 渐进式神经网络结构搜索威廉希尔官方网站
渐进式神经网络结构搜索威廉希尔官方网站

神经网络结构搜索是谷歌的AutoML的一个具体分支。约翰斯霍普金斯大学刘晨曦博士和Alan Yullie 教授,以及Google AI的李飞飞、李佳等多名研究者提出渐进式神经网络结构搜索威廉希尔官方网站 ,论文被ECCV 2018接收作为Oral。本文中,第一作者刘晨曦详细分析了这一威廉希尔官方网站 的原理以及设计细节。
谷歌的AutoML一经提出,就引起了学界及业界的广泛关注,然而其简易操作的背后,则是强大算力支持下的大量科研工作,其中之一便是渐进式网络结构搜索威廉希尔官方网站 。
渐进式神经网络结构搜索威廉希尔官方网站 (Progressive Neural Architecture Search)由约翰斯霍普金斯大学刘晨曦博士和Alan Yullie 教授,以及Google AI的李飞飞、李佳等多名研究者共同提出。
这篇文章被ECCV 2018录用为Oral paper,研究者提出的渐进式神经架构搜索方法,比普通计算速度快8倍,效率提高5倍,AI自动搜索得到的模型在ImageNet大规模数据集上取得了当前最高精度。
这一威廉希尔官方网站 已经被用于谷歌AutoML架构自动搜索,进一步提升性能。本文中,论文的第一作者刘晨曦博士将为大家揭开AutoML的面纱,看他如何通过迭代自学习的方式,积跬步以至千里,寻找到最优网络结构,从而将万繁归于至简。
文中提到所有文章和代码的下载链接附在文末。
摘要
我们提出一种学习卷积神经网络(CNN)结构的新方法,该方法比现有的基于强化学习和进化算法的威廉希尔官方网站 更有效。使用了基于序列模型的优化(SMBO)策略,在这种策略中,按照增加的复杂性对结构进行搜索,同时学习代理模型(surrogate model)来引导在结构空间中的搜索。
在相同搜索空间下直接比较的结果表明,该方法比Zoph等人(2018)的RL方法所评估的模型数量多5倍,总计算速度快8倍,并且用该结构在CIFAR-10和ImageNet上实现了最高的分类精度。
本文中,将介绍的渐进式神经网络搜索算法,是和谷歌大脑、谷歌云、谷歌研究院的很多研究员一同完成的。
其中,PNASNet-5在ImageNet上的代码和模型已经发布在TensorFlow Slim:
https://github.com/tensorflow/models/tree/master/research/slim#Pretrained
欢迎大家下载使用。
首先介绍AutoML,它是谷歌内部一个宏大的目标,是创造一种机器学习算法,使得它能够最好地服务于用户提供的数据,而在这过程中有尽可能少的人类参与。
从起初的AlexNet到Inception,ResNet,Inception-ResNet,机器在图像分类问题上已经取得了很好的成绩,那么我们为什么还想使用AutoML算法来研究图像分类呢?
