 OpenAI的研究者们提出了一种新的生成模型,能快速输出高清、真实的图像
OpenAI的研究者们提出了一种新的生成模型,能快速输出高清、真实的图像
风格迁移、变装模型这些改变图像属性的任务之前都是GAN的热门话题。现在,OpenAI的研究者们提出了一种新的生成模型,能快速输出高清、真实的图像。以下是论智对OpenAI博客的编译。
这篇文章介绍了我们的新成果——Glow,这是一个可逆的生成模型,其中使用了可反复的1×1卷积网络。2015年,我们曾推出过NICE,它是一种针对复杂高维进行建模的深度学习框架。在可逆模型的基础上,研究人员简化了NICE的网络结构,使模型能生成更加真实的高分辨率图像,并支持高效的采样,能发现可以用来控制数据属性的特征。下面让我们看看这个模型到底怎么玩:
这是年轻貌美的瑟曦。
黑化之后:
沧桑的瑟曦:
除此之外,你还能改变人物头发的颜色、眼睛大小和胡子。接下来,还有另一种玩法,即混合两张图:
碧昂斯和小李子Mix一下,长这样。
这是Glow模型的一个交互式Demo,感兴趣的读者可以移步官网体验试试,支持上传自己的照片调整脸部属性和合成两张图片。
动机
以上是研究者Prafulla Dhariwal和Durk Kingma的面部表情特征变化图。模型在训练时并没有被给予属性标签,但是它学会了一种隐藏空间,在其中特定的方向对应不同特征的变化,例如胡子的茂密程度、年龄、发色等等
生成模型与数据的观察有关,就像面对许多人脸图片,从中学习一种模型,了解数据是如何生成的。学习估计数据生成的过程需要学习数据中所有的结构,并且成功的模型可以合成和数据很相似的输出结果。精确的生成模型可应用的场景非常广泛,例如语音识别、文本分析合成、半监督学习和基于模型的控制。
Glow是一种可逆的生成模型,也可以称作“流式”生成模型,是NICE和RealNVP威廉希尔官方网站 的扩展。目前,流式生成模型的关注度并不如GAN和VAE。
流式生成模型的几个优点有:
确切的隐藏变量推断和对数相似度评估。在VAE中,模型智能大致推断与数据点相对应的隐藏变量的值,而GAN根本就没有能推测隐藏变量的编码器。但是在可逆生成模型中,这一过程能精确地推算出来。这不但能输出一个精确的结果,还能对数据的对数相似度进行优化,而不是之前对数据的下限值优化。
高效的推理和合成。自回归的模型,例如PixelCNN同样是可逆的,但是这种模型的合成结果很难平行化,通常在平行硬件上很低效。而类似Glow的流式生成模型不论在推理还是合成方面都很高效。
为下游任务提供了有用的隐藏空间。自回归模型的隐藏层有着位置的边缘分布,使其更难对数据进行正确操作。在GAN中,数据点经常不能直接表现在隐藏空间中,因为它们没有编码器,可能无法支持数据分布。在可逆生成模型和VAE上就没有这种情况。
