 使用机器学习预测公交车延误
使用机器学习预测公交车延误
全球数亿人的日常通勤都依靠公共交通工具,其中超过半数在出行时会选择乘坐公交车。随着全球城市的不断发展,通勤一族希望了解公共交通工具尤其是公交车可能出现的延误时间,以便提前安排出行计划。因为公交车往往会遇到交通拥堵。Google 地图的公交路线实时数据由众多公共交通运营机构提供,但因威廉希尔官方网站 和资源限制,仍有许多公共交通运营机构无法提供这些信息。
近日,Google 地图为全球数百个城市(包括亚特兰大、萨格勒布、伊斯坦布尔、马尼拉等),推出了基于机器学习的实时公交延误预测服务。如此一来,六千多万人便能更准确地把握出行时间。这套系统于三周前率先在印度发布,系统采用机器学习模型,整合了实时汽车交通预测与公交路线和站台数据,以便更准确地预测公交出行的时间。
模型初探
许多城市的公共交通运营机构并不提供实时预测数据,在对这类城市的用户进行调查后,我们发现,他们借助一种巧妙方法来粗略估计公交车的延误时间:使用 Google 地图的驾驶路线功能。然而,公交车并非只是大型汽车。公交车在站台停靠,加速、减速和转弯都需要更长时间,有时甚至拥有专属道路特权(如公交专用车道)。
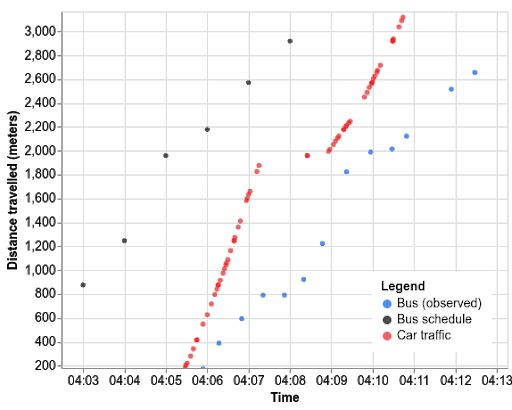
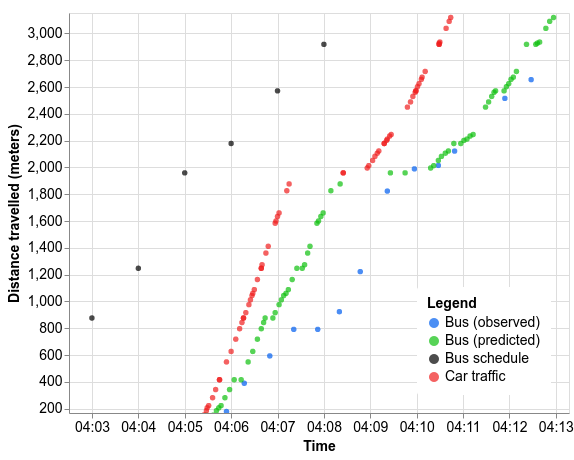
举个例子,我们于周三下午在悉尼测试了一次公交车之旅。相较于公交时刻表(黑点),公交车的实际行驶时间(蓝点)会晚几分钟。汽车行驶速度(红点)确实会对公交车造成影响,例如行驶至 2000 米处的减速情形。但与汽车相比,公交车在 800 米标记处的长时间停靠也会大大减慢自身的速度。
为了开发模型,我们从公共交通运营机构的实时反馈中获得了公交车位置序列,从中提取训练数据,并将其与汽车在公交行驶路线上的行驶速度进行调整。我们将该模型划分为时间线单元(表示在街区和站台停靠),每个单元对应一段公交车的时间线,并预测持续时间。由于报告频率低、再加上公交车行驶速度较快、街区和站台停靠时间较短,相邻的观测数据可能会跨越多个单元。
此结构非常适合于神经序列模型,如近期在语音处理和机器翻译等领域成功实现应用的模型。而我们的模型更加简单。每个单元会独立预测其持续时间,最终的输出结果为每单元预测时间的总和。
与许多序列模型不同,我们的模型并不需要学习组合单元输出,也无需通过单元序列传递状态。相反,序列结构让我们能够共同:(1) 训练一个单元持续时间的模型,(2) 优化“线性系统”,其中每条观测到的轨迹会将总持续时间分配给其跨越的所有单元。
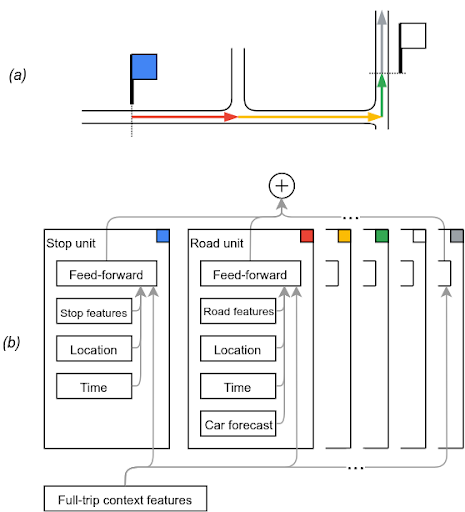
为interwetten与威廉的赔率体系 从蓝色站台开始的公交车行程 (a),模型 (b) 将蓝色站台、三个路段和白色站台等各处的时间线单元延误预测进行相加
构建“地点”模型
除了因交通拥堵导致的延误之外,我们在训练模型时还详细考虑了公交车路线,以及行程中各地点与时段的交通信号灯。
