 原因分析:CPU拓扑差异导致Unixbench分数异常
原因分析:CPU拓扑差异导致Unixbench分数异常
本文通过实验论证:Unixbench的Pipe-based Context Switching用例受操作系统调度算法的影响波动很大,甚至出现了虚拟机跑分超过物理机的情况。在云计算时代,当前的Unixbench已不能真实地反映被测系统的真实性能,需要针对多核服务器和云计算环境进行完善。
简单的说,视操作系统多核负载均衡策略的差异,该用例可能表现出两种截然不同的效果:
1、在惰性的调度策略环境下,测试得分较高,但是会导致系统中任务调度延迟,最终可能引起业务性能抖动。例如,在视频播放、音频处理的业务环境中,引起视频卡顿、音频视频不同步等问题。
2、在积极的调度策略环境下,测试得分偏低,但是系统中任务运行实时性更高,业务运行更流畅。
后文将详细说明Pipe-basedContext Switching用例的设计原理,测试其在不同系统中的运行结果,并提出测试用例改进建议。
1测试背景
近期,团队在进行服务器选型的时候,需要对两款服务器进行性能评估,其中一款服务器采用64核Xeon CPU,另一台则采用16核Atom CPU。详细配置信息如下:
| 指标名称 | Xeon服务器 | Atom服务器 |
| Architecture | x86_64 | x86_64 |
| CPUs | 64 | 16 |
| Threads per core | 2 | 1 |
| Core(s) per socket | 16 | 16 |
| Socket(s) | 2 | 1 |
| NUMA node(s) | 1 | 1 |
| Model name | Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz | Intel(R) Atom(TM) CPU C3958 @ 2.00GHz |
| CPU MHz | 2499.902 | 1999.613 |
| BogoMIPS | 4993.49 | 3999.22 |
| L1d cache | 32K | 24K |
| L1i cache | 32K | 32K |
| L2 cache | 256K | 2048K |
| L3 cache | 40960K | None |
根据硬件厂商的评测,Xeon服务器的综合性能是Atom服务器的3倍。
我们采用了久负盛名的Unixbench性能测试套件,为我们最终的选择提供参考。
Xeon的性能碾压Atom是毋庸置疑的,毕竟Atom 更专注于功耗而不是性能,Atom服务器甚至没有3级缓存,并且StoreBuffer、Message Queue的深度更低,流水线级数更少。
出于业务需求,在整个测试过程中我们更关注单核的性能。为了排除软件的影响,两台服务器均安装Centos 7操作系统。
测试命令很简单,在控制台中执行如下命令:
./Run -c 1 -v
执行时间比较久,我们可以到一边去喝点烧酒。一杯烧酒下肚,神清气爽:-)可以看看结果是否符合咱们的预期:
| 指标名称 | Xeon服务器 | Atom服务器 |
| Dhrystone 2 using register variables | 2610.1 | 1283.7 |
| Double-Precision Whetstone | 651.2 | 489.4 |
| Execl Throughput | 447.9 | 361.5 |
| File Copy 1024 bufsize 2000 maxblocks | 2304.5 | 955.0 |
| File Copy 256 bufsize 500 maxblocks | 1494.5 | 711.2 |
| File Copy 4096 bufsize 8000 maxblocks | 4475.9 | 1396.2 |
| Pipe Throughput | 1310.9 | 614.4 |
| Pipe-based Context Switching | 428.4 | 339.8 |
| Process Creation | 461.7 | 159.6 |
| Shell Scripts (1 concurrent) | 1438.8 | 326.7 |
| Shell Scripts (8 concurrent) | 5354.5 | 789.8 |
| System Call Overhead | 2237.0 | 930.1 |
| System Benchmarks Index Score | 1390.9 | 588.4 |
