 赛灵思发布自适应计算加速平台芯片系列Versal
赛灵思发布自适应计算加速平台芯片系列Versal
2018年10月16日,FPGA大厂赛灵思(Xilinx)在北京召开了一年一度的“Xilinx开发者大会 ”(XDF) 。在本次会议上,赛灵思发布了全球首款自适应计算加速平台 (Adaptive Compute Acceleration Platform ,ACAP)芯片系列Versal。与此同时,赛灵思还针对云端和本地数据中心市场还发布了一款功能强大的加速器卡——Alveo。至此,赛灵思的转型大幕正式开启,而人工智能则是赛灵思转型的最大推力。
AI推断需求暴涨,推动FPGA市场加速增长
目前,人工智能可谓是非常的火爆。而数据的爆发式增长,人工智能算法的不断完善以及芯片算力的快速增长,则是推动人工智能应用爆发的三大关键因素。
随着人工智能计算的快速发展,自去年以来更是出现了一股AI芯片的热潮。由于传统的CPU、GPU已经开始难以满足越来越多的新的需求,并且在AI计算能效上也开始处于劣势。在此形势之下,半定制的FPGA和定制型的ASIC开始迎来了高速的发展。
虽然ASIC芯片的计算能力和计算效率都直接根据特定的算法的需要进行定制的,可以实现体积小、功耗低、计算性能高、计算效率高等优势,但是人工智能仍在快速发展,每天都会有不少新的算法/模型出现,很多领域都还没有一个标准的算法。
而ASIC芯片则是针对特定算法的需要进行设计的,设计一旦完成就无法修改,通常一颗ASIC芯片从设计到量产一般都需要18-24个月的时间,这也意味着当这款ASIC芯片量产之时,可能就已经落后于当下算法发展的18-24个月的时间。相比之下,FPGA则没有这个问题。
另外,在市场需求变化越来越快速的当下,客户都希望产品能够在快速创新的同时,尽可能的实现快速上市。FPGA作为一种可编程的半定制芯片,其与GPU一样具有并行处理优势,并且也可以设计成具有多内核的形态,当然其最大的优势还是在于其可以通过软件编程的手段更改、配置器件内部连接结构和逻辑单元,完成既定设计功能的数字集成电路。这也意味着即使是出厂后的FPGA的逻辑块和连接,开发者若要适应新的AI算法或者实现新的功能应用,只需通过升级软件就可重新配置这些芯片,可以更加快速的适应市场的需求。
虽然GPU也可灵活的适应各种AI算法,但是能效很低。而GPU虽然被广泛的用于深度学习领域,但是需要指出的是,其主要被应用在深度学习的训练环节,在推理时对于小批量数据,并行计算的优势不能发挥出来。但而FPGA同时拥有流水线并行和数据并行,因此处理推理任务时候可以时延更低。
根据赛灵思在会上公布的来自Barclays Reseach于今年5月公布的数据显示,目前人工智能市场主要来自于“训练”的需求,不过自2019年开始来自“推断”(包括数据中心和边缘端)的需求将会持续快速爆发式增长。而“训练”的需求增长将会逐渐放缓,并趋于停滞。到2021年来自“推断”的市场规模将会首次超过“训练”,之后2023年将达到“训练”市场的三倍左右。
另外有数据显示,未来至少95%的AI计算都是用于“推断”,只有不到5%是用于模型“训练”。
赛灵思软件及IP产品执行副总裁Salil Raje
赛灵思软件及IP产品执行副总裁Salil Raje也指出:“今后AI模型必须应用在云端和边缘的模型上,所以未来的模式更多的是推断,而不是训练。赛灵思关注的就是推断。”
而“推断”则是FPGA的优势。其可以在大幅提升推能效、降低功耗(韩国SK电讯的NUGU个人助理服务器原来采用的是GPU来进行AI加速,在采用赛灵思的FPGA之后,实现了每瓦性能比原本的GPU方案提升了16倍)的同时,还可降低精度损失,同时其还拥有出色的灵活性和低延时特性。不难想象,随着AI“推断”需求的快速增长,FPGA市场也有望迎来高速成长。
赛灵思VR Ramine在会后接受专访时也表示:“虽然GPU现在在深度学习训练这一块应用非常多,但是它的功耗很高,而且这个市场已经处于比较饱和的状态。而赛灵思并不是特别关注训练这个市场,我们更多关注的是推断这部分的市场,这个市场仍然处于初期上升期,尤其在推断在加速应用这方面刚刚处于一个快速增长的阶段,特别是在数据中心和边缘计算领域。在推断这块市场,GPU用的并不多。虽然CPU有一定的市场份额,但是性能、能效和时延也并不好。所以为什么赛灵思在推断这个领域,包括在智慧城市、自动驾驶车领域已经有了很多的客户。”
