 华为、苹果争“世界首款7纳米”,台积电:稳了!
华为、苹果争“世界首款7纳米”,台积电:稳了!
(本文来自新智元微信号,本文作为转载分享。)
“稳了”!
昨天,在苹果2018秋季新品发布会刚刚结束后的凌晨3点零1分,华为消费者BG CEO余承东在微博上发文:“稳了,我们十月十六日伦敦见!”
10月16日,伦敦,正是华为下半年旗舰机 Mate20 系列的发布时间和地点。
随后,“华为终端公司”微信号发布海报,标语为——“谢谢你,给了我们做英雄的机会”。
这简直就像某老坛酸菜牛肉面的广告最后直接说别人抄袭一样,华为要表达的意思也再明显不过。
今年,苹果的新品外观虽无太大新意,价格反而让人“惊喜”:“廉价版”iPhone XR起售价6499元,顶配版iPhone XS MAX则高达12799元。
缺乏新意却昂贵的苹果新品,可能让中国消费者有更多的兴趣关注国产手机。在这样一个日子里,华为这一波操作不仅引起舆论热议,热心网友还纷纷在线激情P图,为华为助威,顺带把华为送上了微博热搜。
苹果A12 vs 华为麒麟980:究竟谁才是全球首款7纳米AI芯片?
这次舆论关注的一个最大焦点,是苹果和华为双方都在各自发布会上公开宣称为“全球首款7纳米手机SoC”的苹果A12和华为麒麟980。
芯片决定了手机应用程序的种类和性能,先把谁是“全球首款”这个问题放在一边,新智元根据公开资料,整理了A12和麒麟980的性能规格对比:
A12仿生:iPhone 迄今最智能、 最强大的芯片
根据苹果公司的说法,这种神经网络引擎每秒能执行 5 万亿次运算,是之前的八倍,消耗的能量只有之前版本的十分之一。
在开始拆解分析苹果A12仿生之前,我们应该提一下去年A11仿生的重要升级也很重要。该处理器采用全新的性能控制器,允许 A11 同时运行所有六个内核,以实现密集型工作负载。苹果在移动硬件领域真正改变了游戏规则,这一事实巩固了苹果在智能手机处理器顶端的领先优势。
回到A12仿生,在 CPU 核心中,有两个是为性能而设计的,比前一代 A11 仿生芯片快 15%。其他 4 个 CPU 核心都是为提高效率而设计的,比 A11 仿生芯片节能最高达 50%。系统可以决定如何组合分配三种类型的核心,以最高效地运行任务。
A12仿生的 GPU 为四核心,与 A11 仿生相比速度提升 50%。对于这个四核心的GPU,除了知道它是定制设计的外,现在还没有任何公开架构细节。这个GPU最早出现在A8上,具有定制的着色器核心(shader core)和编译器。苹果去年正式与Imagination Technologies分道扬镳,但早在那之前苹果就开始着手自研定制设计。
最大的重头戏是8核心的神经网络引擎,这是苹果处理器升级的真正优势。A11的神经网络引擎只有两个核心,A12将其增加到8个——相应地,峰值性能增加到5 TFLOPS,即每秒执行 5 万亿次运算。这是8倍的提升,显示出密集SoC的强大优势。此外,A12的ISP(图像信号处理器)也加持了神经网络引擎,新iPhone系列的智能HDR效果有了大幅提升。
最后,半精度浮点数(16 位)也出现在 A12 上。 在 A8 之后,Apple 开始转向 16 位,A12 的神经引擎也是如此。这使得芯片可以快速执行操作并节省电力。
神经网络引擎能力的提升,也增强了新 iPhone 的机器学习能力,包括发送信息、拍照、人像模式、AR 功能、甚至原彩显示,都可以调用神经网路引擎进行学习优化。包括 Siri 在 iOS 12 中也拥有更强的学习功能,可以深度学习用户的使用路径与习惯。值得一提的是,这些神经网络功能的运算调用,所消耗的电量仅为前代产品的十分之一。
A12仿生的神经网络引擎也开放给 Core ML 平台,Core ML 运行速度比 A11 仿生提高 9 倍。开发者可将强大、实时的机器学习应用到自己的 app 中,让学习在 iPhone 上即可进行。
VLSI 研究分析师 G. Dan Hutcheson 称,A12 仿生芯片是 “一项令人印象深刻的壮举”,他说该芯片 “表明沿着摩尔定律这条路走下去,对各厂家来说仍然有吸引力”。
麒麟 980:创造了 6 个世界第一
华为的麒麟 980 芯片于 8 月 31 日在柏林 IFA 2018 上亮相。它将 69 亿个晶体管封装在一块 1 平方厘米的芯片上。
华为宣称,麒麟 980 创造了 6 个世界第一:
1、全球最早商用的台积电 7nm 工艺的手机 SoC 芯片
2、全球首次实现基于 ARM Cortex-A76 开发的商用 CPU 架构,最高主频可达 2.6GHz
3、全球首款搭载双核 NPU
4、全球最新采用 Mali-G76 GPU
5、全球最先支持 LTE Cat.21,峰值下载速率 1.4Gbps,达到业内最高
6、支持全球最快 LPDDR4X 颗粒,主频最高可达 2133MHz,同样业内最高
具体来说,麒麟 980 是第一款使用基于 Arm Cortex-A76 处理器的芯片,与其前身 A73 和 A75 相比,性能提高了 75%,效率提高了 58%。
