 一致性哈希是什么?为什么它是可扩展的分布式系统架构的一个必要工具
一致性哈希是什么?为什么它是可扩展的分布式系统架构的一个必要工具
在本文中,我们将了解一致性哈希是什么、为什么它是可扩展的分布式系统架构中的一个必要工具。
此外,我们将探究可用于大规模实施该算法的数据结构。最后,我们还将探究一个实际例子。
一致性哈希到底是什么?
还记得你在大学里学到的那种传统的朴素哈希方法吗?使用哈希函数,我们确保计算机程序所需的资源能够高效地存储在内存中,从而确保内存中的数据结构均匀地加载。
我们还确保该资源存储策略同样使得信息检索更高效,因而使程序运行起来更快。
经典的哈希方法使用哈希函数来生成伪随机数,然后除以内存空间的大小,将随机标识符转变成可用空间内的一个位置。
结果看起来如下:location = hash(key)mod size。
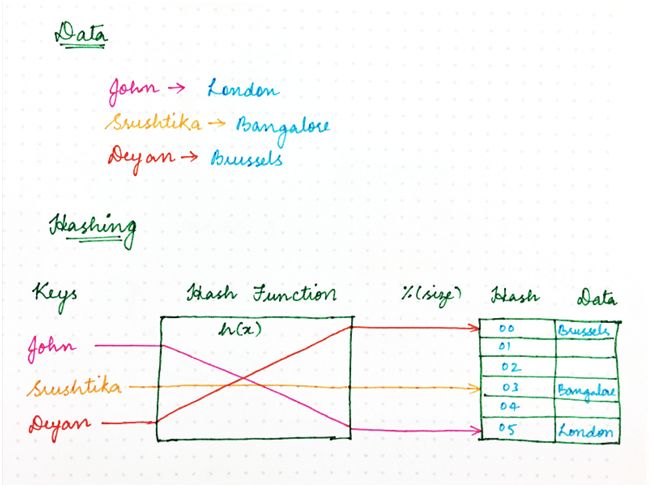
图 1
那么,我们为什么不使用同一方法来处理网络上的请求?
在各种程序、计算机或用户向多个服务器节点请求一些资源的场景下,我们需要一种机制将请求均匀地映射到可用的服务器节点,从而确保负载均衡,并且保持一致的性能。
我们不妨将服务器节点视为一个或多个请求可以映射到的占位符,现在不妨后退一步。
在经典哈希方法中,我们总是假设:内存位置的数量是已知的,而且这个数永远不变。
比如我们通常在一天内扩大或缩小集群规模,还要处理突如其来的故障。但是如果我们考虑上述场景,就无法保证服务器节点的数量保持不变。
如果其中一个突然出现故障,该怎么办?使用朴素哈希方法,我们最终需要重新计算每一个键的哈希值,因为新映射依赖节点数量/内存位置,如下所示:
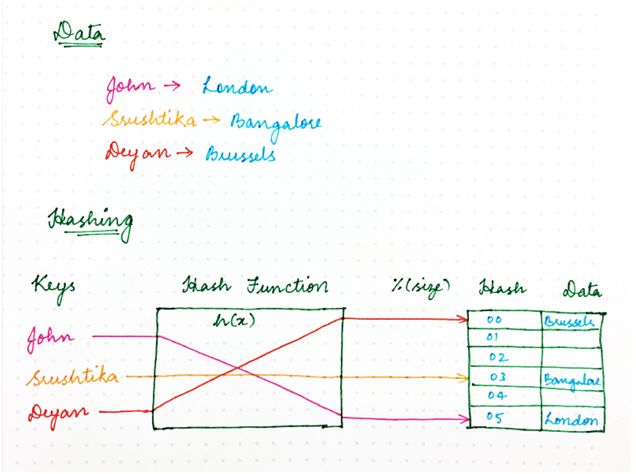
图 2:之前
