 介绍用迁移学习处理NLP任务的大致思路
介绍用迁移学习处理NLP任务的大致思路
编者按:迁移学习在CV领域的应用已经取得不小的进步了,而在自然语言处理(NLP)领域,很多任务还在使用词嵌入。嵌入的确是种更丰富的表现单词的形式,但是随着任务种类的增多,嵌入也有了局限。本文将介绍用迁移学习处理NLP任务的大致思路,以下是论智的编译。
通用语言建模
迁移学习在计算机视觉领域已经有了很多应用,最近几年也做出了许多不错的成果。在一些任务中,我们甚至能以超越人类精确度的水平完成某项任务。最近,很少能看到用无需预训练的权重输出顶尖结果的模型。事实上,当人们生产它们时,经常会用迁移学习或某种微调的方法。迁移学习在计算机视觉领域有很大的影响,为该领域的发展做出了巨大贡献。
但是直到现在,迁移学习对计算机视觉还有些许限制,最近的研究表明,这种限制可以扩展到多个方面,包括自然语言处理和强化学习。最近的几篇论文表明,NLP领域中的迁移学习和微调的结果也很不错。
最近,OpenAI举办了一场Retro竞赛,其中参赛者要创建多个智能体,在玩游戏时不能接触环境,而是利用迁移学习进行训练。现在,我们可以探索这种方法的潜力了。
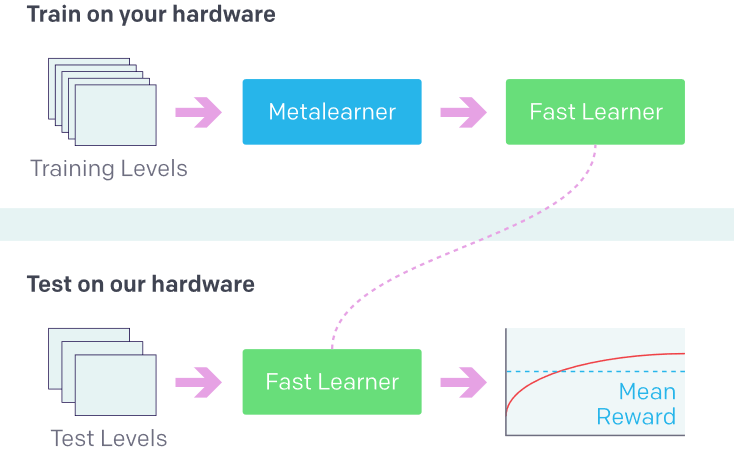
利用之前的经验学习新事物(强化学习中的新环境)。来源:OpenAI Retro Contest
此前在计算机视觉领域关于渐进式学习的研究给模型进行了概括,因为这是保证神经网络在学习时稳定的最重要因素之一。想实现这一目的的论文就是Universal Language Model Fine-tuning for Text Classification。
文本分类是NLP领域重要的部分,它与现实生活中的场景密切相关,例如机器人、语音助手、垃圾或诈骗信息监测、文本分类等等。这项威廉希尔官方网站 的用途十分广泛,几乎可以用在任意语言模型上。本论文的作者进行的是文本分类,直到现在,很多学术研究人员仍然用词嵌入训练模型,例如word2vec和GloVe。
词嵌入的局限
词嵌入是单词的密集表示,通过用转换成张量的真实数字转化而来。在模型中,嵌入需要用特殊顺序排列,这样模型才能学会词语和语境中的语法和语义关系。
进行可视化时,有相近语义的单词的嵌入也会更近,这样每个单词也会有不同的向量表示。
词汇表中的不常见词
处理数据集时,我们经常会碰到生僻词语。

