
 电子发烧友App
电子发烧友App


在近日举办的架构日活动上,英特尔罕见地公布了未来多年的CPU、GPU架构路线图,以及一系列相关威廉希尔官方网站 、战略规划,让人大饱眼福,其中新的CPU架构是很多人非常关心的亮点。本文收集了一些资料,为大家尽量通俗地做一些简单解读。
2019-2021年三年间,英特尔将每年推出一代高性能酷睿(Core)架构(当然也会用于至强),同时在2019-2023年间,将推出三代低功耗凌动(Atom)架构,重点当然是前者啦。
2019年的高性能新架构是“Sunny Cove”(阳光海湾),CPU大幅升级的同时集成第11代核芯显卡,采用10nm工艺制造,桌面端处理器代号“Ice Lake”,这也将是英特尔第一个规模量产的10nm产品。
2020年是“Willow Cove”(柳树海湾),几乎肯定还是10nm工艺,但应该会像14nm+、14nm++那样优化改进,2021年则是“Golden Cove”(金色海湾),不知道能不能用上7nm。
对于Willow Cove、Golden Cove,英特尔只是简单提及了一些主要特性,而对于近在眼前的Sunny Cove,英特尔则是毫不吝啬地公布了不少架构威廉希尔官方网站 细节。
首先说,这应该是英特尔历史上第一次在新品发布之前N个月,就大方地公布路线图和威廉希尔官方网站 细节,再加上将会第一次大规模应用10nm新工艺,因此10nm Sunny Cove一经宣布,就吸引行业乃至普通用户的广泛关注。
而每当一代新的CPU架构公布时,了解它的原理、它的变革都让人很兴奋,英特尔这一次提前公布一系列猛料也值得鼓掌,值得细细品味。
但略有遗憾的是,英特尔目前给出的信息还不完整,主要只是介绍了Sunny Cove架构的后端设计细节,不涉及指令分派、指令队列等前端部分。
Sunny Cove的架构更新可以分为两部分,一是通用目的性能提升,二是特定目的性能提升。
通用目的性能的提升,就是通过架构增强,改进大量应用的性能和能效,几乎所有人在日常使用中都能体验到,其本质上就是原始IPC(每时钟周期指令数)吞吐量的变化,或者运行频率的提高。
无论什么工艺节点,只要这两点有一个提升,整体性能就会随之上升,至少在涉及计算的方面会有直接体现。
频率通常取决于工艺和优化,IPC则可以来自更宽、更深、更智能的内核,或者专业点说分别就是每个时钟周期执行更多指令、每时钟周期更多并行、通过前端更好地传输数据。
而特定目的性能的提升,是针对特定使用场景、算法进行架构上的扩展,包括新的指令集、新的软件编译器/库等。
这种变化只有在专门的场合才能体会到,比如说英特尔宣传Sunny Cove架构通过新加入的指令集,可以让7-Zip软件的压缩解压性能提升多达75%,就是一个典型例子,只有用这款软件或者针对其他针对相应指令优化的软件,才能获得如此明显的提升。
特殊目的性能提升虽然应用范围有限,但是只要给它发挥的空间,效果就是极为显著的,幅度远超通用性能提升。
Sunny Cove也在这方面做了大量的改进,涉及人工智能/机器学习、加解密、压缩/解压、通信/网络、通用SIMD(单指令多数据流)/矢量处理、特殊SIMD/矢量处理、多线程与多代理处理等等。
如果你有这些方面的应用,Sunny Cove带来的变化会非常可观。
上边说的都是一些大的应用范围,具体到每个领域还有更确切的应用场景,新指令的引入可以大大加速特定计算任务的执行。随着AVX-512指令单元的加入,Sunny Cove为大数运算增加了IFMA(带符号熔加算法),也可用于加解密。
同时还有矢量AES加密(支持更多AES指令并行执行)、矢量乘(Vector Carryless Multiply)、伽罗瓦域(Galois Field)、SHA/SHA-NI安全算法等,其中不少都是密码学的一些基本元素。
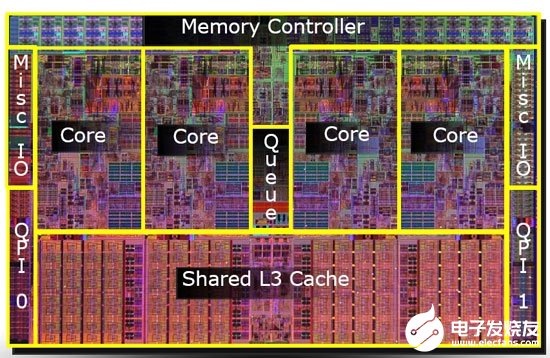
在缓存方面,Sunny Cove后端拥有48KB一级数据缓存,比现在的32KB增加了50%。一般来说,缓存的非命中率和容量增加幅度的平方根成反比,也就是说Sunny Cove的一级数据缓存命中错误率将会降低22%。
