
 循环神经网络注意力的模拟实现
循环神经网络注意力的模拟实现
我们观察PPT的时候,面对整个场景,不会一下子处理全部场景信息,而会有选择地分配注意力,每次关注不同的区域,然后将信息整合来得到整个的视觉印象,进而指导后面的眼球运动。将感兴趣的东西放在视野中心,每次只处理视野中的部分,忽略视野外区域,这样做最大的好处是降低了任务的复杂度。
深度学习领域中,处理一张大图的时候,使用卷积神经网络的计算量随着图片像素的增加而线性增加。如果参考人的视觉,有选择地分配注意力,就能选择性地从图片或视频中提取一系列的区域,每次只对提取的区域进行处理,再逐渐地把这些信息结合起来,建立场景或者环境的动态内部表示,这就是本文所要讲述的循环神经网络注意力模型。
怎么实现的呢?
把注意力问题当做一系列agent决策过程,agent可以理解为智能体,这里用的是一个RNN网络,而这个决策过程是目标导向的。简要来讲,每次agent只通过一个带宽限制的传感器观察环境,每一步处理一次传感器数据,再把每一步的数据随着时间融合,选择下一次如何配置传感器资源;每一步会接受一个标量的奖励,这个agent的目的就是最大化标量奖励值的总和。
下面我们来具体讲解一下这个网络。
如上所示,图A是带宽传感器,传感器在给定位置选取不同分辨率的图像块,大一点的图像块的边长是小一点图像块边长的两倍,然后resize到和小图像块一样的大小,把图像块组输出到B。
图B是glimpse network,这个网络是以theta为参数,两个全连接层构成的网络,将传感器输出的图像块组和对应的位置信息以线性网络的方式结合到一起,输出gt。
图C是循环神经网络即RNN的主体,把glimpse network输出的gt投进去,再和之前内部信息ht-1结合,得到新的状态ht,再根据ht得到新的位置lt和新的行为at,at选择下一步配置传感器的位置和数量,以更好的观察环境。在配置传感器资源的时候,agent也会受到一个奖励信号r,比如在识别中,正确分类r是1,错误分类r是0,agent的目标是最大化奖励信号r的和:
梯度的近似可以表示为:
公式(1)也叫做增强学习的规则,它包括运用当前的策略运行agent去获得交互序列,然后根据可以增大奖励信号的行为调整theta。它的训练过程就是用增强学习的方法学习具体任务策略。关于给定任务,根据模型做出的一系列决定给出表现评价,最大化表现评价,对其进行端到端的优化。
首先为什么要用增强学习呢?因为数据的状态不是非常明确的,不是可以直接监督或者非监督来训练的,比如机器人的控制很难完全精确。
那么什么是增强学习呢?
增强学习关注的是智能体如何在环境中采取一系列行为,从而获得最大的累积回报。RL是从环境状态到动作的映射的学习,我们把这个映射称为策略。通过增强学习,一个智能体(agent)应该知道在什么状态下应该采取什么行为。
假设一个智能体处于下图(a)中所示的4x3的环境中。从初始状态开始,它需要每个时间选择一个行为(上、下、左、右)。在智能体到达标有+1或-1的目标状态时与环境的交互终止。如果环境是确定的,很容易得到一个解:[上,上,右,右,右]。可惜智能体的行动不是可靠的(类似现实中对机器人的控制不可能完全精确),环境不一定沿这个解发展。下图(b)是一个环境转移模型的示意,每一步行动以0.8的概率达到预期,0.2的概率会垂直于运动方向移动,撞到(a)图中黑色模块后会无法移动。两个终止状态分别有+1和-1的回报,其他状态有-0.4的回报。现在智能体要解决的是通过增强学习(不断的试错、反馈、学习)找到最优的策略(得到最大的回报)。
上述问题可以看作为一个马尔科夫决策过程,最终的目标是通过一步步决策使整体的回报函数期望最优。
提到马尔科夫,大家通常会立刻想起马尔可夫链(Markov Chain)以及机器学习中更加常用的隐式马尔可夫模型(Hidden Markov Model, HMM)。它们都具有共同的特性便是马尔可夫性:当一个随机过程在给定现在状态及所有过去状态情况下,未来状态的条件概率分布仅依赖于当前状态;换句话说,在给定现在状态时,它与过去状态是条件独立的,那么此随机过程即具有马尔可夫性质。具有马尔可夫性质的过程通常称之为马尔可夫过程。
