 手把手教你使用Python实现机器学习算法
手把手教你使用Python实现机器学习算法
这是一篇手把手教你使用 Python 实现机器学习算法,并在数值型数据和图像数据集上运行模型的入门教程,当你看完本文后,你应当可以开始你的机器学习之旅了!
本教程会采用下述两个库来实现机器学习算法:
scikit-learn
Keras
此外,你还将学习到:
评估你的问题
准备数据(原始数据、特征提取、特征工程等等)
检查各种机器学习算法
检验实验结果
深入了解性能最好的算法
在本文会用到的机器学习算法包括:
KNN
朴素贝叶斯
逻辑回归
SVM
决策树
随机森林
感知机
多层前向网络
CNNs
安装必备的 Python 机器学习库
开始本教程前,需要先确保安装了一下的 Python 库:
Numpy:用于 Python 的数值处理
PIL:一个简单的图像处理库
scikit-learn:包含多种机器学习算法(注意需要采用 0.2+ 的版本,所以下方安装命令需要加上--upgrade)
Kears 和 TensorFlow:用于深度学习。本教程可以仅采用 CPU 版本的 TensorFlow
OpenCV:本教程并不会采用到 OpenCV,但imutils库依赖它;
imutils:作者的图像处理/计算机视觉库
安装命令如下,推荐采用虚拟环境(比如利用 anaconda 创建一个新的环境):
$pipinstallnumpy$pipinstallpillow$pipinstall--upgradescikit-learn$pipinstalltensorflow#ortensorflow-gpu$pipinstallkeras$pipinstallopencv-contrib-python$pipinstall--upgradeimutils
数据集
本教程会用到两个数据集来帮助更好的了解每个机器学习算法的性能。
第一个数据集是 Iris(鸢尾花)数据集。这个数据集的地位,相当于你刚开始学习一门编程语言时,敲下的 “Hello,World!”
这个数据集是一个数值型的数据,如下图所示,其实就是一个表格数据,每一行代表一个样本,然后每一列就是不同的属性。这个数据集主要是收集了三种不同的鸢尾花的数据,分别为:
Iris Setosa
Iris Versicolor
Iris Virginica
对应图中最后一列Class label,然后还有四种属性,分别是:
Sepal length--萼片长度
Sepal width--萼片宽度
Petal length--花瓣长度
Petal width--花瓣宽度
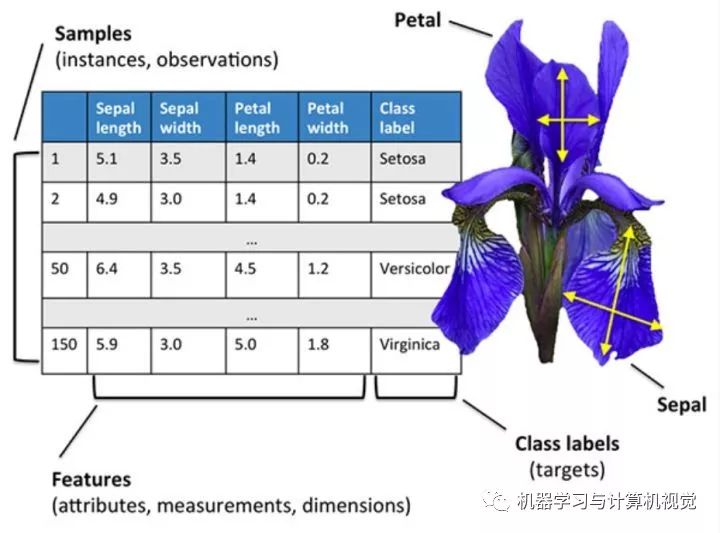
这个数据集可能是最简单的机器学习数据集之一了,通常是用于教导程序员和工程师的机器学习和模式识别基础的数据集。
对于该数据集,我们的目标就是根据给定的四个属性,训练一个机器学习模型来正确分类每个样本的类别。
需要注意的是,其中有一个类别和另外两个类别是线性可分的,但这两个类别之间却并非线性可分,所以我们需要采用一个非线性模型来对它们进行分类。当然了,在现实生活中,采用非线性模型的机器学习算法是非常常见的。
第二个数据集是一个三场景的图像数据集。这是帮助初学者学习如何处理图像数据,并且哪种算法在这两种数据集上性能最优。
下图是这个三场景数据集的部分图片例子,它包括森林、高速公路和海岸线三种场景,总共是 948 张图片,每个类别的具体图片数量如下:
Coast: 360
Forest: 328
Highway: 260
这个三场景数据集是采样于一个八场景数据集中,作者是 Oliva 和 Torralba 的 2001 年的一篇论文,Modeling the shape of the scene: a holistic representation of the spatial envelope
利用 Python 实现机器学习的步骤
无论什么时候实现机器学习算法,推荐采用如下流程来开始:
评估你的问题
准备数据(原始数据、特征提取、特征工程等等)
检查各种机器学习算法
检验实验结果
深入了解性能最好的算法
这个流程会随着你机器学习方面的经验的积累而改善和优化,但对于初学者,这是我建议入门机器学习时采用的流程。
所以,现在开始吧!第一步,就是评估我们的问题,问一下自己:
数据集是哪种类型?数值型,类别型还是图像?
