 基于卷积神经网络的组合模型处理NLP任务讽刺检测
基于卷积神经网络的组合模型处理NLP任务讽刺检测
编者按:NTU研究人员Soujanya Poria等提出了一个组合模型,基于预训练的卷积神经网络提取情感、情绪、个性特征,以进行讽刺检测。NTHU PhD学生Elvis Saravia简明扼要地总结了论文的主要思路。
概览
这篇论文使用基于卷积神经网络(CNN)的组合模型处理NLP任务讽刺检测(sarcasm detection)。讽刺检测对情感检测和情感分析等领域而言十分重要,因为这一表达将翻转句子的极性。
例子
人们可以认为讽刺用来挖苦或奚落。比如“是你还是我该吃药了”、“我每周工作40小时才这么穷”。(examples.yourdictionary.com上有更多例子。)
挑战
理解和检测讽刺很重要的一点就是理解关于事件的事实。这让我们可以检测客观极性(通常是负面的)和作者的讽刺特征(通常是正面的)之间的反差。
考虑以下例子,“我爱分手之苦”,很难从中提取检测其中是否存在讽刺的知识。例子中的“我爱其苦”提供了作者表达的情感的知识(在这个例子中是正面的),而“分手”描述了一个相反的情感(负面)。
讽刺语句中的其他挑战包括指代多个事件,以及提取大量事实、常识、指代解析、逻辑推理。论文的作者依靠CNN从讽刺语料库中自动学习特征。
贡献
将深度学习应用于讽刺检测
利用用户简介、情绪、情感特征进行讽刺检测
应用预训练模型自动提取特征
模型
情感转移(sentiment shifting)在牵涉讽刺的交流中很常见。因此,论文作者首先训练基于CNN训练一个情感模型学习情感特定的特征提取。模型在低层学习局部特征,之后在高层转换为全局特征。作者发现讽刺表达和用户相关——某些用户比其他用户发布更多讽刺性内容。
作者提出的框架整合了基于用户个性的特征,情感特征,基于情绪的特征。每组特征通过独立的模型学习,成为从数据集中提取讽刺相关特征的预训练模型。
CNN框架
CNN能够有效地建模局部特征以学习更全局的特征,本质上,这是在学习上下文(learn context)。句子使用词向量(嵌入)表示(基于Google的word2vec向量)。使用了非静态表示,因此,词向量的参数在训练阶段学习。接着,在特征映射上应用最大池化,以生成特征。然后是softmax层及全连接层,以输出最终预测。(见下图)

为了得到其他特征——情感(S)、情绪(E)、个性(P)——预训练了CNN模型,并使用这些预训练模型从讽刺数据集中提取特征。训练每个模型使用了不同的训练数据集。(参考论文了解更多细节)
测试了两个分类器——一个CNN分类器(CNN)和一个SVM分类器(CNN-SVM,使用CNN提取的特征作为输入)。
另外还训练了一个基线分类器(B)——仅仅使用CNN模型,没有结合其他模型(情绪、情感等)。
试验
数据为均衡和失衡的讽刺推文数据集,取自Ptacek等2014年的工作和The Sarcasm Detector。移除了用户名、URL、#标记,使用了NLTK Twitter Tokenizer。(参考论文了解更多细节)
下表显示了CNN和CNN-SVM分类器的表现。我们可以观测到结合了讽刺特征、情感特征、情绪特征、个性特征的模型(特别是CNN-SVM)的表现超过了其他模型。
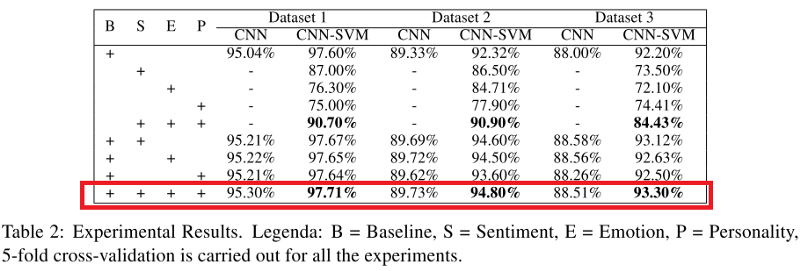
B = 基线,S = 情感,E = 情绪, P = 个性。所有试验使用了五折交叉验证
下表则是与当前最先进模型(第一行)和另一个知名的讽刺检测模型(第二行)的比较。同样,论文提出的模型的表现超过了其他模型。

D3 => D1意为在数据集3上训练,在数据集1上测试
论文测试了模型的概括能力,主要的发现是如果数据集本质上很不相同,会显著影响结果。(见下图基于PCA可视化的数据集)。例如,在数据集1上训练,然后在数据集3上测试,模型的F1评分为33.05%.
结论
总体而言,论文作者发现讽刺高度依赖主题,并且高度上下文相关。因此,情感和其他上下文线索有助于从文本中检测讽刺。使用预训练的情感、情绪、个性模型从文本中捕捉上下文信息。
手工构造的特征(例如,n元语法),尽管某种程度上有助于讽刺检测,会产生非常稀疏的特征向量表示。因此,使用词嵌入作为输入特征。
-
神经网络
+关注
关注
42文章
4771浏览量
100760 -
数据集
+关注
关注
4文章
1208浏览量
24700 -
深度学习
+关注
关注
73文章
5503浏览量
121157
原文标题:基于深度卷积网络进行讽刺检测
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论