 如何解决人工智能应用中数据隐私保护带来的挑战?
如何解决人工智能应用中数据隐私保护带来的挑战?
近日,在百大人物峰会上,创新工场创始人李开复谈及数据隐私保护和监管问题时,表示:“人们不应该只将人工智能带来的隐私问题视为一个监管问题,可尝试用‘以子之矛攻己之盾’——用更好的威廉希尔官方网站 解决威廉希尔官方网站 带来的挑战,例如同态加密、联邦学习等威廉希尔官方网站 。”
那么最近备受关注、被越来越多提及的联邦学习是什么?如何解决人工智能应用中数据隐私保护带来的挑战?
▌“联邦学习”到底是什么?能解决什么问题?
在回答 “联邦学习” 是什么之前,我们需要了解为什么会有这样的威廉希尔官方网站 出现,它的出现是为了解决什么问题。
近年来,随着人工智能威廉希尔官方网站 的发展和更广泛的应用,数据隐私保护也被越来越多地关注,欧盟出台了首个关于数据隐私保护的法案《通用数据保护条例》(General Data Protection Regulation, GDPR),明确了对数据隐私保护的若干规定,中国在 2017 年起实施的《中华人民共和国网络安全法》和《中华人民共和国民法总则》中也指出 “网络运营者不得泄露、篡改、毁坏其收集的个人信息,并且与第三方进行数据交易时需确保拟定的合同明确约定拟交易数据的范围和数据保护义务。” 这意味着对于用户数据的收集必须公开、透明,企业、机构之间在没有用户授权的情况下数据不能交换。
这给人工智能应用给机器学习带来的挑战是:如果机构之间的数据无法互通,一家企业一家机构数据量有限,或者是少数巨头公司垄断大量数据,而小公司很难获得数据,形成大大小小的“数据孤岛”。在这种没有权限获得足够多的用户数据的情况下,各个公司尤其是小公司,如何建模?
在这种情况下,“联邦学习”的概念应运而生。所谓 “联邦学习”,首先是一个“联邦”。不同于企业之前的“各自为政”,拥有独立的数据和独立的模型,联邦学习通过将企业、机构纳入“一个国家、一个联邦政府” 之下,将不同的企业看作是这个国家里的 “州”,彼此又保持一定的独立自主,在数据不共享的情况下共同建模,提升模型效果。所以“联邦学习” 实际上是一种加密的分布式机器学习威廉希尔官方网站 ,参与各方可以在不披露底层数据和底层数据的加密(混淆)形态的前提下共建模型。
Google 公司率先提出了基于个人终端设备的“横向联邦学习”(Horizontal Federated Learning),其核心是,手机在本地进行模型训练,然后仅将模型更新的部分加密上传到云端,并与其他用户的进行整合。目前该方法已在 Google 输入法中进行实验。一些研究者也提出了 CryptoDL 深度学习框架、可扩展的加密深度方法、针对于逻辑回归方法的隐私保护等。但是,它们或只能针对于特定模型,或无法处理不同分布数据,均存在一定的弊端。
在国内,联邦威廉希尔官方网站 的研究由微众银行首席人工智能官(CAIO)杨强教授带领微众银行 AI 团队主导,并且首次提出了基于 “联邦学习” 的系统性的通用解决方案,强调在任何数据分布、任何实体上,均可以进行协同建模学习,解决个人 (to C) 和公司间 (to B) 联合建模的问题,开启了将联邦学习威廉希尔官方网站 进行商用,建立联邦行业生态的探索。
▌如何在保护数据隐私前提下打破数据孤岛?
因为孤岛数据具有不同的分布特点,所以在联邦学习的威廉希尔官方网站 方案中,也大致分为:横向联邦学习、纵向联邦学习、联邦迁移学习三种方案。
考虑有多个数据拥有方,每个数据拥有方各自所持有的数据集 Di 可以用一个矩阵来表示。矩阵的每一行代表一个用户,每一列代表一种用户特征。同时,某些数据集可能还包含标签数据。如果要对用户行为建立预测模型,就必须要有标签数据。可以把用户特征定义为 X,把标签特征定义为 Y。
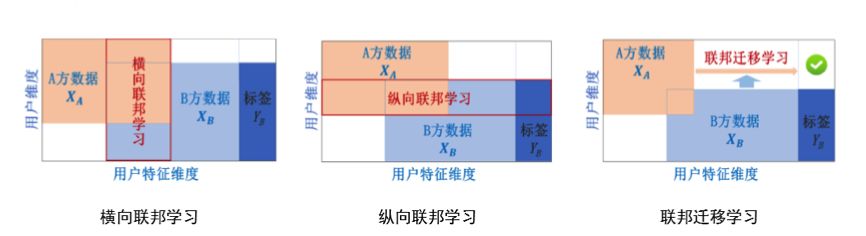
比如,在金融领域,用户的信用是需要被预测的标签 Y;在营销领域,标签是用户的购买愿望 Y;在教育领域,则是学生掌握知识的程度等。用户特征 X 加标签 Y 构成了完整的训练数据(X,Y)。但是,在现实中,往往会遇到这样的情况:各个数据集的用户不完全相同,或用户特征不完全相同。具体而言,以包含两个数据拥有方的联邦学习为例,数据分布可以分为以下三种情况:两个数据集的用户特征(X1,X2,…)重叠部分较大,而用户 (U1,U2…) 重叠部分较小;两个数据集的用户 (U1,U2…) 重叠部分较大,而用户特征(X1,X2,…)重叠部分较小;两个数据集的用户 (U1,U2…) 与用户特征重叠(X1,X2,…)部分都比较小。
可以看出,联邦迁移学习解决了不同样本(数据集)、不同特征维度之前联合建模的问题,第一次让不同领域的企业之间在保护彼此数据隐私的前提下实现跨领域创造价值。例如,银行拥有用户购买能力的特征,社交平台拥有用户个人偏好特征,而电商平台则拥有产品特点的特征,传统的机器学习模型无法直接在异构数据上进行学习,联邦学习却能在保护三方数据隐私的基础上进行联合建模,从而打破数据壁垒,构建跨领域合作。