模型的最终目标是什么?
如何定义和衡量“准确率”呢?
以目前自身的机器学习知识来看,哪些算法在处理这类问题上效果很好?
最后一个问题非常重要,随着你使用 Python 实现机器学习的次数的增加,你也会随之获得更多的经验。根据之前的经验,你可能知道有一种算法的性能还不错。
因此,接着就是准备数据,也就是数据预处理以及特征工程了。
一般来说,这一步,包括了从硬盘中载入数据,检查数据,然后决定是否需要做特征提取或者特征工程。
特征提取就是应用某种算法通过某种方式来量化数据的过程。比如,对于图像数据,我们可以采用计算直方图的方法来统计图像中像素强度的分布,通过这种方式,我们就得到描述图像颜色的特征。
而特征工程则是将原始输入数据转换成一个更好描述潜在问题的特征表示的过程。当然特征工程是一项更先进的威廉希尔官方网站 ,这里建议在对机器学习有了一定经验后再采用这种方法处理数据。
第三步,就是检查各种机器学习算法,也就是实现一系列机器学习算法,并应用在数据集上。
这里,你的工具箱应当包含以下几种不同类型的机器学习算法:
线性模型(比如,逻辑回归,线性 SVM)
非线性模型(比如 RBF SVM,梯度下降分类器)
树和基于集成的模型(比如 决策树和随机森林)
神经网络(比如 多层感知机,卷积神经网络)
应当选择比较鲁棒(稳定)的一系列机器学习模型来评估问题,因为我们的目标就是判断哪种算法在当前问题的性能很好,而哪些算法很糟糕。
决定好要采用的模型后,接下来就是训练模型并在数据集上测试,观察每个模型在数据集上的性能结果。
在多次实验后,你可能就是有一种“第六感”,知道哪种算法更适用于哪种数据集。比如,你会发现:
对于有很多特征的数据集,随机森林算法的效果很不错;
而逻辑回归算法可以很好处理高维度的稀疏数据;
对于图像数据,CNNs 的效果非常好。
而以上的经验获得,当然就需要你多动手,多进行实战来深入了解不同的机器学习算法了!
开始动手吧!
接下来就开始敲代码来实现机器学习算法,并在上述两个数据集上进行测试。本教程的代码文件目录如下,包含四份代码文件和一个3scenes文件夹,该文件夹就是三场景数据集,而Iris数据集直接采用scikit-learn库载入即可。
├──3scenes│├──coast[360entries]│├──forest[328entries]│└──highway[260entries]├──classify_iris.py├──classify_images.py├──nn_iris.py└──basic_cnn.py
首先是实现classify_iris.py,这份代码是采用机器学习算法来对Iris数据集进行分类。
首先导入需要的库:
fromsklearn.neighborsimportKNeighborsClassifierfromsklearn.naive_bayesimportGaussianNBfromsklearn.linear_modelimportLogisticRegressionfromsklearn.svmimportSVCfromsklearn.treeimportDecisionTreeClassifierfromsklearn.ensembleimportRandomForestClassifierfromsklearn.neural_networkimportMLPClassifierfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_irisimportargparse#设置参数ap=argparse.ArgumentParser()ap.add_argument("-m","--model",type=str,default="knn",help="typeofpythonmachinelearningmodeltouse")args=vars(ap.parse_args())#定义一个保存模型的字典,根据key来选择加载哪个模型models={"knn":KNeighborsClassifier(n_neighbors=1),"naive_bayes":GaussianNB(),"logit":LogisticRegression(solver="lbfgs",multi_class="auto"),"svm":SVC(kernel="rbf",gamma="auto"),"decision_tree":DecisionTreeClassifier(),"random_forest":RandomForestClassifier(n_estimators=100),"mlp":MLPClassifier()}
可以看到在sklearn库中就集成了我们将要实现的几种机器学习算法的代码,包括:
KNN
朴素贝叶斯
逻辑回归
SVM
决策树
随机森林
感知机
我们直接调用sklearn中相应的函数来实现对应的算法即可,比如对于knn算法,直接调用sklearn.neighbors中的KNeighborsClassifier()即可,只需要设置参数n_neighbors,即最近邻的个数。
这里直接用一个models的字典来保存不同模型的初始化,然后根据参数--model来调用对应的模型,比如命令输入python classify_irs.py --model knn就是调用knn算法模型。
接着就是载入数据部分:
print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,random_state=3,test_size=0.25)
这里直接调用sklearn.datasets中的load_iris()载入数据,然后采用train_test_split来划分训练集和数据集,这里是 75% 数据作为训练集,25% 作为测试集。
最后就是训练模型和预测部分:
#训练模型print("[INFO]using'{}'model".format(args["model"]))model=models[args["model"]]model.fit(trainX,trainY)#预测并输出一份分类结果报告print("[INFO]evaluating")predictions=model.predict(testX)print(classification_report(testY,predictions,target_names=dataset.target_names))