总分整体符合预期:Xeon服务器单核性能是Atom服务器的2.36倍(1390/588.4)
但是,这里出现了一个异常,细心的读者应该已经发现:Pipe-based Context Switching测试用例的结果比较反常!从上表可以看出,无论是总分还是单项分数,Xeon服务器均远远超过Atom服务器。其中也包括Pipe Throughput这项用例。然而“Pipe-based Context Switching”这项指标显得有点与众不同:在这项指标中,Xeon服务器的优势并不明显,仅领先25%左右。
为了排除测试误差,我们反复进行了几次测试,均发现同样的规律。“Pipe-based Context Switching”项的分数差异并不明显,没有体现出Xeon服务器的性能优势。
这一问题引起了我们的兴趣,Unixbench这样的权威测试软件的结果居然和厂商宣称的出入这么大。为了找出原因,我们使用其他测试环境,进行了一系列的对比测试。首先,我们找了更多物理机进行对比分析。
1.1物理机对比测试
为此,我们使用另一组服务器进行对比测试,其型号分别为:HP ProLiantDL360p Gen8、DELL PowerEdge R720xd。配置如下:
| 指标名称 | HP ProLiant DL360p Gen8 | DELL PowerEdge R720xd |
| Architecture | x86_64 | x86_64 |
| CPUs | 24 | 32 |
| Threads per core | 2 | 2 |
| Core(s) per socket | 6 | 16 |
| Socket(s) | 2 | 2 |
| NUMA node(s) | 1 | 1 |
| Model name | Intel(R) Xeon(R) CPU E5-2630 0 @ 2.30GHz | Intel(R) Xeon(R) CPU E5-2680 0 @ 2.70GHz |
| CPU MHz | 1200.000 | 2300.000 |
| BogoMIPS | 4594.05 | 4615.83 |
| L1d cache | 32K | 32K |
| L1i cache | 32K | 32K |
| L2 cache | 256K | 256K |
| L3 cache | 15360K | 20480K |
分别在两台服务器的控制台中输入如下命令,单独对“Pipe-based Context Switching”用例进行测试:
./Run index2 -c1
得到该测试项的分数为:
| 指标名称 | ProLiant DL360p Gen8 | PowerEdge R720xd |
| Pipe-based Context Switching | 381.4 | 432.1 |
测试结果与上面相似,硬件参数明显占优的DELLL跑分仅领先HP不到20%:-(
1.2物理机VS虚拟机
测试似乎陷入了迷途,然而我们一定需要将加西亚的信送到目的地,并且坚信“柳暗花明又一村”的那一刻终究会到来。
为此,我们使用三组云虚拟机来进行测试。这三组虚拟机配置如下:
| 指标名称 | 虚拟机A | 虚拟机B | 虚拟机C |
| Architecture | x86_64 | x86_64 | x86_64 |
| CPUs | 4 | 4 | 4 |
| Threads per core | 2 | 1 | 1 |
| Core(s) per socket | 2 | 4 | 4 |
| Socket(s) | 1 | 1 | 1 |
| NUMA node(s) | 1 | 1 | 1 |
| Model name | Intel(R) Xeon(R) CPU E5-2682 v4 @ 2.50GHz | Intel(R) Xeon(R) CPU E5-26xx v4 | Intel(R) Xeon(R) CPU E5-2676 v3 @2.40 GHz |
| CPU MHz | 2494.222 | 2394.454 | 2400.102 |
| BogoMIPS | 4988.44 | 4788.90 | 4800.07 |
| L1d cache | 32K | 32K | 32k |
| L1i cache | 32K | 32K | 32k |
| L2 cache | 256K | 4096K | 256K |
| L3 cache | 40960K | none | 30720K |
这三款虚拟机与此前的物理机参数相差不大,如果不出意外的话,分数应当介于300~400之间。