标记化(Tokenization)。这些词语都是常见词,但是有了类似这样的嵌入就会很难处理
对于某些只出现很少几次的词语,模型就要花大量时间弄清楚它的语义,所以人们专门建立了一个词汇集来处理这一问题。Word2vec无法处理未知词语。当模型不认识某个词时,它的向量就不能被确切地分解,所以它必须随意地进行初始化操作。关于嵌入,常见的问题有:
处理共享表示(shared representations)
词语表示的另一个问题是,在子字词中没有一个共同的表示。英文中的前缀和后缀通常会改变词语的意思。由于每个向量都是独立的,词语间的语义关系就不能完全被理解。
共现统计(co-occurrence statistics)
分布式词向量模型能够捕捉到词语中共现统计的某些方面。在单词共现上训练的嵌入可以捕捉单词语义之间的相似性,所以可以在单词相似性的任务上进行评估。
如果某个特殊的语言模型用char-based输入,并且无法从与训练中受益,那么就需要对词嵌入进行随机处理。
支持新语言
嵌入的使用在面对其他语言时,会出现不稳定的情况。新语言需要新的嵌入矩阵,无法使用共同的参数,所以模型不能用于多语言任务。
词嵌入可以被连接起来,但是用于训练的模型必须从新开始处理嵌入。预训练嵌入被看成是固定参数。这样的模型在渐进式学习中是没有用的。
计算机视觉已经表明,hypercolumns和其他常用的训练方法相比,并不实用。在CV中,一个像素的hypercolumn是该像素之上,所有卷积网络单元中的活动向量。
平均随机梯度方法,权重下降LSTM
这个研究中所用模型的灵感来自论文:Regularizing and Optimizing LSTM Language Models。它使用权重下降的LSTM,LSTM利用DropConnect作为循环正则化形式。DropConnect是在神经网络中对大型完全连接层进行规范化的泛化。
用Dropout训练时,一个随机选择的子集在每层中被设置为0.DropConnect设置了一个随机选择的权重子集,每个单元从其中接收从上一层来的输入。
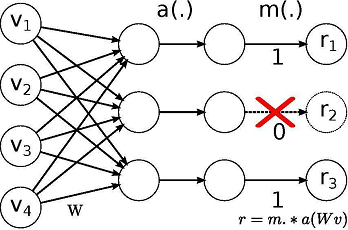
Dropout网络和DropConnect网络的不同
通过在hidden-to-hidden权重矩阵上使用DropConnect,可以避免LSTM循环连接中的过度拟合。这一正则化威廉希尔官方网站 还可以防止其他循环神经网络中的循环权重矩阵的过度拟合现象。
通常所用的值为:
dropouts = np.array([0.4,0.5,0.05,0.3,0.1]) x 0.5
这里的×0.5是一个超参数,虽然数组中的比列已经达到很好的平衡,但是用0.5进行调整可能也是需要的。
由于同样的权重可能在不同阶段重复使用,同样的权重会在全部过程中保持下降。结果和variational dropout非常像,它运用了相同的dropout掩码,只是应用在了循环权重上。
通用语言模型
一个三层的LSTM结构以及经过调整的dropout参数能比其他文本分类任务表现得更好。主要用到的有三种威廉希尔官方网站 。
三角变化学习速率(STLR)
最初我使用Adam优化算法和权重衰减,但是优化器又很有限制。如果模型在下鞍点卡住,同时生成的梯度很小,那么模型就很难生成足够的梯度走出非凸区域。
Leslie Smith提出的循环学习速率(CLR)解决了这一问题。使用了CLR之后,精确度提高了10%。
学习速率决定了在目前的权重上应用多少损失梯度,这一方法和热启动的随机梯度很像。

简单地说,选择初始学习速率和学习速率调度表比较困难,因为有时并不能分辨那种情况更好。
但是可以给每个参数应用灵活的学习速率,例如Adam、Adagrad和RMSprop等优化器可以在训练时对每个参数的学习速率进行调整。
论文Cyclical Learning Rates for Training Neural Networks用简洁优雅的方法解决了上述常见问题。
循环学习速率(CLR)为学习速率的值创建了高低两个界限。它可以和适应性学习速率结合,但是和SGDR很相似,同时所需计算力并不多。
如果在最低点停滞,可以使用更高的学习速率让模型走出此区域,但如果位置过于低,那么传统的改变学习速率的方法就无法生成足够的梯度。
非凸函数
周期性的更高学习速率可以更流利、更快地穿过此区域。
最优学习速率将处于最大和最低界限之间。
所以有了迁移学习在A上运用的模型可以迁移到B上提到其表现力。语言模型有着用于CV分类的所有功能:它了解语言、理解层次关系,能够进行长时间应用,可进行情感分析。
ULMFiT和CV一样有三个阶段。

