 超级计算机Top 500名单的更新,美国重回算例榜首但明显损失份额
超级计算机Top 500名单的更新,美国重回算例榜首但明显损失份额
就在刚才,美国超算确认登顶世界第一。
北京时间 6 月 25 日下午 15:00 左右,在德国法兰克福召开的全球超算大会(ISC2018)公布了“超级计算机500强”(TOP500)最新榜单,其中,美国超算“Summit”排名第一,中国超算“神威·太湖之光”位列第二,第三名则是来自美国的“Sierra”。
在上一届的榜单中,中国超算“神威·太湖之光”和“天河 2 号”分别位列 TOP500 第一、第二,美国的超算“Titan”则名列第五,也是 20 年来美国首次跌出该榜单的前三名。而这一次,美国重回全球超算霸主地位。

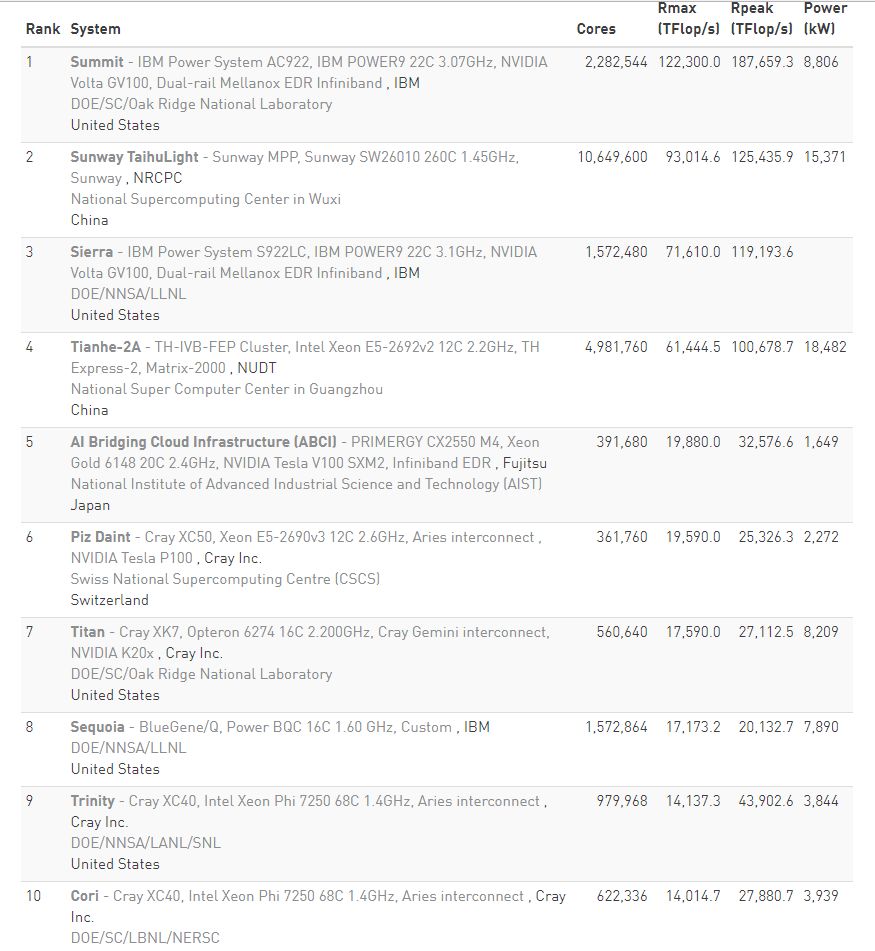
图丨最新全球超算 TOP 500 榜单前 10 名
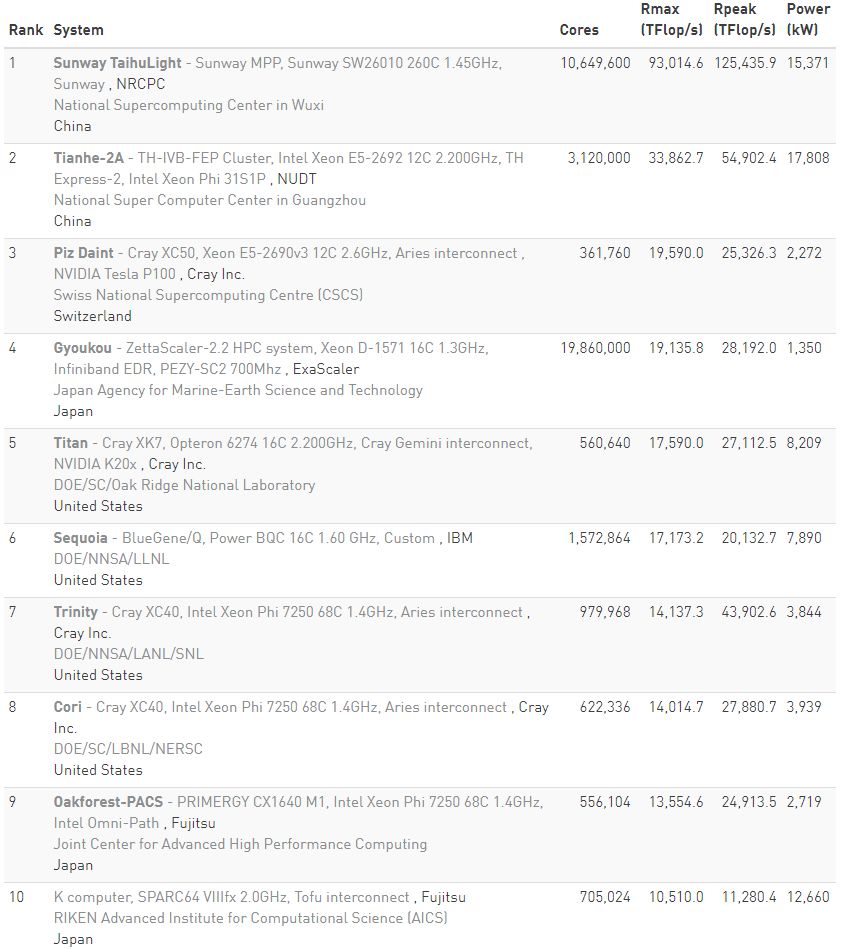
图丨上一届全球超算 TOP 500 榜单前 10 名
美国凭借着进入半导体产业早,相关威廉希尔官方网站 积累深厚,多年来一直垄断着 Top 500 超算冠军,不仅算力高超,就连超算的数量也占据绝对优势,不过最近 10 年来中国超算威廉希尔官方网站 奋起直追,入围 Top 500 的超算越来越多,甚至最近 5 年 10 届 Top 500 冠军都是中国超算,入围 Top 500 的超算数量也超过美国,直到美国前不久推出的 Summit 超算,才终于在算力反超中国的神威·太湖之光,成功夺回 Top 500 冠军之位。
