 《中国近代史纲要》考试过关?Python帮你划重点
《中国近代史纲要》考试过关?Python帮你划重点
打开查分界面,我看到我的“中国近现代史纲要”一栏露出了难看的脸色。
这时,一个程序突然自告奋勇:“不就是这种简单的考试吗?让我学一下你们的课本,我也能够上考场! (  ̄ー ̄)”
我把我的课本文本输入给它。不到一分钟以后,它对我说:“我学完了,来考我吧。”
虽然也只是在考前突击了两天,但我对它如此之快的速度还是深感嫉妒。我问:“你知道孙中山先生都干了哪些事情吗?”
“发动护法运动、就任临时大总统、让位于***”
“不错吗,你是怎么做到的?”
“让我给你细细讲来吧……”
准备工作
程序:“首先引入一些必要的库,然后我加载doc为1840—1919年中国大事的那一段段文本做个简单的示例,这部分代码就不用我列出来了吧。”
旁白:这里使用harvesttext库进行文本挖掘,它的许多功能能够使得文本分析的流程变得更加轻松。前面的“用python分析《三国演义》中的社交网络”一文也使用了这一工具。
ht = HarvestText()sentences = ht.cut_sentences(doc)
有哪些重要对象
“重要对象,一般都是一些专有名词。我可以利用自然语言处理中的命名实体识别威廉希尔官方网站 就能够识别出这样的一些对象,比如:人名、地名、机构名还有其他专有名词等。”
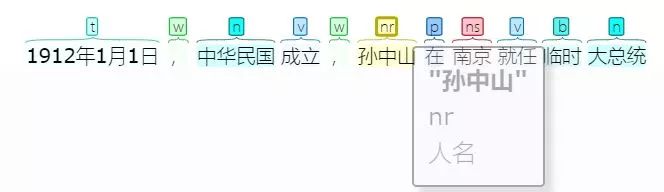
HarvestText中包装精简了pyhanlp中的命名实体识别接口,让我们来使用它找到近代史中的重要对象吧。
entity_type_dict = {}for i, sent in enumerate(sentences): entity_type_dict0 = ht.named_entity_recognition(sent) for entity0, type0 in entity_type_dict0.items(): entity_type_dict[entity0] = type0for entity in list(entity_type_dict.keys())[:10]: print(entity, entity_type_dict[entity])中国 地名鸦片战争 其他专名五四运动 其他专名英国 地名南京 地名望厦 其他专名黄埔 地名不平等条约 其他专名洪秀全 人名金田 地名
把找到的实体登录,我们就可以统计他们出现的次数,通过词频来判断它们的重要性。
ht.add_entities(entity_type_dict = entity_type_dict)inv_index = ht.build_index(sentences)counts = ht.get_entity_counts(sentences,inv_index)print(pd.Series(counts).sort_values(ascending=False).head())中国 21清政府 6日本 5孙中山 4英国 3dtype: int64
我:“这个分析确实有用,看着这些词我就联想到了,在1840—1919年的中国,清政府面对外敌的屈辱,以及孙中山先生为代表的有识之士的努力。但是考试不是单考这些对象,关键要考和它们有关的知识点啊。”
程序:“别着急,对于知识点,我也有办法找到。”
有哪些重要知识点
程序:“你们说的重要知识点,可以认为是包含了那些重要对象的事件或者事实吧。对于你们人类,事实可能就是自然语言描述的一句话。不过对于我们程序,我们要用一种标准清晰的结构来表示它。三元组组成的知识图谱就是一种解决方案。”
三元组就是类似(主语,谓词,宾语)的结构,比如:
[‘清政府’, ‘签订’, ‘天津条约’]
[‘***’, ‘复辟’, ‘帝制’]
[‘孙中山’, ‘就任’, ‘临时大总统’]
我:“有点意思,三个词基本就能凝练地表达一句话中的主要事实了。但是你只有文本作为输入,你要怎么从中提取出这样的三元组呢?”
程序:“上面已经提到三元组有(主语,谓词,宾语)的结构。你要是英语/语文课学得好的话,应该会联想到主语、谓语、宾语这些语法概念吧?而我就可以使用依存句法分析威廉希尔官方网站 从文本中获得这些句法信息。”
分析大致是这样的:
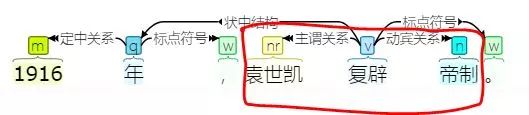
可以看到,从主谓关系和动宾关系,我们就能够自然地得到我们需要的三元组[‘***’, ‘复辟’, ‘帝制’]。
保留更多的信息,比如修饰主语的形容词,能够让三元组的意思更加完整。我们可以利用别的关系来扩充事实:

原来我们只会得到[‘孙中山’, ‘就任’, ‘大总统’]。现在利用定中关系,我们就知道“临时”一词修饰“大总统”,我们就能够得到[‘孙中山’, ‘就任’, ‘临时大总统’]这个更完整的事实了。
我:“emmm…我的英语学得不好,这些语法看得有点头晕。”
程序:“好吧 (¬_¬),不过把它包装成接口以后,我们就可以很简单地使用这个威廉希尔官方网站 了。现在让我们用它来找到课本里的重要知识点:”
ht2 = HarvestText()SVOs = []for i, sent in enumerate(sentences): SVOs += ht2.triple_extraction(sent.strip())print(" ".join(" ".join(tri) for tri in SVOs[5:10]))英法联军 发动 侵略中国清政府 签订 天津条约清政府 签订 北京条约慈禧太后 掌握 清王朝政权这是中国半殖民地半封建社会 形成 中国资本主义产生时期
程序:“怎么样?要不考虑下次考试让我帮你划重点?”
我:“有的三元组看起来还挺不错的,但是有的感觉有点奇怪啊。”
程序:“不要在意这些细节……那是因为你们给我写的算法还有很多提升空间吗,但总体质量还是不错的。”
“有了这些结构化的知识,我就可以接着建立知识图谱,‘掌握’这些知识之间的联系。”
知识图谱长什么样呢?它可以理解为实体之间的网络,网络之间的连边就是实体之间的联系,做出一张图来直观地感受下:
fig = plt.figure(figsize=(12,8),dpi=100)g_nx = nx.DiGraph()labels = {}for subj, pred, obj in SVOs: g_nx.add_edge(subj,obj) labels[(subj,obj)] = predpos=nx.spring_layout(g_nx)nx.draw_networkx_nodes(g_nx, pos, node_size=300)nx.draw_networkx_edges(g_nx,pos,width=4)nx.draw_networkx_labels(g_nx,pos,font_size=10,font_family='sans-serif')nx.draw_networkx_edge_labels(g_nx, pos, labels , font_size=10, font_family='sans-serif')plt.axis("off")plt.show()
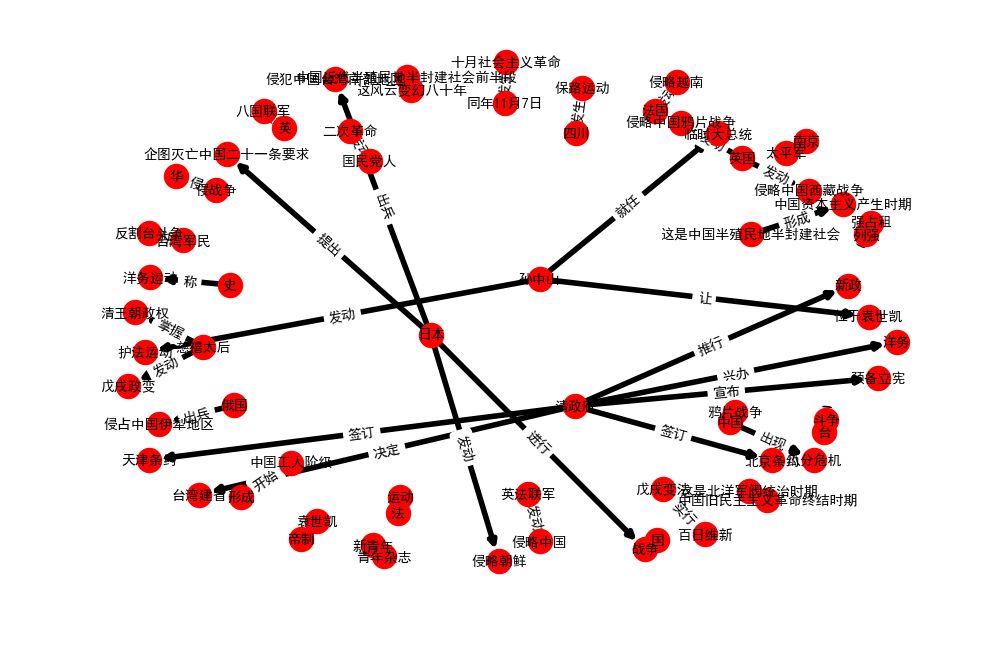
现在,上考场吧
“现在我学会了这些知识,就可以建立起问答系统,回答一些问题。出几个问题来考考我吧?”
问答系统的具体实现思路可以见我的另一篇博客:https://blog.csdn.net/blmoistawinde/article/details/86556844
QA = NaiveKGQA(SVOs, entity_type_dict=entity_type_dict)questions = ["孙中山干了什么事?","清政府签订了哪些条约?","谁复辟了帝制?"]for question0 in questions: print("问:"+question0) print("答:"+QA.answer(question0))问:孙中山干了什么事?答:让位于***、发动护法运动、就任临时大总统问:清政府签订了哪些条约?答:天津条约、北京条约问:谁复辟了帝制?答:***
回答得相当不错。尽管当下这些问题是我特地挑选出来的,确定知识库里有正确的答案。不过当威廉希尔官方网站 发展完善,或许有一天,它真的能够走上考场,取得不错的成绩呢。
本文故事纯属虚构,近纲考砸却是真事。不过我会感谢这门课教给我的历史教训,还有带给我的本文写作灵感。
-
python
+关注
关注
56文章
4793浏览量
84634 -
识别威廉希尔官方网站
+关注
关注
0文章
203浏览量
19695 -
自然语言
+关注
关注
1文章
288浏览量
13347
原文标题:《中国近代史纲要》考试过关?Python帮你划重点
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
适配器输出电压异常、纹波过高、EMI传导不过关?这些窍门管用

2021年高压电工考试报名及高压电工考试资料相关推荐
2021年电工(初级)证考试及电工(初级)作业模拟考试相关资料分享
2021年电工(初级)报名考试及电工(初级)考试内容相关资料推荐
2021年电工(初级)考试及电工(初级)考试题库相关资料下载
划平行线和垂直线的导向工具
Python程序设计的考试大纲详细资料说明







 工商网监
工商网监
评论