 电子发烧友App
电子发烧友App


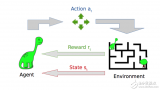
强化学习属于机器学习中的一个子集,它使代理能够理解在特定环境中执行特定操作的相应结果。目前,相当一部分机器人就在使用强化学习掌握种种新能力。
强化学习是一种行为学习模型,由算法提供数据分析反馈,引导用户逐步获取最佳结果。
不同于使用样本数据集训练机器模型的各类监督学习,强化学习尝试通过反复试验掌握个中诀窍。通过一系列正确的决策,模型本身将得到逐步强化,慢慢掌控解决问题的更佳方法。
强化学习与人类在婴幼儿时期的学习过程非常相似。我们每个人的成长都离不开这种学习强化——正是在一次又一次跌倒与父母的帮扶之下,我们才最终站立起来。
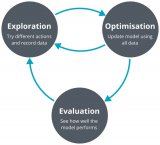
这是一种基于经验的学习流程,机器会不断尝试、不断犯错,最终找到正确的解决思路。
我们只需要为机器模型提供最基本的“游戏规则”,余下的就完全交给模型自主探索。模型将从随机尝试开始,一步步建立起自己的复杂战术,通过无数次尝试达成任务、获得奖励。
事实证明,强化学习已经成为培养机器人想象力的重要方法之一。不同于普通人类,人工智能将从成千上万轮游戏中积累知识,而强大的计算机基础设施则为这类模型提供可靠的算力支持。
YouTube上的视频就是强化学习的应用实例。在观看当前视频之后,该平台会向你展示它认为你可能感兴趣的类似内容。如果你点开了推荐视频但却没有看完,机器会认为此次推荐失败,并在下一次尝试其他推荐方法。
强化学习的挑战
强化学习面对的核心挑战,在于如何规模interwetten与威廉的赔率体系 环境。模拟环境在很大程度上由有待执行的任务所决定。我们以国际象棋、围棋或者雅达利游戏为例,这类模拟环境相对简单也易于构建。但是,要想用同样的方法训练出安全可靠的自动驾驶汽车,就必须创建出非常逼真的街道原型环境,引入突然闯出的行人或者可能导致碰撞事故的各类因素。如果仿真度不够,那么模型在从训练环境转移到现实场景之后,就会出现一系列问题。
另一个难题,在于如何扩展及修改代理的神经网络。除了奖励与处罚之外,我们再无其他方法与该网络建立联系。这有可能引发严重的“健忘”症状,即网络在获取新信息后,会将一部分可能非常重要的旧知识清除出去。换句话说,我们需要想办法管理学习模型的“记忆”。
最后,我们还得防止机器代理“作弊”。有时候,机器模型能够获得良好的结果,但实现方式却与我们的预期相去甚远。一部分代理甚至会在不完成实际任务的情况下,通过“浑水摸鱼”拿到最大奖励。
强化学习的应用领域
游戏
机器学习之所以具有极高的知名度,主要源自它在解决各类游戏问题时展现出的惊人实力。
最著名的自然是AlphaGo与AlphaGo Zero。AlphaGo通过无数人类棋手的棋谱进行大量训练,凭借策略网络中的蒙特卡洛树价值研究与价值网络(MCTS)获得了超人的棋力。但研究人员随后又尝试了另一种更加纯粹的强化学习方法——从零开始训练机器模型。最终,新的代理AlphaGo Zero出现,其学习过程完全源自自主摸索、不添加任何人为数据,最终以100-0的碾压性优势战胜了前辈AlphaGo。
个性化推荐
新闻内容推荐是一项历史性难题,快速变化的新闻动态、随时可能转变的用户喜好再加上与用户留存率若即若离的点击率都让研究人员头痛不已。Guanjie等研究者发布的《DRN:用于新闻推荐的深度强化学习框架》一文,希望探讨如何将强化学习威廉希尔官方网站 应用于新闻推荐系统以攻克这一重大挑战。
为此,他们构建起四种资源类别,分别为:1)用户资源;2)上下文资源(例如环境状态资源);3)用户新闻资源;4)新闻资源(例如行动资源)。他们将这四种资源插入深度Q网络(DQN)以计算Q值。随后,他们以Q值为基础选择一份新闻列表进行推荐,并将用户对推荐内容的点击情况作为强化学习代理的重要奖励指标。
作者们还采用其他威廉希尔官方网站 以解决相关难题,包括记忆重复、生存模型、Dueling Bandit Gradient Descent等方法。
计算机集群中的资源管理
如何设计算法以将有限的资源分配给不同任务同样是一项充满挑战的课题,而且往往需要人为启发的引导。
题为《使用深度强化学习实现资源管理》的论文介绍了如何使用强化学习让模型自动探索如何为保留的作业分配及调度计算机资源,借此最大程度降低平均作业(任务)的处理时长。
这种方法用“状态空间”来表现当前资源分配与作业的资源配置方式。而在行动空间方面,他们使用一种技巧,允许代理在各个时间阶段选择多项行动。奖励则是系统中所有作业的总和(-1/作业持续时间)。接下来,他们将强化学习算法与基准值相结合,借此计算策略梯度,找出最佳策略参数,凭借这些参数计算出能够实现目标最小化的行动概率分布。
交通灯控制
在题为《基于强化学习的多代理交通信号网络控制系统》一文中,研究人员尝试设计一种交通信号灯控制方案,借此解决交通拥堵问题。他们的方法仅在模拟环境下进行了测试,并表现出优于传统方法的性能水平,这也体现出在交通系统设计中引入多代理强化学习威廉希尔官方网站 的潜在可行性。
