 如何从头开始进行数据科学项目
如何从头开始进行数据科学项目
编者按:Zalando研究工程师Jekaterina Kokatjuhha通过解决现实生活的实际问题,介绍了如何从头开始进行数据科学项目。
网上有许多关于数据科学和机器学习的教程,它们涉及的实操案例往往离不开讲解理论,提供一些代码,然后分析很干净的数据。
但是,如果你想开始实践数据科学,最好的方法其实是选取一个真实生活问题,深入数据以寻找深刻的洞见,用额外的数据来源进行特征工程,创建可独立运行的机器学习工作流。
这篇博客文章将讲解从头创建数据科学项目的主要步骤。它基于现实生活问题——柏林租金高低的主要决定因素是什么?我们将分析这一情况,并列出机器学习初学者常犯的错误。
下面是我们将详细讨论的步骤:
寻找主题
自web提取数据并清洗
取得深入的洞见
基于外部API进行特征工程
从事机器学习时常犯的错误
特征重要性:找到主导租金高低的因素
创建机器学习模型
寻找主题
有许多问题都可以通过分析数据解决,不过寻找一个你感兴趣并能给你提供动力的问题总是最好的。搜寻主题时,毫无疑问,你应该重点关注自己的偏好和兴趣。
不过,我建议你不仅关注自己的兴趣,也听听周围的人在谈论什么。什么给他们造成了困扰?他们在抱怨什么?这是数据科学项目的又一个灵感来源。如果人们在抱怨,那也许意味着现有方案并没有很好地解决人们的问题。因此,如果你尝试基于数据分析来处理这一问题,你可能提供一个更好的解决方案,影响人们对这一主题的看法。
这些听起来也许都比较抽象。所以让我谈谈自己是如何想到分析柏林的租金的。
“早知道这里的租金这么高,我报期望薪资的时候会报一个更高的价格。”这是我从最近搬到柏林工作的人那里听到的话。大多数刚搬到柏林的人抱怨他们没想到柏林的生活成本这么高,也没有关于公寓可能价格范围的统计数据。如果他们事先知道这一点,他们在工作申请过程中本可以报一个更高的价,或者考虑其他选项。
我在网上搜索了一番,也查看了若干租房网站,也问了一些人,但都没能找到关于当前市场价格的合理统计数据或可视化。所以我萌生了自己进行分析的想法。
我想要收集数据,创建一个面板,这个面板会根据你选择的条件(例如,40平方米,米特区,带阳台、炊具齐全的厨房)显示价格范围。这本身就有助于人们理解柏林的房租价格。另外,通过应用机器学习,我将能识别决定房租价格的因素,并练习不同的机器学习算法。
自web提取数据并清洗
获取数据
在对要做数据科学项目有一个概念之后,我们可以开始寻找数据了。网上有特别多很棒的数据仓库,例如Kaggle、UCI ML、数据集搜索引擎、收录学术论文及其数据集的网站。此外,你可以爬取网站数据。
不过,小心——旧数据到处都是。我在搜索关于柏林房租的信息的时候,找到了许多可视化结果,但它们或者比较陈旧,或者没有指明年份。
有些统计甚至注明只统计了不带家具的50平方米的两室公寓的租金。如果我想要一个带装修好了的厨房的较小的公寓呢?