对节省内存有重大意义。可逆神经网络的计算梯度应该是恒定的内存量,而不是线性的。
结果
利用这种威廉希尔官方网站 ,我们在标准上比较了RealNVP和我们的Glow,RealNVP是在这之前表现最佳的流式生成模型。结果如下:
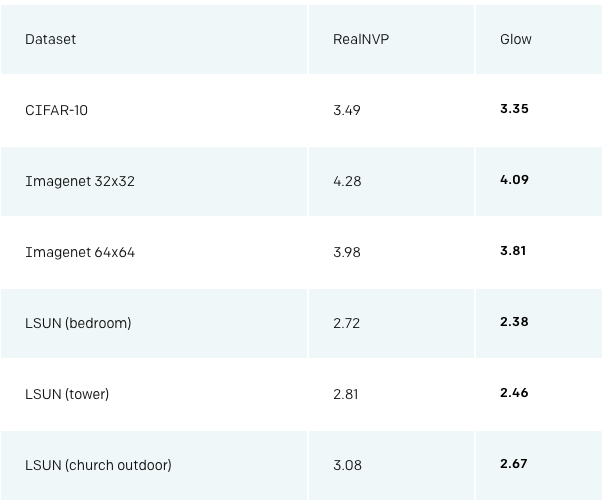
在含有30000张照片的数据集上训练之后,模型生成的样本
Glow模型能生成非常逼真的高分辨率图像,并且非常高效。模型在NVIDIA 1080 Ti GPU上只用130毫秒(0.13秒)就生成了一张256×256的照片。
在隐藏空间插值
我们还可以在两个随机面孔之间进行插值,利用编码器在两个图片之间进行编码,并从中间点中取样。注意,输入的是随机面孔,并不是模型中的样本,所以这也证明了模型可以支持完全的目标分布。
变脸过程十分流畅
在隐藏空间中处理
无需标签,我们就可以训练一个流式模型,然后利用学习到的隐藏表示进行下游任务。这些语义分布可以改变头发的颜色、图片风格、音调高低或者文本情感。由于流式模型拥有完美的编码器,你可以编码输入并且计算输入的平均隐藏向量。二者间向量的方向可以用来将输入向该方向改变。
这一过程只需要少量的标记数据,并且模型一训练完就能完成。在此之前,用GAN做这些需要训练一个单独的编码器,而VAE需要保证解码器和编码器适用于分布数据。其他类似CycleGAN直接学习表示变化的函数,也需要重新训练每一个变化。
# Train flow model on large, unlabelled dataset X
m = train(X_unlabelled)
# Split labelled dataset based on attribute, say blonde hair
X_positive, X_negative = split(X_labelled)
# Obtain average encodings of positive and negative inputs
z_positive = average([m.encode(x) for x in X_positive])
z_negative = average([m.encode(x) for x in X_negative])
# Get manipulation vector by taking difference
z_manipulate = z_positive - z_negative
# Manipulate new x_input along z_manipulate, by a scalar alpha in [-1,1]
z_input = m.encode(x_input)
x_manipulated = m.decode(z_input + alpha * z_manipulate)
