 OpenAI发布Neural MMO—一个强化学习的大型多智能体游戏环境
OpenAI发布Neural MMO—一个强化学习的大型多智能体游戏环境
今日凌晨,OpenAI发布Neural MMO—一个强化学习的大型多智能体游戏环境。这一平台可以在持久性和开放式任务中支持大量可变数量的智能体。
一直以来,人工智能研究者都希望让智能体(agent)学会合作竞争,一些研究者也认为这是实现通用人工智能(AGI)的必要条件。
17年7月份,OpenAI、麦吉尔大学和 UC Berkeley 联合提出了一种“用于合作-竞争混合环境的多智能体 actor-critic”,可用于多智能体环境中的中心化学习(centralized learning)和去中心化执行(decentralized execution),让智能体可以学会彼此合作和竞争。
论文地址:
https://arxiv.org/pdf/1706.02275.pdf
之后,OpenAI也一直没有放弃对多智能体学习环境的探索。
今日凌晨,OpenAI宣称发布Neural MMO——一个强化学习的大型多智能体游戏环境。这一多智能体的环境可以探索更兼容和高效的整体环境,力求在复杂度和智能体人数上获取难得的平衡。
近年来,多重代理设置已成为深度强化学习研究的一个有效平台。尽管进展颇丰,但其仍存在两个主要挑战:当前环境要么复杂但过于受限,要么开放但过于简单。
其中,持久性和规模化将是探讨的关键属性,但研究者们还需要更好的基准测试环境,在存在大量人口规模和持久性的情况下量化学习进度。这一游戏类型(MMO:大型多人在线游戏)interwetten与威廉的赔率体系 了在持续和广泛环境中可变数量玩家进行竞争的大型生态系统。
为了应对这些挑战,OpenAI构建了神经MMO以满足以下标准:
持久性:在没有环境重置的情况下,代理可以在其他学习代理存在的情况下同时学习。策略必须具有远见思维,并适应其他代理行为的潜在快速变化。
比例:环境支持大量且可变数量的实体。实验考虑了100个并发服务器中每个服务器128个并发代理且长达100M的生命周期。
效率:进入的计算障碍很低。可以在单个桌面CPU上培训有效的策略。
扩展:与现有MMO类似,Neural MMO旨在更新内容。目前的核心功能包括基于拼接单元块(tile-based)的地形的程序生成,食物和水觅食系统以及战略战斗系统。未来有机会进行开源驱动的扩展。
OpenAI在博客中详细介绍了这一新环境。
环境
玩家(代理)可以加入任何可用的服务器(环境),每个都会包含一个可配置大小、且自动生成的基于图块的游戏地图。一些障碍块,例如森林和草,是可穿越的;其他的如水和实心岩石,则不能穿越。
代理在环境边缘的随机位置产生。他们需要获得食物和水,并避免其他代理的战斗伤害,以维持自己的生存。踩在森林地块上或出现在水资源地块的旁边会分别填充一部分代理的食物和水供应。然而,森林的食物供应有限,随着时间的推移会缓慢再生。这意味着代理必须竞争食品块,同时定期补充水源。玩家还可以使用三种战斗风格参与战斗,分别为混战,游猎及魔法。
输入:代理观察以其当前位置为中心的方形区域。这包括地块类型和占用代理的选择属性(健康,食物,水和位置)。