由于我只找到了旧数据,所以我决定爬取租房网站的信息。关于爬取网站信息,我专门写了一篇博客,讨论其细节、缺陷、设计模式:https://hackernoon.com/web-scraping-tutorial-with-python-tips-and-tricks-db070e70e071
要点是:
在爬取之前,检查下是否有公共API可用。
文明爬取!不要在一秒内发送数百个请求使网站过载。
在提取信息的过程中及时保存数据。
数据清洗
一旦开始获取数据,非常重要的一点是及早查看数据,以便尽早找出可能存在的问题。例如,爬取程序可能漏掉了一些重要的字段,保存程序至文件时,如果使用逗号作为分隔符,而原数据中也包含逗号,如果没有正确处理,最终文件的格式会出现错乱。
在爬取租房信息的时候,我的爬取程序内置了一些小小的检查措施,查验所有特征的缺失值数目。站长可能会更改网站的HTML结构,导致爬取程序无法获取任何数据。
确保考虑了网站爬取的所有威廉希尔官方网站 方面的问题之后,我本以为数据基本上是理想的。然而,我最终花了大约一周清洗所有数据,因为数据当中包含一些隐蔽的重复条目。
理想和现实
出现重复条目的原因有:
多次展示的同一间公寓
中介输入时输错了信息,比如租金或楼层。之后他们有时会更正信息,有时会重新发布一条包含正确信息的新广告。
同一间公寓的价格在一个月后会变动(涨价或降价)。
尽管第一种情形很容易识别(通过ID),第二种情形非常复杂。原因在于中介可能略微修改描述,改动错误的价格,并作为新广告发布,因此ID也会是新的。
我设计了许多规则来识别这种情况。一旦识别出这些公寓其实是重复条目,我会根据日期对这些条目进行排序,选择最新发布的条目。
此外,有些中介会在一个月后调整同一间公寓的房租。我听说如果无人问津,那么会降价,相反则会涨价。
取得深入的洞见
一切就绪之后,我们可以开始分析数据了。我知道数据科学家喜欢seaborn和ggplot2,还有其他许多静态可视化工具。
然而,可交互面板有助于你本人和其他利益相关人找出有用的洞见。这方面有许多非常棒的易用工具,例如Tableau和Microstrategy。
我花了不到30分钟就创建了一个交互式面板,可以根据选择的条件显示价格范围。
这样一个相当简单的面板已经可以为刚来柏林的人提供不少关于房租的洞见,如果租房网站能提供这样一个工具,应该也会吸引不少用户。
我们从数据可视化中已经能看到,从租金分布上来说,2.5房公寓的租金总体上反而低于2房公寓。原因在于大多数2.5房公寓不在市中心。
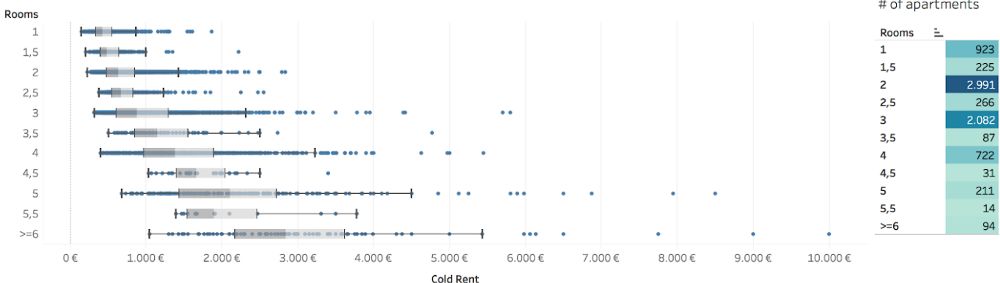
基于外部API进行特征工程
可视化有助于识别重要属性,或“特征”,这些特征可以为机器学习算法所用。如果用到的特征包含很少信息,任何算法都不能给出良好的预测。如果特征很给力,即使非常简单的算法也能得到相当不错的结果。
在房租项目中,价格是一个连续变量,所以通常而言这是一个回归问题。我从提取的信息中收集了特征,以预测租金。
然而,这里有一个特征比较麻烦——地址。总共有6千6百间公寓,位于4千4百个不同粒度的地址。我们可以按邮政编码划分地址,然后将其转换为独热编码,不过这会损失特定位置的精确信息。

不同粒度的地址:详细地址;只有街名,门牌号隐藏;只有邮政编码
当你得到一个新地址的时候,你会做什么?
你要么搜一下它在哪里,要么搜下如何去哪里。
通过使用外部的API,我们可以根据公寓地址计算:
到柏林腓特烈大街站(中央车站)坐火车要多久?
到柏林市中心站的汽车行车距离
到最近地铁站步行要多久?
公寓方圆一公里内的地铁站数量
这四个特征显著提升了模型的表现。
从事机器学习和数据科学项目时常犯的错误
爬取或获取数据之后,在应用机器学习模型之前还有许多步骤需要完成。
我们需要可视化每个变量,看看它们的分布,找到离群值,并理解为何存在这些离群值。
如何处理具体特征中的缺失值?