然而测试结果出人意料,以至于笔者的镜片摔了一地:
| 指标名称 | 虚拟机A | 虚拟机B | 虚拟机C |
| Pipe-based Context Switching | 109.4 | 589.1 | 105.1 |
特别令人吃惊的是:第二组虚拟机的测试分数,竟然是物理主机的1.5倍,并且是第一组虚拟机和第三组虚拟机的5.4倍。
1.3单核和多核对比测试
为此,我们认真分析不同系统中的CPU占用率。发现一个特点:在Pipe-based Context Switching用例运行期间,在得分高的环境中,两个context线程基本上运行在同一CPU上。而在得分低的环境中中,两个context线程则更多的运行在不同的CPU上。这说明:测试结果差异可能与Guest OS中的调度算法及CPU负载均衡策略有关。
我们不得不启用了排除法,先看单核和多核之间的差异。
为了验证猜想是否正确,我们临时修改了Guest OS中内核调度算法。修改原理是:在唤醒线程时,不管其他CPU核是否空闲,优先将被唤醒任务调度到当前CPU中运行。这样的调度算法,其缺点是:被唤醒任务将不能立即运行,必须等待当前线程释放CPU后才能获得CPU,这将导致被唤醒线程的实时性较弱。
经过测试,在打上了Linux内核调度补丁的系统中,Pipe-based Context Switching在虚拟机和物理机上,得分大大提升。实际测试的结果如下:
| 指标名称 | 虚拟机A |
| Pipe-based Context Switching | 530.2 |
很显然,我们不能将上述补丁直接应用到生产环境中,因为该补丁会影响任务运行的实时性。因此我们将Linux内核调度补丁回退,并修改“Pipe-based ContextSwitching”测试用例的代码,强制将context线程绑定到CPU 0中运行,这样可以避免Guest OS中的调度算法及CPU负载均衡算法的影响。测试结果如下:
| 指标名称 | 虚拟机A | 虚拟机B | 虚拟机C |
| Pipe-based Context Switching | 761.0 | 953.7 | 675.3 |
我们再次修改“Pipe-based Context Switching”测试用例的代码,强制将context线程分别绑定到CPU 0和CPU 1中运行,这样也可以避免Guest OS中的调度算法及CPU负载均衡算法的影响。测试结果如下:
| 指标名称 | 虚拟机A | 虚拟机B | 虚拟机C |
| Pipe-based Context Switching | 109.1 | 133.6 | 105.1 |
可以看到,应用了新的“Pipe-basedContext Switching”补丁之后,所有测试结果都恢复了正常,离真相越来越近了。
2原因分析: CPU拓扑差异导致Unixbench分数异常
通过前面针对“Pipe-based Context Switching”单实例用例的测试,带给我们如下疑问:
为什么在该用例中,虚拟机B得分接近600,远高于虚拟机A、虚拟机C,甚至高于虚拟机A所在的物理机?
为了分析清楚该问题,我们分析了Pipe-based Context Switching用例, 这个用例的逻辑是:测试用例创建一对线程A/B,并创建一对管道A/B。线程A写管道,线程B读A管道;并且线程B写B管道,线程A程读B管道。两个线程均同步执行。
经过仔细分析,虚拟机A和虚拟机B在该用例上的性能差异的根本原因是:在虚拟机环境下,底层Host OS向Guest OS透传的cpu拓扑不同,导致虚拟机系统中的调度行为不一致, 最终引起很大的性能差异。其中虚拟机A是按照Host主机的实际情况,将真实的CPU拓扑传递给Guest OS。而虚拟机B的主机则没有将真实的物理主机CPU拓扑传递给Guest OS。这会导致虚拟机内所见到的CPU拓扑和共享内存布局有所不同。
在真实的物理服务器上,每个物理核会有各自的FLC和MLC,同一个Core上的CPU共享LLC。这样的CPU拓扑允许同一Core上的CPU之间更积极的进行线程迁移,而不损失缓存热度,并且能够提升线程运行的实时性。这个特性,更利于视频播放这类实时应用场景。
下图是虚拟机A和虚拟机B中看到的CPU视图:
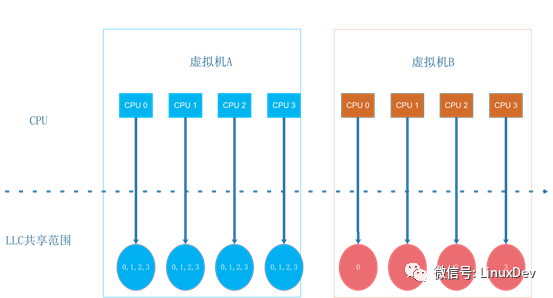