完整版代码代码如下:
fromsklearn.neighborsimportKNeighborsClassifierfromsklearn.naive_bayesimportGaussianNBfromsklearn.linear_modelimportLogisticRegressionfromsklearn.svmimportSVCfromsklearn.treeimportDecisionTreeClassifierfromsklearn.ensembleimportRandomForestClassifierfromsklearn.neural_networkimportMLPClassifierfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_irisimportargparse#设置参数ap=argparse.ArgumentParser()ap.add_argument("-m","--model",type=str,default="knn",help="typeofpythonmachinelearningmodeltouse")args=vars(ap.parse_args())#定义一个保存模型的字典,根据key来选择加载哪个模型models={"knn":KNeighborsClassifier(n_neighbors=1),"naive_bayes":GaussianNB(),"logit":LogisticRegression(solver="lbfgs",multi_class="auto"),"svm":SVC(kernel="rbf",gamma="auto"),"decision_tree":DecisionTreeClassifier(),"random_forest":RandomForestClassifier(n_estimators=100),"mlp":MLPClassifier()}#载入Iris数据集,然后进行训练集和测试集的划分,75%数据作为训练集,其余25%作为测试集print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,random_state=3,test_size=0.25)#训练模型print("[INFO]using'{}'model".format(args["model"]))model=models[args["model"]]model.fit(trainX,trainY)#预测并输出一份分类结果报告print("[INFO]evaluating")predictions=model.predict(testX)print(classification_report(testY,predictions,target_names=dataset.target_names))
接着就是采用三场景图像数据集的分类预测代码 classify_images.py ,跟 classify_iris.py 的代码其实是比较相似的,首先导入库部分,增加以下几行代码:
fromsklearn.preprocessingimportLabelEncoderfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportos
其中LabelEncoder是为了将标签从字符串编码为整型,然后其余几项都是处理图像相关。
对于图像数据,如果直接采用原始像素信息输入模型中,大部分的机器学习算法效果都很不理想,所以这里采用特征提取方法,主要是统计图像颜色通道的均值和标准差信息,总共是 RGB 3个通道,每个通道各计算均值和标准差,然后结合在一起,得到一个六维的特征,函数如下所示:
defextract_color_stats(image):'''将图片分成RGB三通道,然后分别计算每个通道的均值和标准差,然后返回:paramimage::return:'''(R,G,B)=image.split()features=[np.mean(R),np.mean(G),np.mean(B),np.std(R),np.std(G),np.std(B)]returnfeatures
然后同样会定义一个models字典,代码一样,这里就不贴出来了,然后图像载入部分的代码如下:
#加载数据并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循环遍历所有的图片数据forimagePathinimagePaths:#加载图片,然后计算图片的颜色通道统计信息image=Image.open(imagePath)features=extract_color_stats(image)data.append(features)#保存图片的标签信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#对标签进行编码,从字符串变为整数类型le=LabelEncoder()labels=le.fit_transform(labels)#进行训练集和测试集的划分,75%数据作为训练集,其余25%作为测试集(trainX,testX,trainY,testY)=train_test_split(data,labels,test_size=0.25)
上述代码就完成从硬盘中加载图片的路径信息,然后依次遍历,读取图片,提取特征,提取标签信息,保存特征和标签信息,接着编码标签,然后就是划分训练集和测试集。
接着是相同的训练模型和预测的代码,同样没有任何改变,这里就不列举出来了。
完整版如下:
fromsklearn.neighborsimportKNeighborsClassifierfromsklearn.naive_bayesimportGaussianNBfromsklearn.linear_modelimportLogisticRegressionfromsklearn.svmimportSVCfromsklearn.treeimportDecisionTreeClassifierfromsklearn.ensembleimportRandomForestClassifierfromsklearn.neural_networkimportMLPClassifierfromsklearn.preprocessingimportLabelEncoderfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportargparseimportosdefextract_color_stats(image):'''将图片分成RGB三通道,然后分别计算每个通道的均值和标准差,然后返回:paramimage::return:'''(R,G,B)=image.split()features=[np.mean(R),np.mean(G),np.mean(B),np.std(R),np.std(G),np.std(B)]returnfeatures#设置参数ap=argparse.ArgumentParser()ap.add_argument("-d","--dataset",type=str,default="3scenes",help="pathtodirectorycontainingthe'3scenes'dataset")ap.add_argument("-m","--model",type=str,default="knn",help="typeofpythonmachinelearningmodeltouse")args=vars(ap.parse_args())#定义一个保存模型的字典,根据key来选择加载哪个模型models={"knn":KNeighborsClassifier(n_neighbors=1),"naive_bayes":GaussianNB(),"logit":LogisticRegression(solver="lbfgs",multi_class="auto"),"svm":SVC(kernel="rbf",gamma="auto"),"decision_tree":DecisionTreeClassifier(),"random_forest":RandomForestClassifier(n_estimators=100),"mlp":MLPClassifier()}#加载数据并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循环遍历所有的图片数据forimagePathinimagePaths:#加载图片,然后计算图片的颜色通道统计信息image=Image.open(imagePath)features=extract_color_stats(image)data.append(features)#保存图片的标签信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#对标签进行编码,从字符串变为整数类型le=LabelEncoder()labels=le.fit_transform(labels)#进行训练集和测试集的划分,75%数据作为训练集,其余25%作为测试集(trainX,testX,trainY,testY)=train_test_split(data,labels,random_state=3,test_size=0.25)#print('trainXnumbers={},testXnumbers={}'.format(len(trainX),len(testX)))#训练模型print("[INFO]using'{}'model".format(args["model"]))model=models[args["model"]]model.fit(trainX,trainY)#预测并输出分类结果报告print("[INFO]evaluating...")predictions=model.predict(testX)print(classification_report(testY,predictions,target_names=le.classes_))
完成这两份代码后,我们就可以开始运行下代码,对比不同算法在两个数据集上的性能。
因为篇幅的原因,这里我会省略原文对每个算法的介绍,具体的可以查看之前我写的对机器学习算法的介绍:
常用机器学习算法汇总比较(上)
常用机器学习算法汇总比较(中)
常用机器学习算法汇总比较(完)
KNN
这里我们先运行下classify_irs.py,调用默认的模型knn,看下KNN在Iris数据集上的实验结果,如下所示:
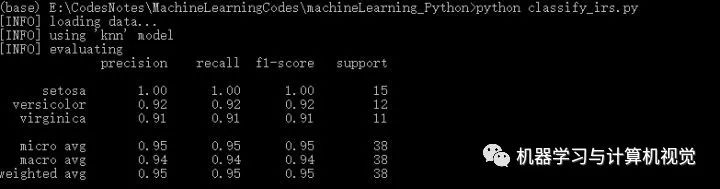
其中主要是给出了对每个类别的精确率、召回率、F1 以及该类别测试集数量,即分别对应precision,recall,f1-score,support。根据最后一行第一列,可以看到KNN取得95%的准确率。
接着是在三场景图片数据集上的实验结果:
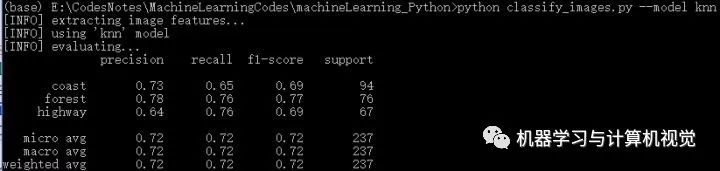
这里KNN取得72%的准确率。
(ps:实际上,运行这个算法,不同次数会有不同的结果,原文作者给出的是 75%,其主要原因是因为在划分训练集和测试集的时候,代码没有设置参数random_state,这导致每次运行划分的训练集和测试集的图片都是不同的,所以运行结果也会不相同!)
朴素贝叶斯
接着是朴素贝叶斯算法,分别测试两个数据集,结果如下:
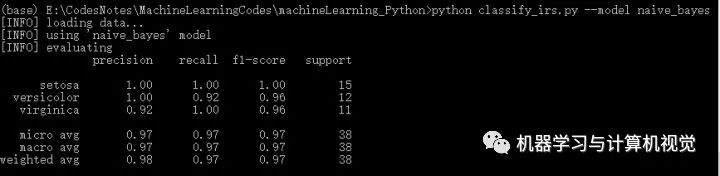
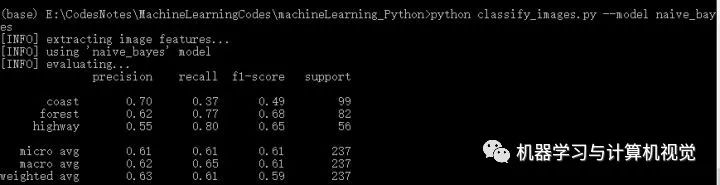
同样,朴素贝叶斯在Iris上有98%的准确率,但是在图像数据集上仅有63%的准确率。
那么,我们是否可以说明KNN算法比朴素贝叶斯好呢?