将类别变量转换成数值的最佳方式是什么?
有许多类似这样的问题,但我会详细解释大多数初学者容易犯错的那些问题。
1. 可视化
首先,你应该可视化连续特征的分布,以大概了解是否有许多离散值,变量的分布是什么样的,以及这些是否有意义。
有许多可视化分布的方式,例如,箱形图、直方图、累积分布函数、提琴形图。然而,你应该选择能够提供最多关于数据的信息的图形。
基于图形,最值得注意的问题是:你看到你想要查看的东西了吗?回答这个问题有助于你找到关于数据的洞见或bug。
我经常从Python的seaborn图片库中汲取该使用哪种图形的灵感。另一个很好的灵感来源是Kaggle网站上的kernel。
就租金而言,我绘制了每个连续特征的直方图,期望可以在大多数特征上看到长尾。
箱形图有助于查看每个特征的离群值。事实上,大部分离群值要么是大于200平方米的工坊,要么是租金极低的学生宿舍。
2. 是否需要根据整个数据集填充缺失值?
由于多种原因,有时候会有缺失值。如果我们排除所有包含至少一个缺失值的观测,我们最终会得到一个缩水很多的数据集。
有许多填充缺失值的方式,比如使用均值,中位数。应该怎么做完全取决于你,但需确保只根据训练数据计算填充值,以防数据泄露。
租金数据同时提取了关于公寓的描述。如果公寓品质、状况、类型缺失,且描述包含相关信息,我会根据描述填充这些缺失值。
3. 如何转换类别变量?
取决于具体实现,某些算法无法直接处理类别数据,需要以某种方式将其转换为数值。
有许多转换类别变量至数值特征的方式,例如标签编码、独热编码、bin编码和哈希编码。然而,大多数人在应该使用独热编码的时候会误用标签编码。
例如,假定租金数据中公寓类型列具有下列值:[底楼, 阁楼, 复式, 阁楼, 阁楼, 底楼]。标签编码将其转为[3, 2, 1, 2, 2, 1],这就引入了顺序,即底楼 > 阁楼 > 复式。在决策树及其变体之类的一些算法上,这种特征编码方式没什么问题,但应用回归算法和SVM也许就会出问题。
在租金数据集中,状况编码为:
新:1
翻新:2
需要翻新:3
品质则编码为:
奢侈:1
优于平常:2
平常:3
简单:4
未知:5
4. 我需要标准化变量吗?
标准化将所有连续变量缩放至同一尺度,也就是说,假设一个变量的取值范围是一千到一百万,另一个变量的取值范围是0.1到1,标准化之后这两个变量的取值范围会一样。
L1或L2正则化是缓解过拟合的常用方式,可用于多种回归算法。然而,在应用L1或L2之前先标准化特征很重要。因为L1或L2会惩罚较大的系数,如果没有标准化,单位较小的系数会受到更多惩罚。
另外,如果算法使用梯度下降,那么标准化特征后梯度下降能够更快收敛。
5. 我需要对目标变量取对数吗?
