理服务器上的GPU,如16台服务器,每台4块GPU。
如此一来,用户GPU资源,就能变成一个真正的数据中心级的资源池。
用户的AI应用可以透明地使用任何一台服务器上的GPU资源,资源利用率和管理调度灵活度,可以得到极大提升。
用户通过Orion AI Platform分配的GPU资源,无论是本地GPU资源,还是远程GPU资源,均软件定义、按需分配。
这些资源不同于通过硬件虚拟化威廉希尔官方网站 得到的资源,它们的分配和释放都能在瞬间完成,不需要重启虚拟机或者容器。
例如,当用户启动了一个虚拟机时,如果用户不需要运行AI应用,那么Orion AI Platform不会给这个虚拟机分配GPU资源。
当用户需要运行一个大型训练任务,例如需要16个Orion vGPU,那么Orion AI Platform会瞬间给该虚拟机分配16个Orion vGPU。
当用户完成训练后,又只需要1个Orion vGPU来做推理,那么Orion AI Platform又能瞬间释放15个Orion vGPU。
值得一提的是,所有上述的资源分配和释放都不需要虚拟机重启。
威廉希尔官方网站 细节和benchmark
上述方案背后,究竟是怎样的威廉希尔官方网站 细节?
实际上,Orion Runtime提供了和CUDA Runtime完全兼容的API接口,保证用户的应用无需修改即能运行。
Orion Runtime在得到用户所有对CUDA Runtime的调用之后,将这些调用发送给Orion Server。
Orion Server会将这些调用加载到物理GPU上去运行,然后再将结果返回给Orion Runtime。
OrionAI计算平台v1.0也公布了性能对比结果。
先看配置:
GPU服务器配置:双路Intel Xeon Gold 6132,128GB内存,单块nVidia Tesla P40。
性能测试集:TensorFlow v1.12, 官方benchmark,无代码修改,测试使用synthetic数据。
“Native GPU”为将性能测试运行在物理GPU之上,不使用虚拟机或者容器;
“Orion Local Container”为将性能测试运行在安装了Orion Runtime的容器之中,Orion Server运行在同一台物理机之上;
“Orion Local KVM”为将性能测试运行在安装了Orion Runtime的KVM虚拟机之中,Orion Server运行在同一台物理机之上;
“Orion Remote – 25G RDMA”为性能测试运行在一台没有GPU的物理机之上,Orion Server运行在有GPU的物理机之上,两台物理机通过25G RDMA网卡连接。
最终对比结果如下:
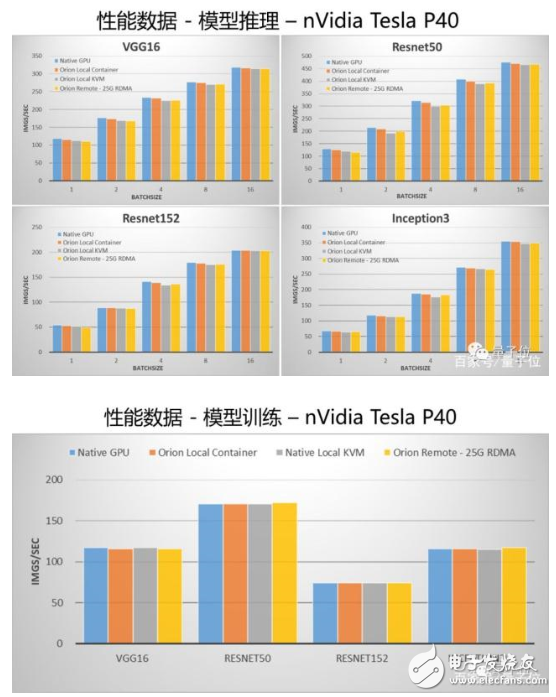
通过数据可以看出,和跑在物理GPU上相比,Orion Runtime和Orion Server引入的性能损失非常小。
尤其是在通过网络连接来使用远程的GPU的情况下,OrionAI计算平台通过大量的优化,使其性能与使用本机GPU相比差距非常小。
OrionAI计算平台打造方
最后,介绍下OrionAI计算平台背后的打造方:
趋动科技 VirtAI Tech。
2019年1月刚创立,主打AI加速器虚拟化软件,以及异构AI加速器管理和调度软件。
主要创始人有三位,皆为该领域的资深老兵。
王鲲,趋动科技CEO。博士毕业于中国科学威廉希尔官方网站 大学计算机系。
在创办趋动科技之前,王鲲博士供职于Dell EMC中国研究院,任研究院院长,负责管理和领导Dell EMC在大中华区的所有研究团队。
他长期从事计算机体系结构,GPU和FPGA虚拟化,分布式系统等领域的研究工作,在业界最早开始推动FPGA虚拟化相关研究,在该领域拥有十多年的工作经验和积累。
陈飞,趋动科技CTO。博士毕业于中国科学院计算威廉希尔官方网站 研究所。
在创立趋动科技之前,陈飞博士供职于Dell EMC,担任Dell EMC中国研究院首席科学家,长期从事高性能计算,计算机体系结构,GPU和FPGA虚拟化等领域的研究工作。
邹懋,趋动科技首席架构师。博士毕业于中国科学威廉希尔官方网站 大学。
在创立趋动科技之前,邹懋博士供职于Dell EMC,担任Dell EMC中国研究院高级研究员,长期从事计算机体系结构,GPU虚拟化等领域的研究工作。















 工商网监
工商网监
评论