 电子发烧友App
电子发烧友App


最近炒得比较火的影子模式实际就是在通过数据收集的方式不断interwetten与威廉的赔率体系
自动驾驶系统按照人类驾驶习惯实现人之间的交互过程。对于开发者而言,则需要重新思考人类驾驶员之间是如何正常且正确交互的,从而在设计实现所标定的控制参数中不断模拟并实现社会面相契合的自动驾驶。
实际上对于如何为自动驾驶真正有效的交互控制能力而言,其核心是需要寻求如下一系列基本问题的答案的:
首先,什么是实际道路驾驶中需要考虑的场景交互过程?各类场景交互的优劣如何评价?如何为合理且正确的场景交互行为建模?如何将建模结果应用于后续开发过程中?
回答如上问题就需要理解复杂交通场景中各行驶车辆之间动态交互的原则和倾向性,通过利用对环境目标行为或反应的信念和期望,产生不同的社会驾驶行为;预测该对应移动目标场景的未来状态,可以最大限度的构建安全的智能车辆行驶行为,进而对行为预测和潜在碰撞过程提升相应的检测能力;最终为开发创建逼真的仿真驾驶模拟器。
如何定义可解释的驾驶行为
在某种程度上,预测需要围绕在高阶自动驾驶系统中观察到的轨迹是否具备可解释性而构建的,目标识别过程有助于直观解释其轨迹预测的合理性,从而有助于进行系统分析和调试。这样将朝着使我们的自动驾驶系统将向更值得信赖的方向发展,也是证明系统决策的能力的关键。
自车以蓝色显示,条形图显示非自车的目标概率。对于每个目标,最多显示两个最有可能到达目标的预测轨迹,其表示宽度与概率成正比。这里的可解释性指的是自车对其目标车的所有实际行为所做出的预判都具备可解释性、合理性分析。比如如下为典型的4个自动驾驶场景下,可以分别给出不同的解释性说明。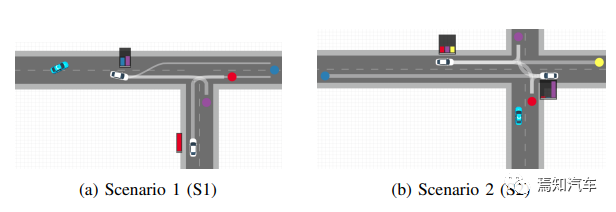
(a)场景1:T字路口换道避撞
(b) 场景2:十字路口
(c)场景3:环岛路口驶出避撞
(d) 场景4:红绿灯复杂场景
(a)S1:自车目标是一个前方蓝色目标。车辆 V1 在自车道上,V1 从左向右变道,如果偏离自车的预测轨迹,那么自动驾驶控制将会退出。由于避撞需要大幅减速,自车可以决定换道以避免被减速。因为如果 V1 的目标是向东行驶,则变道将是不合理的。
(b)S2:自车目标是一个前方蓝色目标。车辆 V1 正从东面接近交叉路口,车辆 V2 从西面接近。当 V1 接近交叉路口、减速并等待转弯时,自车对 V1 将右转的信念显着增加,因为如果目标是左转或直行,停下来是不合理的。由于自车识别出V1的目标是往北走,它预测V1会等到V2过去,给自车一个上路的机会。
(c)S3:自车目标是绿色目标。当 V1 从环形交叉路口的内侧车道变为外侧车道并降低速度时,自车将预测V1 将从南出口驶出,因为这是实现该目标的合理行动过程。这样,自车将在 V1 仍在环形交叉路口时驶入环形交叉路口。
(d)S4:自车的目标是紫色目标。两辆车在红绿灯处停在路口,车辆 V1 从后面接近他们,车辆 V2 从相反的方向穿过。当 V1 达到零速度时,目标生成函数在其当前位置为 V1 添加一个停止目标(橙色),此目标分布将向它移动,因为停止对于北/西目标来说是不合理的。