即便是在小区内,该模型也需根据各个街道的路况,以不同方式将汽车速度预测转化为公交车速度。如下方左图所示,模型预测了公交车行程中汽车与公交车速度之比,我们用不同颜色对其进行标记。
红色(表示车速较慢)的部分符合公交车在站台附近减速的实况。针对突出显示的绿色路段(表示车速较快),我们查看了相关街景,了解到该模型发现了一条公交车专用的转弯车道。顺便一提,这条路线位于澳大利亚,该国右转车速低于左转车速,而这也是不考虑地点特殊性的模型会忽略的另一方面。
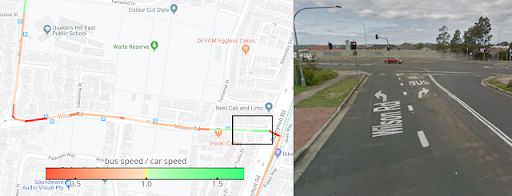
为获取特定街道、街区和城市的独特属性,我们让该模型学习不同大小区域的表示层次结构,通过地区位置的总嵌入,在模型中按不同比例表示时间线单元的地理位置(即道路或站台的精确定位)。
我们首先训练模型,对特殊情况下的细粒度位置进行逐渐加重的处罚,并使用结果进行特征选择。这样就可以确保考虑到百米影响公交行为的复杂区域中的细粒度特征,而不像开放的乡村那样细致的特征很少。
训练期间,我们还模拟了训练数据以外地区可能的后续查询。在每个训练批次中,我们会随机抽取一些示例,随机选取某一比例并丢弃地理特征。某些示例拥有准确的公交路线和街道信息,某些仅包含街区或城市位置,还有一些则没有任何地理环境信息。如此一来,模型便能做好充足准备,从而在后续查询训练数据不足的地区。我们通过匿名用户的公交行程,并使用与 Google 地图在商业繁忙、停车难度及其他特征的相同数据集,来扩展我们的培训语料库覆盖范围。然而,即使是这类数据也无法涵盖全球大部分公交路线,因此我们必须大幅提升模型的泛化能力,使其适应更多新地区。
学习地方性节奏
不同城市和街区的运转节奏各有差异,因此我们让模型将其位置表示与时间信号进行结合。
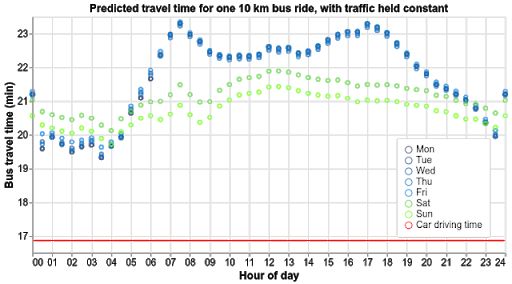
公交车对时间的依赖包含不同情形:周二下午 6:30 至 6:45,一些街区的下班高峰可能已逐渐淡去,另一些街区可能在忙于用餐,而冷清的小镇可能已是万籁俱寂。我们的模型学习嵌入了局部地区的当日时间与星期信号,当此类信号与地点表示相结合时,模型便可获取显著的局部地区变化(如上下班高峰期在公交站台等候的人群),而我们无法通过交通情况观测这类变化。
这种嵌入会向一天的时间分配四维向量。与大多数神经网络内部架构不同,四维空间几乎无法实现可视化。因此,让我们以如下所示的艺术渲染图为例,向您展示此模型如何在其中的三个维度内安排一天的时间。此模型确实知道时间具有周期性,因而会将其放在“循环”内。但此循环并非只是时钟表面的平面圆环。
此模型学习了大量弯曲 (wide bends),让其他神经元组成简单的规则,以轻松区分“午夜”或“傍午”等概念。而在此类概念中,公交车的行驶状态不会产生太大变化。另一方面,不同街区和城市的夜间通勤模式差异甚大。针对下午 4 点至晚上 9 点之间的时段,模型似乎创建了更复杂的“折皱”模式,从而能对每个城市的高峰时间进行更复杂的推理。