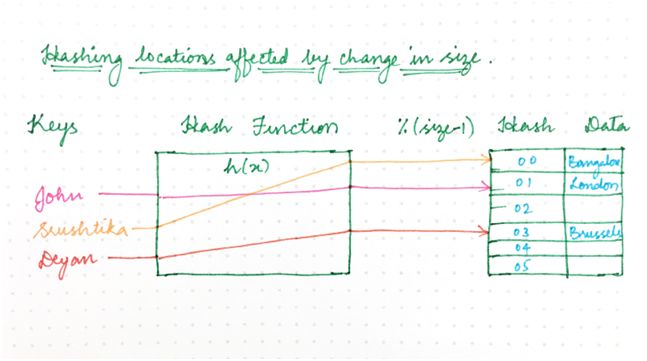
图 3:之后
只是重新计算哈希值的分布式系统(每个键的位置都移动)存在一个问题,那就是每个节点上都存储了状态。
比如说,集群规模的微小变化可能导致大量的工作,以便重新调整集群内的所有数据。
集群规模变大后,这就无以为继,因为每个哈希变更(hash change)所需的工作量随集群规模呈线性增长。这时,一致性哈希这个概念有了用武之地。
一致性哈希到底是什么?可以这样来描述:
它表示某种虚拟环结构(名为哈希环,HashRing)中的资源请求者(我们在本文中简称为“请求”)和服务器节点。
位置数量不再固定,但是环被认为有无限数量的点,服务器节点可以放置在该环上的随机位置。
当然,再次选择该随机数可以使用哈希函数来完成,但是除以可用位置数量的第二步被跳过,因为它不再是一个有限数。
请求即用户、计算机或无服务器程序,它们类似于经典哈希方法中的键,也使用同样的哈希函数放置在同一个环上。
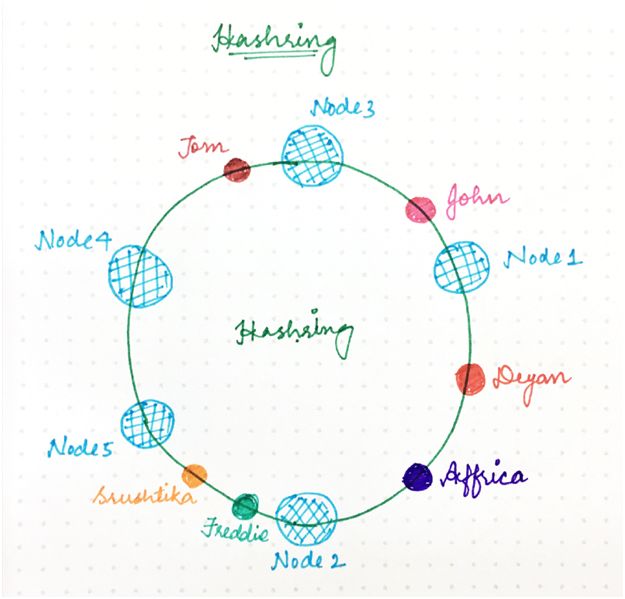
图 4
那么,如何决定哪个请求将由哪个服务器节点来处理?如果我们假设环是有序的,以便环的顺时针遍历与位置地址的递增顺序对应,那么每个请求可以由最先出现在该顺时针遍历中的那个服务器节点来处理。
也就是说,地址高于请求地址的第一个服务器节点负责处理该请求。如果请求地址高于最高寻址节点,它由最小地址的服务器节点来处理,因为环遍历以圆形方式进行。如下图所示:
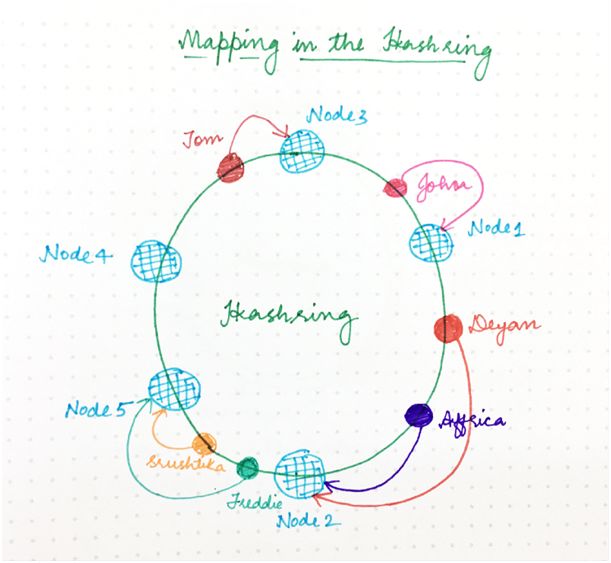
图 5
从理论上来说,每个服务器节点“拥有”哈希环的一个区间,进入该区间的任何请求将由同一服务器节点来处理。
现在,如果其中一个服务器节点(比如节点 3)出现故障,下一个服务器节点的区间就变宽,进入该区间的任何请求都将进入到新的服务器节点,该怎么办?