为了更加清楚方案背后的逻辑,以包含两个数据拥有方(即企业 A 和 B)的场景为例来介绍联邦学习的系统构架,这个架构可以拓展延伸到包含多个数据拥有方的场景。
假设企业 A 和 B 想联合训练一个机器学习模型,它们的业务系统分别拥有各自用户的相关数据。此外,企业 B 还拥有模型需要预测的标签数据。出于数据隐私和安全考虑,A 和 B 无法直接进行数据交换。此时,可使用联邦学习系统建立模型,系统构架由两部分构成,如图 a 所示。

图:联邦学习系统构架
第一部分:加密样本对齐。由于两家企业的用户群体并非完全重合,系统利用基于加密的用户样本对齐威廉希尔官方网站 ,在 A 和 B 不公开各自数据的前提下确认双方的共有用户,并且不暴露不互相重叠的用户。以便联合这些用户的特征进行建模。
第二部分:加密模型训练。在确定共有用户群体后,就可以利用这些数据训练机器学习模型。为了保证训练过程中数据的保密性,需要借助第三方协作者 C 进行加密训练。以线性回归模型为例,训练过程可分为以下 4 步(如图 b 所示):第①步:协作者 C 把公钥分发给 A 和 B,用以对训练过程中需要交换的数据进行加密;第②步:A 和 B 之间以加密形式交互用于计算梯度的中间结果;第③步:A 和 B 分别基于加密的梯度值进行计算,同时 B 根据其标签数据计算损失,并把这些结果汇总给 C。C 通过汇总结果计算总梯度并将其解密。第④步:C 将解密后的梯度分别回传给 A 和 B;A 和 B 根据梯度更新各自模型的参数。
迭代上述步骤直至损失函数收敛,这样就完成了整个训练过程。在样本对齐及模型训练过程中,A 和 B 各自的数据均保留在本地,且训练中的数据交互也不会导致数据隐私泄露。因此,双方在联邦学习的帮助下得以实现合作训练模型。
第三部分:效果激励。联邦学习的一大特点就是它解决了为什么不同机构要加入联邦共同建模的问题,即建立模型以后模型的效果会在实际应用中表现出来,并记录在永久数据记录机制(如区块链)上。提供的数据多的机构会看到模型的效果也更好,这体现在对自己机构的贡献和对他人的贡献。这些模型对他人效果在联邦机制上以分给各个机构反馈,并继续激励更多机构加入这一数据联邦。以上三个步骤的实施,既考虑了在多个机构间共同建模的隐私保护和效果,又考虑了如何奖励贡献数据多的机构,以一个共识机制来实现。所以,联邦学习是一个 “闭环” 的学习机制。
由此我们也可以看出联邦学习的几个显著特征:
一、各方数据都保留在本地,不泄露隐私也不违反法规;
二、多个参与者联合数据建立虚拟的共有模型,实现各自的使用目的、共同获益;
三、在联邦学习的体系下,各个参与者的身份和地位相同;
四、联邦学习的建模效果和传统深度学习算法的建模效果相差不大;
五、“联邦”就是数据联盟,不同的联邦有着不同的运算框架,服务于不同的运算目的。如金融行业和医疗行业就会形成不同的联盟。
▌联邦学习目前进展
说了那么多,联邦学习目前到底有哪些威廉希尔官方网站 进展呢?
最新消息显示,Google 推出了首个产品级的联邦学习系统并发布论文 “Towards Federated Learning at Scale:System Design”,介绍了联邦学习系统的设计理念和现存挑战并提出了自己的解决方案。国内方面,微众 AI 团队对外开源了自研的 “联邦学习 FATE(Federated AI Technology Enabler)” 学习框架,目前在信贷风控、客户权益定价、监管科技等领域已经推出了相应的商用方案。
在系统框架之外,围绕联邦学习的威廉希尔官方网站 标准也在陆续推进中。今年 2 月份,IEEE P3652.1(联邦学习基础架构与应用)标准工作组第一次会议在深圳召开,作为国际上首个针对人工智能协同威廉希尔官方网站 框架订立的标准,不仅明确了联邦学习在数据合规、william hill官网 等方面的重要意义,还为立法机构在涉及隐私保护的问题时提供威廉希尔官方网站 参考。
总而言之,无论是威廉希尔官方网站 理论的探索还是统一标准的制定,在全球范围内对联邦学习的落地探索都会继续,联邦学习作为一个新兴的人工智能基础威廉希尔官方网站 ,还有很长的路要走。我们也有理由期待,随着联邦学习理论、应用体系的逐渐丰富,隐私保护问题所带来的威廉希尔官方网站 挑战将得到有效解决。
-
数据
+关注
关注
8文章
7017浏览量
89008 -
人工智能
+关注
关注
1791文章
47258浏览量
238417 -
迁移学习
+关注
关注
0文章
74浏览量
5561
原文标题:李开复口中的“联邦学习” 到底是什么?| 威廉希尔官方网站 头条
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论