 电子发烧友App
电子发烧友App


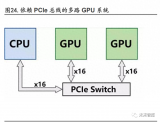
AI 服务器是专门为运行人工智能算法和处理大规模数据而设计的高性能计算机,它们通常 具备高处理能力、大内存和高速存储器、多核心处理器、高速网络接口等特点,能够应对复 杂的计算任务和大数据量的处理任务。 AI 服务器中 PCB 价值量的提升主要体现在以下几个模块:GPU 加速卡(OAM),主要由 GPU 芯片、内存芯片、电源模块、散热器等部件组成,通过 PCB 板 来连接和传输信号。GPU 加速卡可以分为两种类型:SXM 版本和 PCIE 版本。SXM 版本是指使 用 NVIDIA 公司开发的 SXM 接口连接 GPU 芯片和主板的加速卡;PCIE 版本是指使用标准的 PCIE 接口连接 GPU 芯片和主板的加速卡。SXM 版本相比 PCIE 版本具有更高的带宽和更低的 延迟,但也需要更高级别的 PCB 板和散热系统。
先进的 GPU 加速卡需要使用 5 阶 20 层或以上的 HDI 板,HDI 板是高密度互连板的简称,它是 一种通过激光钻孔或微细加工威廉希尔官方网站 ,在普通 PCB 板上形成微小的孔径或线宽,从而实现更高 层次、更密集的布线和连接的 PCB 板。HDI 板可以提高信号完整性、降低电磁干扰、缩小尺 寸和重量、增强可靠性等优点。HDI 板可以分为不同的阶数和层数,阶数表示每个层面上有 多少次激光钻孔或微细加工,层数表示有多少个层面叠加在一起。一般来说,阶数越高,层 数越多,HDI 板的密度和复杂度就越高。
GPU 芯片和内存芯片都有很多引脚或焊盘,需要通过 HDI 板来实现高效率、低延迟、低功耗、低噪声的信号传输。 GPU 加速卡需要使用高层次、高密度、高可靠性的 HDI 板来连接各个部件,主要有以下几个 原因:GPU 芯片和内存芯片都有很多引脚或焊盘,需要通过 HDI 板来实现高效率、低延迟、低 功耗、低噪声的信号传输。GPU 加速卡的功耗较高,会产生大量的热量,如果不能及时散发,会影响其稳定性和寿 命。
因此,需要使用具有良好导热性能的 HDI 板材料。GPU 加速卡的尺寸较小,需要使用 HDI 板来减少 PCB 板的面积和厚度,提高空间利用率 和散热效果。GPU 加速卡的性能较高,需要使用 HDI 板来支持更高的频率和带宽,提高数据传输速度 和质量。
5 阶 20 层以上的 HDI 板是目前 PCB 行业中高端且昂贵的产品之一,其制造工艺要求非常高, 需要使用先进的设备、材料和工艺。目前,全球能够生产这种 HDI 板的厂商很少,主要集中 在日本、韩国、中国台湾等地。 GPU 加速卡对 CCL 的具体要求主要有以下几点:
高频高速性能:由于 AI 服务器需要处理大量的数据和信号,因此 GPU 加速卡需要使用 具有高频高速性能的 CCL,即能够在高频率下保持低损耗、低时延、低串扰、低噪声等 特性的 CCL。这需要 CCL 具有较低的介电常数(Dk)、介电损耗(Df)、表面粗糙度(Rz) 等参数。
