 机器学习算法优缺点对比及选择
机器学习算法优缺点对比及选择
机器学习算法太多了,分类、回归、聚类、推荐、图像识别领域等等,要想找到一个合适算法真的不容易,所以在实际应用中,我们一般都是采用启发式学习方式来实验。通常最开始我们都会选择大家普遍认同的算法,诸如SVM,GBDT,Adaboost,现在深度学习很火热,神经网络也是一个不错的选择。
假如你在乎精度(accuracy)的话,最好的方法就是通过交叉验证(cross-validation)对各个算法一个个地进行测试,进行比较,然后调整参数确保每个算法达到最优解,最后选择最好的一个。但是如果你只是在寻找一个“足够好”的算法来解决你的问题,或者这里有些技巧可以参考,下面来分析下各个算法的优缺点,基于算法的优缺点,更易于我们去选择它。
1.天下没有免费的午餐
在机器学习领域,一个基本的定理就是“没有免费的午餐”。换言之,就是没有算法能完美地解决所有问题,尤其是对监督学习而言(例如预测建模)。
举例来说,你不能去说神经网络任何情况下都能比决策树更有优势,反之亦然。它们要受很多因素的影响,比如你的数据集的规模或结构。
其结果是,在用给定的测试集来评估性能并挑选算法时,你应当根据具体的问题来采用不同的算法。
当然,所选的算法必须要适用于你自己的问题,这就要求选择正确的机器学习任务。作为类比,如果你需要打扫房子,你可能会用到吸尘器、扫帚或是拖把,但你绝对不该掏出铲子来挖地。
2. 偏差&方差
在统计学中,一个模型好坏,是根据偏差和方差来衡量的,所以我们先来普及一下偏差(bias)和方差(variance):
偏差:描述的是预测值(估计值)的期望E’与真实值Y之间的差距。偏差越大,越偏离真实数据。
![]()
方差:描述的是预测值P的变化范围,离散程度,是预测值的方差,也就是离其期望值E的距离。方差越大,数据的分布越分散。
![]()
模型的真实误差是两者之和,如公式:
![]()
通常情况下,如果是小训练集,高偏差/低方差的分类器(例如,朴素贝叶斯NB)要比低偏差/高方差大分类的优势大(例如,KNN),因为后者会发生过拟合(overfiting)。然而,随着你训练集的增长,模型对于原数据的预测能力就越好,偏差就会降低,此时低偏差/高方差的分类器就会渐渐的表现其优势(因为它们有较低的渐近误差),而高偏差分类器这时已经不足以提供准确的模型了。
为什么说朴素贝叶斯是高偏差低方差?
以下内容引自知乎:
首先,假设你知道训练集和测试集的关系。简单来讲是我们要在训练集上学习一个模型,然后拿到测试集去用,效果好不好要根据测试集的错误率来衡量。但很多时候,我们只能假设测试集和训练集的是符合同一个数据分布的,但却拿不到真正的测试数据。这时候怎么在只看到训练错误率的情况下,去衡量测试错误率呢?
由于训练样本很少(至少不足够多),所以通过训练集得到的模型,总不是真正正确的。(就算在训练集上正确率100%,也不能说明它刻画了真实的数据分布,要知道刻画真实的数据分布才是我们的目的,而不是只刻画训练集的有限的数据点)。而且,实际中,训练样本往往还有一定的噪音误差,所以如果太追求在训练集上的完美而采用一个很复杂的模型,会使得模型把训练集里面的误差都当成了真实的数据分布特征,从而得到错误的数据分布估计。这样的话,到了真正的测试集上就错的一塌糊涂了(这种现象叫过拟合)。但是也不能用太简单的模型,否则在数据分布比较复杂的时候,模型就不足以刻画数据分布了(体现为连在训练集上的错误率都很高,这种现象较欠拟合)。过拟合表明采用的模型比真实的数据分布更复杂,而欠拟合表示采用的模型比真实的数据分布要简单。
在统计学习框架下,大家刻画模型复杂度的时候,有这么个观点,认为Error = Bias + Variance。这里的Error大概可以理解为模型的预测错误率,是有两部分组成的,一部分是由于模型太简单而带来的估计不准确的部分(Bias),另一部分是由于模型太复杂而带来的更大的变化空间和不确定性(Variance)。
所以,这样就容易分析朴素贝叶斯了。它简单的假设了各个数据之间是无关的,是一个被严重简化了的模型。所以,对于这样一个简单模型,大部分场合都会Bias部分大于Variance部分,也就是说高偏差而低方差。
在实际中,为了让Error尽量小,我们在选择模型的时候需要平衡Bias和Variance所占的比例,也就是平衡over-fitting和under-fitting。
