 谷歌研究人员利用3D卷积网络打造视频生成新系统
谷歌研究人员利用3D卷积网络打造视频生成新系统
谷歌研究人员利用3D卷积网络打造视频生成新系统,只需要视频的第一帧和最后一帧,就能生成完整合理的整段视频,是不是很神奇?
漫画书秒变动画片了解一下?
想象一下,现在你的手中有一段视频的第一帧和最后一帧图像,让你负责把中间的图像填进去,生成完整的视频,从现有的有限信息中推断出整个视频。你能做到吗?
这可能听起来像是一项不可能完成的任务,但谷歌人工智能研究部门的研究人员已经开发出一种新系统,可以由视频第一帧和最后一帧生成“似是而非的”视频序列,这个过程被称为“inbetween”。
“想象一下,如果我们能够教一个智能系统来将漫画自动变成动画,会是什么样子?如果真实现了这一点,无疑将彻底改变动画产业。“该论文的共同作者写道。“虽然这种极其节省劳动力的能力仍然超出目前最先进的水平,但计算机视觉和机器学习威廉希尔官方网站 的进步正在使这个目标的实现越来越接近。”
原理与模型结构
这套AI系统包括一个完全卷积模型,这是是受动物视觉皮层启发打造的深度神经网络,最常用于分析视觉图像。它由三个部分组成:2D卷积图像解码器,3D卷积潜在表示生成器,以及视频生成器。
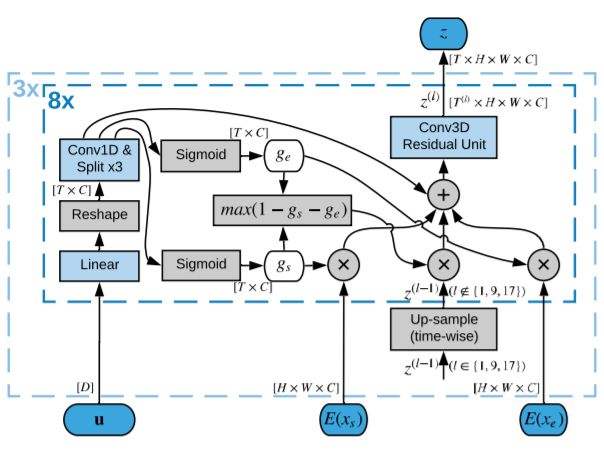
图1:视频生成模型示意图
图像解码器将来自目标视频的帧映射到潜在空间,潜在表示生成器学习对包含在输入帧中的信息进行合并。最后,视频生成器将潜在表示解码为视频中的帧。
研究人员表示,将潜在表示生成与视频解码分离对于成功实现中间视频至关重要,直接用开始帧和结束帧的编码表示生成视频的结果很差。为了解决这个问题,研究人员设计了潜在表示生成器,对帧的表示进行融合,并逐步增加生成视频的分辨率。
图2:模型生成的视频帧序列图,对于每个数据集上方的图表示模型生成的序列,下方为原视频,其中首帧和尾帧用于生成模型的采样。
实验结果
为了验证该方法,研究人员从三个数据集中获取视频 - BAIR机器人推送,KTH动作数据库和UCF101动作识别数据集 - 并将这些数据下采样至64 x 64像素的分辨率。每个样本总共包含16帧,其中的14帧由AI系统负责生成。
研究人员为每对视频帧运行100次模型,并对每个模型变量和数据集重复10次,在英伟达Tesla V100显卡平台上的训练时间约为5天。结果如下表所示:

表1:我们报告了完整模型和两个基线的平均FVD,对每个模型和数据集重复10次,每次运行100个epoch,表中FVD值越低,表示对应生成视频的质量越高。
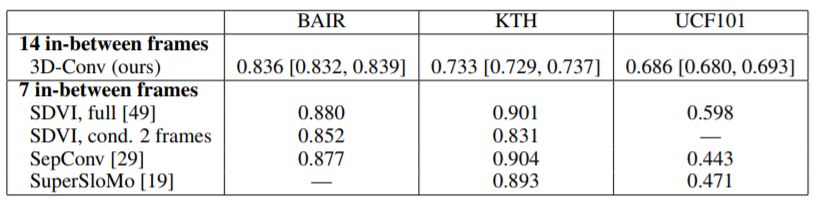
表2:使用直接3D卷积和基于的替代方法的模型的平均SSIM
RNN(SDVI)或光流(SepConv和SuperSloMo),数值越高越好。
研究人员表示,AI生成的视频帧序列在风格上与给定的起始帧和结束帧保持一致,而且看上去说得通。“令人惊喜的是,这种方法可以在如此长的时间段内实现视频生成,”该团队表示,“这可能给未来的视频生成威廉希尔官方网站 研究提供了一个有用的替代视角。”
-
解码器
+关注
关注
9文章
1143浏览量
40737 -
谷歌
+关注
关注
27文章
6167浏览量
105356 -
智能系统
+关注
关注
2文章
394浏览量
72451
原文标题:谷歌AI动画接龙:只用头尾两帧图像,片刻生成完整视频!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenAI开放Sora视频生成模型
欢创播报 腾讯元宝首发3D生成应用

奥比中光3D相机打造高质量、低成本的3D动作捕捉与3D动画内容生成方案
Runway发布Gen-3 Alpha视频生成模型
谷歌发布全新视频生成模型Veo与Imagen文生图模型
阿里云视频生成威廉希尔官方网站 创新!视频生成使用了哪些AI威廉希尔官方网站 和算法
NVIDIA生成式AI研究实现在1秒内生成3D形状

Stability AI推出Stable Video 3D模型,可制作多视角3D视频
openai发布首个视频生成模型sora
AI视频年大爆发!2023年AI视频生成领域的现状全盘点






 工商网监
工商网监
评论