他们在五个路口的交通网络中部署了五个代理,并在中央路口处部署强化学习代理以控制交通信号。他们将交通状态定义为8维向量,每个元素代表各条车道的相对交通流量。每个代理可以从8种选项中任选其一,各选项代表每个阶段的组合,奖励条件则是新的组合必须在交通流量延迟方面优于前一组合。作者们使用SQN计算{状态,行动}对的Q值。
机器人
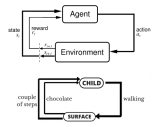
强化学习在机器人威廉希尔官方网站 领域的应用同样大放异彩。感兴趣的朋友请关注强化学习在机器人领域的研究成果。在这方面,研究人员们通过训练引导机器人学习策略,尝试将原始视频图像与机器人的行动映射起来。将RGB图像输入CNN进行计算,最终输出的则是各台驱动引擎的扭矩。强化学习组件负责根据训练数据中的状态分布总结出准确的转换策略。
网络系统配置
网络系统当中往往包含超过100项可配置参数,而参数调整过程则需要合格的操作人员持续进行跟踪与错误测试。
题为《强化在线网络系统自我配置能力的学习方法》的论文,介绍了研究人员如何在基于动态虚拟机的环境中自动重新配置多层网络系统内各项参数的首次尝试。
研究人员可以将重新配置的流程公式化为有限MDP(马尔科夫决策流程)的形式。其中的状态空间为系统配置,各参数的行动空间则包括{增加,减少,保持不变}。奖励被定义为预期响应时间与实测响应时间之差。作者使用Q学习算法执行这项任务。
当然,作者也使用了其他一些威廉希尔官方网站 (例如策略初始化)以解决较大状态空间与复杂问题场景下的计算难度问题,因此并不能算单纯依靠强化学习与神经网络组合实现。但可以相信,这项开拓性工作为未来的探索铺平了道路。
化学
强化学习在优化化学反应方面同样表现出色。研究人员们发现,他们的模型已经摸索出极为先进的算法,《通过深度强化学习优化化学反应》一文还探讨了如何将这种算法推广到多种不同的潜在场景当中。
配合LSTM(长短期记忆网络)对策略特征进行建模,强化学习代理通过以{S,A,P,R}为特征的马尔科夫决策流程(MDP)优化了化学反应。其中的S代表一组实验条件(例如温度、pH等),A为可以调整的一切可能行动的集合,P为从当前实验条件转换至下一条件的概率,R则为状态奖励函数。
这套应用方案很好地演示了强化学习威廉希尔官方网站 如何在相对稳定的环境下减少试错次数并缩短学习周期。
拍卖与广告
阿里巴巴公司的研究人员发表了《在广告展示中采用多代理强化学习进行实时竞拍》一文,表示其基于集群的分布式多代理解决方案(DCMAB)取得了可喜的成果,并计划在下一步研究中投放淘宝平台进行实际测试。
总体而言,淘宝广告平台负责为经销商提供可供竞拍的广告展示区域。目前大多数代理无法快速解决这个问题,因为交易者往往互相竞标,而且出价往往与其业务及决策密切相关。在这篇论文中,研究人员将商户与客户划分为不同的组以降低计算复杂性。各代理的状态空间表示代理本身的成本-收入状态,行动空间为(连续)竞标,奖励则为客户集群收入。
近期,越来越多研究人员开始尝试将强化学习与其他深度学习架构相结合,并带来了令人印象深刻的成果。
其中最具影响力的成果之一,正是DeepMind将CNN与强化学习相结合做出的尝试。以此为基础,代理可以通过高维传感器“观察”环境,而后学习如何与之交互。
CNN配合强化学习已经成为人们探索新思路的有力组合。RNN是一种具有“记忆”的神经网络。与强化学习结合使用,RNN将为代理提供记忆能力。例如,研究人员将LSTM与强化学习进行组合,创建出一套深循环Q网络(DRQN)并学习如何游玩雅达利游戏。他们还使用LSTM加强化学习解决了化学反应优化问题。
DeepMind还展示了如何使用生成模型与强化学习生成程序。在这套模型中,以对抗方式训练而成的代理会将对抗信号作为改善行动的奖励,这种方式与GAN(生成对抗网络)将梯度传播至入口空间的方法有所不同。
总结:何时开始使用强化学习?
所谓强化,是指根据制定的决策配合奖励摸索最佳方法;这类能够随时与环境交互并从中学习。每做出一项正确行动,我们都将予以奖励;错误行动则对应惩罚。在行业当中,这类学习方法将有助于优化流程、模拟、监控、维护并有望催生出强大的自治型系统。
大家可以参考以下标准思考何时在何处使用强化学习威廉希尔官方网站 :
• 需要对复杂甚至存在一定危险性的特定流程进行模拟时。
• 处理某些需要大量人类分析师及领域专家的特定问题时。强化学习方法能够模仿人类的推理过程,而非单纯预测最佳策略。
• 能够为学习算法提供良好的奖励定义时。你可以在每次交互中正确对模型进行校准,借此保证奖励总比惩罚多,帮助模型逐步摸索出正确的解决路线。
• 当缺少关于特定问题的充足数据时。除了工业领域之外,强化学习也广泛适用于教育、卫生、金融、图像以及文本识别等各个行业。
除了工业领域之外,强化学习也广泛适用于教育、卫生、金融、图像以及文本识别等各个行业。
责编AJX



























 工商网监
工商网监
评论