本文提出的车辆轨迹预测方法
基于前序分析,可以说预测其他车辆的意图和行驶轨迹的能力是自动驾驶的关键问题。首先,对于驾驶场景中这种耦合多代理交互是一种有限观察数据,可以增强预测环境移动目标趋势的能力,从而做出快速准确的预测,因此这个问题将变得非常复杂。
为了在这种情况下进行预测,自动驾驶研究的标准方法是假设车辆使用有限数量的不同高级操作之一,例如车道跟随、变道、转弯、停止等。 最近基于深度学习的方法在自动驾驶中呈现了不少令人惊喜的结果。这些预测模型是在大型数据集上训练的,这些数据集通过涉及传感车辆(例如视频、激光雷达、雷达)的数据收集活动变得可用。
为了预测车辆的未来行驶动机,我们必须推理为了什么目的 - 车辆执行其过去的行驶路径还是改变其预期路径,这就需要了解其他车辆的目标来预测其未来的行驶动机和轨迹,这有助于在未来一定的时间范围内进行精准规划。那么,这种推理将有助于解决保守的自动驾驶问题。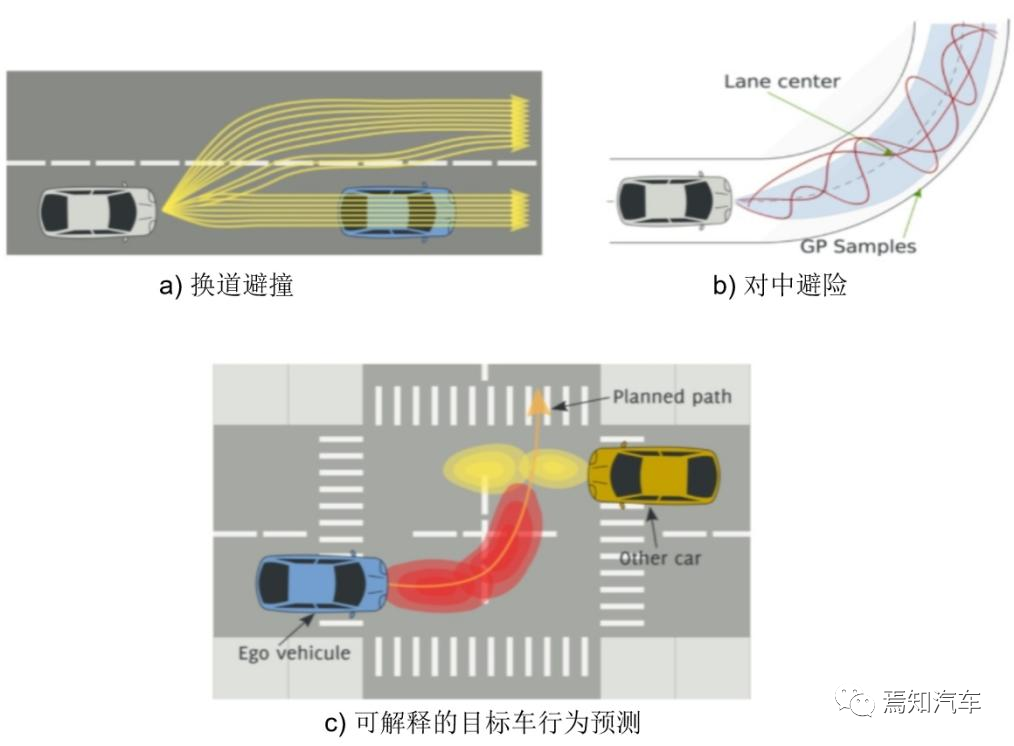
这里我们需要通过分类器来根据观察到的驾驶轨迹,预测当前车辆需要执行的操作。这种方法的局限性在于它们只能检测其他车辆的当前动机,因此使用此类预测规划器实际上受限于检测到的运动时间尺度。另一种方法是为每个其他车辆指定一组有限的可能目标(例如道路出口点),并根据车辆观察到的局部状态规划到每个目标的完整轨迹。虽然这种方法可以生成长期预测,但其局限性在于生成的轨迹必须与车辆相对紧密地匹配,才能对车辆的目标做出高置信度的预测。
本文阐述了一种用于自动驾驶的集成预测和规划系统,该系统使用“理性逆向规划”(也就是逆向假设)来识别其他车辆的目标。目标识别通过蒙特卡洛树搜索 (MCTS) 算法来规划自车的最佳行驶策略。逆向规划和 MCTS 利用一组共享的已定义演习和宏观行动,以此来构建合理性说明的行动规划。城市驾驶场景模拟评估表明该系统能够稳健地识别其他车辆目标,使我们的车辆能够利用重要的机会来显着减少驾驶时间。在每种情况下都需要会为证明系统预测及决策是否合理输出直观的解释。
为此,利用可解释的基于目标行为分析的预测和规划 (IGP2),利用有限空间下的运动分析计算优势,可以很好的扩展机动序列的规划和预测方法。通过理性逆向规划的新颖整合来实现这一目标,以识别其他车辆目标,并使用蒙特卡洛树搜索 (MCTS)为自车规划最佳行动轨迹。
实际上,这种最佳轨迹的预测是通过逆向规划和 MCTS ,利用一组共享的已定义操作来构建合理性原则解释的运动规划,即规划相对于给定指标应该是最优的,来实现的。
IGP2:可解释的基于目标的预测和规划
整个预测方法依赖于两个假设:首先,每辆车都试图从一组可能的目标中达到某个(未知)目标,同时,每辆车都遵循从一个有限的已定义操作库来生成对应的规划。
下图中概述了我们提议的 IGP2 系统中的组件。
