 电子发烧友App
电子发烧友App


一、霍夫曼编码介绍
霍夫曼编码(Huffman Coding)是一种编码方式,是一种用于无损数据压缩的熵编码(权编码)算法。
霍夫曼编码是可变字长编码(VLC)的一种。 Huffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就称Huffman编码。下面引证一个定理,该定理保证了按字符出现概率分配码长,可使平均码长最短。
定理:在变字长编码中,如果码字长度严格按照对应符号出现的概率大小逆序排列,则其平 均码字长度为最小。
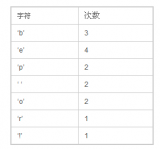
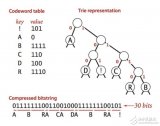
霍夫曼编码的具体方法:先按出现的概率大小排队,把两个最小的概率相加,作为新的概率 和剩余的概率重新排队,再把最小的两个概率相加,再重新排队,直到最后变成1。每次相 加时都将“0”和“1”赋与相加的两个概率,读出时由该符号开始一直走到最后的“1”, 将路线上所遇到的“0”和“1”按最低位到最高位的顺序排好,就是该符号的霍夫曼编码。
二、霍夫曼编码特点
1) 编出来的码都是异字头码,保证了码的唯一可译性。
2) 由于编码长度可变。因此译码时间较长,使得霍夫曼编码的压缩与还原相当费时。
3) 编码长度不统一,硬件实现有难度。
4) 对不同信号源的编码效率不同,当信号源的符号概率为2的负幂次方时,达到100%的编码效率;若信号源符号的概率相等,则编码效率最低。
5) 由于0与1的指定是任意的,故由上述过程编出的最佳码不是唯一的,但其平均码长是一样的,故不影响编码效率与数据压缩性能。
三、Huffman霍夫曼编码的压缩原理
我们把文件中一定位长的值看作是符号,比如把8位长的256种值,也就是字节的256种值看作是符号。我们根据这些符号在文件中出现的频率,对这些符号重新编码。对于出现次数非常多的,我们用较少的位来表示,对于出现次数非常少的,我们用较多的位来表示。这样一来,文件的一些部分位数变少了,一些部分位数变多了,由于变小的部分比变大的部分多,所以整个文件的大小还是会减小,所以文件得到了压缩。
四、Huffman霍夫曼压缩编码算法实现分析
哈夫曼编码Huffman方法于1952年问世,迄今为止仍经久不衰,广泛应用于各种数据压缩威廉希尔官方网站 中,且仍不失为熵编码中的最佳编码方法,deflate等压缩算法也是结合了huffman算法的。
采用霍夫曼编码时有两个问题值得注意:
①霍夫曼码没有错误保护功能,在译码时,如果码串中没有错误,那么就能一个接一个地正确译出代码。但如果码串中有错误,哪仅是1位出现错误,不但这个码本身译错,更糟糕的是一错一大串,全乱了套,这种现象称为错误传播(error propagation)。计算机对这种错误也无能为力,说不出错在哪里,更谈不上去纠正它。
②霍夫曼码是可变长度码,因此很难随意查找或调用压缩文件中间的内容,然后再译码,这就需要在存储代码之前加以考虑。尽管如此,霍夫曼码还是得到广泛应用。
/*
霍夫曼编码模型:思想是压缩数据出现概率高的用短编码,出现概率低的用长编码,且每个字符编码都不一样。
压缩数据单个字符出现的概率抽象为叶子节点的权值,huffman树叶子节点到根节点的编码(是父节点左子节点那么填0,否则填1)
作为字符的唯一编码。
实现时候需要注意的规则:
1)最左的放置在左边,作为父节点的左节点。
2)每次都从没有设置父节点的所用节点中(叶子和分支节点一样对待),从数组小下标到大下标优先顺序遍历。
3)当前搜寻的次数i + n作为新生成的分支节点的数组下标。
实现的过程和具体算法思想:
两个数据结构:
一个是huffman树节点结构体,一个是从霍夫曼树叶子节点编码的结构体。
两个处理过程:
1)建立huffman树:
基本思想是:对于没有设置父节点的节点集选出最小的两个,最小的放置在左边,次小的放置在右边
设置好父节点和左右子节点关系,方便获得霍夫曼编码。
2) 从huffman树得到叶子节点的huffman编码:
基本思想:对于建立好的Huffman树的每个叶子节点,由编码的数组的末端也是从叶子节点最底端,往上遍历
如果是父节点的左节点那么用编码数组填1,如果是父节点的右节点那么编码数组填0,一直往上追溯到根节点。
*/
// 以下是实现的代码,在win32编译通过。
#include “stdafx.h”
#define MAXCODELEN 7
#define MAXWEIGHT 10000
struct tagHuffmanNode
{
int m_nWeight;
int m_nParent;
int m_nLChild;
int m_nRChild;
};
struct tagHuffmanCode
{
int m_nWeight;
int m_nStart;
int m_nBit[MAXCODELEN];
};
void Huffman(int w[], int n, tagHuffmanNode ht[], tagHuffmanCode hc[])
{
int nTotalCount = 2 * n - 1;
// 初始化填充好ht的所有权值,包括叶子节点和分支节点
for(int i = 0; i 《 nTotalCount; i++)
{
if( i 《 n)
{
ht[i].m_nWeight = w[i];
}
else
{
ht[i].m_nWeight = 0;
}
ht[i].m_nParent = 0;