而作为FPGA市场的老大(占据了近60%的市场份额),赛灵思也将成为最大的受益者。在AI异常火爆的当下,此次赛灵思的开发者大会也是备受行业内外的广泛关注,会议现场更是人气爆棚,近千人的会场是座无虚席。
超越FPGA,迎来全新物种ACAP
虽然FPGA拥有很多的优势,但是不可否认的是,FPGA的基本单元的计算能力是有限的。为了实现可重构的特性,FPGA内部有大量极细粒度的基本单元,但是每个单元的计算能力(主要依靠LUT查找表)都远远低于CPU和GPU中的ALU模块。另外,在计算的效率和功耗上FPGA也要低于ASIC。
随着越来越多的应用趋向于既具高速处理又兼具灵活性的系统,FPGA厂商为了弥补单纯采用FPGA的缺陷,开始推出整合了CPU/GPU/RF/FPGA的异构SoC的融合性方案。
比如赛灵思此前就曾推出了多处理器SoC(MPSoC,在FPGA上整合了Arm的CPU内核,还有Mali系列的GPU等)、RFSoC(将通信级RF采样数据转换器、SD-FEC内核、Arm处理器以及 FPGA 架构整合到单芯片器件中)。而为了能够帮助更多的用户和开发者提供更为强大的计算平台,今年3月,赛灵思还发布了全新的超越FPGA功能的突破性新型产品——ACAP自适应计算加速平台。
赛灵思软件及IP产品执行副总裁Salil Raje表示:“赛灵思在过去三十年当中一直引领FPGA行业的发展。FPGA是非常强大的,灵活度非常好,但是现在我们面临着海量的数据,摩尔定律已经不再有效了,现在没有任何一个单一的计算架构能够适应如此海量的数据。我们需要进入一个异构计算的时代,需要各种各样的计算架构才能解决现在所面临的挑战。ACAP就是我们为了解决这项挑战所推出的具有颠覆性的创新型产品。”
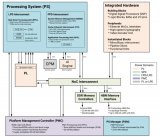
据介绍,ACAP结合了分布式存储器与硬件可编程的DSP 模块、一个多核SoC 以及一个或多个软件可编程且同时又具备硬件自适应性的计算引擎,并全部通过片上网络(NoC,Network on Chip)实现互连。
赛灵思在现场展示的112G高速收发器演示
ACAP还拥有高度集成的可编程I/O功能,根据不同的器件型号这些功能从集成式硬件可编程存储器控制器,到先进的SerDes收发器威廉希尔官方网站 (最高可支持112Gbps),前沿的RF-ADC/DAC和集成式高带宽存储器(HBM)。
软件开发人员将能够利用C/C++、OpenCL 和Python 等软件工具应用ACAP系统。同时,ACAP也仍然能利用FPGA工具从RTL级进行编程。
赛灵思总裁兼首席执行官Victor Peng
赛灵思总裁兼CEOVictor Peng强调:“ACAP是一个全新的产品类别,它不是一个品牌的名称,也不是FPGA。ACAP是可扩展的一体化程度非常高的计算平台,它的硬件和软件都是可编程的。也就是说,你可以用它来实现你想要的架构来优化网络、优化算法,优化应用。也可以在几秒甚至几毫秒内改变这个架构,它能够实现非常低的延时,非常高的通量,和原来产品类别有很大差异。”
全球首款ACAP——Versal系列
在此次的赛灵思开发者大会上,赛灵思正式发布了其历时4年开放出的全球首款自适应计算加速平台(ACAP)产品——Versal系列。其整合了标量处理引擎、自适应硬件引擎和智能引擎以及前沿的存储器和接口威廉希尔官方网站 ,能为所有的应用提供强大的异构加速功能。
赛灵思称Versal ACAP独特架构针对云端、网络、无线通信乃至边缘计算和端点等不同市场的众多应用提供了可扩展性和 AI 推断功能,将为所有的开发者开发任何应用开启了一个快速创新的新时代。
具体来说,Versal系列产品均基于台积电最新的7nmFinFET工艺,是第一个将软件可编程性与特定领域硬件加速和灵活应变能力相结合的平台。该产品组合包括了6个系列的器件:基础系列(Versal Prime),旗舰系列(Versal Premium旗舰)系列和HBM系列(能针对要求最严格的应用提供业界领先的性能、连接性、带宽和集成功能)。此外,该产品组合还包括AI核心系列(AI Core),AI边缘系列( AI Edge) 和AI射频系列(AI RF),Versal AI系列均采用了突破性的AI引擎。