当模型复杂度上升的时候,偏差会逐渐变小,而方差会逐渐变大。
3. 常见算法优缺点
3.1 朴素贝叶斯
朴素贝叶斯属于生成式模型(关于生成模型和判别式模型,主要还是在于是否需要求联合分布),比较简单,你只需做一堆计数即可。如果注有条件独立性假设(一个比较严格的条件),朴素贝叶斯分类器的收敛速度将快于判别模型,比如逻辑回归,所以你只需要较少的训练数据即可。即使NB条件独立假设不成立,NB分类器在实践中仍然表现的很出色。它的主要缺点是它不能学习特征间的相互作用,用mRMR中R来讲,就是特征冗余。引用一个比较经典的例子,比如,虽然你喜欢Brad Pitt和Tom Cruise的电影,但是它不能学习出你不喜欢他们在一起演的电影。
优点:
朴素贝叶斯模型发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。
对大数量训练和查询时具有较高的速度。即使使用超大规模的训练集,针对每个项目通常也只会有相对较少的特征数,并且对项目的训练和分类也仅仅是特征概率的数学运算而已;
对小规模的数据表现很好,能个处理多分类任务,适合增量式训练(即可以实时的对新增的样本进行训练);
对缺失数据不太敏感,算法也比较简单,常用于文本分类;
朴素贝叶斯对结果解释容易理解;
缺点:
需要计算先验概率;
分类决策存在错误率;
对输入数据的表达形式很敏感;
由于使用了样本属性独立性的假设,所以如果样本属性有关联时其效果不好;
朴素贝叶斯应用领域
欺诈检测中使用较多
一封电子邮件是否是垃圾邮件
一篇文章应该分到科技、政治,还是体育类
一段文字表达的是积极的情绪还是消极的情绪?
人脸识别
3.2 Logistic Regression(逻辑回归)
逻辑回归属于判别式模型,同时伴有很多模型正则化的方法(L0, L1,L2,etc),而且你不必像在用朴素贝叶斯那样担心你的特征是否相关。与决策树、SVM相比,你还会得到一个不错的概率解释,你甚至可以轻松地利用新数据来更新模型(使用在线梯度下降算法-online gradient descent)。如果你需要一个概率架构(比如,简单地调节分类阈值,指明不确定性,或者是要获得置信区间),或者你希望以后将更多的训练数据快速整合到模型中去,那么使用它吧。
Sigmoid函数:表达式如下:
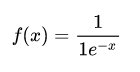
优点:
实现简单,广泛的应用于工业问题上;
分类时计算量非常小,速度很快,存储资源低;
便利的观测样本概率分数;
对逻辑回归而言,多重共线性并不是问题,它可以结合L2正则化来解决该问题;
计算代价不高,易于理解和实现;
缺点:
当特征空间很大时,逻辑回归的性能不是很好;
容易欠拟合,一般准确度不太高
不能很好地处理大量多类特征或变量;
只能处理两分类问题(在此基础上衍生出来的softmax可以用于多分类),且必须线性可分;
对于非线性特征,需要进行转换;
logistic回归应用领域:
用于二分类领域,可以得出概率值,适用于根据分类概率排名的领域,如搜索排名等。
Logistic回归的扩展softmax可以应用于多分类领域,如手写字识别等。
信用评估
测量市场营销的成功度
预测某个产品的收益
特定的某天是否会发生地震
3.3 线性回归
线性回归是用于回归的,它不像Logistic回归那样用于分类,其基本思想是用梯度下降法对最小二乘法形式的误差函数进行优化,当然也可以用normal equation直接求得参数的解,结果为:![]()
而在LWLR(局部加权线性回归)中,参数的计算表达式为: ![]()
由此可见LWLR与LR不同,LWLR是一个非参数模型,因为每次进行回归计算都要遍历训练样本至少一次。
优点:实现简单,计算简单;
缺点:不能拟合非线性数据。
3.4 最近邻算法——KNN
KNN即最近邻算法,其主要过程为:
1. 计算训练样本和测试样本中每个样本点的距离(常见的距离度量有欧式距离,马氏距离等);2. 对上面所有的距离值进行排序(升序);3. 选前k个最小距离的样本;4. 根据这k个样本的标签进行投票,得到最后的分类类别;