那就需要重新分配的是仅仅这一个区间(与出现故障的服务器节点对应),哈希环的其余部分和请求/节点分配仍然不受影响。
这与经典哈希威廉希尔官方网站 形成了对比:哈希表大小的变更实际上干扰了所有映射。
由于一致性哈希,只有一部分请求(相对于环分配因子)会受到特定的环变更的影响。(之所以出现环变更,是由于添加或删除节点导致一些请求/节点映射发生了变化。)
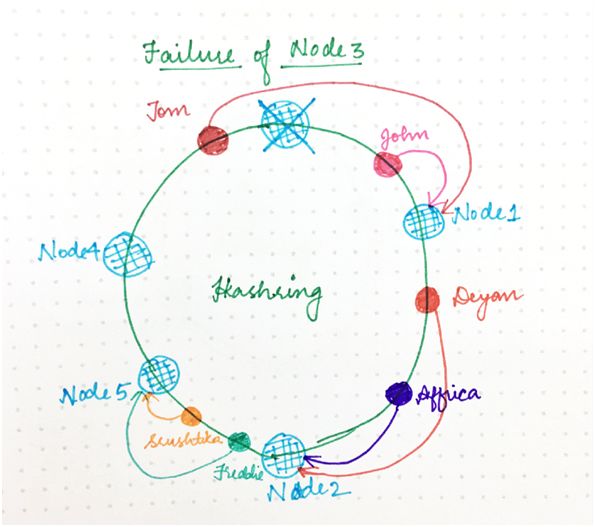
图 6
如何高效地实施一致性哈希算法?
我们弄清楚了哈希环是什么,现在需要实施下列部分让它发挥作用:
从我们的哈希空间到集群中节点的映射,让我们得以找到负责某个请求的节点。
针对解析到某个节点的集群的那些请求的集合。之后,这将让我们得以搞清楚哪些哈希值受到添加或删除某个节点的影响。
映射
为了完成上面第一个部分,我们需要下列部分:
在给出请求标识符的情况下,计算环中位置的哈希函数。
搞清楚哪个节点与哈希请求对应的方法。
为了搞清楚与某个请求对应的节点,我们可以使用一种简单的数据结构来进行表示,包括下列部分:
与环中节点对应的哈希数组。
用于查找与某个请求对应的节点的图(哈希表)。
这实际上是有序图的一种原始表示。想找到负责上述结构中某个哈希值的节点,我们需要:
执行修改后的二进制搜索,查找数组中等于或大于(≥)所要查找的哈希值的第一个节点/哈希值。
查找与图中已找到的节点/哈希值对应的节点。
添加或删除节点
正如我们在文章开头看到,添加新节点时,必须将含有各种请求的哈希环的某些部分分配给该节点。
反过来,删除节点时,已分配给该节点的请求需要由另外某个节点来处理。
我们如何查找受环变更影响的那些请求?一种解决方案是遍历分配给节点的所有请求。
对于每个请求,我们确定它是否属于已出现的环变更的范围内,必要时将它移到其他位置。
不过,执行此操作所需的工作量随分配给某个节点的请求数量的增加而增加。由于节点数量增加后,出现的环变更的数量往往增加,情况变得更糟。
在最糟糕的情况下,由于环变更常常与局部故障有关,因此与环变更相关的瞬时负载也可能加大其他节点同样受影响的可能性,可能导致整个系统出现连锁反应问题。
为了解决这个问题,我们希望请求的重新定位尽可能高效。理想情况下,我们将所有请求存储在这样一种数据结构中:便于我们找到受环上任何位置的单一哈希变更影响的那些请求。
高效地查找受影响的哈希值
往集群添加节点或从集群删除节点将改变在环的一些部分分配请求,我们称之为受影响的区间(affected range)。如果我们知道受影响区间的界限,就能够将请求移到正确的位置。
想找到受影响区间的边界,从已添加或已删除的节点的哈希值 H 开始,我们就能从 H 开始沿环向后移动(图中逆时针),直至找到另一个节点。
不妨称该节点的哈希值为 S(开始值)。该节点逆时针的请求将定位到它,那样这些请求不会受影响。
请注意:这只是简单描述了发生的情况;实际上,结构和算法更加复杂,因为我们使用大于 1 的复制因子和专门的复制策略(只有一小部分的节点适用于任何特定的请求)。
区间中的放置哈希值介于已找到的节点与已添加(或已删除)的节点之间的请求是需要移动的请求。
高效地查找受影响区间中的请求