输出:代理为下一个游戏单位时间(timestep)输出操作选项。该操作由一个动作和一个攻击组成。
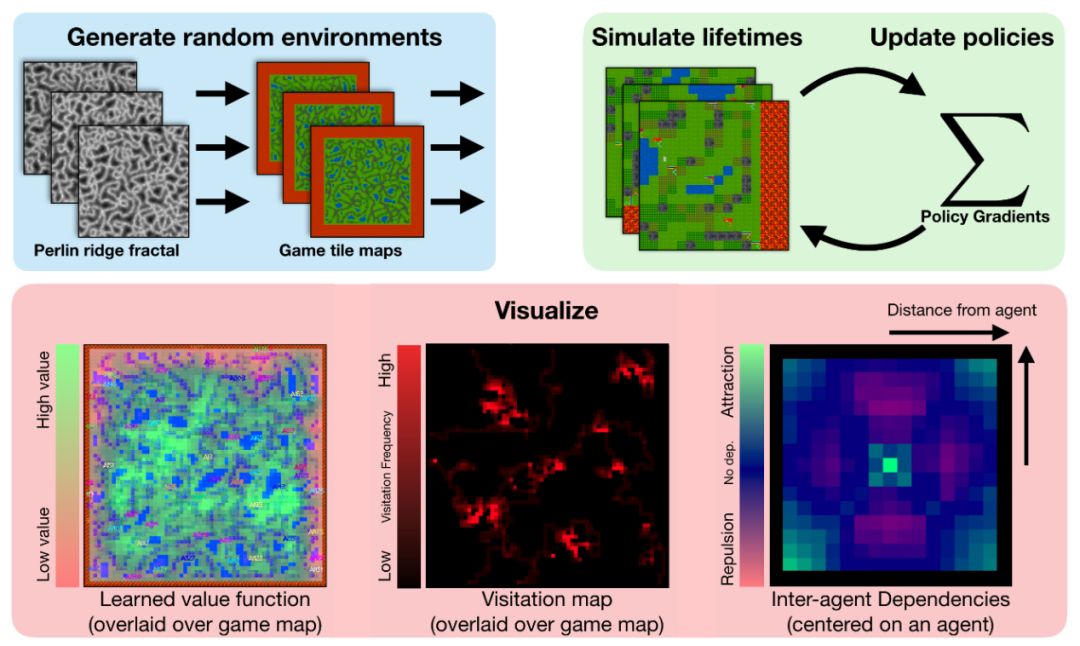
模型
作为一个简单的基准,我们使用vanilla策略梯度训练一个小型,完全连接的架构,并把值函数基准和奖励折扣作为唯一的增强功能。在这个模型中,奖励策略并不针对实现特定目标,而是针对其生命周期(轨迹长度)进行优化:他们在其生命周期的每个单位时间上获得奖励1。我们通过计算所有代理的最大值来将可变长度观测值(例如周围代理列表)转换为单个长度向量(OpenAI Five也使用了这个技巧)。基于PyTorch和Ray,源版本包括我们完整分布式培训的实现。
训练中最大种群数量在(16,32,64,128)之间变化。为了提高效率,在测试时,将在一对实验中学到的特定群进行合并,并在一个固定的范围内进行评估。只对作战策略进行评估,因为直接量化作战策略比较困难。通常来说,在更大的分布范围内进行训练效果会更好。
代理的策略是从多个种群中简单抽样——不同种群中的代理共享体系结构,但只有相同种群中的代理共享权重。初步实验表明,随着多智能体相互作用的增加,智能体的能力也随之增加。增加并发智能体的最大数量将放大探索行为;增加种群的数量将放大生态位形成——也就是说,种群在地图的不同部分扩散和觅食的趋势。
在评估跨多台服务器的玩家能力方面,并没有统一的标准。然而,有时,MMO服务器会进行合并。我们通过合并在不同服务器中训练的玩家基地来实现“锦标赛”风格的评估。这使得我们可以直接比较在不同实验环境中学到的策略。改变了测试时间范围,发现在较大环境下训练的代理一直优于在较小环境中训练的代理。
评估结果
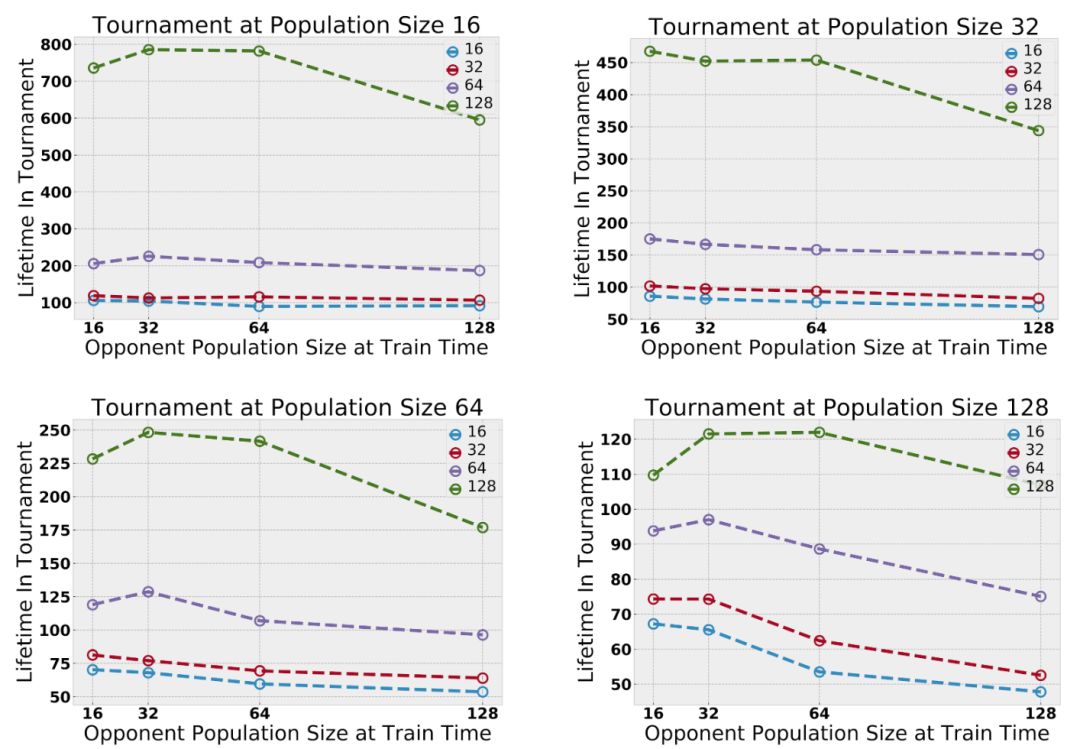
训练中最大种群数量在(16,32,64,128)之间变化。为了提高效率,在测试时,将在一对实验中学到的特定群进行合并,并在一个固定的范围内进行评估。只对作战策略进行评估,因为直接量化作战策略比较困难。通常来说,在更大的分布范围内进行训练效果会更好。
代理的策略是从多个种群中简单抽样——不同种群中的代理共享体系结构,但只有相同种群中的代理共享权重。初步实验表明,随着多智能体相互作用的增加,智能体的能力也随之增加。增加并发智能体的最大数量将放大探索行为;增加种群的数量将放大生态位形成——也就是说,种群在地图的不同部分扩散和觅食的趋势。
服务器合并条件下的锦标赛:多代理放大了竞争行为
在跨多台服务器队玩家能力的能力进行评估时,我们并没有统一的标准。然而,有时MMO服务器会进行合并。我们通过合并在不同服务器中训练的玩家基地来实现“锦标赛”风格的评估。这使得我们可以直接比较在不同实验环境中学到的策略。改变了测试时间范围后,我们发现,在较大环境下训练的代理一直优于在较小环境中训练的代理。
种群规模的增加放大了探索行为
种群规模放大了探索行为:代理表现出分散开来的特征以避免竞争。最后几帧显示学习值函数叠加。有关其他参数,请参阅论文:
https://s3-us-west-2.amazonaws.com/openai-assets/neural-mmo/neural-mmo-arxiv.pdf