我花了一段时间才明白这个问题没有统一的答案。
它取决于很多因素:
你想要的是百分比误差还是绝对误差
你用的是什么算法
残差图和测度的变化告诉了你什么
在回归问题中,首先关注残差图和测度。有时候,目标变量的对数导向一个更好的模型,并且模型的结果仍然容易理解。然而,还有其他值得关注的变换,比如取平方根。
Stack Overflow上有很多关于这个问题的回答,我觉得EdM的回答解释得很好:https://stats.stackexchange.com/a/320213
我在租金数据上,对价格取了对数,这样残差图看起来要好一点。
左:取对数;右:未转换数据
6. 更多重要事项
有些算法,比如回归算法,当系数变得非常不稳定时,会陷入数据的共线性问题。更多数学方面的讲解可以参考:http://www.stat.cmu.edu/~larry/=stat401/lecture-17.pdf 取决于核的选取,SVM也许会也许不会受此困扰。
基于决策树的算法不会碰到多重共线性问题,因为它们可以在不同树中交换特征而不影响表现。然而,特征重要性的解读会变得更困难,因为相关变量可能显得不那么重要。
机器学习
监督机器学习有许多算法可供选择,我打算探索三种不同的算法,比较下它们的表现和速度。这三种算法是梯度提升(XGBoost和LightGMB)、随机森林(scikit-learn的实现)、3层神经网络(基于TensorFlow框架)。由于我对目标变量取了对数,因此我选择了RMSLE作为优化过程的测度。
XGBoost和LightGBM的表现相当,随机森林略差,而神经网络的表现是最差的。
算法在测试集上的表现(RMSLE)
基于决策树的算法在解读特征上非常方便,它们可以生成特征重要性评分。
特征重要性:找到决定租金的因素
使用基于决策树的模型拟合数据后,我们可以查看哪些特征在价格预测中起的作用最大。
特征重要性提供了一个评分,这个评分指示了在构建模型中的决策树时,每个特征的信息量有多大。计算这种评分的一种方式是算下一种特征在所有树中多少次用于分割数据。当然,也可以用不同的方法计算评分。
特征重要性可以揭示其他关于决定价格的主要因素的洞见。
就租金预测而言,总面积是最重要的决定价格的因素,这并不令人意外。有意思的是,一些利用外部API构建的特征同样属于最重要的特征。
然而,Scott Lundberg在Interpretable Machine Learning with XGBoost(基于XGBoost的可解释的机器学习)中指出,不同的选项(测度)可能得出不一致的特征重要性。Scott Lundberg在NIPS 2017上提出了一种新的兼具精确性和一致性的计算特征重要性的方法,并提供了这一方法的开源Python实现SHAP。
基于SHAP得到的特征重要性分析如下:
x轴位置表示特征对模型预测的影响,颜色表示特征值的大小
上图包含大量信息:(声明:数据采集自2018年初,之后的情况可能有变动)
离市中心越近(到柏林腓特烈大街站坐火车花费的时间和到柏林市中心站的汽车行车距离),预测租金越高
总面积是最强的决定因素
如果公寓主要求你有低收入证明(德国的WBS),预测价格会比较低
下面这些区域的租金较高:Mitte、 Prenzlauer Berg、Wilmersdorf、Charlottenburg、Zehlendorf and Friedrichshain
下面这些区域的租金较低:Spandau、 Tempelhof、Wedding、 Reinickendorf
显然,状况较好(特征值较低意味着较好)、品质较好(特征值较低意味着较好),家具齐全,内置厨房,有电梯的公寓租金是最贵的。
比较有意思的是下面两个特征的影响:
到最近地铁站步行时间
方圆一公里内的地铁站数量
到最近地铁站步行时间
看起来,对某些公寓而言,较高的特征值意味着价格较高。原因在于,这些公寓位于柏林外富裕的住宅区。
我们也能看到,靠近地铁站既拉高租金又降低租金。原因可能是靠近地铁站的公寓出行更方便,但噪音比较大。我们可以进一步探索这一点,比如考虑到最近的公交站的步行时间。
方圆一公里内的地铁站数量这一特征同理。
集成平均
在探索了不同的模型并比较其表现后,我们可以组合每个模型的结果,创建一个集成模型!
