 如何使用Python编写能够从原始文本提取信息的程序
如何使用Python编写能够从原始文本提取信息的程序
【导读】我们从日常每天都会用到的推荐系统到现在研究火热的开放性聊天、对话机器人,越来越多的产品与应用的背后都需要自然语言处理(NLP)和知识图谱的威廉希尔官方网站 。也有越来越多的学者与工作人员投身于 NLP 领域的研究。为什么要研究NLP呢?如果计算机想要更好的理解人类的语言,拥有更好的人机交互体验,都离不开 NLP。那么,计算机到底是如何理解人类语言的?接下来让我们跟着作者 Adam Geitgey ,和他一起体会自然语言处理威廉希尔官方网站 里那些有意思的事情。
计算机非常擅长处理像电子表格、数据库这样的结构化数据。但是,人与人之间是用语言来交流的,而不是用表格。这对计算机来说就很倒霉了。
然而不幸的是,我们并不是生活在所有数据都是结构化的历史交替版本中
这个世界上的许多信息都是非结构化的,如英语,或者其他人类语言写成的原文。那么,如何让计算机理解这种非结构化文本并从中提取数据呢?

自然语言处理(Natural Language Processing,NLP)是人工智能的子领域之一,其重点是使计算机能够理解和处理人类语言。在本文中,我们将知晓NLP是如何工作的,并学习如何使用Python编写能够从原始文本提取信息的程序。(注:作者在文中选择的语言对象是英语)
计算机能够理解语言吗?
自从计算机问世以来,为了能够开发出可以理解语言的程序,程序员们一直在努力。为什么一定要这么做呢?理由很简单:人类运用语言已经有千年的历史,如果计算机能够读懂这些,对人们将会非常有帮助。
计算机虽然还不能像人类那样真正地理解语言,但是它们现在已经可以做很多事情了。在某些领域中,可以用NLP来做的那些事情,已经能够让人感到很神奇了。如果将NLP威廉希尔官方网站 应用到你自己的项目,也许可以节省很多时间。
好消息是,NLP的最近进展可以通过开源Python库(如spaCy、textcy 和 neuralcoref)轻松访问。只需简单几行Python代码就能完事儿,这一点就很让人惊叹。
难点:从文本中提取意义
阅读和理解英语的过程是非常复杂的,尤其是考虑到是否有遵循逻辑和一致的规则。例如,下面这个新闻标题是什么意思?
“Environmental regulators grill business owner over illegal coal fires.”
这新闻标题,究竟想表达什么意思呢?监管机构是否就非法燃煤的问题对企业主进行了质询?还是监管者把非法燃煤的企业主拿来烧烤了?你看,如果用计算机来解析英语的话,事情就会变得异常复杂。
在机器学习中,做任何一件复杂的事情通常意味着需要构建一个工作流。这个想法就是将你的问题分解成很小的部分,然后使用机器学习来分别解决每一个部分。然后,将几个相互作用的机器学习模型链接在一起,你就得以能够完成非常复杂的事情。
这就是我们将用在NLP的策略。我们将把理解英语的过程分解成小块,看看每个部分是如何工作的。
一步一步构建NLP工作流
我们来看一下取自维基百科上的一段文字:
London is the capital and most populous city of England and the United Kingdom. Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia. It was founded by the Romans, who named it Londinium.
(来源维基百科词条 London)
这一段包含了几个有用的事实。如果计算机能够读懂这段文字,并理解London(伦敦)是一座城市,位于England(英格兰),由Romans(罗马人)建立的地方,那就太好了。但是要实现这一目标,就必须教会计算机学习书面语言的最基本的概念,然后再继续前进。
▌第一步:句子切分(Sentence Segmentation)
工作流的第一步,是将文本切分成单独的句子。我们得到的是:
1.“London is the capital and most populous city of England and the United Kingdom.”
2.“Standing on the River Thames in the south east of the island of Great Britain, London has been a major settlement for two millennia.”
3.“It was founded by the Romans, who named it Londinium.”
我们可以假设,英语中每个句子都表达了一种独立的意思或者想法。编写程序来理解单个句子,可比理解整个段落要容易多了。
为句子切分模型编码就像你看到标点符号时对句子进行断句一样,都不是难事。但是,现代的NLP工作流通常会使用更为复杂的威廉希尔官方网站 ,就算文档格式不是很干净利落,也能正常工作。
▌第二步:单词标记(Word Tokenization)
现在我们已经将文本切分成了句子,这样就可以做到一次处理一个句子。就从这段文本的第一条句子开始吧:
“London is the capital and most populous city of England and the United Kingdom.”
NLP工作流中的下一步就是将这个句子切分成单独的单词或标记。这就是所谓的“标记”(Tokenization)。以下是单词标记的结果:
“London”, “is”, “ the”, “capital”, “and”, “most”, “populous”, “city”, “of”, “England”, “and”, “the”, “United”, “Kingdom”, “.”
标记在英语中很容易做到。只要单词之间有空格,我们就可以将它们分开。我们还将标点符号视为单独的标记,因为标点符号也有意义。
▌第三步:预测每个标记的词性
接下来,我们将查看每个标记并试着猜测它的词性:名词、动词还是形容词等等。只要知道每个单词在句子中的作用,我们就可以开始理解这个句子在表达什么。
我们可以通过将每个单词(以及周围的一些额外单词)输入到预训练的词性分类模型来实现,如下图所示:

需要记住一点:这种模型完全基于统计数据,实际上它并不能像人类那样理解单词的含义。它只知道如何根据以前所见过的类似句子和单词来猜测词性。
在处理完整个句子后,我们会得到这样的结果,如下图所示:

有了这些信息之后,我们就可以开始收集一些非常基本的含义。比如,我们看到这个句子中的名词包括“London”和“capital”,所以可以认为这个句子可能是在说 London。
▌第四步:文本词形还原(Text Lemmatization)
在英语(以及大多数语言)中,单词是以不同的形式出现的。看看下面这两个句子:
1.I had apony.
2.I had twoponies.
这两个句子都有名词“pony”,但是它们的词性不同。当计算机处理文本时,了解每个单词的基本形式是很有帮助的,唯有如此你才能知道这两个句子是在讨论同一个概念。否则,字符串“pony”和“ponies”在计算机看来就是两个完全不同的单词。
在NLP中,我们将发现这一过程叫“词形还原”(Lemmatization),就是找出句子中每个单词的最基本的形式或引理。
这同样也适用于动词。我们还可以通过找到动词的词根,以非共轭形式(unconjugated form)来引申动词。所以,“I had two ponies”就变成了“I [have] two [pony].”
词形还原通常是通过查找单词生成表格来完成的,也可能有一些自定义规则来处理你以前从未见过的单词。
下面是句子词形还原之后添加动词的词根形式之后的样子:

我们所做的唯一改变就是将“is”变成“be”。
▌第五步:识别停止词(Identifying StopWords)
接下来,我们要考虑句子中每个单词的重要性。英语中有很多填充词,经常出现“and”、“the”和“a”。当对文本进行统计时,这些填充词会带来很多噪音,因为它们比其他词出现得更频繁。一些NLP工作流会将它们标记为停止词(stop words),即在进行任何统计分析之前可能想要过滤掉的单词。
这个句子使用停用词变灰之后看上去像下面的样子:

我们是通过检查已知停止词的编码列表来识别停止词的。但是,并没有一个适合所有应用的标准停止词列表。因此,要忽略的单词列表可能因应用而异。
例如,如果你要构建摇滚乐队的搜索引擎,你要确保不会忽略“The”这个单词。因为“The”这个单词不仅仅出现在很多乐队的名字中,上世纪80年代还有一支著名的摇滚乐队就叫“The The”!
▌第六步:依存句法分析(Dependency Parsing)
下一步就是弄清楚句子中所有单词是如何相互关联的,这称为依存句法分析(Dependency Parsing)。
我们的目标就是构建一棵依存树,为句子中每个单词分配一个母词(parent word)。这棵树的根就是句子中的主动词(main verb)。这个句子的解析树的开头看上去如下图所示:
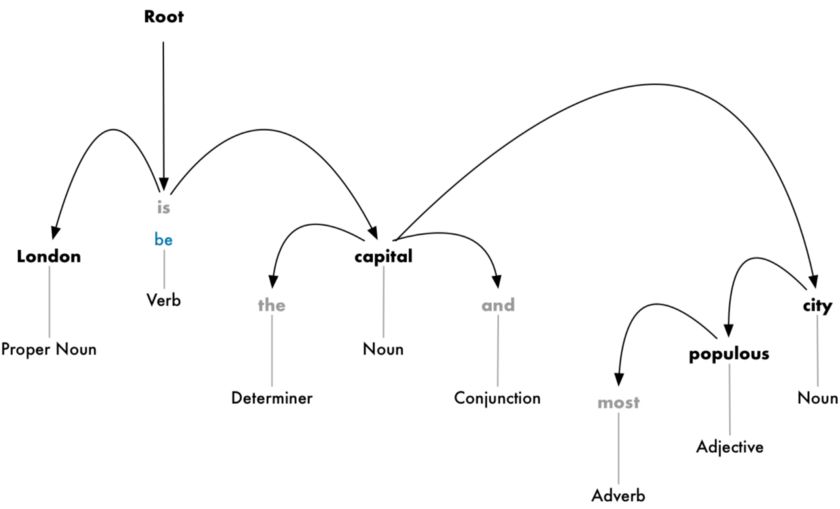
但我们还可以更进一步。除了识别每个单词的母词之外,我们还可以预测这两个单词之间存在的关系类型:
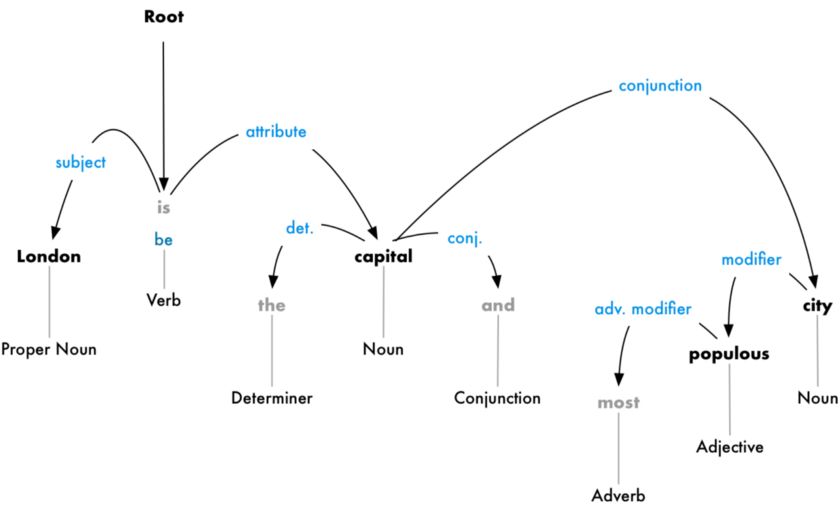
这棵解析树向我们展示了这个句子的主语是名词“London”,它与单词“capital”有“be”的关系。这样,我们终于知道了一些有用的信息:London是一个capital(首都)!如果我们按照完整的解析树来解析这个句子(超出所示内容),我们甚至会发现:London是英国的首都。
就像我们之前使用机器学习模型预测词性一样,依存语法分析也可以通过将单词输入到机器学习模型中并输出结果来实现。但是,解析单词的依存关系是一项特别复杂的任务,需要另起一篇文章来详细解释。如果你好奇它是如何工作的,可以去参阅Matthew Honnibal写的一篇优秀文章《Parsing English in 500 Lines of Python》,我们在文末附上了阅读链接。
要注意的是:尽管这篇文章的作者在 2015 年声称,这种方法现在已成为标准。但是实际上,它已经过时了,甚至连作者都不再使用这个方法了。2016年,Google 发布了一个新的依存句法分析器,名为 Parsey McParseface,它使用了一种新的深度学习方法,迅速在整个行业流行开来,其性能超过了以前的基准测试。一年后,他们发布了一种叫做 ParseySaurus 的新模型,实现了进一步的改进。换句话说,句法分析威廉希尔官方网站 仍然是一个活跃的研究领域,还在不断变化和改进。
此外,英语中有很多句子是模棱两可的,很难分析。在这些情况下,模型会根据句子的分析版本进行猜测,但是并不完美,有时候模型会出现令人尴尬的错误。但随着时间的推移,我们的NLP模型将继续以合理的方式更好地分析文本。
▌第六b步:查找名词短语
到目前为止,我们把句子中的每个单词都视为一个独立的实体。但有时候将表示一个想法或事物的单词放在一起更有意义。我们可以用依存句法解析树中的信息,自动将所有讨论同一事物的单词分组在一起。
例如,下面这个形式:

我们可以对名词短语进行分组来生成如下图所示:

是否采取这一步骤,要取决于我们的最终目标。但是,如果我们不需要关心哪些单词的额外细节,而是更关心提取完整的意思,那么这通常是简化句子的快速而简单的方法。
▌第七步:命名实体识别(NER)
既然我们已经完成了所有这些艰苦的工作,我们终于可以越过初级语法,开始真正地提取句子的意思。
在这个句子中,我们有下列名词:

如上图所示,有些名词表示世界上真实的事物。例如,“London”、“England”和“United Kingdom”代表的是地图上的物理位置。能够检测到这一点,真实太好了!有了这些信息,我们就可以使用NLP自动提取文本中提到的真实世界位置列表。
命名实体识别(Named Entity Recognition,NER)的目标是用它们所代表的真实概念来检测和标记这些名词。在我们的NER标记模型中运行每个标记之后,这条句子看起来如下图所示:

但是,NER系统并非只是简单地进行字典查找。相反,它们使用单词如何出现在句子中的上下文和统计模型来猜测单词所代表的名词类型。一个优秀的NER系统可以通过上下文线索来区分人名“Brooklyn Decker”和地名“Brooklyn”之间的区别。
下面是典型NER系统可以标记的一些对象:
人名
公司名称
地理位置(包括物理位置和行政位置)
产品名
日期和时间
金额
事件名称
NER 有很多用途,因为它可以很容易地从文本中获取结构化数据。这是快速从 NLP工作流中获取价值的最简单方法之一。
▌第八步:指代消解
至此,我们已经对句子有了一个有用的表述。我们知道了每个单词的词性,这些单词之间的关系,以及哪些单词表示命名实体。
但是,我们仍然有一个很大的问题。在英语中有大量像“he”、“she”、“it”这样的代词。这些代词是我们使用的“快捷方式”,这样某些名称就不用在每条句子中反复出现。人们可以根据文本中上下文来理解这些代词的含义。但NLP模型做不到这一点,它不会知道这些代词代表的是什么意思,因为它只能逐句检测每个句子。
让我们看一下文本中的第三句话:
“It was founded by the Romans, who named it Londinium.”
如果我们用 NLP工作流来分析这个句子,模型只知道“It”是由 Romans 创立的。但是,我们读过后都知道,“It”指的是“London”,这句的意思是:London是由 Romans 创立的。
指代消解(Coreference Resolution)的目标是,通过跟踪句子中的代词来找到相同的映射。我们要弄清楚所有指向同一个实体的代词。
如下图所示,是文本中为“London”一词进行指代消解的结果:

通过将指代消解、解析树和命名实体信息相结合,我们应该能够从这段文本中提取大量的信息!
指代消解是我们工作流准备实施中最困难的步骤之一。它比句子解析还要难。深度学习方面的最新进展已经产生了更为准确的新方法,但是还不够完美。
用Python编写NLP工作流
如下图所示,是我们完整的NLP工作流概述:

注:指代消解是可选步骤,并非必选步骤。上图所示的这些是典型的NLP工作流中的步骤,但你可以跳过某些步骤或重新排序步骤,这要取决于你想做的事情以及NLP库的实现方式。例如,某些像spaCy这样的库使用依存句法分析的结果在工作流中进行句子切割。
首先,假设你已经安装了Python 3,那么可以按照下面的步骤安装 spaCy:
#InstallspaCypip3install-Uspacy#DownloadthelargeEnglishmodelforspaCypython3-mspacydownloaden_core_web_lg#Installtextacywhichwillalsobeusefulpip3install-Utextacy
然后,下面是运行NLP工作流的代码:
importspacy#LoadthelargeEnglishNLPmodelnlp=spacy.load('en_core_web_lg')#Thetextwewanttoexaminetext="""LondonisthecapitalandmostpopulouscityofEnglandandtheUnitedKingdom.StandingontheRiverThamesinthesoutheastoftheislandofGreatBritain,Londonhasbeenamajorsettlementfortwomillennia.ItwasfoundedbytheRomans,whonameditLondinium."""#ParsethetextwithspaCy.Thisrunstheentirepipeline.doc=nlp(text)#'doc'nowcontainsaparsedversionoftext.Wecanuseittodoanythingwewant!#Forexample,thiswillprintoutallthenamedentitiesthatweredetected:forentityindoc.ents:print(f"{entity.text}({entity.label_})")
运行后将获得我们的文本中检测到的命名实体和实体类型的列表:
London(GPE)England(GPE)theUnitedKingdom(GPE)theRiverThames(FAC)GreatBritain(GPE)London(GPE)twomillennia(DATE)Romans(NORP)Londinium(PERSON)
注意,在“Londinium”一词上有一个错误:认为该词是人名而非地名。之所以出现这种错误是因为训练集中没有与之类似的东西,它所能做出的最好猜测。如果你要解析具有此类唯一或专用术语的文本,你就需要对命名实体检测进行一些模型微调。
让我们考虑一下检测实体,并将其进行扭曲以构建一个数据清理器。通过查阅海量文档并试图手工编辑所有的名称,需要耗费数年的时间。但是对于NLP来说,这实在是小菜一碟。这里有一个简单的 scrubber,可以很轻松地删除掉它所检测到的所有名称:
importspacy#LoadthelargeEnglishNLPmodelnlp=spacy.load('en_core_web_lg')#Replaceatokenwith"REDACTED"ifitisanamedefreplace_name_with_placeholder(token):iftoken.ent_iob!=0andtoken.ent_type_=="PERSON":return"[REDACTED]"else:returntoken.string#Loopthroughalltheentitiesinadocumentandcheckiftheyarenamesdefscrub(text):doc=nlp(text)forentindoc.ents:ent.merge()tokens=map(replace_name_with_placeholder,doc)return"".join(tokens)s="""In1950,AlanTuringpublishedhisfamousarticle"ComputingMachineryandIntelligence".In1957,NoamChomsky’sSyntacticStructuresrevolutionizedLinguisticswith'universalgrammar',arulebasedsystemofsyntacticstructures."""print(scrub(s))
运行这段代码会得到下面的结果
In1950,[REDACTED]publishedhisfamousarticle"ComputingMachineryandIntelligence".In1957,[REDACTED]SyntacticStructuresrevolutionizedLinguisticswith'universalgrammar',arulebasedsystemofsyntacticstructures.
▌提取事实
除了用 spaCy 外,还可以用一个叫 textacy 的 python 库,它在spaCy 的基础上,实现了几种常见的数据提取算法。
textacy 实现的算法中,有一种叫半结构化语句提取(Semi-structured Statement Extraction)算法。我们可以使用这个算法进行搜索解析树,查找主语是“London”且动词为“be”的简单语句。这有助于我们找到有关“London”的事实。
代码如下所示:
importspacyimporttextacy.extract#LoadthelargeEnglishNLPmodelnlp=spacy.load('en_core_web_lg')#Thetextwewanttoexaminetext="""LondonisthecapitalandmostpopulouscityofEnglandandtheUnitedKingdom.StandingontheRiverThamesinthesoutheastoftheislandofGreatBritain,Londonhasbeenamajorsettlementfortwomillennia.ItwasfoundedbytheRomans,whonameditLondinium."""#ParsethedocumentwithspaCydoc=nlp(text)#Extractsemi-structuredstatementsstatements=textacy.extract.semistructured_statements(doc,"London")#Printtheresultsprint("HerearethethingsIknowaboutLondon:")forstatementinstatements:subject,verb,fact=statementprint(f"-{fact}")
运行结果如下:
HerearethethingsIknowaboutLondon:-thecapitalandmostpopulouscityofEnglandandtheUnitedKingdom.-amajorsettlementfortwomillennia.
这么简单的演示,也许不会让人感到印象特别深刻。但是如果你在维基百科的“London”词条上运行同样的代码,而不是仅仅使用三条句子来演示,你就会得到更加令人印象深刻的结果:
Here are the things I know about London:
- the capital and most populous city of England and the United Kingdom
- a major settlement for two millennia
- the world's most populous city from around 1831 to 1925