用流式模型改变属性的简单代码
进步之处
相比之前的RealNVP,我们的进步之处主要是一个可逆的1×1卷积,以及删减掉其他元素,简化了模型。
RealNVP架构由两种图层组成:具有棋盘蒙版的图层和通道蒙版的图层。我们去除了棋盘样的图层,简化了结构。剩下的通道类型的蒙版起到以下作用:
在通道维度中改变输入的顺序
将输入分成A和B两部分,从特征维度的中部开始
将A输入到一个较浅的卷积神经网络。根据神经网络的输出线性地对B进行转换
连接A和B
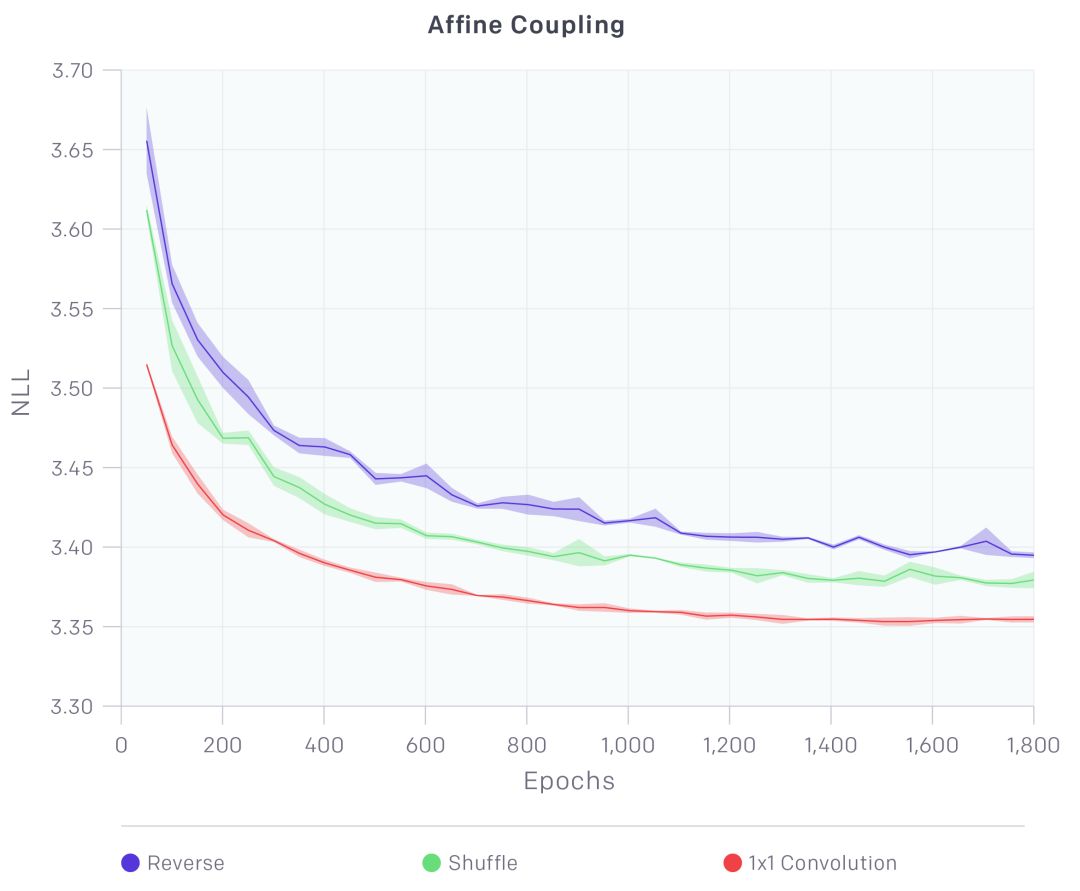
可以看到我们的1×1卷积在性能上有大大的提升
除此之外,我们取消了批归一化,将它替换成激活归一图层。该图层利用基于数据的初始化,简单地转换并缩放激活,该初始化在给定初始小批量数据的情况下将激活规范化。
训练规模
我们的结构结合了多种优化,例如梯度检查点,可以让我们在较大规模上训练流式生成模型。我们使用Horovod轻松地将模型在多个机器上进行了训练;文章开头的Demo用了8个GPU。
未来方向
这篇研究表明,训练流式模型生成真实的高清图像是很有潜力的,并且经过学习的隐藏表示可以很容易用于下流任务。我们对未来工作的方向有以下计划:
1.在可能性上比其他模型更有竞争力
在对数相似度上,自适应模型和VAE的表现比流式模型要好,但是他们在采样和精确推理上不如流式模型。未来我们会尝试结合这几种模型,以弥补不足。
2.改进结构,提高计算和参数效率
为了生成逼真的高分辨率图像,人脸生成模型利用大约200M的参数和将近600个卷积层,训练起来成本很高。但是更浅的网络表现得又不好。使用自注意力结构或者进行渐进式训练可能会让训练成本更便宜。
-
图像
+关注
关注
2文章
1084浏览量
40455 -
深度学习
+关注
关注
73文章
5500浏览量
121118
原文标题:OpenAI提出能合成高清逼真图像的模型:“我们和GAN不一样!”
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
为什么生成模型值得研究
一种解决连续问题的真实在线自然梯度行动者-评论家算法
美研究者研发出了一种新型缝线 能够监测伤口的愈合情况
卫星图像进行目标识别仍然困难重重,美国提出了一种方法
OpenAI最新提出的可逆生成模型Glow
OpenAI提出了一种回报设置方法RND
JD和OPPO的研究人员们提出了一种姿势引导的时尚图像生成模型
微软亚洲研究院的研究员们提出了一种模型压缩的新思路


一种基于改进的DCGAN生成SAR图像的方法

识别「ChatGPT造假」,效果超越OpenAI:北大、华为的AI生成检测器来了

Adobe提出DMV3D:3D生成只需30秒!让文本、图像都动起来的新方法!






 工商网监
工商网监
评论