当然是不可以的,上述结果只能说明在三场景图像数据集上,KNN算法优于朴素贝叶斯算法。
实际上,每种算法都有各自的优缺点和适用场景,不能一概而论地说某种算法任何时候都优于另一种算法,这需要具体问题具体分析。
逻辑回归
接着是逻辑回归算法,分别测试两个数据集,结果如下:
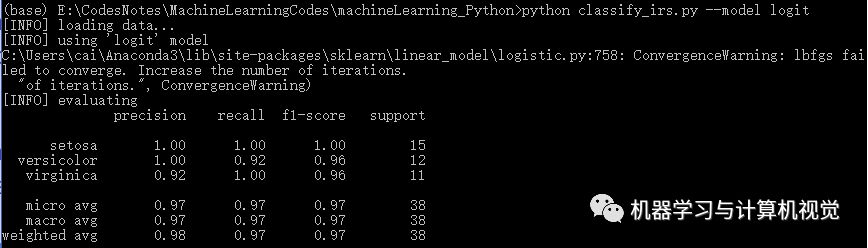
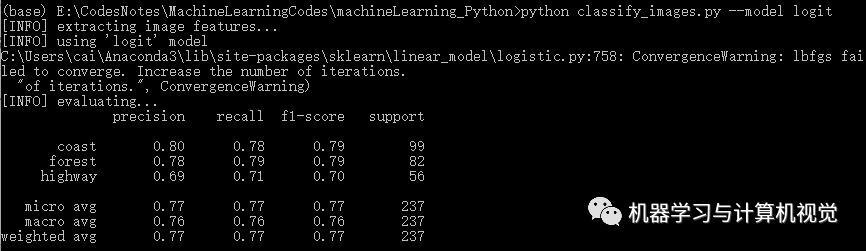
同样,逻辑回归在Iris上有98%的准确率,但是在图像数据集上仅有77%的准确率(对比原文作者的逻辑回归准确率是 69%)
支持向量机 SVM
接着是 SVM 算法,分别测试两个数据集,结果如下:
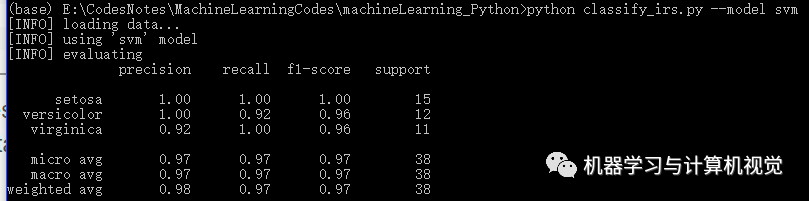
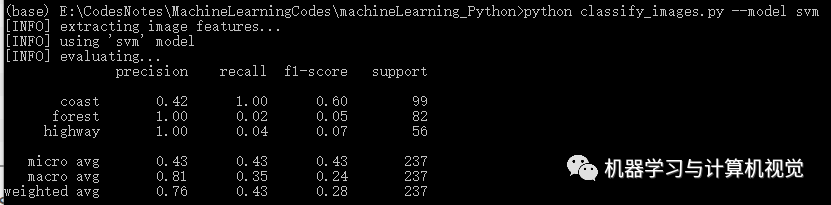
同样,SVM 在Iris上有98%的准确率,但是在图像数据集上仅有76%的准确率(对比原文作者的准确率是 83%,主要是发现类别coast差别有些大)
决策树
接着是决策树算法,分别测试两个数据集,结果如下:
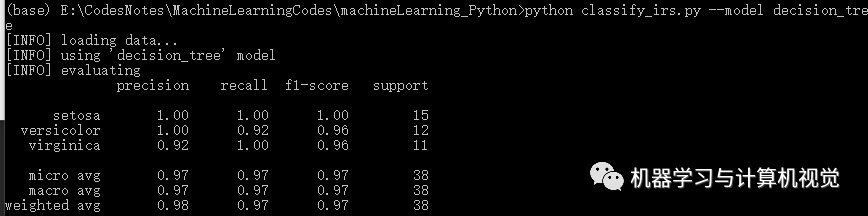
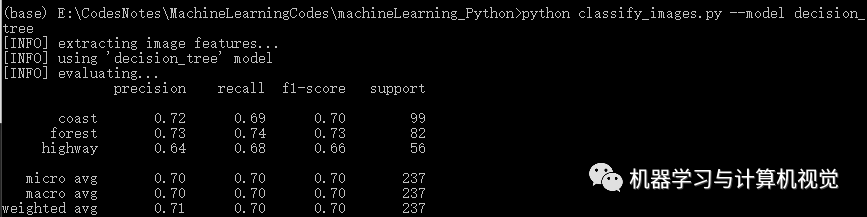
同样,决策树在Iris上有98%的准确率,但是在图像数据集上仅有71%的准确率(对比原文作者的决策树准确率是 74%)
随机森林
接着是随机森林算法,分别测试两个数据集,结果如下:

同样,随机森林在Iris上有96%的准确率,但是在图像数据集上仅有77%的准确率(对比原文作者的决策树准确率是 84%)
注意了,一般如果决策树算法的效果还不错的话,随机森林算法应该也会取得不错甚至更好的结果,这是因为随机森林实际上就是多棵决策树通过集成学习方法组合在一起进行分类预测。
多层感知机
最后是多层感知机算法,分别测试两个数据集,结果如下:
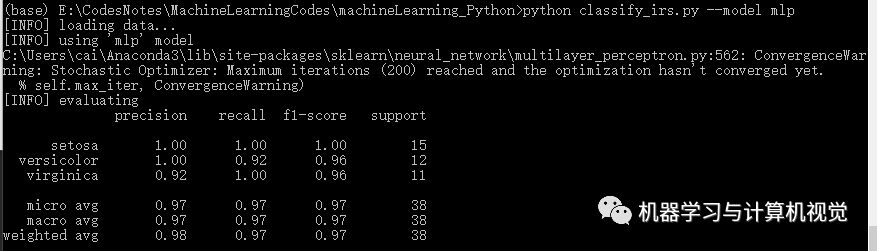
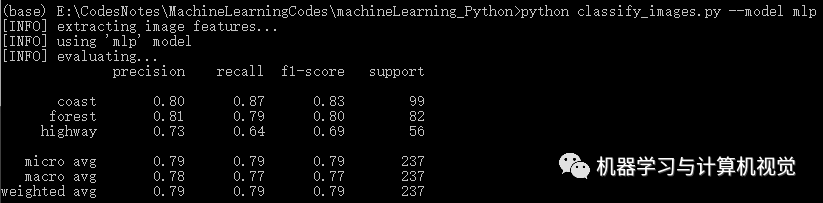
同样,多层感知机在Iris上有98%的准确率,但是在图像数据集上仅有79%的准确率(对比原文作者的决策树准确率是 81%).
深度学习以及深度神经网络
神经网络
最后是实现深度学习的算法,也就是nn_iris.py和basic_cnn.py这两份代码。
(这里需要注意TensorFlow和Keras的版本问题,我采用的是TF=1.2和Keras=2.1.5)
首先是nn_iris.py的实现,同样首先是导入库和数据的处理:
fromkeras.modelsimportSequentialfromkeras.layers.coreimportDensefromkeras.optimizersimportSGDfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_iris#载入Iris数据集,然后进行训练集和测试集的划分,75%数据作为训练集,其余25%作为测试集print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,test_size=0.25)#将标签进行one-hot编码lb=LabelBinarizer()trainY=lb.fit_transform(trainY)testY=lb.transform(testY)
这里我们将采用Keras来实现神经网络,然后这里需要将标签进行one-hot编码,即独热编码。
接着就是搭建网络模型的结构和训练、预测代码:
#利用Keras定义网络模型model=Sequential()model.add(Dense(3,input_shape=(4,),activation="sigmoid"))model.add(Dense(3,activation="sigmoid"))model.add(Dense(3,activation="softmax"))#采用梯度下降训练模型print('[INFO]trainingnetwork...')opt=SGD(lr=0.1,momentum=0.9,decay=0.1/250)model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=250,batch_size=16)#预测print('[INFO]evaluatingnetwork...')predictions=model.predict(testX,batch_size=16)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=dataset.target_names))