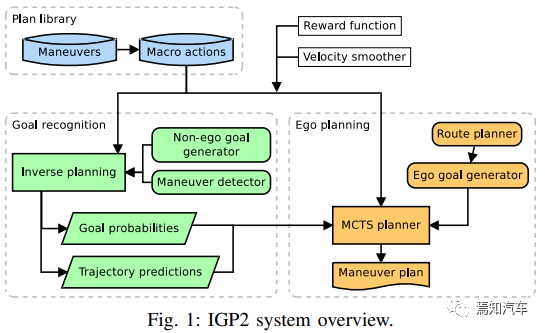
在高层次上,可解释的行为预测能力IGP2 近似最优自车行驶策略 π* 定义如下: 对于每个非自车情况,生成其可能的目标并为该车辆反向规划每个目标。每个非自车的最终目标概率和预测轨迹是由蒙特卡洛树搜索 (MCTS) 算法的模拟过程所提供的信息生成的,这一过程中包含了自车朝向其当前目标的最佳机动计划。为了在逆向规划和 MCTS 中保持所需的高效搜索能力,如上这些操作需要使用上下文信息灵活地连接操作。
本文将在如下部分中详细介绍如上图中的这些组件如何生成。
A. 行为预测
在对智驾车辆进行行为预测分析的时候,需要提前做出一些行为假设。比如,我们可以假设每辆车都在执行以下操作之一:车道跟随、左/右变道、左/右转、让路、停止。每个机动参数 ω 指定适用性和终止条件。例如,左变道仅适用于车辆左侧有一条相同行驶方向的车道,并在车辆到达新车道且其方向与车道对齐时终止。
一些动作有自由参数,例如 follow-lane 有一个参数来指定何时终止。如果适用,指定机动车辆要遵循的局部轨迹可以表示为 si 1:n,其中包括全局坐标系中的参考路径和沿路径的目标速度。为了便于说明,我们假设 si 使用与 si 相同的表示和索引,但通常情况并非如此(例如,s可以按纵向位置而不是时间进行索引,它可以插值到时间指数)。
此时,参考路径是通过贝塞尔样条函数生成的,该样条函数拟合到从道路拓扑中提取的一组点,目标速度是使用类似于域启发式方法进行设置。
B.宏动作
宏动作指定了智能汽车的常见机动序列,并根据道路布局等上下文信息自动设置机动车运动的自由参数。下表指定了我们系统中使用的宏操作。宏动作的适用条件由宏动作中第一个机动的适用条件以及可选的附加条件给出。宏动作的终止条件由宏动作中最后一个机动的终止条件给出。
| 宏动作 | 附加应用条件 | 手动序列(操作参数) |
| 继续行驶 | -- | 跟车(可见车道的尾部) |
| 继续驶向出口 | 必须在环岛且未在驶出车道 | 跟车(下一个出口点) |
| 变道左边/右边 | 有一个车道向左或右方 | 跟车(直道目标车道清晰),变道至左/右 |
| 退出至左/右方 | 出口点在车辆前方相同的车道上 | 跟车(出口点),给定道路(相关车道),转向左/右 |
| 停止 | 存在一个停止目标在当前车道的前方 | 跟车(关闭向停止点),停止 |
C. 速度平滑
为了获得车辆 i 的可行轨迹,需要定义一个速度平滑操作,用于优化给定轨迹 si 1:n 中的目标速度。设置 xt 为参考路径上在 si 和 vt 处的纵向位置,其目标速度为 1 ≤ t ≤ n。我们将 κ : x → v 定义为点 xt 之间目标速度的分段线性插值。给定两个时间步长差值为时间Δt;最大速度和加速度,vmax/amax;并设置 x1 = x^1, v1 = v^1,我们将速度平滑定义为: 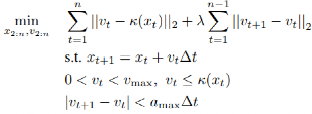
