 中山大学HCP实验室PAMI论文:低成本、可扩展的三维人体位姿预测应用
中山大学HCP实验室PAMI论文:低成本、可扩展的三维人体位姿预测应用
论文提出的3D人体位姿预测框架:先使用一个轻量级CNN提取2D人体位姿特征和粗略估计3D人体位姿,然后用RNN学习时序相关性以得到流畅的三维人体位姿初步预测结果,最后使用自监督学习引导机制,根据三维几何一致性,优化从2D到3D的预测结果。项目主页:http://www.sysu-hcp.net/3d_pose_ssl/
中山大学使用自监督学习精准预测三维人体位姿。新方法减少了对3D标记数据的依赖,还能通过使用现有的大量2D标记数据提高最终预测结果,实现低成本、可扩展的3D人体位姿估计实际应用。
3D人体位姿估计是当前的一个热点研究课题,也具有广泛的应用潜力。
深度神经网络已经在2D人体位姿估计上取得了优异的结果,如果想使用深度学习,在3D人体位姿估计中也取得同样的效果,那么首先就需要大量的3D人体位姿标记数据。
但问题是,现在没有大量带精准标记的3D人体位姿数据。
在一篇最新发表于《IEEE模式分析与机器智能会刊》(PAMI) 的论文[1]中,中山大学的研究人员提出了一种新的方法,让计算机通过自监督学习的方式,精准预测视频片段中的三维人体位姿,大幅减少对3D标记数据的依赖。
“我们通过有效结合二维时空关系和三维几何知识,提出了一个由自监督学习引导的快速精准三维人体位姿估计方法。”论文一作、目前在加州大学洛杉矶分校 (UCLA) 朱松纯教授实验室担任博士后研究员的王可泽博士告诉新智元。在完成这篇论文时,王可泽还是中山大学和香港理工大学的博士生,导师是中山大学HCP人机物智能融合实验室的林倞教授 (林教授也参与了这项工作) 和香港理工大学的张磊博士。
新方法在Human3.6M基准测试中的一些可视化结果。(a)为2D-to-2D位姿变换模块估计的中间3D人体位姿,(b)为3D-to-2D位姿映射模块细化的最终3D人体位姿,(c)为ground-truth。估计的3D位姿被重新映射到图像中,并在侧面 (图像旁边) 显示出来。如图所示,与(a)相比,(b)中预测的3D位姿得到了显著的修正。红色和绿色分别表示人体左侧和右侧。来源:论文《自监督学习引导的人体三维位姿估计》[1]
“该方法采用轻量级的神经网络,有效减少了计算量,并克服了三维人体位姿标注数据不够丰富的难点,能在实际应用场景中流畅稳定地进行三维人体位姿预测。”
在单个的Nvidia GTX1080 GPU上运行时,新方法处理一幅图像只需要51毫秒,而其他方法需要880毫秒。
使用自监督学习,减少对3D标记数据的依赖
这篇论文题为《自监督学习引导的人体三维位姿估计》(3D Human Pose Machines with Self-supervised Learning),作者是王可泽,林倞,江宸瀚,钱晨和魏朋旭。

研究人员向新智元介绍,他们这项工作的背景,是现有的基于彩色图像视频数据的三维人体位姿估计研究,在实际场景应用中有两大明显的不足:
一是所需要的计算量大:当前,绝大多数的现有三维人体位姿估计方法,都依赖最先进的二维人体位姿估计来获得精准的二维人体位姿,然后再构建神经网络,实现从2D到3D人体位姿的映射。由于采用的二维人体位姿估计方法往往需要庞大的计算量,再加上所构建的神经网络自身的运算开销,难以满足三维人体位姿估计在实际应用中的时间需求;
二是应用效果不理想:当前的三维人体位姿数据集都是在受控的实验环境下创建的 (摄像机视角固定、背景单一),所包含的三维标注信息不够丰富,不能全面反映真实生活场景,使得现有方法所预测出的三维人体位姿质量参差不齐,鲁棒性差。
为了解决上述的问题,研究人员进行了深入的研究和分析,尝试利用海量的二维人体位姿数据来弥补三维标注信息不丰富的问题。
同时,他们受二维和三维空间彼此存在的联系启发,根据三维人体位姿的映射是二维人体位姿这一几何特性,结合之前的自监督学习工作(参考王可泽博士等人此前的论文[2]),制定了2D到3D变换和3D到2D映射的自监督学习任务。
这一关键的2D和3D相互转换自监督学习模块架构示意如下:

3D到2D人体位姿映射模块训练阶段示意图

3D到2D人体位姿映射模块测试阶段示意图
在这项研究中,作者使用MPII数据集,从图像中提取2D人体位姿。然后,使用另一个名为“Human3.6M”的数据集,提取3D的ground truth数据。Human3.6M数据集包含有360万张在实验室拍摄的照片,任务包括跑步、散步、吸烟、吃饭,等等。
初始化后,他们将预测的2D人体位姿和3D人体位姿替换为2D和3D的 ground-truth,从而以自监督学习的方式优化模型。
3D-to-2D人体位姿映射模块的学习目标,就是将3D人体位姿的2D映射与预测的2D人体位姿两者间的差异最小化,以实现对中间3D人体位姿预测的双向校正 (或细化)。
“模型采用了序列训练的方法来捕获人体多个部位之间的长期时间一致性,并通过一种新的自监督校正机制进一步增强这种一致性,这包含两个对偶学习任务,即2D-to-3D位姿变换和3D-to-2D位姿映射,从而生成几何一致的3D位姿预测。”
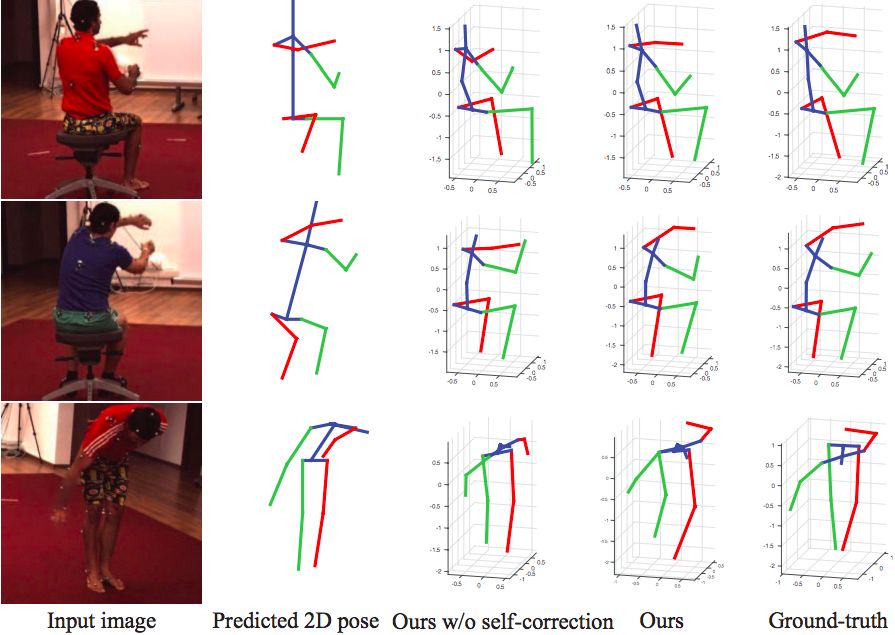
经过自监督校正以后的结果 (Ours) 比没有经过校正的 (Ours w/o self-correction) 更接近 Ground-truth。来源:论文
未来方向:非受限条件下三维人体位姿预测
研究人员在论文中指出,这项工作的主要贡献有三方面:
提出了一种新的模型,可以学习整合丰富的时空长程依赖性和3D几何约束,而不是依赖于特定的手动定义的身体平滑度或运动学约束;
开发了一种简单有效的自监督校正机制,以结合3D位姿几何结构信息;这一创新机制也可能启发其他3D视觉任务;
提出了自监督校正机制,使模型能够使用足够的2D人体位姿数据,显著提高3D人体位姿估计的性能。
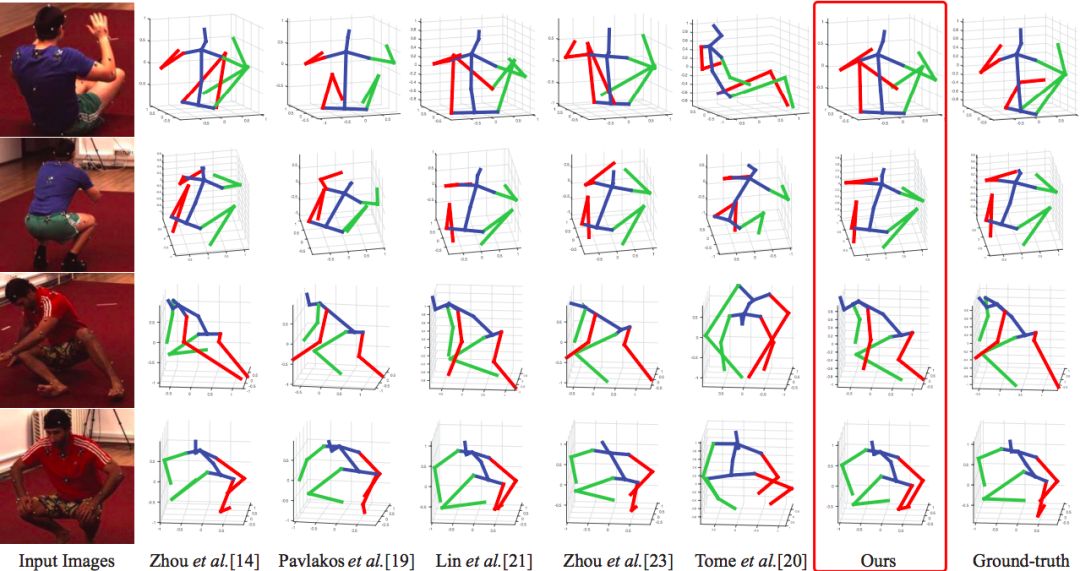
新方法 (Ours,红框标识) 显著优于其他同类方法,绿色代表右侧手脚,红色代表左侧 (下同):最右边一列为Ground-truth;使用Human3.6M数据集。

