 数据挖掘的功能
数据挖掘的功能
数据挖掘的功能
1、数据分类
数据分类为数据挖掘中常见的功能之一,顾名思义即是将分析对象依不同的属性分类加以定义,建立不同的类组。数据挖掘中的分类是指针对未发生的结果进行预测分类,主要包括归纳和推论两步骤,其主要目的在于提高分类的准确度,建立分类规则,再评估准则的优劣。常用“判定树”算法。
2、数据估计
根据不同相关属性数据的连续性数值,找出各属性间的关联性,以了解并获得某一特定属性未知的连续性数值,常用“回归分析”及“类神经网络算法”。
3、数据预测
预测工作的目的在于以其他属性的值为基础来预测特定属性的值。而这个被预测属性的值通常称为目标变量或是因变量;而其他属性则称为解释变量或自变量,预测的主要方法在于建立数据当中因变量与自变量间的关系。常用“回归分析”“时间序列分析”及“类神经网络”算法。
4、数据关联分组
数据关联分组主要用来发现数据中特征属性间具有高度关联性的一种模式,其所发现的模式通常是用规则来表现。常用“关联规则(又称购物蓝分析)”算法。
5、数据聚类
数据聚类主要是利用数据中类似或相同的项目,将同构型较高的数据区隔为不同的聚类,聚类内数据相似度越高越好,聚类间差异度越大越好。在一大群的研究对象中,根据不同的研究目的必定会有异质化的现象,但异质化的现象可能是几个同质化的群组所造成,数据聚类的主要目的便是将不同的同质化的组别差异找出来,常用“判别分析”与聚类分析“算法。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
数据挖掘
+关注
关注
1文章
406浏览量
24236
发布评论请先 登录
相关推荐
精准定位隧道挖掘通讯难题:虹科PCAN卡如何满足专业通讯需求?
在现代隧道挖掘行业中,电控系统作为设备的“大脑”,其性能优劣直接关系到设备的整体运作效率与安全性。本文将深入探讨虹科PCAN卡在隧道挖掘机器电控系统中的应用,了解它是如何提升设备性能,确保工程

中科曙光受邀参加第十届中国数据挖掘会议
近日,国内数据挖掘领域最主要的学术活动之一—第十届中国数据挖掘会议(CCDM2024)于山东泰安举行,中科曙光参与并分享了曙光AI构建产学研用的生态实践。
工业数据中台的功能和应用场景
工业数据中台是一个集数据采集、存储、处理、分析和应用于一体的综合性平台,其主要功能和应用场景如下: 功能 1.数据采集与接入: 支持多种
易华录无锡数据湖与清华大学苏州汽车研究院(吴江)合作挖掘智能驾驶数据新价值
6月15日,易华录无锡数据湖与清华大学苏州汽车研究院(吴江)数字工业中心就“聚焦汽车智能驾驶领域,共同挖掘智驾数据新价值”举行了签约仪式。清华大学苏州汽车研究院顾问、数字工业中心主任王小明,易华录
数据采集网关的功能和应用场景
随着信息威廉希尔官方网站
的飞速发展,物联网系统在各行业的应用越来越广泛,数据采集网关作为物联网系统中的重要组成部分,发挥着至关重要的作用。本文将详细介绍数据采集网关的功能及应用场景,以便读者更好地理解其在物联网

工业数据采集网关功能优势
实现智能制造和精益生产提供了强有力的支持。 一、工业数据采集网关的定义与功能 工业数据采集网关是一种用于连接不同设备、系统和网络,实现数据互通与信息共享的设备。其主要

求助,labview数据存储和历史数据查询功能应该如何做课程设计?
纯labview小白,正在做声卡声音信号采集的课程设计,要求有数据存储和历史数据查询功能,搞不懂如何历史数据查询,都将数据存储在了文件夹,在
发表于 04-15 09:32
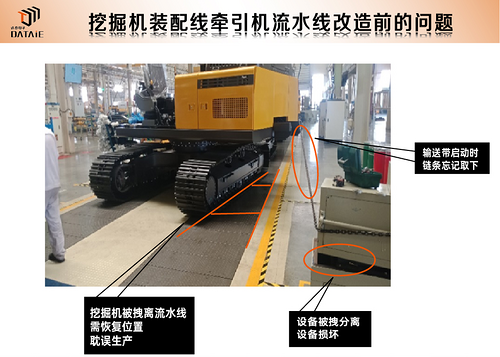
牵引机和挖掘机装配流水线自动互锁防呆系统无线通讯应用
在挖掘机装配工序中,液压系统检测、调试是其生产工艺中的重要环节。液压检测过程中需要操作铲斗、斗杆、动臂动作,这一过程中流水线挖掘机因带动偏移易发生安全事故及机械损伤故障等情况,需要采用牵引机链条牵引

AD4003数据手册中的Input span compression功能是什么意思?
AD4003数据手册中的Input span compression功能是什么意思啊
发表于 02-26 08:19
挖掘机生产装配线无线通讯应用
一、应用背景 山东某挖掘机机械有限公司主要产品有装载机、挖掘机、道路机械及核心关键零部件等系列工程机械产品。为加速新旧动能转换,全新挖掘机整机装配线配合劳动组合的调整,提高装配水平和生产效率;可集中
谷歌在Play商店启用AI摘要功能
据悉,现阶段该功能对少数用户开放,他们可以在应用详情页面的“安装”按钮之下查看到“应用亮点”。这一功能依靠AI算法自动挖掘出应用的核心优势,并用通俗易懂的文字概括出来,以便用户能够迅速了解应用的主要特色。
数据挖掘的应用领域,并举例说明
数据挖掘(Data Mining)是一种从大量数据中提取出有意义的信息和模式的威廉希尔官方网站
。它结合了数据库、统计学、机器学习和人工智能等领域的理论和方法,通过高效的算法和工具,对大
Volteq推出电动遥控迷你挖掘机Sky 1000
Sky 1000 不仅支持常规的直立操作模式,同时也支持远程遥控,用户仅需手持遥控器,即可从最远处约 48.8 米处轻松操控挖掘机。此举让操作者拥有更广阔的观察视角,降低安全风险。针对可能出现的突发事件,遥控器及挖掘机本机均配置了紧急停止按钮。





 工商网监
工商网监
评论