在自然世界中,动物之间的竞争可以激励它们分散开来以避免冲突。我们观察到,随着并发代理数量的增加,映射覆盖率增加。代理学习探索仅仅是因为其他代理的存在提供了这样做的自然动机。物种数量的增加扩大了生态位形成的几率。
物种数量的增加扩大了生态位的形成。
物种数量(种群数量)放大了生态位的形成。上图中访问地图覆盖了游戏地图;不同的颜色对应不同的物种。训练单一物种倾向于产生单一的深度探索路径。训练八个物种则会导致许多较浅的探索路径:种群扩散以避免物种之间的竞争。
鉴于环境足够大且资源丰富,我们发现不同的代理群在地图上呈现分散的特点,以避免随着数量的增加与其他代理产生竞争。由于代理不能与自己种群中的其他代理竞争(即与他们共享权重的代理),他们倾向于寻找包含足够资源来维持其种群数量的地图区域。在DeepMind的并发多代理研究中也独立地观察到类似的效果。
并发多代理研究:
https://arxiv.org/abs/1812.07019
其他见解
每个方形图显示位于中心的代理对其周围代理的存在的响应。我们在初始化和训练早期展示觅食地图;额外的依赖图对应于觅食和战斗的不同表述。
我们通过将代理固定在假设的地图中心来对代理进行可视化。对于该代理可见的每个位置,我们将显示在该位置有第二个代理时的值函数。
我们发现代理商在觅食和战斗环境中,可以学习依赖于其他代理的策略。代理学习“插眼(bull’s eye)”行为时,在几分钟的训练后就能更有效地开始觅食。当代理学习环境的战斗力学时,他们开始适当地评估有效的接触范围和接近角度。
下一步
Neural MMO解决了之前基于游戏环境的两个主要限制,但仍有许多尚未解决。这种Neural MMO在环境复杂性和人口规模之间尽力寻求平衡。OpenAI在设计这个环境时考虑了开源扩展,并为研究社区提供了基础。
-
人工智能
+关注
关注
1791文章
47207浏览量
238279 -
智能体
+关注
关注
1文章
147浏览量
10575 -
强化学习
+关注
关注
4文章
266浏览量
11249
原文标题:OpenAI发布Neural MMO :大型多智能体游戏环境
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
OpenAI 发了一个支持 ESP32 的 Realtime API SDK
【「具身智能机器人系统」阅读体验】+初品的体验
《具身智能机器人系统》第1-6章阅读心得之具身智能机器人系统背景知识与基础模块

OpenAI连续12天直播,揭秘新产品与功能

蚂蚁集团收购边塞科技,吴翼出任强化学习实验室首席科学家
【书籍评测活动NO.51】具身智能机器人系统 | 了解AI的下一个浪潮!
如何使用 PyTorch 进行强化学习
谷歌AlphaChip强化学习工具发布,联发科天玑芯片率先采用
通过强化学习策略进行特征选择

OpenAI 深夜抛出王炸 “ChatGPT- 4o”, “她” 来了
Sora与世界模型:为何它未能成为全面代表?

一文详解Transformer神经网络模型

OpenAI GPT 商店即将亮相,SpaceX 新型 Starlink 卫星发射上天






 工商网监
工商网监
评论