首先,如果可以通过自动搜索,找到比人类设计的最好算法还好的算法,岂不是很酷?其次,从更加实用的角度出发,图像分类问题是大家学习得很多的问题,如果在该问题上取得突破,那么突破其他问题的可能性也大大增加。
接下来介绍Neural Architecture Search(NAS)问题,它是AutoML一个具体的分支。
Neural Architecture Search基本遵循这样一个循环:首先,基于一些策略规则创造简单的网络,然后对它训练并在一些验证集上进行测试,最后根据网络性能的反馈来优化这些策略规则,基于这些优化后的策略来对网络不断进行迭代更新。
之前的NAS工作可以大致分为两方面,首先是强化学习,在神经结构搜索中需要选择很多的元素,如输入层和层参数(比如选择核为3还是5的卷积操作)的设置,设计整个神经网络的过程可以看作一系列的动作,动作的奖赏就是在验证集上的分类准确率。通过不断对动作更新,使智能体学习到越来越好的网络结构,这样强化学习和NAS就联系起来了。
另一方面NAS是一些进化算法,这一大类方法的主要思路是,用一串数定义一个神经网络结构。如图是ICCV2017谢凌曦博士的工作,他用一串二进制码定义一种规则来表达特定的神经网络连接方式,最开始的码是随机的,从这些点出发可以做一些突变,甚至在两个数串(拥有较高验证准确率)之间做突变,经过一段时间就可以提供更好的神经网络结构。
而目前方法最大的问题在于,它对算力的要求特别高。以强化学习为例,谷歌大脑最开始提出的强化学习方法,用了800块K40GPU,训练了28天;后来2017年7月提出的改进版,用了500块P100GPU训练了4天,而且这是在非常小的CIFAR-10数据集上做的,该数据集只有5万张30*30的图。即便这样小的数据集就需要如此大的算力支撑,也就是说想要继续扩展NAS,用强化学习的方法是不现实的。
为加速NAS过程,我们提出了一个新的方法,谓之“渐进式的神经结构搜索”。它既不是基于强化学习的,也不属于进化算法。在介绍具体算法前,首先来理解这里的搜索空间。
首先搜索可重复的cells(可以看作是Residual block),一旦找到一个cell,就可以自由地选择其叠加方式,形成一个完整的网络。这样的策略在Residual Network中已经出现多次。当确定了cell structure后如上右图将其叠加成一个完整的网络,以CIFAR-10网络举例,在两个stride2的cell之间,stride1的cell叠加次数都为N,而Residual网络中不同的groups叠加的次数不同。
一个网络通常由这三个要素来确定:cell的结构,cell重复的次数N,每一个cell中的卷积核个数F,为了控制网络的复杂度,N和F通常经手工设计。可以理解为,N控制网络的深度,F控制网络的宽度。