如何选择一个最佳的K值,这取决于数据。一般情况下,在分类时较大的K值能够减小噪声的影响,但会使类别之间的界限变得模糊。一个较好的K值可通过各种启发式威廉希尔官方网站 来获取,比如,交叉验证。另外噪声和非相关性特征向量的存在会使K近邻算法的准确性减小。近邻算法具有较强的一致性结果,随着数据趋于无限,算法保证错误率不会超过贝叶斯算法错误率的两倍。对于一些好的K值,K近邻保证错误率不会超过贝叶斯理论误差率。
KNN算法的优点
理论成熟,思想简单,既可以用来做分类也可以用来做回归;
可用于非线性分类;
训练时间复杂度为O(n);
对数据没有假设,准确度高,对outlier不敏感;
KNN是一种在线威廉希尔官方网站 ,新数据可以直接加入数据集而不必进行重新训练;
KNN理论简单,容易实现;
缺点
样本不平衡问题(即有些类别的样本数量很多,而其它样本的数量很少)效果差;
需要大量内存;
对于样本容量大的数据集计算量比较大(体现在距离计算上);
样本不平衡时,预测偏差比较大。如:某一类的样本比较少,而其它类样本比较多;
KNN每一次分类都会重新进行一次全局运算;
k值大小的选择没有理论选择最优,往往是结合K-折交叉验证得到最优k值选择;
KNN算法应用领域
文本分类、模式识别、聚类分析,多分类领域
3.5 决策树
决策树的一大优势就是易于解释。它可以毫无压力地处理特征间的交互关系并且是非参数化的,因此你不必担心异常值或者数据是否线性可分(举个例子,决策树能轻松处理好类别A在某个特征维度x的末端,类别B在中间,然后类别A又出现在特征维度x前端的情况)。它的缺点之一就是不支持在线学习,于是在新样本到来后,决策树需要全部重建。另一个缺点就是容易出现过拟合,但这也就是诸如随机森林RF(或提升树boosted tree)之类的集成方法的切入点。另外,随机森林经常是很多分类问题的赢家(通常比支持向量机好上那么一丁点),它训练快速并且可调,同时你无须担心要像支持向量机那样调一大堆参数,所以在以前都一直很受欢迎。
决策树中很重要的一点就是选择一个属性进行分枝,因此要注意一下信息增益的计算公式,并深入理解它。
信息熵的计算公式如下:
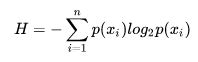
其中的n代表有n个分类类别(比如假设是二类问题,那么n=2)。分别计算这2类样本在总样本中出现的概率 和 ,这样就可以计算出未选中属性分枝前的信息熵。
现在选中一个属性 用来进行分枝,此时分枝规则是:如果 的话,将样本分到树的一个分支;如果不相等则进入另一个分支。很显然,分支中的样本很有可能包括2个类别,分别计算这2个分支的熵 和 ,计算出分枝后的总信息熵 ,则此时的信息增益 。以信息增益为原则,把所有的属性都测试一边,选择一个使增益最大的属性作为本次分枝属性。
决策树自身的优点
决策树易于理解和解释,可以可视化分析,容易提取出规则;
可以同时处理标称型和数值型数据;
比较适合处理有缺失属性的样本;
能够处理不相关的特征;
测试数据集时,运行速度比较快;
在相对短的时间内能够对大型数据源做出可行且效果良好的结果。
缺点
容易发生过拟合(随机森林可以很大程度上减少过拟合);
容易忽略数据集中属性的相互关联;
对于那些各类别样本数量不一致的数据,在决策树中,进行属性划分时,不同的判定准则会带来不同的属性选择倾向;信息增益准则对可取数目较多的属性有所偏好(典型代表ID3算法),而增益率准则(CART)则对可取数目较少的属性有所偏好,但CART进行属性划分时候不再简单地直接利用增益率尽心划分,而是采用一种启发式规则)(只要是使用了信息增益,都有这个缺点,如RF)。
ID3算法计算信息增益时结果偏向数值比较多的特征。
改进措施
对决策树进行剪枝。可以采用交叉验证法和加入正则化的方法。
使用基于决策树的combination算法,如bagging算法,randomforest算法,可以解决过拟合的问题;
应用领域
企业管理实践,企业投资决策,由于决策树很好的分析能力,在决策过程应用较多。
3.5.1 ID3、C4.5算法
ID3算法是以信息论为基础,以信息熵和信息增益度为衡量标准,从而实现对数据的归纳分类。ID3算法计算每个属性的信息增益,并选取具有最高增益的属性作为给定的测试属性。C4.5算法核心思想是ID3算法,是ID3算法的改进,改进方面有:- 用信息增益率来选择属性,克服了用信息增益选择属性时偏向选择取值多的属性的不足;- 在树构造过程中进行剪枝;- 能处理非离散的数据;- 能处理不完整的数据。