- beyond all comparison the largest town in England
- still very compact
- the world's largest city from about 1831 to 1925
- the seat of the Government of the United Kingdom
- vulnerable to flooding
- "one of the World's Greenest Cities" with more than 40 percent green space or open water
- the most populous city and metropolitan area of the European Union and the second most populous in Europe
- the 19th largest city and the 18th largest metropolitan region in the world
- Christian, and has a large number of churches, particularly in the City of London
- also home to sizeable Muslim, Hindu, Sikh, and Jewish communities
- also home to 42 Hindu temples
- the world's most expensive office market for the last three years according to world property journal (2015) report
- one of the pre-eminent financial centres of the world as the most important location for international finance
- the world top city destination as ranked by TripAdvisor users
- a major international air transport hub with the busiest city airspace in the world
- the centre of the National Rail network, with 70 percent of rail journeys starting or ending in London
- a major global centre of higher education teaching and research and has the largest concentration of higher education institutes in Europe
- home to designers Vivienne Westwood, Galliano, Stella McCartney, Manolo Blahnik, and Jimmy Choo, among others
- the setting for many works of literature
- a major centre for television production, with studios including BBC Television Centre, The Fountain Studios and The London Studios
- also a centre for urban music
- the "greenest city" in Europe with 35,000 acres of public parks, woodlands and gardens
- not the capital of England, as England does not have its own government
现在事情变得有趣了!这就是我们自动收集的大量信息。
你还可以试着安装neuralcoref库并在工作流中添加指代消解。这样一来你就能得到更多的事实,因为它会捕捉到那些提到“it”的句子,而不是直接提及“London”的句子。
▌我们还能做什么?
查看spaCy的文档和textacy的文档,可以看到许多解析文本的方法示例。在本文中,我们只是用了一个小小的样本示例。
这里还有一个实例:假设你正在构建一个网站,让用户使用我们在上一个示例中提取的信息查看世界上每座城市的信息。
如果在你的网站上有搜索功能,那么就可以像 Google 那样自动填充常见的搜索查询,这点子可能很不错,如下图所示:
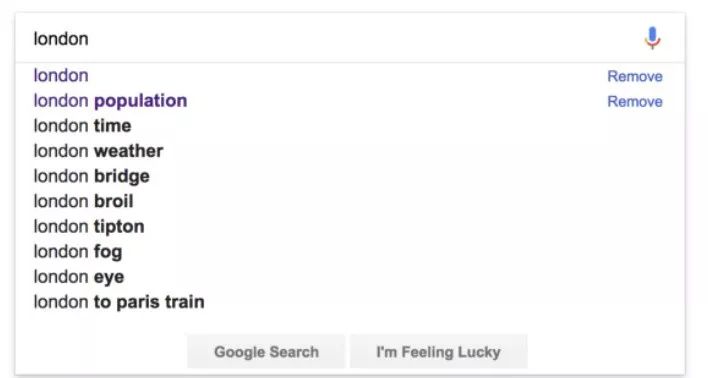
Google对“London”的自动填充建议
但是要做到这一点,我们需要一个可能完成的列表来为用户提供建议。可以使用NLP来快速生成这些数据。
要怎么生成这些数据呢?这里有一种方法,可以从文档中提取频繁提到的名词块:
importspacyimporttextacy.extract#LoadthelargeEnglishNLPmodelnlp=spacy.load('en_core_web_lg')#Thetextwewanttoexaminetext="""Londonis[..shortenedforspace..]"""#ParsethedocumentwithspaCydoc=nlp(text)#Extractnounchunksthatappearnoun_chunks=textacy.extract.noun_chunks(doc,min_freq=3)#Convertnounchunkstolowercasestringsnoun_chunks=map(str,noun_chunks)noun_chunks=map(str.lower,noun_chunks)#Printoutanynounsthatareatleast2wordslongfornoun_chunkinset(noun_chunks):iflen(noun_chunk.split(""))>1:print(noun_chunk)
得到如下的输出:
westminster abbey natural history museum west end east end st paul's cathedral royal albert hall london underground great fire british museum london eye…. etc ….
本文例举的内容只是你可以用NLP做的一小部分。在后续文章中,我们将会讨论NLP的其他应用,如文本分类,以及像Amazon Alexa这样的系统如何解析问题。
现在你就可以安装spaCy,开始尝试一下吧!如果你不是Python用户,使用的是不同的NLP库,文章中这些步骤,在你的处理过程中仍是有借鉴可取之处的。
-
计算机
+关注
关注
19文章
7489浏览量
87877 -
人工智能
+关注
关注
1791文章
47208浏览量
238304 -
python
+关注
关注
56文章
4793浏览量
84634
原文标题:计算机如何理解我们的语言?NLP is fun!
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
如何提取工频含谐波的电压电流信号频率相位幅值等信息
NLPIR在文本信息提取方面的优势介绍
FreeRTOS如何从队列中获取信息
如何使用Python编写一个简单的程序
如何使用TensorFlow Lite从Android设备图像提取文本
如何使用OpenCV和Python从图像中提取感兴趣区域
Python的PDF表格提取器-Camelot

Camelot:Python超强大的PDF表格提取器





 工商网监
工商网监
评论