第一阶段,语言模型的预训练。语言模型在通用数据集上训练,它从中学习到通用特征,了解语义关系,就像ImageNet。
第二阶段,语言模型的微调。用不同的微调方法和三角形可变学习速率,从而使模型适应不同的任务。
第三阶段,分类器微调。对分类器进行调整,逐步解锁进行微调,用STLP保存低水平表示,同时对高层次进行调整。
总之,ULMFiT可以看做是模型的主干,上面添加了一个分类器。它用的是在通用语料上训练过的模型。在之后的任务上可以进行微调以达到文本分类的最佳水平。
ULMFiT可以解决的问题
这一方法之所以通用,是因为它对数据集没有要求。任何长度的文件和数据集都能用它解决。它使用单一的结构(在这个案例中是AWD-LSTM,和CV中的ResNet一样)。无需特殊定制,也不需要额外的文本使其适应不同的任务。
该模型还可以用注意力进行进一步改善提高,如有需要还可以加入跳跃式连接(skip connection)。
不同情况下的微调
神经网络的每个图层都捕捉到不同的信息。在CV中,初始层捕捉到的是广泛的、明显的特征。越深的图层捕捉到的特征就越复杂、具体。利用同样的规则,这种方法会在语言模型的不同图层提出不同的调整方法。为了达到这一目的,每一层的学习速率都不相同,这样一来人们可以决定每一层的参数如何优化。
参数θ将会分成一系列参数,并作用在l个图层上{θ1,…,θL},同时学习速率也可以做出同样的操作,随机梯度下降可以表示成:
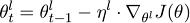
不同任务权重下对分类器的微调
之后会添加两个线性模块,每个模块利用批归一化和较低值的dropout。在模块之间,ReLU用来作为激活函数。这些分类器图层并不会从预训练中延续某种特征,而是从零开始训练。在搭建模块之前,会对上一个隐藏层进行池化,然后输入到第一个线性层中。
trn_ds = TextDataset(trn_clas, trn_labels)
val_ds = TextDataset(val_clas, val_labels)
trn_samp = SortishSampler(trn_clas, key=lambda x: len(trn_clas[x]), bs=bs//2)
val_samp = SortSampler(val_clas, key=lambda x: len(val_clas[x]))
trn_dl = DataLoader(trn_ds, bs//2, transpose=True, num_workers=1, pad_idx=1, sampler=trn_samp)
val_dl = DataLoader(val_ds, bs, transpose=True, num_workers=1, pad_idx=1, sampler=val_samp)
md = ModelData(PATH, trn_dl, val_dl)
dropouts = np.array([0.4,0.5,0.05,0.3,0.4])*0.5
m = get_rnn_classifer(bptt, 20*70, c, vs, emb_sz=em_sz, n_hid=nh, n_layers=nl, pad_token=1,
layers=[em_sz*3, 50, c], drop=[dropouts[4], 0.1],
dropouti=dropouts[0], wdrop=dropouts[1], dropoute=dropouts[2], dropouth=dropouts[3])
Concat池化
注意循环模型的状态通常是很重要的,并且要保留有用的状态,释放没有用的并且限制内存的状态。但是隐藏包含了许多信息,而需要保留的权重都在隐藏层。为了做到这一点,我们将最后一步的隐藏层和隐藏层最大和平均池化的表示连接起来,这样可以适应GPU的内存。
trn_dl = DataLoader(trn_ds, bs//2, transpose=True, num_workers=1, pad_idx=1, sampler=trn_samp)