优点
产生的分类规则易于理解,准确率较高。
缺点
在构造树的过程中,需要对数据集进行多次的顺序扫描和排序,因而导致算法的低效;
C4.5只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时程序无法运行。
3.5.2 CART分类与回归树
是一种决策树分类方法,采用基于最小距离的基尼指数估计函数,用来决定由该子数据集生成的决策树的拓展形。如果目标变量是标称的,称为分类树;如果目标变量是连续的,称为回归树。分类树是使用树结构算法将数据分成离散类的方法。
优点
1)非常灵活,可以允许有部分错分成本,还可指定先验概率分布,可使用自动的成本复杂性剪枝来得到归纳性更强的树。2)在面对诸如存在缺失值、变量数多等问题时CART 显得非常稳健。
3.6 Adaboosting
Adaboost是一种加和模型,每个模型都是基于上一次模型的错误率来建立的,过分关注分错的样本,而对正确分类的样本减少关注度,逐次迭代之后,可以得到一个相对较好的模型。该算法是一种典型的boosting算法,其加和理论的优势可以使用Hoeffding不等式得以解释。有兴趣的同学可以阅读下自己之前写的这篇文章AdaBoost算法详述。下面总结下它的优缺点。
优点
Adaboost是一种有很高精度的分类器。
可以使用各种方法构建子分类器,Adaboost算法提供的是框架。
当使用简单分类器时,计算出的结果是可以理解的,并且弱分类器的构造极其简单。
简单,不用做特征筛选。
不易发生overfitting。
关于Adaboost, GBDT 及 XGBoost 算法区别,参考这篇文章:Adaboost、GBDT与XGBoost的区别
缺点
对outlier比较敏感
3.7 SVM支持向量机
支持向量机,一个经久不衰的算法,高准确率,为避免过拟合提供了很好的理论保证,而且就算数据在原特征空间线性不可分,只要给个合适的核函数,它就能运行得很好。在动辄超高维的文本分类问题中特别受欢迎。可惜内存消耗大,难以解释,运行和调参也有些烦人,而随机森林却刚好避开了这些缺点,比较实用。
优点
可以解决高维问题,即大型特征空间;
解决小样本下机器学习问题;
能够处理非线性特征的相互作用;
无局部极小值问题;(相对于神经网络等算法)
无需依赖整个数据;
泛化能力比较强;
缺点
当观测样本很多时,效率并不是很高;
对非线性问题没有通用解决方案,有时候很难找到一个合适的核函数;
对于核函数的高维映射解释力不强,尤其是径向基函数;
常规SVM只支持二分类;
对缺失数据敏感;
对于核的选择也是有技巧的(libsvm中自带了四种核函数:线性核、多项式核、RBF以及sigmoid核):
第一,如果样本数量小于特征数,那么就没必要选择非线性核,简单的使用线性核就可以了;
第二,如果样本数量大于特征数目,这时可以使用非线性核,将样本映射到更高维度,一般可以得到更好的结果;
第三,如果样本数目和特征数目相等,该情况可以使用非线性核,原理和第二种一样。
对于第一种情况,也可以先对数据进行降维,然后使用非线性核,这也是一种方法。
SVM应用领域
文本分类、图像识别(主要二分类领域,毕竟常规SVM只能解决二分类问题)
3.8 人工神经网络的优缺点
人工神经网络的优点:
分类的准确度高;
并行分布处理能力强,分布存储及学习能力强,
对噪声神经有较强的鲁棒性和容错能力;
具备联想记忆的功能,能充分逼近复杂的非线性关系;
人工神经网络的缺点:
神经网络需要大量的参数,如网络拓扑结构、权值和阈值的初始值;
黑盒过程,不能观察之间的学习过程,输出结果难以解释,会影响到结果的可信度和可接受程度;
学习时间过长,有可能陷入局部极小值,甚至可能达不到学习的目的。
人工神经网络应用领域:
目前深度神经网络已经应用与计算机视觉,自然语言处理,语音识别等领域并取得很好的效果。
3.9 K-Means聚类
是一个简单的聚类算法,把n的对象根据他们的属性分为k个分割,k《 n。算法的核心就是要优化失真函数J,使其收敛到局部最小值但不是全局最小值。
关于K-Means聚类的文章,参见机器学习算法-K-means聚类。关于K-Means的推导,里面可是有大学问的,蕴含着强大的EM思想。
优点