导热性能:由于 GPU 加速卡的功耗较高,会产生大量的热量,如果不能及时散发,会影 响其稳定性和寿命。因此,GPU 加速卡需要使用具有良好导热性能的 CCL,即能够有效 地将热量从芯片传导到散热器或外部环境的 CCL。这需要 CCL 具有较高的导热系数(K) 和较低的热膨胀系数(CTE)等参数。
可靠性:由于 GPU 加速卡需要在复杂的环境中长期稳定运行,因此 GPU 加速卡需要使用 具有高可靠性的 CCL,即能够抵抗各种应力和环境因素的影响,保持其结构和功能不变 的 CCL。这需要 CCL 具有较高的玻璃化转变温度(Tg)、较低的水分吸收率(MOT)、较强 的机械强度和耐化学腐蚀性等参数。
GPU 模组板(UBB),即 Unit Baseboard,是一种用于搭载整个 GPU 平台的 PCB 板。GPU 模组 板的主要功能是连接多个 GPU 加速卡并与 CPU 主板通信。GPU 加速卡,即 Open Accelerator Module,是一种基于开放标准设计的 GPU 模块,可以插入到 GPU 模组板上。
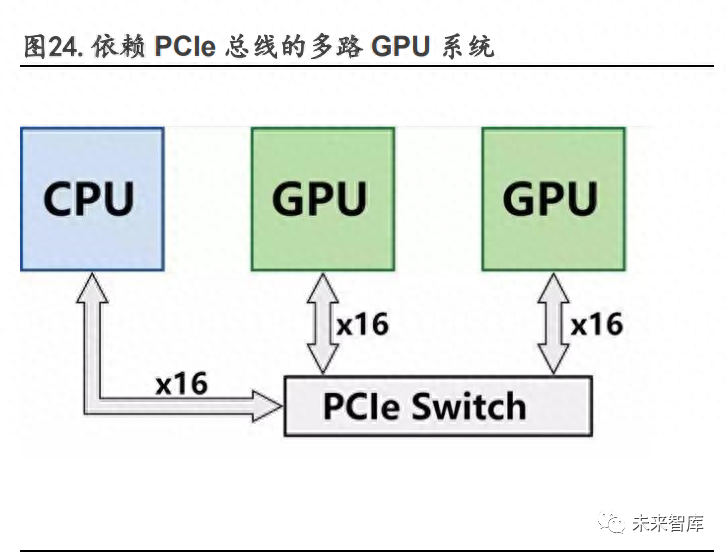
GPU 之间的高速互联可以通过 NVLink + NVSwitch 实现。NVSwitch 是英伟达推出的一种高性 能交换芯片,用于实现多个 GPU 加速卡之间的互联和通信,NVLink 2.0 协议最大能够提供每 秒 900GB 的双向带宽。第三代 NVSwitch 有 64 个第四代 NVLink 端口,每个端口可以连接一 个 GPU 加速卡或一个 CPU 主板,从而实现多达 64 个 GPU 加速卡的全互联架构。NVSwitch 基 于 NVLink 的高级通信能力构建,可为计算密集型工作负载提供更高带宽和更低延迟。
基于 第三代 NVSwitch,通过在服务器外部添加第二层 NVSwitch,NVLink 网络可以连接多达 32 个 服务器、256 个 GPU,并提供 57.6TB/s 的多对多带宽,实现 GPU 在服务器节点间通信扩展, 形成数据中心大小的 GPU。为了实现高速、高效、高可靠的数据传输和图形处理,GPU 模组板需要使用高多层通孔板(THP 板)作为载体。
THP 板是指通过机械钻孔或激光钻孔,在普通 PCB 板上形成大量的通孔,并 在通孔内壁镀上一层导电铜箔,从而实现不同层面之间的电气连接。THP 板可以分为不同的 层数,层数表示有多少个层面叠加在一起。一般来说,层数越多,THP 板的密度和复杂度就 越高。 GPU 模组板需要使用高多层 THP 板来实现高速数据传输和高频信号处理的原因有:GPU 模组板需要处理大量的数据和信号,因此需要使用具有高频高速性能的 THP 板,即 能够在高频率下保持低损耗、低时延、低串扰、低噪声等特性的 THP 板。这需要 THP 板 具有较低的介电常数(Dk)、介电损耗(Df)、表面粗糙度(Rz)等参数。GPU 模组板需要连接多个 NVLink 芯片和 GPU 加速卡,因此需要使用具有高层次的 THP 板,即能够实现更多的信号通道和更好的电气性能的 THP 板。