一种解决方案就是遍历与某个节点对应的所有请求,并更新哈希值在该区间内的请求。
在 JavaScript 中可能看起来像这样:
for(constrequestofrequests){if(contains(S,H,request.hash)){/*therequestisaffectedbythechange*/request.relocate();}}functioncontains(lowerBound,upperBound,hash){constwrapsOver=upperBound< lowerBound; const aboveLower = hash >=lowerBound;constbelowUpper=upperBound>=hash;if(wrapsOver){returnaboveLower||belowUpper;}else{returnaboveLower&&belowUpper;}}
由于环是圆形的,光查找 S <= r
只要请求数量比较少,或如果节点的添加或删除比较少见,迭代某个节点上的所有请求就行。
不过,某个节点处的请求数量增加后,所需的工作量随之增加;更糟糕的是,随着节点数量增加,无论是由于自动扩展还是故障切换,环变更往往会更频繁地出现,从而触发系统上的同步负载重新均衡请求。
在最糟糕的情况下,与此相关的负载可能加大其他节点上出现故障的可能性,可能导致整个系统出现连锁反应问题。
为了应对这种情况,我们还可以将请求存储在与前面讨论的数据结构类似的单独的环数据结构中。在此环中,哈希直接映射到位于该哈希值的请求。
然后我们可以执行下列操作,找到区间内的请求:
找到区间开始值 S 后的第一个请求。
顺时针迭代,直至找到哈希值超出区间的请求。
重新找到区间内的那些请求。
针对特定的哈希更新而需要迭代的请求数量平均为 R/N,其中 R 是位于节点区间内的请求数量,N 是环中哈希值的数量,假设请求均匀地分配。
下面用一个实际的例子来介绍上述解释。
假设我们有一个集群含有两个节点:A 和 B。不妨为这每个节点随机生成一个“放置哈希值”(假设是 32 位哈希值)。
于是我们得到:
A:0x5e6058e5
B:0xa2d65c0
这将节点放在一个假想环上,其中数字 0x0、0x1、0x2......连续放置到 0xffffffff。
由于节点 A 有哈希值 0x5e6058e5,因此它负责哈希进入到区间 0xa2d65c0+1 直到 0xffffffff 以及从 0x0 直到 0x5e6058e5 的任何请求,如下所示:
图 7
另一方面,B 负责区间 0x5e6058e5+1 直到 0xa2d65c0。因此,整个哈希空间是分布式的。
从节点到哈希的这种映射需要与整个集群共享,以便环计算的结果始终相同。因此,需要特定请求的任何节点都可以查明其所在位置。
假设我们想要查找(或创建)拥有标识符“bobs.blog@example.com”的请求:
我们计算标识符的哈希值 H,比如 0x89e04a0a。
我们查看环,找到哈希值大于 H 的第一个节点,这里恰好是 B。
因此 B 是负责该请求的节点。如果我们再次需要该请求,将重复上述步骤,再次登陆到同一个节点,它有我们所需的状态。