这里是定义了 3 层全连接层的神经网络,前两层采用Sigmoid激活函数,然后最后一层是输出层,所以采用softmax将输出变成概率值。接着就是定义了使用SGD的优化算法,损失函数是categorical_crossentropy,迭代次数是 250 次,batch_size是 16。
完整版如下:
fromkeras.modelsimportSequentialfromkeras.layers.coreimportDensefromkeras.optimizersimportSGDfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromsklearn.datasetsimportload_iris#载入Iris数据集,然后进行训练集和测试集的划分,75%数据作为训练集,其余25%作为测试集print("[INFO]loadingdata...")dataset=load_iris()(trainX,testX,trainY,testY)=train_test_split(dataset.data,dataset.target,test_size=0.25)#将标签进行one-hot编码lb=LabelBinarizer()trainY=lb.fit_transform(trainY)testY=lb.transform(testY)#利用Keras定义网络模型model=Sequential()model.add(Dense(3,input_shape=(4,),activation="sigmoid"))model.add(Dense(3,activation="sigmoid"))model.add(Dense(3,activation="softmax"))#采用梯度下降训练模型print('[INFO]trainingnetwork...')opt=SGD(lr=0.1,momentum=0.9,decay=0.1/250)model.compile(loss='categorical_crossentropy',optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=250,batch_size=16)#预测print('[INFO]evaluatingnetwork...')predictions=model.predict(testX,batch_size=16)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=dataset.target_names))
直接运行命令python nn_iris.py, 输出的结果如下:
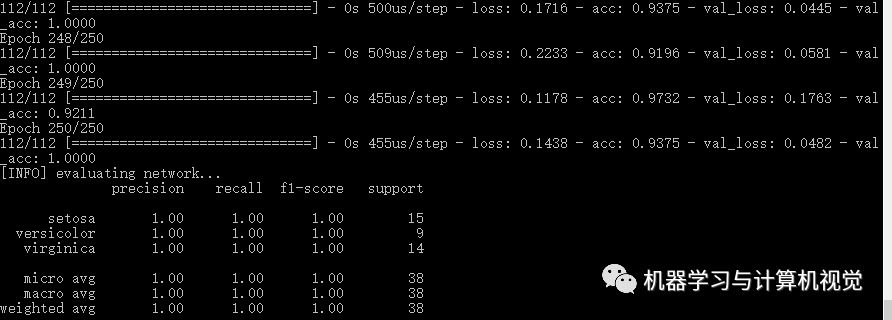
这里得到的是 100% 的准确率,和原文的一样。当然实际上原文给出的结果如下图所示,可以看到其实类别数量上是不相同的。
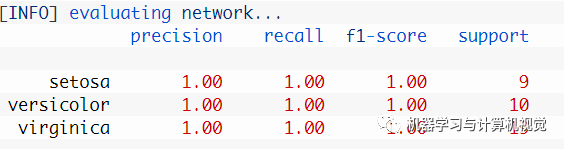
CNN
最后就是实现basic_cnn.py这份代码了。
同样首先是导入必须的库函数:
fromkeras.modelsimportSequentialfromkeras.layers.convolutionalimportConv2Dfromkeras.layers.convolutionalimportMaxPooling2Dfromkeras.layers.coreimportActivationfromkeras.layers.coreimportFlattenfromkeras.layers.coreimportDensefromkeras.optimizersimportAdamfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportargparseimportos#配置参数ap=argparse.ArgumentParser()ap.add_argument("-d","--dataset",type=str,default="3scenes",help="pathtodirectorycontainingthe'3scenes'dataset")args=vars(ap.parse_args())
同样是要导入Keras来建立CNN的网络模型,另外因为是处理图像数据,所以PIL、imutils也是要导入的。
然后是加载数据和划分训练集和测试集,对于加载数据,这里直接采用原始图像像素数据,只需要对图像数据做统一尺寸的调整,这里是统一调整为 32×32,并做归一化到[0,1]的范围。