接下来主要讨论如何确定cell,在我们的搜索空间中,一个cell由5个block组成,每个block是一个(I_1,I_2,O_1,O_2,C)的元组。以下将具体介绍。
如图,网络输入的搜索空间如图中灰色矩形所示,I_1,I_2对应图中hidden layer A和hidden layer B,I即指输入(Input)。这两个灰块可以选择不同的隐含空间,cell c block b可能的输入定义为:
前一个cell的输出:H_B^(c-1)
前一个的前一个的cell的输出:H_B^(c-2)
在当前cell的当前block的所有之前输出:{H_1^c,…,H_(b-1)^c }
比如右边的block是这个cell里的第一个block,在选用第二个block的时候它就可以选取第一个block产生的new hidden layer,也就是说,第二个block的输入涵盖了第一个block的输出。这样的设计为了允许一定的泛化性,可以刻画Residual Network,DenseNet之类的网络。
O_1,O_2对应图中的黄色方框,这其实是对刚才选取的隐含层的一元运算符,它包含了3*3的卷积,5*5的卷积,7*7的卷积,identity,3*3的均值池化,3*3的最大值池化,3*3的加宽池化以及1*7后接7*1的卷积。让数据在搜索空间中学习找到最适合的操作。
绿色框代表C这个运算,它把由I_1,I_2产生的O_1,O_2通过一定的方式组合到一起,产生一个新的隐含空间。这个C操作是按位加和的操作。
在这个搜索空间下,尽可能有效地学习到一个性能较好的cell,这样就能叠加起来成为一个完整的网络。而刚才包含5个block的cell的搜索空间是非常大的,如上图等式所示。而之前介绍的无论是强化学习还是基于进化算法,都是直接搜索,这在搜索开始是非常迷茫的,那么如果不直接在那个空间进行搜索,而是渐进式地进行如下操作会怎样呢:
首先训练所有的1-block cells,只有256个这样的cell。虽然可以通过枚举的方式,但性能会很低,因为只有1个block的cell不如包含5个block的cell有效。但是,这部分性能信息可以为是否继续采用这个cell的信号提供辅助,基于1-block cell的表现,我们可以尝试发现最有希望的2-block cell,并对其进行训练,如此迭代,即可构建整个网络。
可以概括为一个简单的算法,训练和评估当前有b个blocks的cells,然后根据其中最好的K个cells来枚举b+1个blocks,然后去训练和评估。
而实际上,这个算法是不能真正奏效的,因为,对于一个合理的K(如〖10〗^2),需要训练的子网络就高达〖10〗^5个,此运算量已经超过了以往的方法。因此,我们提出了一个准确率预测器,它可以不用训练和测试,而是只通过观察数串,就能评估一个模型是否是有潜力的。