据赛灵思介绍,ACAP的AI引擎是一种新型硬件模块,专为解决各种应用低时延 AI 推断的新需求而设计,同时支持高级DSP实现方案,满足无线和雷达等应用要求。它与Versal的自适应硬件引擎紧密结合,支持整体应用加速,也就是说软硬件都能调节,从而确保最高性能和效率。
不过,此次开发者大会上,赛灵思只发布了Versal基础系列和Versal AI核心系列,这两款芯片有望在今年年底流片。而Versal旗舰系列和AI Edge将会在明年上半年发布;AI RF系列将会在明年下半年发布。至于Versal HBM系列可能要等到2021年下半年才会发布。
Versal AI核心系列
据赛灵思介绍,Versal AI核心系列可提供Versal AI系列当中最高的计算性能和最低的时延,可实现突破性的 AI 推断吞吐量和性能。该系列主要针对云端、网络和自动驾驶威廉希尔官方网站 进行了优化(支持L4级别的自动驾驶),可提供业界最广泛的 AI 和工作负载加速功能。
Versal AI 核心系列有5款产品,可提供128到400个AI引擎。
该系列还包括双核 Arm Cortex-A72 应用处理器、双核 Arm Cortex-R5 实时处理器、256KB片上ECC存储器、超过1900个专为高精度低时延浮点运算而优化的 DSP引擎。
此外,它还包括 190 多万个系统逻辑单元以及超过 130Mb 的 UltraRAM、高达 34Mb 的块 RAM 和 28Mb 分布式 RAM 和 32Mb 新加速器 RAM 块,任何引擎都能直接访问,这也是 Versal AI 系列的独特之处,而且都能支持定制存储器架构。
该系列还包括 PCIe Gen4 8 信道和 16 信道以及 CCIX 主机接口、功耗优化型 32G SerDes、多达 4 个集成型 DDR4 存储器控制器、多达 4 个多速率以太网 MAC、650 个高性能 I/O(用于 MIPI D-PHY)、NAND、存储级内存接口和 LVDS、78 个多路复用 I/O(连接外部组件)和超过 40 个 HD I/O(3.3V 接口)。
以上所有器件均通过业界一流的片上网络 (NoC) 实现互联,具有多达 28 个主/从端口,以低时延提供每秒多 Tb 带宽,而且提供高功率效率和原生软件的可编程性。
Versal基础系列
相对于Versal AI核心系列来说,Versal基础系列最大的不同就是没有了AI内核,取而代之的则是更大面积的DSP,并针对各种工作负载的连接性和在线加速进行了优化。适用于多个市场的广泛应用。
Versal基础系列包括 9 款产品,每款产品都采用双核Arm Cortex-A72 应用处理器、双核 Arm Cortex-R5 实时处理器、256KB 片上存储器(带 ECC)、超过 4000 个专为低时延高精度浮点运算优化的 DSP 引擎。
此外,它还包括 200 多万个系统逻辑单元,结合 200Mb 以上 UltraRAM、超过 90Mb 的块 RAM 以及 30Mb 分布式 RAM,能支持定制存储器架构。该系列还包括 PCIe®Gen4 8信道和 16 信道以及 CCIX 主机接口、功耗优化型 32Gb 每秒的 SerDes 和主流 58Gb 每秒的 PAM4 SerDes、多达 6 个集成型 DDR4 存储器控制器、多达 4 个多速率以太网 MAC、700 个高性能 I/O(支持 MIPI D-PHY)、NAND、存储级内存接口和 LVDS、78 个多路复用 I/O(连接外部组件)和超过 40 个 HD I/O(3.3V 接口)。
以上均通过业界一流的片上网络 (NoC) 实现互联,具有多达 28 个主/从端口,以低时延提供每秒多 Tb 带宽,而且提供高功率效率和原生的软件可编程性。
性能对比
从上面的介绍来看,作为目前赛灵思ACAP的首款产品Versal系列,其各项指标和参数都很出色。那么其AI性能与目前主流的高端CPU和GPU相比又如何呢?