ht[i].m_nLChild = ht[i].m_nRChild = -1;
}
// 构造一颗huffman树,设置n-1个分支节点(非叶子),
// 基本思想是:对于没有设置父节点的节点集选出最小的两个,最小的放置在左边,次小的放置在右边
// 设置好父节点和左右子节点关系,方便获得霍夫曼编码
int nCurMinWeight,nCurSecondMinWeight;
int nCurLeftChild, nCurRightChild;
for( int i = 0; i 《 n-1; i++)
{
nCurMinWeight = nCurSecondMinWeight = MAXWEIGHT;
nCurLeftChild = nCurRightChild = 0;
// 确定一个分支节点,需要对n + i个节点进行筛选
for( int j = 0; j 《 n + i; j++)
{
if( ht[j].m_nWeight 《 nCurMinWeight && ht[j].m_nParent == 0)
{
nCurSecondMinWeight = nCurMinWeight;
nCurRightChild = nCurLeftChild;
nCurMinWeight = ht[j].m_nWeight;
nCurLeftChild = j;
}
else if(ht[j].m_nWeight 《 nCurSecondMinWeight && ht[j].m_nParent == 0)
{
nCurSecondMinWeight = ht[j].m_nWeight;
nCurRightChild = j;
}
}
// 得到分支节点,设置节点关系
ht[n + i].m_nLChild = nCurLeftChild;
ht[n + i].m_nRChild = nCurRightChild;
ht[n + i].m_nWeight =nCurMinWeight + nCurSecondMinWeight;
ht[nCurLeftChild].m_nParent = n + i;
ht[nCurRightChild].m_nParent = n + i;
}
// 测试用
/*for(int i = 0; i 《 nTotalCount; i++)
{
printf(“--------------------------------\n”);
printf(“ht[%d].m_nWeight: %d\n”, i, ht[i].m_nWeight);
printf(“ht[%d].m_nParent: %d\n”, i, ht[i].m_nParent);
printf(“ht[%d].m_nLChild: %d\n”, i, ht[i].m_nLChild);
printf(“ht[%d].m_nRChild: %d\n”, i, ht[i].m_nRChild);
}*/
// 记录下来每个叶子节点的huffman编码
// 基本思想:对于建立好的Huffman树的每个叶子节点,由编码的数组的末端也是从叶子节点最底端,往上遍历
// 如果是父节点的左节点那么用编码数组填1,如果是父节点的右节点那么编码数组填0,一直往上追溯到根节点。
for(int k = 0; k 《 n; k++)
{
hc[k].m_nWeight = ht[k].m_nWeight;
hc[k].m_nStart = n - 1;// start等于最大的值
int nChild = k;
int nParent = ht[k].m_nParent;
while(nParent != 0)
{
if(nChild == ht[nParent].m_nLChild)
{
hc[k].m_nBit[hc[k].m_nStart] = 0;
}
else if(nChild == ht[nParent].m_nRChild)
{
hc[k].m_nBit[hc[k].m_nStart] = 1;
}
hc[k].m_nStart--;
nChild = nParent;
nParent = ht[nChild].m_nParent;
}
// 因为递减了需要增加,得到正确的起始下标
hc[k].m_nStart++;
}
}
int _tmain(int argc, _TCHAR* argv[])
{
int nDataNum = 7;
int nWeigt[] = {4, 2, 6, 8, 3, 2, 1};
const int nMaxLen = 2 * nDataNum - 1;
tagHuffmanNode *ht = new tagHuffmanNode[nMaxLen];
tagHuffmanCode *hc = new tagHuffmanCode[nDataNum];
Huffman(nWeigt, nDataNum, ht, hc);
for(int i = 0; i 《 7; i++)
{
printf(“index: %d, weight: %d, hc[%d].m_nBit: ”, i, hc[i].m_nWeight, i);
for(int j = hc[i].m_nStart; j 《 7; j++)
{
printf(“%d”, hc[i].m_nBit[j]);
}
printf(“\n”);
}
delete []ht;
delete []hc;
while(1);
return 0;
}













 工商网监
工商网监
评论