 电子发烧友App
电子发烧友App


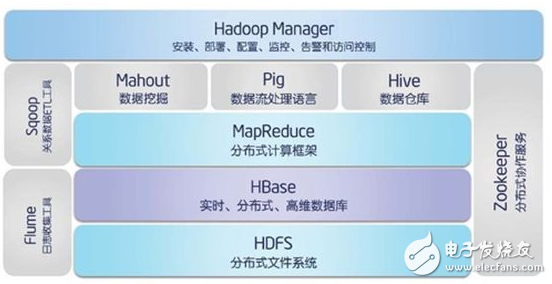
Hadoop
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hadoop特点和优缺点
一、 Hadoop 特点
1、支持超大文件
一般来说,HDFS存储的文件可以支持TB和PB级别的数据。
2、检测和快速应对硬件故障
在集群环境中,硬件故障是常见性问题。因为有上千台服务器连在一起,故障率高,因此故障检测和自动恢复hdfs文件系统的一个设计目标。假设某一个datanode节点挂掉之后,因为数据备份,还可以从其他节点里找到。namenode通过心跳机制来检测datanode是否还存在
3、流式数据访问
HDFS的数据处理规模比较大,应用一次需要大量的数据,同时这些应用一般都是批量处理,而不是用户交互式处理,应用程序能以流的形式访问数据库。主要的是数据的吞吐量,而不是访问速度。访问速度最终是要受制于网络和磁盘的速度,机器节点再多,也不能突破物理的局限,HDFS不适合于低延迟的数据访问,HDFS的是高吞吐量。
4、简化的一致性模型
对于外部使用用户,不需要了解hadoop底层细节,比如文件的切块,文件的存储,节点的管理。
一个文件存储在HDFS上后,适合一次写入,多次写出的场景once-write-read-many。因为存储在HDFS上的文件都是超大文件,当上传完这个文件到hadoop集群后,会进行文件切块,分发,复制等操作。如果文件被修改,会导致重新出发这个过程,而这个过程耗时是最长的。所以在hadoop里,不允许对上传到HDFS上文件做修改(随机写),在2.0版本时可以在后面追加数据。但不建议。
5、高容错性
数据自动保存多个副本,副本丢失后自动恢复。可构建在廉价机上,实现线性(横向)扩展,当集群增加新节点之后,namenode也可以感知,将数据分发和备份到相应的节点上。
6、商用硬件
Hadoop并不需要运行在昂贵且高可靠的硬件上,它是设计运行在商用硬件的集群上的,因此至少对于庞大的集群来说,节点故障的几率还是非常高的。HDFS遇到上述故障时,被设计成能够继续运行且不让用户察觉到明显的中断。
二、HDFS缺点
1、不能做到低延迟
由于hadoop针对高数据吞吐量做了优化,牺牲了获取数据的延迟,所以对于低延迟数据访问,不适合hadoop,对于低延迟的访问需求,HBase是更好的选择,
2、不适合大量的小文件存储
由于namenode将文件系统的元数据存储在内存中,因此该文件系统所能存储的文件总数受限于namenode的内存容量,根据经验,每个文件、目录和数据块的存储信息大约占150字节。因此,如果大量的小文件存储,每个小文件会占一个数据块,会使用大量的内存,有可能超过当前硬件的能力。
3、不适合多用户写入文件,修改文件
Hadoop2.0虽然支持文件的追加功能,但是还是不建议对HDFS上的 文件进行修改,因为效率低。
对于上传到HDFS上的文件,不支持修改文件,HDFS适合一次写入,多次读取的场景。
HDFS不支持多用户同时执行写操作,即同一时间,只能有一个用户执行写操作。
三、HDFS优点
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性。Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本。与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。









 工商网监
工商网监
评论