根据赛灵思公布的数据显示,在时延不敏感的AI推断上,基于GoogleNet-V1网络模型测试,Versal的CNN性能是英特尔Xeon Platinum8124 CPU的43倍,是Nvidia V100 GPU的两倍。
如果要将时延控制在7ms以内,那么Versal系列的CNN性能优势将会进一步提升,达到英特尔XeonPlatinum8124Skylake CPU的72倍,Nvidia V100 GPU的2.5倍。
如果将时延控制在更低的2ms之内,那么Versal系列的CNN性能将达到Nvidia V100 GPU的8倍。
以基于GoogleNet-V1网络低于2ms时延的图片识别测试下,Versal核心系列可以实现每秒22500张图片的识别,相比Nvidia今年发布的TeslaT4 GPU的性能(每秒3500张)高出约6.5倍。
如果再加上赛灵思收购的深鉴科技的“剪枝威廉希尔官方网站 ”的加持,Versal核心系列在2ms以内的低时延图像识别上的性能可进一步提升至每秒29250张,相比Nvidia TeslaT4 GPU的性能可高出8倍以上。
Versal工具和软件
软件开发者、数据科学家和硬件开发者均可通过C/C++、OpenCL 和Python 等软件工具应用对Versal ACAP的硬件和软件进行编程和优化,同时,ACAP也仍然能利用FPGA工具从RTL级进行编程。开发者用一个界面就可以接入和控制各种引擎。这都要归功于其符合业界标准设计流程的一系列工具、软件、库、IP、中间件和框架。
不过,具体的软件编程工具需要等到明年才会发布。
供货情况
赛灵思目前正通过早期试用计划与多家关键客户合作。Versal基础系列和Versal AI核心系列将于今年年底流片,预计2019年下半年上市。
加码数据中心,Alveo速器卡发布
除了发布了全新的Versal系列之外,赛灵思此次还首次推出了针对数据中心设计的功能强大的加速器卡——Alveo。用户在通过Alveo运行实时机器学习推断以及视频处理、基因组学、数据分析等关键的数据中心应用时,有望以较低时延实现突破性的性能提升。
此次赛灵思发布了两款Alveo加速卡:Alveo U200和AlveoU250。不过这两款产品并不是采用Versal系列芯片,而是采用的是赛灵思UltraScale+FPGA方案。不过,其与所有赛灵思威廉希尔官方网站 一样,客户能对硬件进行重配置,从而针对工作负载迁移、新标准和更新的算法进行优化,而且无需支付替代产品衍生的成本。
据赛灵思介绍称,Alveo加速器卡针对各种类型的应用提供显著的性能优势。就机器学习而言,在GoogLeNet V1网络下,Alveo U250实时推断吞吐量比英特尔Xeon Platinum Skylake CPU(c5.18xlarge 实例)高出20倍,相对于Nvidia V100 GPU等固定功能的加速器,能让2ms以下的低时延应用性能提升4倍以上。
此外,Alveo 加速器卡相对于 GPU 能将时延减少 3 倍,在运行实时推断应用时提供显著的性能优势。比如在CNN+BLSTM 语音转文本应用时,可从根本上得到加速(Alveo U250 或 U200 +Intel Xeon CPU E5-2686 v4 的运行速度是 Nvidia P4 + Xeon CPU E5-2690v4 的 4 倍);数据库搜索等一些应用可从根本上得到加速,性能比CPU(EC2 C4.8xlarge 实例)高90倍以上。
“Alveo加速器卡第一是速度快;第二是架构和算法灵活多变;第三是容易访问、易于使用。”对于Alveo加速器卡的特点Victor Peng总结到。