Bagging是利用多种算法的预测计算最终的聚合预测的机器学习集成模型。它的设计有助于防止过拟合并降低算法的方差。
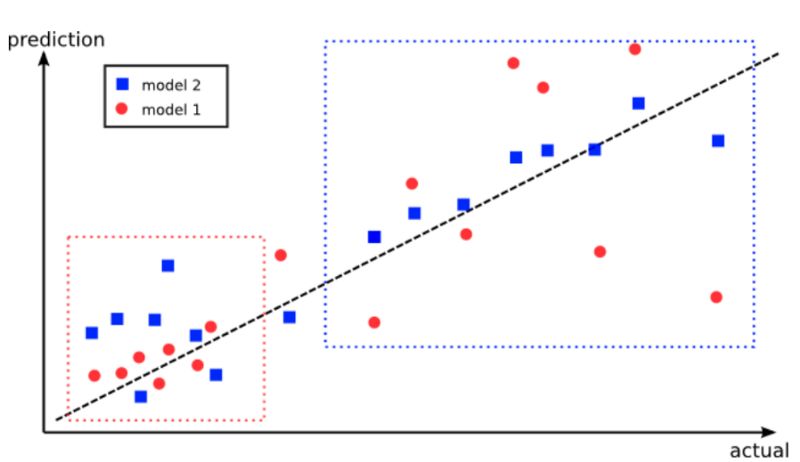
集成模型的优势;图片来源:burakhimmetoglu.com
由于我已经具备了上述算法的预测,我尝试了这些算法的各种组合方式,基于在验证集上的RMSLE得出了7个最佳模型。
然后在测试集上计算这7个模型的RMSLE。
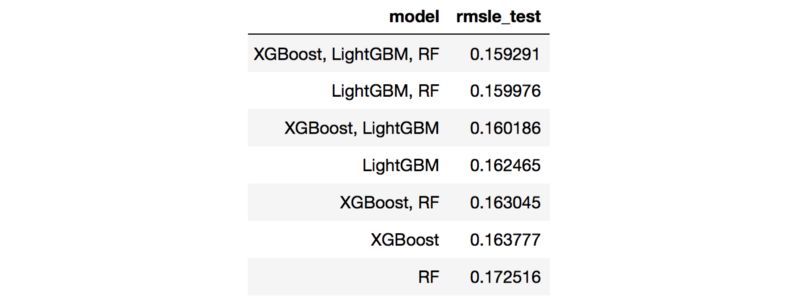
相比之下,集成三种基于决策树的模型表现最佳。
我们也可以构建一个加权集成模型,给表现更好的单个模型更多的权重。背后的依据是,仅当其他模型在另一种替代预测上取得一致时,才能压过最佳模型一头。
在现实中,如果不进行尝试,我们永远不会知道平均集成会比单个模型的效果更好。
堆叠模型
平均或加权集成并不是组合不同模型预测的唯一方法。我们还能以不同方式堆叠模型!
堆叠模型背后的思路是创建若干基础模型,然后创建一个元模型,元模型根据基础模型的结果生成最终预测。然而,如何训练元模型并不是显而易见的,否则元模型很容易偏向最佳的基础模型。burakhimmetoglu写的Stacking models for improved predictions(堆叠模型以改进预测)很好地解释了如何正确地做到这一点。
在我们的租金预测中,堆叠模型完全没有提升RMSLE——甚至结果更差了。可能的原因有很多——也许我的代码写错了;),或者堆叠引入了过多噪声。
如果你对更多关于集成模型和堆叠模型的内容感兴趣,Triskelion的文章Kaggle Ensemble Guide(Kaggle集成指南)讲解了许多不同种类的集成方法,并比较了它们的表现,也讨论了堆叠模型是如何成为Kaggle竞赛的王者。
总结
留心周围人谈话的内容;他们抱怨的东西可能给你提供启发。
提供可交互的面板让人们找到自己的洞见。
不要让自己局限于常见的特征工程方法,比如将两个变量相乘。尝试寻找其他数据来源或解释。
尝试集成模型和堆叠模型,因为这些方法可能可以提升表现。
最后,别忘了提供数据的日期!
-
可视化
+关注
关注
1文章
1194浏览量
20942 -
机器学习
+关注
关注
66文章
8418浏览量
132630 -
数据科学
+关注
关注
0文章
165浏览量
10059
原文标题:以房租分析为例:如何从头创建数据科学项目
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
MikroElektronika的mikroBUS Click板是否从头开始的制作?
使用MHC从头开始构建项目时无法连接到TCP IP Stack
ARM嵌入式系统设计:从头开始构建还是使用SBC?
能否连接JTAG调试器并从头开始对MCU进行编程,因为MCU上没有旧代码?
DMA进行数据传输和CPU进行数据传输的疑问
PyTorch教程4.4之从头开始实现Softmax回归

PyTorch教程-3.4. 从头开始执行线性回归

PyTorch教程-4.4. 从头开始实现 Softmax 回归






 工商网监
工商网监
评论