其中,λ > 0 是给予优化目标的加速部分的权重。如上公式是一个非线性非凸优化问题,例如,使用原始对偶内点法可以解决该类问题。
从问题的解决方案 (x2:n, v2:n) 中,利用插值可以获得原始点在 x^t 处可实现的速度。
D. 目标识别
我们假设每个非自车 i 寻求达到有限数量的可能目标之一 Gi ∈ Gi ,使用从我们定义的宏观行动中构建对应的运动规划。我们使用理性逆向规划的框架来计算 i 在时间 t 的目标的贝叶斯后验分布: 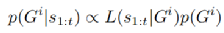
其中 L(s1:t|Gi) 是假设 i 的目标为 Gi 时观察到的轨迹的似然,p(Gi) 指定 Gi 的先验概率。
似然度是两个计划之间奖励差异的函数:从 i 的初始观察状态 si1 到速度平滑后的目标 Gi ,得到最佳轨迹的奖励 r^,沿着观察到的轨迹直到时间 t 的轨迹奖励 r ,然后继续以最佳方式达到目标 Gi,平滑仅应用于 t 之后的轨迹。
概率定义为一个缩放参数,这种可能性定义假设车辆以近似理性地(即最佳地)驾驶以实现其目标,同时允许有一些偏差。如果目标不可行,我们将其概率设置为零。
1)目标生成: 启发式函数用于根据车辆 i 的位置和上下文信息(例如道路布局)生成一组可能的目标 Gi。在我们的系统中,我们包括当前道路和连接道路可见端的目标(以自车的视野区域为界)。除了此类静态目标之外,还可以添加取决于当前流量的动态目标。例如,密集合并场景中,动态添加停止目标以模拟车辆允许自车在前方合并的意图。
2)机动检测: 机动检测用于检测车辆当前(在时间t)需要执行的动作,在持续规划之前允许逆向规划所需要完成的动作。假设有一个模块计算每辆车 i 的当前动作概率 p(ωi),一种选择是贝叶斯变点检测。由于不同的当前动作可能暗示不同的目标,可以对 p(ωi) > 0 的每个可能的当前动作执行逆向规划。因此,每个当前动作产生其相关的目标后验概率可以表示为 p(Gi| s1:t , ωi).
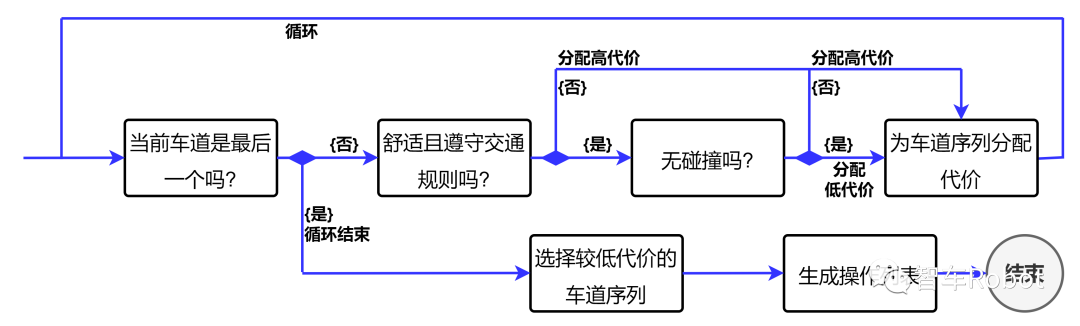
3)逆向规划: 逆向规划是使用 A*search 对宏观行动进行规划。A* 在完成产生初始轨迹 s^1:τ 的当前机动 ωi 后开始。每个搜索节点 q 对应于一个状态 s ∈ S,初始节点处于状态 s^τ ,并且宏动作通过它们应用于 s 的适用性条件进行过滤。A* 选择通向节点 q’ 的下一个宏操作,该节点对目标 Gi 的估计总成本最低,由 f(q’ ) = l(q’ ) + h(q’)到达节点 q’ 的成本 l(q’ )计算得出。由从 i 在初始搜索节点中的位置到它在 q’ 中的位置行驶时间给出,遵循通向 q’ 的宏动作返回的轨迹。 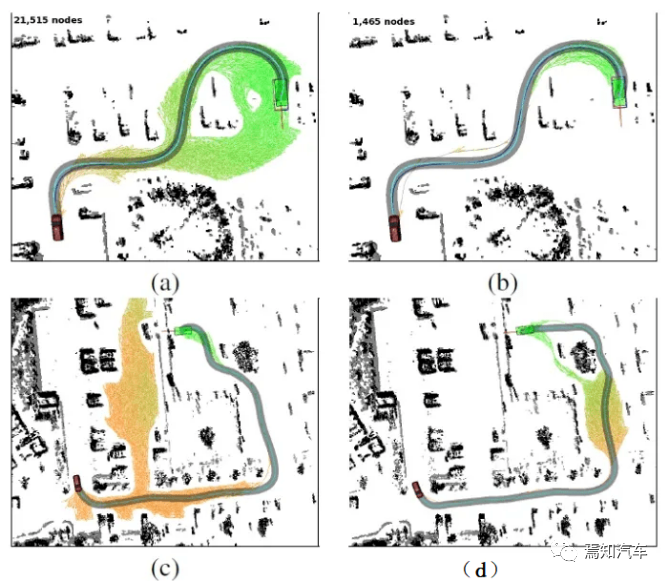