这需要 THP 板具有较高的 线宽线距、孔径、阻抗控制等参数。GPU 模组板的功耗较高,会产生大量的热量,如果不能及时散发,会影响其稳定性和寿 命。因此,GPU 模组板需要使用具有良好导热性能的 THP 板,即能够有效地将热量从芯 片传导到散热器或外部环境的 THP 板。这需要 THP 板具有较高的导热系数(K)和较低 的热膨胀系数(CTE)等参数。
GPU 模组板对覆铜板有以下具体要求:
层数:由于 GPU 模组板需要连接多个 GPU 加速卡,并且需要实现多层次的电源分配网络 (PDN),因此需要使用较高层数的覆铜板。目前,GPU 模组板使用的覆铜板一般在 16 层 以上;
电性能:由于 GPU 模组板需要支持高速数据传输和高频信号处理,因此需要使用具有较 低介电常数(Dk)和介质损耗因子(Df)的覆铜板,以减少信号的衰减和失真,提高信 号的完整性和可靠性,目前 GPU 模组板使用的覆铜板一般采用 PPO 等高性能树脂材料;
热性能:由于 GPU 模组板需要承受较高的功耗和发热量,因此需要使用具有较高热导率 和热稳定性的覆铜板,以有效地将热量从元器件传导到散热模组,防止过热造成性能下 降或损坏。
目前,GPU 模组板使用的覆铜板一般采用金属基板或者添加导热填料的复合 基板;加工性能:由于 GPU 模组板需要实现较多的通孔连接不同层次的电路线路,并且需要实 现较大的面积和厚度,因此需要使用具有较好加工性能的覆铜板,以满足 THB 的要求, 提高 PCB 的质量和良率。目前,GPU 模组板使用的覆铜板一般采用改性 PPO(MPPO)等 可交联的热固性材料,可以提高流动性和加工性。
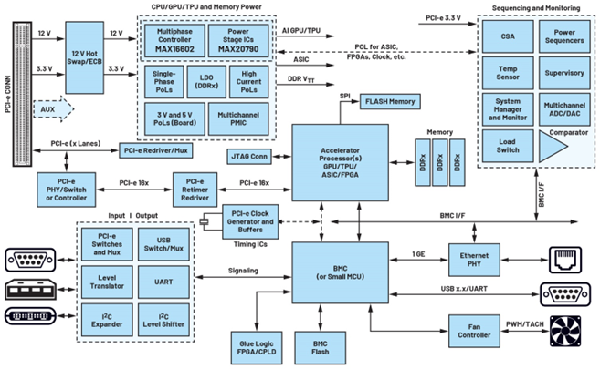
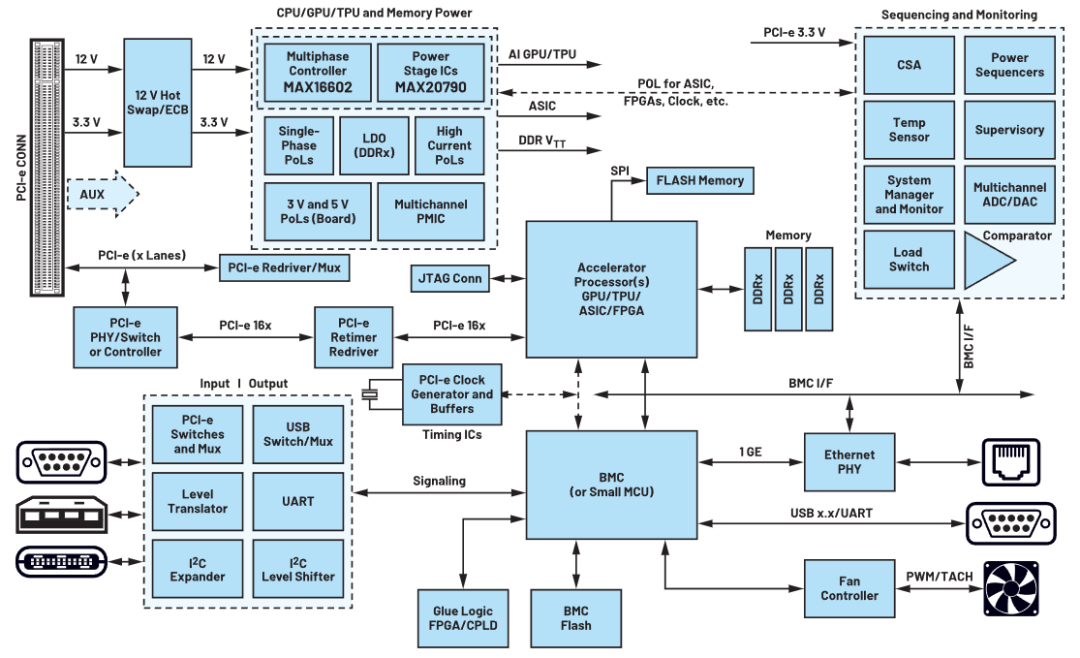
CPU 主板,是 AI 服务器中连接 CPU、内存、存储等核心部件的部件,它可以实现 CPU 与其他 部件之间的高速数据传输,并通过 PCIe 5.0 实现与 GPU 主板的互联。CPU 主板一般采用 ATX 或 EATX 等标准规格,其尺寸为 305mm x 244mm 或 305mm x 330mm,其内部包含一个或多个 CPU 插槽、内存插槽、存储插槽、电源管理芯片等元器件。CPU 主板通过 PCIe 插槽连接到 GPU 主板上,并通过 PCIe 实现高速数据传输。
CPU 主板使用的 PCB 一般为高多层通孔板(Through Hole Board, THB),其特点是具有较多 的通孔连接不同层次的电路线路,并且可以实现较大的面积和厚度。THB 可以实现更强的结 构支撑和散热能力,并且可以承载更多更复杂的元器件。
CPU 主板对覆铜板有以下具体要求:
介电常数和介质损耗:这两个参数影响信号的传输速度和能量损失,对于高频、高速的 CPU 主板来说,需要选择低介电常数和低介质损耗的 CCL,以保证信号的完整性和质量。