马尔可夫决策过程(Markov Decision Process),其也具有马尔可夫性,与上面不同的是MDP考虑了动作,即系统下个状态不仅和当前的状态有关,也和当前采取的动作有关。
一个马尔科夫决策过程(Markov Decision Processes, MDP)有五个关键元素组成{S,A,{Psa},γ,R},其中:
这个就是马尔科夫决策过程。讲完马尔科夫决策之后我们回过头回顾一下训练的过程:每次agent只通过一个带宽限制的传感器观察环境,每一步处理一次传感器数据,再把每一步的数据随着时间融合,选择下一次如何配置传感器资源;每一步会接受一个标量的奖励,这个agent的目的就是最大化标量奖励值的总和。
注意力模型的效果如何
把注意力模型和全连接网络以及卷积神经网络进行比较,实验证明了模型可以从多个glimpse结合的信息中成功学习,并且学习的效果优于卷积神经网络。
由于注意力模型可以关注图像相关部分,忽视无关部分,所以能够在在有干扰的情况下识别,识别效果也是比其他网络要好的。下面这个图表现的是注意力的路径,表明网络可以避免计算不重要的部分,直接探索感兴趣的部分。
基于循环神经网络的注意力模型比较有特色的地方就在于:
●提高计算效率,处理比较大的图片的时候非常好用;
●阻塞状态下也能识别。
我们讲了半天,一个重要的概念没有讲,下面来讲讲循环神经网络RNN。
我们做卷积神经网络的时候样本的顺序并不受到关注,而对于自然语言处理,语音识别,手写字符识别来说,样本出现的时间顺序是非常重要的,RNNs出现的目的是来处理时间序列数据。
这个网络最直观的印象是什么呢,就是线多。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层的节点之间是无连接的。但是这种普通的神经网络对于很多问题却没有办法。例如,要预测句子的下一个单词,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。RNNs之所以称为循环神经网路,即一个序列当前的输出与前面的输出也有关,网络会对前面的信息进行记忆并应用于当前输出的计算中,具体的表现形式为即隐藏层之间的节点不再无连接而是有连接的,并且隐藏层的输入不仅包括输入层的输出还包括上一时刻隐藏层的输出。理论上,RNNs能够对任何长度的序列数据进行处理。但是在实践中,为了降低复杂性往往假设当前的状态只与前面的几个状态相关,下图便是一个典型的RNNs:
T时刻的输出是该时刻的输入和所有历史共同的结果,这就达到了对时间序列建模的目的。RNN可以看成一个在时间上传递的神经网络,它的深度是时间的长度。对于t时刻来说,它产生的梯度在时间轴上向历史传播几层之后就消失了,根本就无法影响太遥远的过去。因此,之前说“所有历史”共同作用只是理想的情况,在实际中,这种影响也就只能维持若干个时间戳。
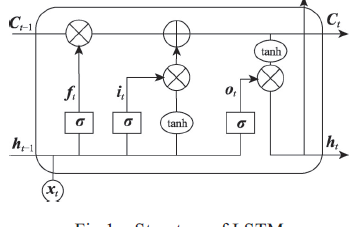
为了解决时间上的梯度消失,机器学习领域发展出了长短时记忆单元LSTM,通过门的开关实现时间上记忆功能,并防止梯度消失。
RNN还可以用在生成图像描述之中,用CNN网络做识别和分类,用RNN网络产生描述语句,这就是李飞飞的实验室所研究的内容。
-
传感器
+关注
关注
2550文章
51065浏览量
753296 -
机器学习
+关注
关注
66文章
8414浏览量
132601
发布评论请先 登录
相关推荐
卷积神经网络模型发展及应用
循环神经网络卷积神经网络注意力文本生成变换器编码器序列表征
基于异质注意力的循环神经网络模型

基于双向长短期记忆神经网络的交互注意力模型
基于语音、字形和语义的层次注意力神经网络模型

基于循环卷积注意力模型的文本情感分类方法





 工商网监
工商网监
评论