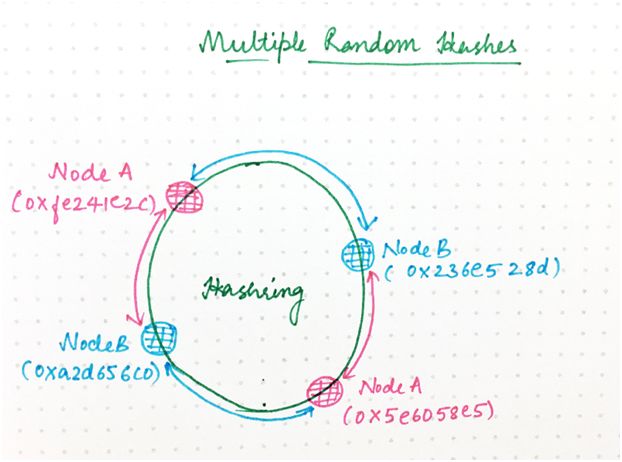
这个例子有点过于简单,实际上,每个节点有一个哈希可能会很不公平地分配负载。
你可能已注意到,在这个例子中,B 负责环的(0xa2d656c0-0x5e6058e5)/232 = 26.7%,而 A 负责其余部分。理想情况下,每个节点将负责环的相等部分。
让这更公平的一种方法是,为每个节点生成多个随机哈希值,如下所示:
图 8
实际上,我们发现这个结果仍然不能令人满意,于是我们将环分成 64 个大小同等的段,确保每个节点的哈希值放在每个段的某个位置;不过,这方面的细节不重要。
目的只是想确保每个节点负责环的同等部分,从而使负载均匀地分配。(每个节点有多个哈希值的另一个优点是,可以逐渐将哈希值添加到环中或从环中移除,以免负载突然猛增。)
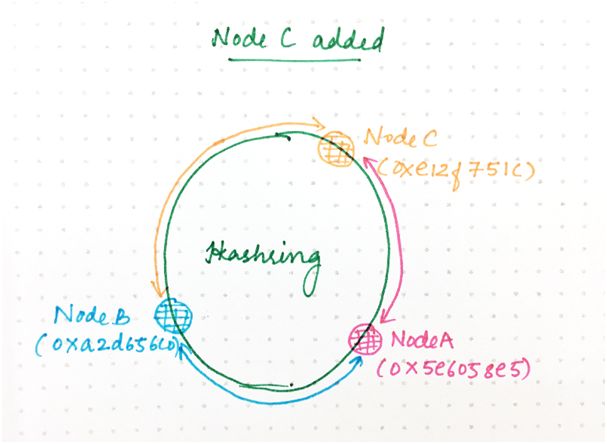
假设现在我们向环添加一个名为 C 的新节点,我们为 C 生成随机哈希值:
A:0x5e6058e5
B:0xa2d65c0
C:0xe12f751c
0xa2d65c0+1 和 0xe12f751c(用于哈希到 A)之间的环空间现在被委托给 C。所有的其他请求将继续哈希到与之前相同的那个节点。
为了处理这种权力转移,该区间内已经在 A 上的所有请求都需要将其所有状态转移到 C。
图 9
你现已了解了为什么分布式系统中需要哈希以均匀地分配负载。然而需要一致性哈希,确保一旦出现环变更,集群中只需要最小的工作量。
此外,节点需要存在于环上的多个位置,确保从统计学上来说负载更可能更均匀地分配。
为每个环变更迭代整个哈希环效率很低下。随着分布式系统的规模不断扩大,势必需要一种更高效的方法来查明什么发生了变更,从而尽可能减小环变更对性能带来的影响。这就需要新的索引和数据类型来解决这个问题。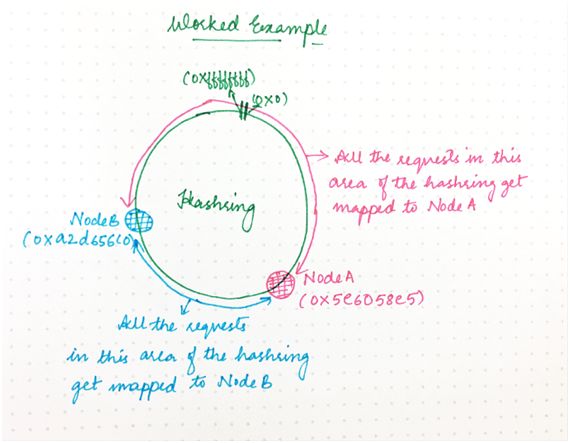
-
算法
+关注
关注
23文章
4607浏览量
92841 -
架构
+关注
关注
1文章
513浏览量
25468 -
分布式系统
+关注
关注
0文章
146浏览量
19219
原文标题:一致性哈希算法很难?看完这篇全懂了
文章出处:【微信号:TheAlgorithm,微信公众号:算法与数据结构】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一致性测试系统的威廉希尔官方网站 原理和也应用场景
一行代码,保障分布式事务一致性—GTS:微服务架构下分布式事务解决方案
一文读懂分布式架构知识体系(内含超全核心知识大图)
分布式一致性算法Yac
基于消息通信的分布式系统最终一致性平台

分布式大数据不一致性检测
分布式系统的CAP和数据一致性模型
基于自触发一致性算法的分布式分层控制策略
一种更安全的分布式一致性算法选举机制

最终一致性是现在大部分高可用的分布式系统的核心思路
Dubbo负载均衡策略之一致性哈希
深入理解数据备份的关键原则:应用一致性与崩溃一致性的区别






 工商网监
工商网监
评论