#加载数据并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循环遍历所有的图片数据forimagePathinimagePaths:#加载图片,然后调整成32×32大小,并做归一化到[0,1]image=Image.open(imagePath)image=np.array(image.resize((32,32)))/255.0data.append(image)#保存图片的标签信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#对标签编码,从字符串变为整型lb=LabelBinarizer()labels=lb.fit_transform(labels)#划分训练集和测试集(trainX,testX,trainY,testY)=train_test_split(np.array(data),np.array(labels),test_size=0.25)
接着定义了一个 4 层的CNN网络结构,包含 3 层卷积层和最后一层输出层,优化算法采用的是Adam而不是SGD。代码如下所示:
#定义CNN网络模型结构model=Sequential()model.add(Conv2D(8,(3,3),padding="same",input_shape=(32,32,3)))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(16,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(32,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Flatten())model.add(Dense(3))model.add(Activation("softmax"))#训练模型print("[INFO]trainingnetwork...")opt=Adam(lr=1e-3,decay=1e-3/50)model.compile(loss="categorical_crossentropy",optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=50,batch_size=32)#预测print("[INFO]evaluatingnetwork...")predictions=model.predict(testX,batch_size=32)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=lb.classes_))
完整版如下:
fromkeras.modelsimportSequentialfromkeras.layers.convolutionalimportConv2Dfromkeras.layers.convolutionalimportMaxPooling2Dfromkeras.layers.coreimportActivationfromkeras.layers.coreimportFlattenfromkeras.layers.coreimportDensefromkeras.optimizersimportAdamfromsklearn.preprocessingimportLabelBinarizerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportclassification_reportfromPILimportImagefromimutilsimportpathsimportnumpyasnpimportargparseimportos#配置参数ap=argparse.ArgumentParser()ap.add_argument("-d","--dataset",type=str,default="3scenes",help="pathtodirectorycontainingthe'3scenes'dataset")args=vars(ap.parse_args())#加载数据并提取特征print("[INFO]extractingimagefeatures...")imagePaths=paths.list_images(args['dataset'])data=[]labels=[]#循环遍历所有的图片数据forimagePathinimagePaths:#加载图片,然后调整成32×32大小,并做归一化到[0,1]image=Image.open(imagePath)image=np.array(image.resize((32,32)))/255.0data.append(image)#保存图片的标签信息label=imagePath.split(os.path.sep