热膨胀系数:这个参数影响 CCL 在温度变化时的尺寸稳定性,对于高温、高功率的 CPU 主板来说,需要选择热膨胀系数与铜箔相近的 CCL,以避免因为热应力导致的层间分离 或过孔开裂等缺陷。
热导率:这个参数影响 CCL 在散热方面的性能,对于高温、高功率的 CPU 主板来说,需 要选择热导率较高的 CCL,以有效地将热量从 CPU 和其他元件传导到散热器或外部环境。
阻燃等级:这个参数影响 CCL 在遇到火灾时的安全性能,对于所有的电子产品来说,都需要选择阻燃等级较高的 CCL,以防止因为火灾引起的人员伤亡或财产损失。一般来说, 阻燃等级应达到 UL94 V-0 或以上。
据产业调研,预估 2024 年 AI 加速卡需求为 400 万颗,加速卡 PCB 用量平均单价 100 美元/ 颗,如果折算成英伟达 DGX A100 服务器对应为 50 万台,对应 UBB 板的 PCB 用量为 1000 美 元/台,对应 CPU 主板的 PCB 用量为 200 美元/台,这三部分带来是市场增量合计 10 亿美元。
此外,随着PCIe 标准升级下信息交互速度不断提升,对 PCB 的设计、走线、板材选择等要求提高。
PCIE5.0(第五代 PCI Express 总线标准),是一种用于连接各种外设设备的高速串行接口, 于 2019 年 5 月正式发布。PCIE5.0 相比于上一代 PCIE4.0,带宽提升了一倍,能够支持更高 性能的 CPU、GPU、存储等设备,满足 AI 服务器等高算力需求。通过改变电气设计改善信号 完整性和机械性能,PCIE5.0 新标准减少了延迟,降低了长距离传输的信号衰减。与 PCIE4.0 相比,PCIE5.0 信号速率达到 32GT/s,x16 带宽(双向)提升到了 128GB/s,能够更好地满足 吞吐量要求高的高性能设备,如数据中心、边缘计算、机器学习、AI、5G 网络等场景日益增 长的需求。除了保证高速传输的能力,PCIE5.0 还进一步加强了信号完整性,不仅适合连接 显卡、SSD 等配件,也适用于平台总线的使用。
目前 PCB 主流板材为 8-16 层,对应 PCIe 3.0 一般为 8-12 层,4.0 为 12-16 层,而 5.0 平台则在 16 层以上。从材料的选择上来看, PCIe 升级后服务器对 CCL 的材料要求将达到高频/超低 损耗/极低损耗级别。 据产业调研,目前支持 PCIe3.0 标准的 Purley 平台 PCB 价值量约 2200- 2400 元,支持 PCIe4.0 的 Whitley 平台 PCB 价值量提升 30%-40%,支持 PCIe5.0 的 Eagle 平 台的 PCB 价值量比 Purley 高一倍。根据我们测算,到 2025 年,PCIe 5.0 的升级有望为服务 器平台 PCB 带来百亿的价值增量。
编辑:黄飞
















 工商网监
工商网监
评论