它有 8 个内核,2 个是基于 A76 的大型高性能内核,2 个同样是 A76 的中等性能内核,以及 4 个基于 Cortex-A55 设计的小型高效内核。这个系统运行在 ARM big.LITTLE 架构的一个变体上,其中大型处理器处理即时、密集的工作负载,小型处理器负责持续的后台任务。
麒麟 980 的 GPU 组件称为 Mali-G76,与上一代相比,它的性能提升了 46%,效率提升了 178% 的。麒麟 980 芯片还有一个双核神经处理单元。用业界最常用的图像识别速率做标准,使用双核 NPU 的麒麟 980 每分钟识别图片的数量达到 4500 张,比 970 增加了一倍多。
华为还设计了一个名叫 “Flex-Scheduling” 的智能调度机制,能根据手机运行的应用智能地进行三级的调度,比如播放音乐就只需要一个小核,使用社交软件就动用中核,当有很多大量的负载,比如玩大型游戏时,就会使用大核。
苹果华为相争,台积电成最大赢家
很难说苹果A12仿生和麒麟980谁是真正的“王者”。光看数据,苹果强调每秒计算次数,华为强调图像识别速度,谁更厉害可能要等 10 月 16 日搭载麒麟 980 的华为 Mate 20 系列正式发布,拿真机测评才知道。
不过,A12处理器最傲人的是神经网络引擎的强化,一下子比上代提升9倍,有网友认为相比980的NPU可能是碾压级的。
苹果A12也好,华为麒麟980也罢,如果非要指名点姓说一家,谁才是真正的“全球首款7纳米芯片”,那答案则是生产这两种芯片的台积电。
事实上,现在的市场形势对台积电非常有利。
全球第二大晶圆代工厂格芯 (Global Foundries) 上月底宣布,将无限期搁置7纳米投资计划。
格芯执行长 Tom Caulfield表示,执行此计划的背后原因是:无法承受与三星和台积电的竞争压力。该公司希望避免将其大部分研究和设备预算,投入到可能永远无法获得回报的工作中。
格芯的重要客户是AMD,主要代工AMD的Ryzen、Radeon芯片。而此项宣布将使AMD将转向台积电。
这对台积电来说也是一份意外之喜,据报道,AMD的相关订单价值高达15亿美元,但目前台积电是唯一量产7nm代工厂,未来两三年还有可能增加到50亿美元。
尽管其他有可能角逐霸主之位的三星和英特尔也曾表示预定在2018年提供代工业者7纳米节点的对应威廉希尔官方网站 ,但台积电在这一方面仍处于领先位置。
为了摩尔定律“续命”,台积电也拼了老命
至于台积电本身,为了给摩尔定律“续命”,这家半导体巨头也可谓是拼了老命。
在大多数人感叹摩尔定律已经走向完结的当口,除了早早投入7纳米工艺研发,并于2017年第二季度进入试产阶段。
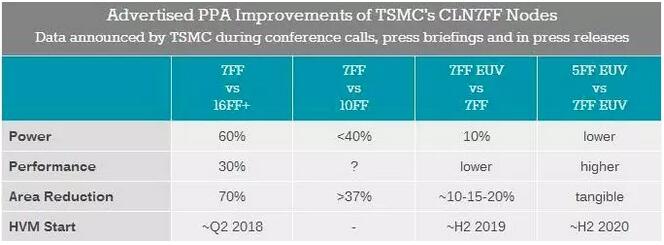
台积电使用DUV光刻的第一代7nm FinFET与此前10nm FinFET制程相比,7nm FinFET将可在晶体管数量不变的情况下使芯片尺寸减少37%,或在电路复杂度相同的情况下降低40%的功耗。
为了满足联发科、海思和高通等无晶圆厂客户不断增长的需求,台积电还提前在2018年第二季度将7纳米工艺威廉希尔官方网站 推向大规模生产。
据***当地媒体DIGITIMES今年6月报道,有消息人士称,台积电已经收到越来越多的7纳米订单,还有更多的无晶圆厂客户打算跳过10nm工艺,转而直接使用7nm。
2016年,台积电就对外宣称,预计投入250亿美元,建设制造5纳米工艺芯片的工厂,并计划于2020年上半年推出5纳米工艺的芯片。
不仅如此,台积电还表示,计划在2022年之前筹建并运营全球首个3nm半导体晶圆厂,虽然有关其对环境潜在影响的公众听证会还在进行中,并且有可能减缓其计划。
但无论如何,3纳米已经逼近芯片上能容纳晶体管数量的极限,再往下缩就不得不考虑电子的量子效应。IBM高管在日前在一次公开发表会议上说,3年内量计算机就将成为现实。
在摩尔定律这条路上,在代工厂这个商业模式上,台积电非常成功,现在以及未来几年也将很辉煌,但良品率和研发投入高昂的5纳米、3纳米工艺,性价比是否真的值得?
最终,由此带来的性能提升,以及费用增长,都将落到消费者身上。
-
台积电
+关注
关注
44文章
5632浏览量
166432 -
7纳米
+关注
关注
0文章
55浏览量
14858 -
A12
+关注
关注
1文章
23浏览量
5937 -
麒麟980
+关注
关注
5文章
399浏览量
22268
发布评论请先 登录
相关推荐
台积电2025年继续涨价,5/3纳米制程产品预计涨幅3~8%
台积电2nm芯片助力 苹果把大招留给了iPhone18
台积电SoIC威廉希尔官方网站 助力苹果M5芯片,预计2025年量产
台积电2纳米工艺生产设备提前部署完成
台积电大客户包下3纳米产能
世界先进董事改选,台积电退出
Marvell将与台积电合作2nm 以构建模块和基础IP
台积电领跑半导体市场:2纳米制程领先行业,3纳米产能飙升
台积电或在日本建第二座工厂!
特斯拉联手台积电布局3纳米芯片,小米汽车首秀






 工商网监
工商网监
评论