拓扑结构的差异地方在LLC的共享方式,虚拟机A使用的拓扑结构与物理机一致,同一个Core内CPU共享LLC。而虚拟机B的配置是同一个Core内CPU不共享LLC。不共享LLC的场景下,Linux将每个CPU在LLC层次的调度域设置为空。这样,虚拟机B的Guest OS会认为同一物理CPU内的两个超线程是两个独立的CPU,处于不同的域之间(这与实际的物理机配置不一致),因此其负载均衡策略会更保守一些。唤醒一个进程时,内核会为其选择一个运行的目标CPU,linux的调度策略会考虑亲和性(提高cache命中率)和负载均衡。在Linux 3.10这个版本下,内核会优先考虑亲和性,亲和性的目标是优先选取同一个调度域内的CPU。虚拟机A共享LLC,所有的CPU都在同一个调度域内,内核为其选择的是同一调度域内的空闲CPU。而虚拟机B因为LLC层次的调度域为空,在进入亲和性选择时,无法找到同一个调度域内的其它空闲CPU,这样就直接返回了正在进行唤醒操作的当前CPU。
最终,在虚拟机B中,除了偶尔进行的CPU域间负载均衡以外,两个测试线程基本上会一直在同一个CPU上运行。而虚拟机A的两个进程会并发的运行在两个不同的CPU上。
这一特征下的运行时间轴如下:
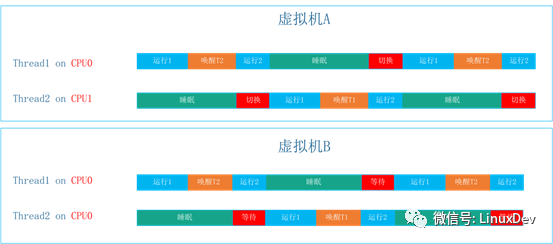
虚拟机B场景引入的开销是唤醒和等待运行开销,虚拟机A场景引入的开销是唤醒和切换运行开销。
在正常的工作负载下面,进程运行的时间会远大于进程切换的开销,而Pipe-based Context Switching用例interwetten与威廉的赔率体系 的是一个极限场景,一个线程在唤醒对端到进入睡眠之间只执行很简单的操作,实际等待运行的开销远小于切换运行的开销。
此外,在虚拟化场景下,两种方式唤醒操作中也存在差异,在虚拟机A这个场景下,唤醒的开销也远大于虚拟机B场景中的唤醒开销。最终出现虚拟机B上该用例的得分远高于虚拟机A、虚拟机C,甚至高于物理机上的得分。
为了进一步验证我们的分析是否正确。我们在HOST OS中,分别向虚拟机A的GuestOS和虚拟机B的Guest OS按照不同方式传递CPU拓扑。测试发现:在同样的CPU拓扑结构下,二者的测试分数是一致的。换句话说,导致该项测试分数差异的原因,在于不同的HOST OS向Guest OS传递的CPU拓扑存在差异,进而导致Guest OS中任务调度行为的差异。
3 结论:Unixbench需要针对多核服务器和云环境进行优化
unixbench的Pipe-based Context Switching用例受操作系统调度算法的影响比较大。视操作系统多核负载均衡策略的差异,可能表现出两种截然不同的效果:
1、在多核负载均衡策略不积极的系统中,测试线程更多的运行在同一个CPU中,线程之间的切换开销更低。因此测试得分更高,但是会导致系统中任务调度延迟。在实时性要求比较高的系统中,这会引起业务抖动。例如,在视频播放、音频处理的业务环境中,这可能引起视频卡顿、音频视频不同步等问题。
2、在多核负载均衡策略更积极的系统中,测试线程更多的运行在不同的CPU中,线程之间的切换开销更高。因此测试分值更低,但是系统中任务调度延迟更低,业务的性能不容易产生波动。
换句话说:当前的Unixbench已不能真实地反映被测系统的真实性能,需要针对多核服务器和云计算环境进行完善。
4 修改建议
我们建议调整unixbench测试用例,将测试用例的线程绑定到Guest OS的CPU上。这样就可以避免受到Guest OS调度策略和CPU负载均衡策略的影响。具体来说,有两种方法:
1、将context1和context2两个线程绑定在同一个CPU核上面。这样可以反应出被测试系统在单核上的执行性能。
2、将context1和context2两个线程分别绑定到不同CPU核上面。这样可以反应出被测试系统在单核的执行性能,以及多核之间的核间通信性能。
(完)
-
cpu
+关注
关注
68文章
10863浏览量
211799 -
云计算
+关注
关注
39文章
7823浏览量
137417 -
服务器
+关注
关注
12文章
9165浏览量
85437
原文标题:燕青: Unixbench 测试套件缺陷深度分析
文章出处:【微信号:LinuxDev,微信公众号:Linux阅码场】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
CYT2B7 SFlash被异常修改的原因?
【NanoPi NEO试用体验】利用unixbench进行性能评估
导致STM32进入HardFault异常的原因
导致致命异常错误和无效页错误的原因是什么?
导致MCU出现功能严重异常的几个原因分析
CPU 拓扑中的SMP架构
分享排查Linux系统CPU占用的一个Shell脚本

拓扑视图与实际拓扑结构间的差异





 工商网监
工商网监
评论