我们使用了一个LSTM网络来做准确率预测器,之所以使用它,是因为在不同的block中可以使用同一个预测器。
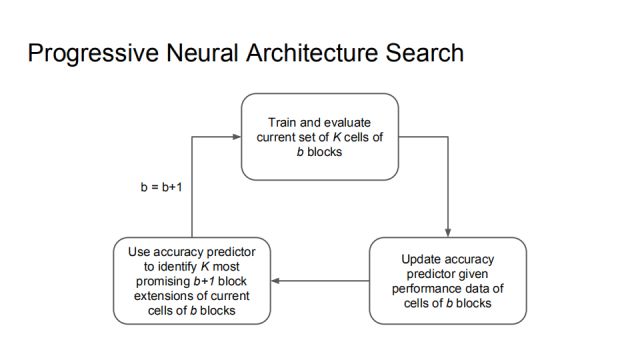
这里给出完整的Progressive Neural Architecture Search的算法。首先训练并评估当前b个blocks的K个cells,然后通过这些数据的表现来更新准确率预测器,可以使准确率预测器更精确,借助预测器识别K个最有可能的b+1个block。这样学出来的结果可能不是最正确的,但却是一个合理的trade-off结果。
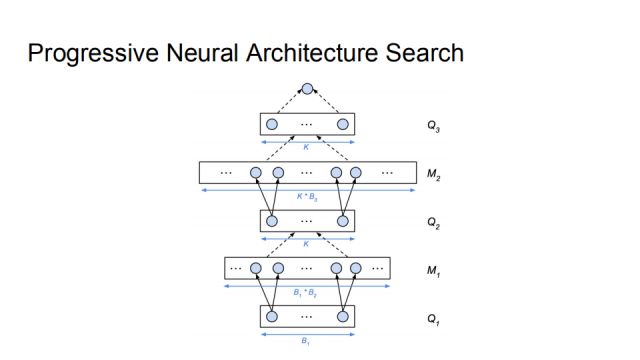
举个例子 ,最开始b=1,Q1时有256个网络,对它全部训练测试,然后用这K个数据点训练准确率预测器。枚举Q1的所有后代M1,并把这个准确率预测器运用在M1的每个元素上,选出其中最好的K个,即得到了b=2时的集合Q2。然后将b=2的网络进行训练测试,经过上述相同的过程,可以得到Q3。Q3中最好的模型即为PNAS返回的结果。

实验分为两个过程,一个是在搜索过程中,另一个是在搜索之后。在搜索过程中,我们使用CIFAR-10这个相对较小的数据集,每一个子网络训练的epoch都设置为20,K取为256,N为2,F为24,这些参数都是相对较小的。在搜索之后,我们在CIFAR-10和ImageNet上进行测试,使用了更长的epochs,更大的N,F。我们这个工作的目的是加速NAS的过程,下面是实验对比。
接下来对比PNAS和之前的NAS方法,蓝色的点是PNAS,红色的是NAS,五个蓝色的chunk对应b=1,2,3,4。每个chunk里有256个点,随着b的增加,进到越来越复杂的搜索空间。可以看出相比于红色的点,蓝色的点上涨更加快也更加紧致。右边是一个放大的图。
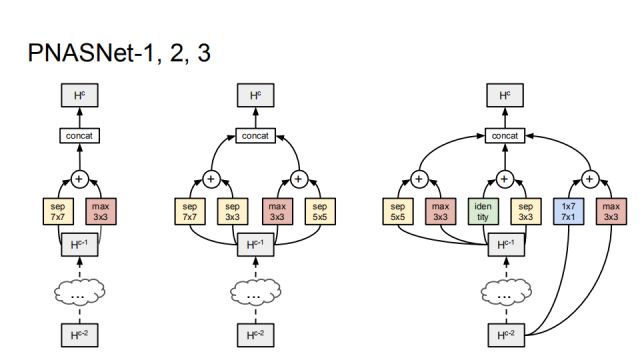
如图是最后学习到的网络结构,可以看出,最开始学习到的是separable和max convolution的组合,后面渐渐学习到更多的组合。
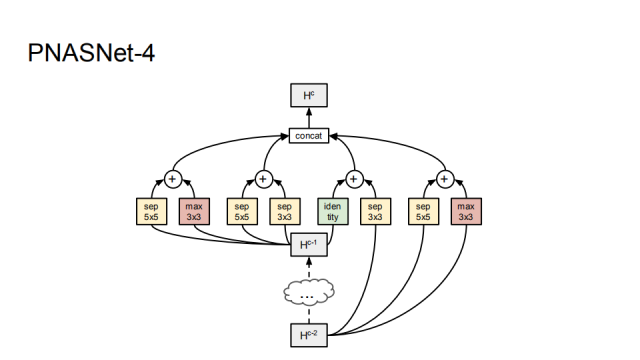
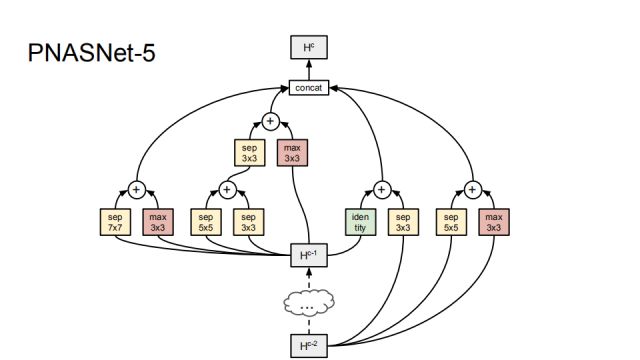
PNASNet-5是我们在搜索的过程中找到的最好的网络结构,它由5个block组成。
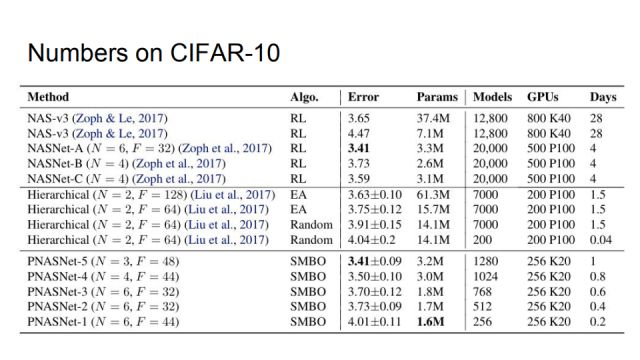