据赛灵思介绍,Alveo已经得到了合作伙伴和 OEM 厂商生态系统的支持,OEM 厂商开发和认证的关键应用涵盖 AI/ML、视频转码、数据分析、金融风险建模、安全和基因组学等。Algo-Logic Systems Inc、Bigstream、BlackLynx Inc.、CTAccel、Falcon Computing、Maxeler Technologies、Mipsology、NGCodec、Skreens、SumUp Analytics、Titan IC、Vitesse Data、VYUsync 和 Xelera Technologies等14家生态系统合作伙伴开发完成的应用可立即投入部署。此外,顶级 OEM 厂商也在同赛灵思合作,认证采用 Alveo 加速器卡的多个服务器 SKU,包括 Dell EMC、Fujitsu Limited 和 IBM 等,此外还有 OEM 厂商会加入进来。
赛灵思的数据中心副总裁 Manish Muthal 指出:“Alveo加速器卡的推出进一步推进了赛灵思向平台公司的转型,使不断增长的应用合作伙伴生态系统以比以往更快的速度加速创新。我们很高兴客户对Alveo加速器的高度兴趣,也很高兴与我们的应用生态系统展开合作,共同向客户推出采用Alveo的各种可产品化的的解决方案。”
另外值得一提的是,在此次赛灵思开发者大会上,华为和浪潮也发布了基于赛灵思的FPGA打造自己加速卡产品。
转型平台厂商
赛灵思总裁兼首席执行官(CEO)Victor Peng 表示:“自从赛灵思发明FPGA到现在已经有三十多年的时间,FPGA也变得越来越强大和复杂,我们现在已经超越了FPGA。赛灵思已经不再是一家FPGA的企业,我们已经转型为一家面向灵活应变、万物智能世界的平台公司,而且我们这个转型也要超越FPGA这个器件来打造整个平台,因为这将使得我们能够更好的满足客户的需求,尤其是在当今这个高速变化时代。”
为了顺利的转型为一家平台型公司,Victor Peng将“数据中心优先”、加速核心市场发展和驱动灵活应变的计算这三个方面作为了赛灵思公司战略转型的进一步深入。
在此次开发者大会上,赛灵思发布的全球首款自适应异构计算加速平台ACAP Versal以及针对数据中心的Alveo加速器卡,也正是赛灵思转型平台厂商新战略的进一步深化。特别是ACAP更是被赛灵思寄予厚望。而后续赛灵思也必定会推出基于ACAP的加速卡。而这又将进一步助力赛灵思的数据中心优先战略。
“ACAP将实现高通量、可扩展、低延迟的性能,目前可以应用在很多的应用场景当中。我们认为ACAP未来将会几乎进入到每一个市场当中。”Victor Peng在赛灵思开发者大会上非常有信心的说到。
-
赛灵思
+关注
关注
32文章
1794浏览量
131237 -
AI芯片
+关注
关注
17文章
1876浏览量
34973
原文标题:AI芯片迎来”新物种“,赛灵思Versal ACAP详解
文章出处:【微信号:icsmart,微信公众号:芯智讯】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AMD推出第二代Versal Premium系列
AMD Versal自适应SoC CPM5 QDMA的Tandem PCIe启动流程介绍
第二代AMD Versal Prime系列自适应SoC的亮点
ALINX受邀参加AMD自适应计算峰会
PMP22165.1-适用于 Xilinx 通用自适应计算加速平台 (ACAP) 的电源 PCB layout 设计

AMD发布第二代Versal自适应SoC,AI嵌入式领域再提速
在Vivado中构建AMD Versal可扩展嵌入式平台示例设计流程
AMD Versal AI Edge自适应计算加速平台之PL通过NoC读写DDR4实验(4)

AMD Versal AI Edge自适应计算加速平台之PL LED实验(3)
AMD Versal AI Edge自适应计算加速平台PL LED实验(3)

【ALINX 威廉希尔官方网站 分享】AMD Versal AI Edge 自适应计算加速平台之 Versal 介绍(2)
【ALINX 威廉希尔官方网站 分享】AMD Versal AI Edge 自适应计算加速平台之准备工作(1)
AMD Versal AI Edge自适应计算加速平台之Versal介绍(2)





 工商网监
工商网监
评论