A* 假设所有其他未计划在观察到的轨迹后使用恒速车道跟随模型的车辆。我们在逆向规划期间不检查碰撞。用于估计从 q’ 到目标 Gi 的剩余成本的成本启发式 h(q 0 ) 由在限速下从 i 在 q0 中的位置通过直线到目标的行驶时间给出。h(q0 ) 的这个定义根据 A* 理论是可接受的,它确保搜索返回最优计划。找到最优计划后,我们从计划中的机动和初始段 s^1:τ 中提取完整的轨迹 s^i 1:n。
4) 轨迹预测: 我们的系统必须要为给定的车辆和目标预测多个可能的轨迹。因为在某些情况下,不同的轨迹可能是(接近)最佳的,但可能导致不同的预测,这可能需要自车的不同行为。我们运行 A* 搜索一段固定的时间,并让它计算一组具有相关奖励的计划(最多一些固定数量的计划)。
每当 A* 搜索找到一个达到目标的节点时,相应的计划就会添加到计划集中。给定一组平滑轨迹{s^i,k 1:n |ω i, Gi} k=1..K 到具有初始状态 ω i 和相关奖励 rk = Ri(s^i,k1:n) 的目标 Gi,我们通过如下波尔兹曼分布预测可以得到最优轨迹: 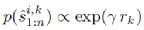
其中 γ 是缩放参数(设定 γ = 1)。
E. 自车规划
为了计算自车的最佳计划,我们使用目标概率和预测轨迹来实现蒙特卡罗树搜索 (MCTS) 算法。
该算法执行多个闭环模拟 s^t:n,从当前状态 s^t = st 开始向下到某个固定的搜索深度或直到达到目标状态。在每次模拟开始时,对于每个非自车,我们首先对当前机动进行采样,然后使用相关概率对车辆的目标和轨迹进行采样。搜索树中的每个节点 q 对应于一个状态 s ∈ S 并且宏动作通过它们应用于 s 的适用性条件进行过滤。
在使用一些探索威廉希尔官方网站
选择宏动作 µ 之后,根据宏动作 µ 生成的轨迹和非自车的采样轨迹,对当前搜索节点中的状态进行前向模拟,生成部分轨迹 s^τ:ι 和新的搜索节点 q0 与状态 s^ι 。
轨迹的前向模拟使用比例控制和自适应巡航控制的组合来控制车辆的加速和转向。根据对车辆的观察,在每个时间步长中监控车辆运动的终止条件。对s^τ:ι 执行碰撞检查以检查自车是否发生碰撞,在这种情况下,我们将奖励设置为 r ← rcoll进行反向传播,其中 rcoll 是方法参数。如果新状态 s^ι 达到自车目标 Gε,我们计算反向传播的奖励为 r ← Rε (s^t:n)。如果搜索达到其最大深度 dmax 而没有碰撞或实现目标,我们设置 r ← rterm,它可以是一个常数或基于类似于 A* 搜索的启发式奖励估计。
总结
本文介绍了一种通过理性逆向规划进行目标识别和多模态轨迹预测的方法。通过将目标识别与MCTS 计划相结合,为自车生成优化计划。在模拟城市驾驶场景中的评估显示准确的目标识别、提高的驾驶效率以及解释预测和自我计划的能力。
审核编辑:刘清




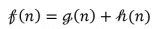





 工商网监
工商网监
评论