)[-2]labels.append(label)#对标签编码,从字符串变为整型lb=LabelBinarizer()labels=lb.fit_transform(labels)#划分训练集和测试集(trainX,testX,trainY,testY)=train_test_split(np.array(data),np.array(labels),test_size=0.25)#定义CNN网络模型结构model=Sequential()model.add(Conv2D(8,(3,3),padding="same",input_shape=(32,32,3)))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(16,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Conv2D(32,(3,3),padding="same"))model.add(Activation("relu"))model.add(MaxPooling2D(pool_size=(2,2),strides=(2,2)))model.add(Flatten())model.add(Dense(3))model.add(Activation("softmax"))#训练模型print("[INFO]trainingnetwork...")opt=Adam(lr=1e-3,decay=1e-3/50)model.compile(loss="categorical_crossentropy",optimizer=opt,metrics=["accuracy"])H=model.fit(trainX,trainY,validation_data=(testX,testY),epochs=50,batch_size=32)#预测print("[INFO]evaluatingnetwork...")predictions=model.predict(testX,batch_size=32)print(classification_report(testY.argmax(axis=1),predictions.argmax(axis=1),target_names=lb.classes_))
运行命令python basic_cnn.py, 输出结果如下:
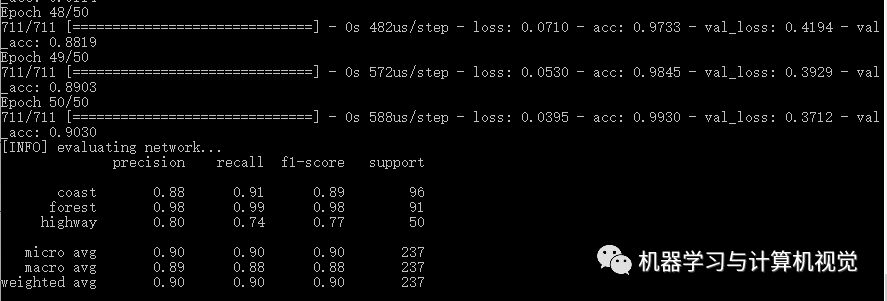
CNN的准确率是达到90%,它是优于之前的几种机器学习算法的结果。
小结
最后,这仅仅是一份对机器学习完全是初学者的教程,其实就是简单调用现有的库来实现对应的机器学习算法,让初学者简单感受下如何使用机器学习算法,正如同在学习编程语言的时候,对着书本的代码例子敲起来,然后运行代码,看看自己写出来的程序的运行结果。
通过这份简单的入门教程,你应该明白的是:
没有任何一种算法是完美的,可以完全适用所有的场景,即便是目前很热门的深度学习方法,也存在它的局限性,所以应该具体问题具体分析!
记住开头推荐的 5 步机器学习操作流程,这里再次复习一遍:
评估你的问题
准备数据(原始数据、特征提取、特征工程等等)
检查各种机器学习算法
检验实验结果
深入了解性能最好的算法
最后一点,是我运行算法结果,和原文作者的结果会不相同,这实际上就是每次采样数据,划分训练集和测试集不相同的原因!这其实也说明了数据非常重要,对于机器学习来说,好的数据很重要!
接着,根据这份教程,你可以继续进一步了解每种机器学习算法,了解每种算法的基本原理和实现,尝试自己手动实现,而不是简单调用现有的库,这样更加能加深印象,这里推荐《机器学习实战》,经典的机器学习算法都有介绍,并且都会带你一步步实现算法!
最后,极力推荐大家去阅读下原文作者的博客,原文作者也是一个大神,他的博客地址如下:https://www.pyimagesearch.com/
他的博客包含了 Opencv、Python、机器学习和深度学习方面的教程和文章,而且作者喜欢通过实战学习,所以很多文章都是通过一些实战练习来学习某个知识点或者某个算法,正如同本文通过实现这几种常见的机器学习算法在两个不同类型数据集上的实战来带领初学者入门机器学习。
-
机器学习
+关注
关注
66文章
8412浏览量
132601 -
python
+关注
关注
56文章
4795浏览量
84656 -
数据集
+关注
关注
4文章
1208浏览量
24694
原文标题:初学者的机器学习入门实战教程!
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
原创手把手教你学习FPGA视频教程,不看后悔哟
手把手教你安装Quartus II
手把手教你开关电源PCB排板






 工商网监
工商网监
评论