Sunny Cove的二级缓存也更大了,但具体容量暂未披露。目前酷睿是每核心256KB二级缓存,至强则是1MB。
另外,微操作(uOp)缓存也比现在的2048-entry设计要更大,只不过具体数字暂时也没有公开。
二级TLB同样增大到未知数,这有助于机器历史地址转换。通常情况下,需要保持和存储更多轮询的时候才会这么做,这意味着英特尔已经发现,在部分应用环境中,最近的机器地址还没有用上就被收回了。
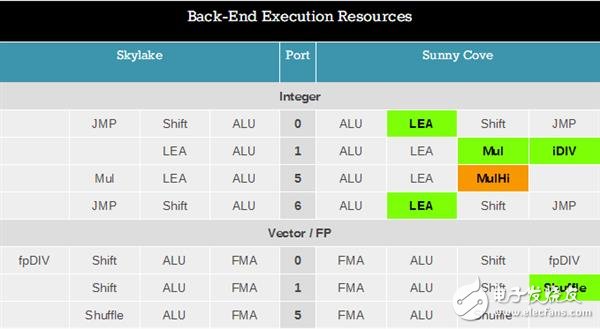
这张图显示了更多变化,包括执行端口从8个增至10个,可以让调度器一次释放更多指令,其中端口4、端口9连接着循环数据存储,带宽加倍,AGU(地址生成单元)存储能力加倍,更大的一级指令缓存也在其中起到了一定作用。
之前的Skylake架构上存在一个瓶颈,当全部三个AGU尝试存储的时候,带宽就会明显不足,每个时钟周期只能执行一个。
载入性能不变,而宽度调度从4个增至5个,这意味着记录缓冲区的分派每时钟周期可以命中5个指令,但是实际效果如何仍有待观察。
Sunny Cove、Skylake架构的执行端口发生了根本性的变化。
可以看到,英特尔为核心的整数部分配备了更多LEA(有效地址载入)单元,用来进行内存寻址计算,可能在需要频繁内存计算的情况下,通过安全更新来缓解性能损失,或者通过恒定的偏移,有助于高性能阵列代码。
MUL(乘法)单元从Skylake的端口5转移到了端口1,可能是出于平衡设计的目的,同时还增加了一个iDIV整数除法单元。
这个变化并不大,10nm Cannon Lake也有一个64位的IDIV,可以将64位证书出发从97个时钟周期(混合指令)降低到18个,Sunny Cove可能也与之类似。
INT整数运算方面,Skylake端口5的乘法单元变成了MulHi单元,但在新架构中的具体作用尚不明晰。
FP浮点运算方面,Sunny Cove增加了重排资源,因为英特尔收到客户反馈,希望能消除代码中的瓶颈。
英特尔没有具体说明核心浮点部分FMA(熔加运算)单元的功能,但我们知道,核心内有一个AVX-512指令单元,所以至少会有一个FMA单元会与之交互。
Cannon Lake架构只有一个512位FMA单元,很可能延续到了这里,在至强上可能会有两个。
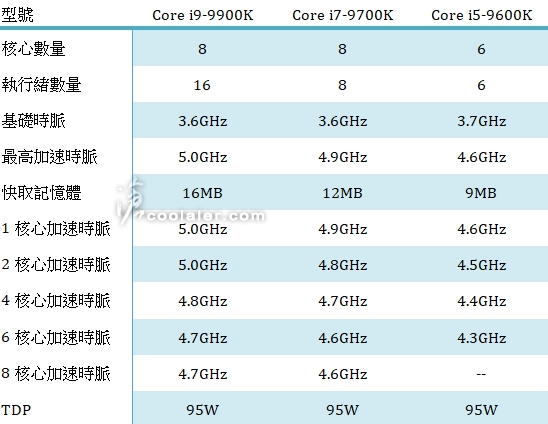
为了更明晰地对比Skylake、Sunny Cove的后端执行资源变化,外媒AnandTech还做了个对比表格如下:
英特尔列出的其他内核改进还有:分支预测器改进、有效载入延迟降低(得益于TLB/L1D)等等,但是英特尔也承认,这些改进不会让每个人获益,需要新的算法在特定代码中使用。
另外,Sunny Cove还支持更大的内存,主内存分页表现在是5层设计(之前是4层),支持的线性寻址空间达到57位,物理寻址空间则是52位。
这意味着,至强服务器平台理论上每颗处理器可以搭配最多4TB内存,而现在Skylake-SP架构的可扩展至强只有1.5TB,AMD霄龙也不过2TB。
事实上,Sunny Cove是自从AMD 2003年引入x86-64 64位架构以来,第一个对x64虚拟内存寻址做出重大变革的架构。
这十几年来,虽然虚拟内存寻址都支持64位,但实际上只有前48位有用,后边的16位只是前边简单的拷贝而已,这就将虚拟寻址空间限制在256TB。
这些虚拟内存通过分页表映射到物理内存,使得物理内存内存寻址也被限制在48位,导致整个系统的最大物理内存不能超过256TB。
现在,Sunny Cove将有效的虚拟内存寻址扩展到了57位,物理寻址则是最多52位,结果就是虚拟内存、物理内存最多分别可以支持到128PB、4PB。
根据英特尔之前给出的路线图,Ice Lake-SP家族的新一代至强将在2020年上市,届时内存扩展能力将得到前所未有的提升。
顺带说,在安全方面,Sunny Cove支持多密钥全内存加密、用户模式指令预防。
至于Sunny Cove前端部分的变化,我们期待英特尔公布更多信息。
阳光海湾充满意境:虽然此图中的天空不算很Sunny,但的确Cove很美


















 工商网监
工商网监
评论