这是我们在CIFAR-10上的对比结果,RL表示算法基于强化学习,EA表示基于遗传算法,我们的算法SMBO即sequential model based optimization,Error指最好模型的top-1误分率。第一组基于强化学习的方法中最好的是NASNet-A,它的错误率是3.41%,所用参数个数为3.3M;第二组是基于遗传算法的方法,它是DeepMind在2018年ICLR发表的工作,它最好的错误率是3.63%,所用参数个数为61.3M,而第三组是我们的方法,在错误率为3.41的条件下,我们所用参数仅为3.2M,并且提速很多。
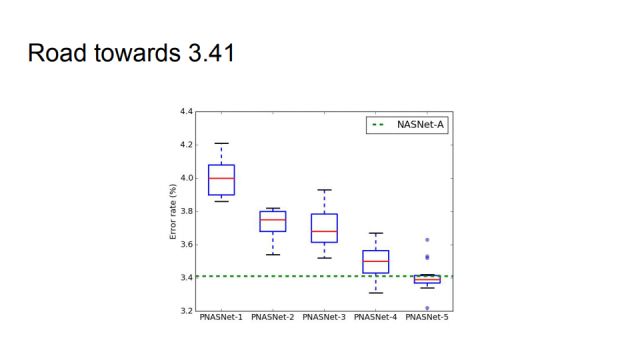
这张图更直观地展示了如何达到了与NASNet-A可比的性能。
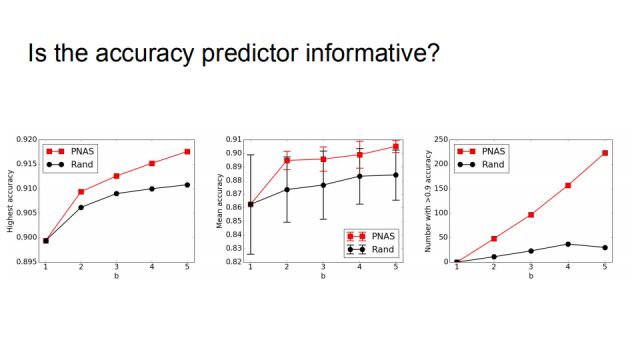
为了验证准确率预测器是否是信息丰富的,我们做了一个随机的对比实验,如果不用progressive neural architecture search,在每一个number of b的时候用随机来代替。结果表明随机的策略性能要差很多,尤其是最右,如果在每一个b的取值,都训练256个模型的话,以准确率大于0.9为统计指标,随机法只有三十多个,而PNAS有二百多个符合。
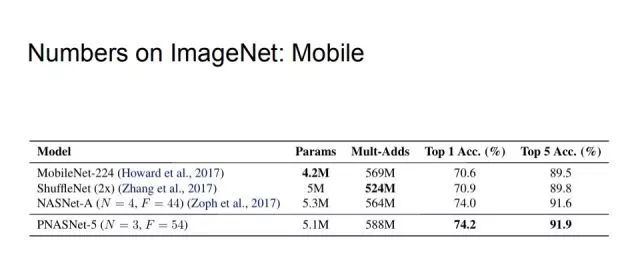
最后是在ImageNet数据集上的对比,首先介绍在轻量神经网络的应用比对。我们控制Mult-Adds不超过600M,在这一条件下,PNASNet-5相比MobileNet-224,ShuffleNet(2x),和NASNet-A有最高的top1和top5的准确率。
此外,对不加限制的模型进行比对,在实验过程中尽量和NASNet-A的参数量保持一致,最后的top1准确率达到了82.9%。
总结一下,本次报告中介绍的工作中最关键的几个点:大多数现存的神经网络搜索方法都有很高的算力需求,由此产生高昂的时间代价,而我们试图加速这个过程。思路的核心在于,将cells从简单到复杂推进,加之比NASNet-A更紧致的搜索空间,PNAS找到了一个可比的cell,只用了1280个而不是20000个子模型。这使得AutoML将可以用到更多有挑战的数据集上。
-
神经网络
+关注
关注
42文章
4771浏览量
100722 -
数据集
+关注
关注
4文章
1208浏览量
24691
原文标题:ImageNet分类精度再创新高!李飞飞组ECCV Oral提出全新渐进式神经结构搜索
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
粒子群优化模糊神经网络在语音识别中的应用
【案例分享】ART神经网络与SOM神经网络
神经网络结构搜索有什么优势?

基于神经网络结构在命名实体识别中应用的分析与总结

一种新型神经网络结构:胶囊网络

卷积神经网络结构优化综述






 工商网监
工商网监
评论