新方法 (Ours) 与ICCV-17微软危夷晨组在MPII数据集上的结果比较,后者使用弱监督迁移学习将2D和3D标记混合在一个统一的深度学习框架里,在2D和3D基准上都取得了较好的结果。新方法在3D预测上更进一步。
自监督学习的价值显然是人工智能研究的一个重点。
其他方法也采用了类似的“弱监督”方法来预测位姿,甚至捕捉人体运动。例如,加州大学伯克利分校Sergey Levine教授的机器人实验室去年10月发表论文称,他们能够训练interwetten与威廉的赔率体系 机器人模仿人类活动,只使用YouTube视频的无标注数据。中山大学的这一工作未来或许能与伯克利的方法实现某种结合。
研究人员告诉新智元,接下来,“我们会针对于实际非受限场景中更加复杂多变的三维人体位姿预测问题,开展进一步研究;另外,进一步优化我们的方法,希望能在移动端实现实时精准的预测效果”。
-
3D
+关注
关注
9文章
2878浏览量
107526 -
神经网络
+关注
关注
42文章
4771浏览量
100754
原文标题:中山大学新突破:自监督学习实现精准3D人体姿态估计
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器视觉教学创新实验室设备维视图像
[招聘]中山大学中山眼科中心招聘工程师
中山大学研发出首个基于人工智能的眼病筛查指导系统
中山大学应用基于RFID威廉希尔官方网站 的智能图书馆
中山大学提出新型行人重识别方法和史上最大最新评测基准

中山大学研发一种基于介孔微针离子泳的集成可穿戴诊疗一体化系统
高校大学数字孪生教学实验室,虚拟仿真实训系统中心

三维天地智能大脑解决方案助力实验室智慧化管理
三维天地助力计量实验室全方位资源管理
浙江大学机械工程学院—思看科技三维扫描实践教学实验室正式揭牌!

中山大学中山眼科中心与华为联合发布ChatZOC眼科大模型
千呼万唤始出来!中山大学-创龙教仪RK3568教学实验室项目正式落地!






 工商网监
工商网监
评论