效果图作者:Will Cassella,所用贴图来源:textures.com,所用 HERI 来源:hdrihaven。模型的时间表示(四维空间中的三个维度)形成循环,在此处您可以将其重新想象成手表的表盘。越依赖位置的时间窗口(如下午 4 点至 9 点,上午 7 点至 9 点)会获得更复杂的“折皱”,而没有特征的大窗口(如凌晨 2 点至 5点)则会发生平面弯曲,进而生成更简单的规则。
借助此时间表示与其他信号,我们可在车速恒定的情况下预测复杂模式。例如,在乘坐公交车完成新泽西州的 10 公里行程时,我们的模型能够了解午餐时间的人群状况以及工作日的高峰时段:
全面整合
在对模型进行充分训练后,让我们看看它对上例中悉尼公交车之旅的了解程度。
如果基于当日的车辆交通数据运行模型,我们会得到如下所示的绿色预测点(该模型无法获取所有信息,例如,模型检测到公交车在 800 米仅停靠了 10 秒,而实际的停靠时间为 31 秒多)。与公交时刻表和汽车行驶时间相比,我们的预测与公交车实际运行时间的差异相对较小,为 1.5 分钟。
未来行程
目前,我们的模型尚缺一类数据,即公交时刻表。截止目前,经试验证明,官方机构提供的公交车时刻表尚无法对我们的预测做出显著改进。在某些城市,变化无常的交通状况可能会打乱出行计划。而在其他城市,公交车时刻表则非常精准,这或许是因为当地公共交通运营机构仔细考虑了本地的交通状况。而我们可以从数据中推断出这些。
我们将继续进行实验,更好地考虑行程限制和其他影响因素,从而推动更精确的预测,为用户的出行计划提供便利。此外,我们希望能为您的出行计划提供帮助。祝您旅途愉快!
-
Google
+关注
关注
5文章
1762浏览量
57509 -
机器学习
+关注
关注
66文章
8408浏览量
132580
原文标题:使用机器学习预测公交车延误
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
中车鲸典客车批量交付1032辆
多场景有序充电:驱动公交绿色低碳转型的新引擎

亿纬锂能与远程新能源商用车合作共塑杭州绿色公交新风貌
城市公交充电站设计策略与综合解决方案探讨

【《时间序列与机器学习》阅读体验】+ 时间序列的信息提取
【「时间序列与机器学习」阅读体验】+ 简单建议
【《时间序列与机器学习》阅读体验】+ 了解时间序列
公交车安全与监控:车载监控的应用与发展
机器学习的经典算法与应用

浅谈电动公交充电站预制舱式储能系统设计方案研究
国内首批!行业唯一!苏州金龙超充纯电公交车正式投运张家港
欧洲议会批准“欧7”汽车监管标准,强制纯电、混合动力汽车采用电动威廉希尔官方网站
公交站配电箱安装安全用电监测终端,实时监测公交车站配电系统漏电电流
公交站安全用电云平台-实时监测公交车站配电系统漏电电流及水浸状态Acrelsale1
公交站安全用电云平台





 工商网监
工商网监
评论