val_dl = DataLoader(val_ds, bs, transpose=True, num_workers=1, pad_idx=1, sampler=val_samp)
md = ModelData(PATH, trn_dl, val_dl)
训练分类器(逐步解锁)
如果直接对分类器进行微调,则有可能导致严重的遗忘出现,而缓慢地微调可能会导致过度拟合和收敛。所以我们认为不能直接对所有图层进行微调,而是要每次只调一个图层,逐步进行。
在文本分类上进行逐步反向传播(BPTT)
BPTT经常用于RNN中处理序列数据,每一步都有一个输入、一个网络的复制版本和一个输出。同时每一步还会生成网络的错误并集合在一起。
模型在上一批处理的最后阶段进行初始化。平均和最大池化的隐藏状态同样被追踪下去。模型的核心使用了可变长度的序列,以下是用PyTorch进行采样的一小片段:
classSortishSampler(Sampler):
def __init__(self, data_source, key, bs):
self.data_source,self.key,self.bs = data_source,key,bs
def __len__(self): return len(self.data_source)
def __iter__(self):
idxs = np.random.permutation(len(self.data_source))
sz = self.bs*50
ck_idx = [idxs[i:i+sz] for i in range(0, len(idxs), sz)]
sort_idx = np.concatenate([sorted(s, key=self.key, reverse=True) for s in ck_idx])
sz = self.bs
ck_idx = [sort_idx[i:i+sz] for i in range(0, len(sort_idx), sz)]
max_ck = np.argmax([self.key(ck[0]) for ck in ck_idx]) # find the chunk with the largest key,
ck_idx[0],ck_idx[max_ck] = ck_idx[max_ck],ck_idx[0] # then make sure it goes first.
sort_idx = np.concatenate(np.random.permutation(ck_idx[1:]))
sort_idx = np.concatenate((ck_idx[0], sort_idx))
return iter(sort_idx)
结果
这一方法比其他依靠嵌入或其他迁移学习的NLP方法优秀得多。通过逐渐解锁并且用新的方法训练分类器,四次迭代后可以达到94.4的精确度,比其他方法都准确。
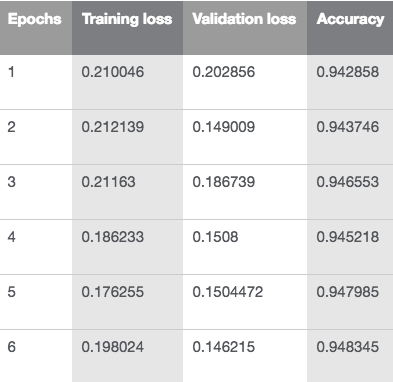
用ULMFiT进行文本分类时的损失和精确度
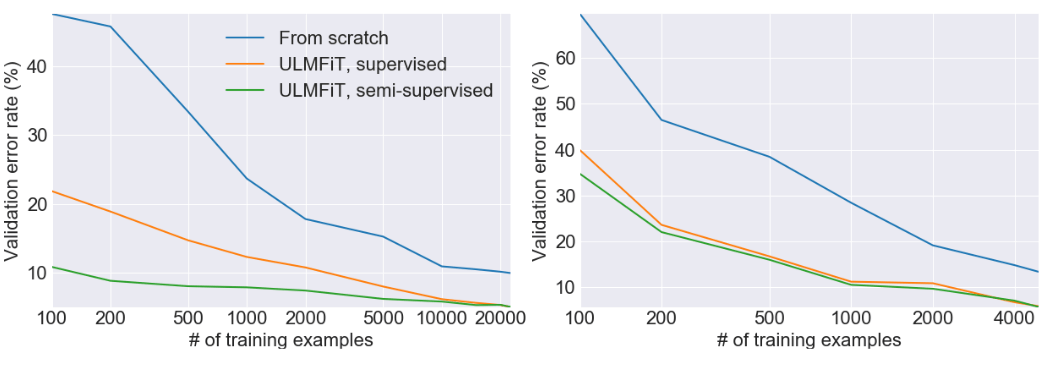
验证错误率
-
计算机视觉
+关注
关注
8文章
1698浏览量
45992 -
强化学习
+关注
关注
4文章
266浏览量
11253 -
自然语言处理
+关注
关注
1文章
618浏览量
13555
原文标题:概览迁移学习在NLP领域中的应用
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
NLP多任务学习案例分享:一种层次增长的神经网络结构
NLP的介绍和如何利用机器学习进行NLP以及三种NLP威廉希尔官方网站 的详细介绍

OpenAI介绍可扩展的,与任务无关的的自然语言处理(NLP)系统

面向NLP任务的迁移学习新模型ULMFit

如何学习自然语言处理NLP详细学习方法说明
8个免费学习NLP的在线资源
NLP迁移学习面临的问题和解决
如何利用机器学习思想,更好地去解决NLP分类任务






 工商网监
工商网监
评论