算法简单,容易实现 ;
算法速度很快;
对处理大数据集,该算法是相对可伸缩的和高效率的,因为它的复杂度大约是O(nkt),其中n是所有对象的数目,k是簇的数目,t是迭代的次数。通常k《《n。这个算法通常局部收敛。
算法尝试找出使平方误差函数值最小的k个划分。当簇是密集的、球状或团状的,且簇与簇之间区别明显时,聚类效果较好。
缺点
对数据类型要求较高,适合数值型数据;
可能收敛到局部最小值,在大规模数据上收敛较慢
分组的数目k是一个输入参数,不合适的k可能返回较差的结果。
对初值的簇心值敏感,对于不同的初始值,可能会导致不同的聚类结果;
不适合于发现非凸面形状的簇,或者大小差别很大的簇。
对于”噪声”和孤立点数据敏感,少量的该类数据能够对平均值产生极大影响。
3.10 EM最大期望算法
EM算法是基于模型的聚类方法,是在概率模型中寻找参数最大似然估计的算法,其中概率模型依赖于无法观测的隐藏变量。E步估计隐含变量,M步估计其他参数,交替将极值推向最大。
EM算法比K-means算法计算复杂,收敛也较慢,不适于大规模数据集和高维数据,但比K-means算法计算结果稳定、准确。EM经常用在机器学习和计算机视觉的数据集聚(Data Clustering)领域。
3.11 集成算法(AdaBoost算法)
AdaBoost算法优点:
很好的利用了弱分类器进行级联;
可以将不同的分类算法作为弱分类器;
AdaBoost具有很高的精度;
相对于bagging算法和Random Forest算法,AdaBoost充分考虑的每个分类器的权重;
Adaboost算法缺点:
AdaBoost迭代次数也就是弱分类器数目不太好设定,可以使用交叉验证来进行确定;
数据不平衡导致分类精度下降;
训练比较耗时,每次重新选择当前分类器最好切分点;
AdaBoost应用领域:
模式识别、计算机视觉领域,用于二分类和多分类场景
3.12 排序算法(PageRank)
PageRank是google的页面排序算法,是基于从许多优质的网页链接过来的网页,必定还是优质网页的回归关系,来判定所有网页的重要性。(也就是说,一个人有着越多牛X朋友的人,他是牛X的概率就越大。)
PageRank优点
完全独立于查询,只依赖于网页链接结构,可以离线计算。
PageRank缺点
PageRank算法忽略了网页搜索的时效性。
旧网页排序很高,存在时间长,积累了大量的in-links,拥有最新资讯的新网页排名却很低,因为它们几乎没有in-links。
3.13 关联规则算法(Apriori算法)
Apriori算法是一种挖掘关联规则的算法,用于挖掘其内含的、未知的却又实际存在的数据关系,其核心是基于两阶段频集思想的递推算法 。
Apriori算法分为两个阶段:
寻找频繁项集
由频繁项集找关联规则
算法缺点:
在每一步产生侯选项目集时循环产生的组合过多,没有排除不应该参与组合的元素;
每次计算项集的支持度时,都对数据库中 的全部记录进行了一遍扫描比较,需要很大的I/O负载。
4. 算法选择参考
之前笔者翻译过一些国外的文章,其中有一篇文章中给出了一个简单的算法选择技巧:
首当其冲应该选择的就是逻辑回归,如果它的效果不怎么样,那么可以将它的结果作为基准来参考,在基础上与其他算法进行比较;
然后试试决策树(随机森林)看看是否可以大幅度提升你的模型性能。即便最后你并没有把它当做为最终模型,你也可以使用随机森林来移除噪声变量,做特征选择;
如果特征的数量和观测样本特别多,那么当资源和时间充足时(这个前提很重要),使用SVM不失为一种选择。
通常情况下:【GBDT》=SVM》=RF》=Adaboost》=Other…】,现在深度学习很热门,很多领域都用到,它是以神经网络为基础的,目前笔者自己也在学习,只是理论知识不扎实,理解的不够深入,这里就不做介绍了,希望以后可以写一片抛砖引玉的文章。
算法固然重要,但好的数据却要优于好的算法,设计优良特征是大有裨益的。假如你有一个超大数据集,那么无论你使用哪种算法可能对分类性能都没太大影响(此时就可以根据速度和易用性来进行抉择)。
-
算法
+关注
关注
23文章
4612浏览量
92901
原文标题:机器学习算法优缺点对比及选择(汇总篇)
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论