但除了中美以外,日本和其他国家也都积极推动超算的发展,日本最近公布的新版 Kyu 超算架构,基于 Arm 架构,其理论性能远超太湖之光,甚至能轻松压制美国的 Summit 超算,不过该架构仍在测试阶段,还未量产,最快也要 2018 下半年才有机会挑战 Top 500。
现在问题来了,各国在超算领域激烈竞争到底有什么意义呢? 答案是超算非常实用,但对大国来说,拥有超算带来的软实力、象征意义也很重要。
就实用范围而言,超算就是什么都能算,不只能夜观天象,揭开宇宙的奥秘,还能把天有不测的风云抓出规律,告诉我们明天出门要不要带伞;而在基础产业推动方面,比如说材料的合成、矿产的探勘,超算扮演着极为重要的地位,美国从石油输入国转而成为产出国部分也是超算之助;超算甚至能代替神算出生命的奥秘,解析那些藏在我们身体里面的最神秘的法则,或者是组合出全新的生命型态;超算帮助我们研发新药,代替神农尝百草;流行的社群网络分析,从大的社会风向,到小的个人人格特征定位也是超算在行的工作;面对金融体系的科技化,网络化,以及区块链化,这些都需要庞大的算力在背后推动;另外,军事与武器研发更需要超算之助。
而就象征意义而言,因为算力对于人类社会的影响越来越深,拥有足够的算力,不只代表对整体社会的发展脉络更能有效控制,让国家能够更有效率的管理与发展,让人民更幸福,同时,算力也代表了国家所能投入的资源及威廉希尔官方网站 力,某种程度上也等同于国力的展现,而这也是各国每年都拼尽全力一较算力高低的原因之一。
Top 500名单的更新,美国重回算例榜首,但明显损失份额
而每年固定时间都会公布排名的全球超算 Top 500 名单也已经公布,从名单中可以看出,美国的 Summit 架构已经确定成为今年上半年 Top 500 超算的榜首,但与此同时,中国超算的份额又再度增加,较去年底的比重增加了 0.8%,达到 41.2%,美国则是再度衰退,仅剩 24.8%。
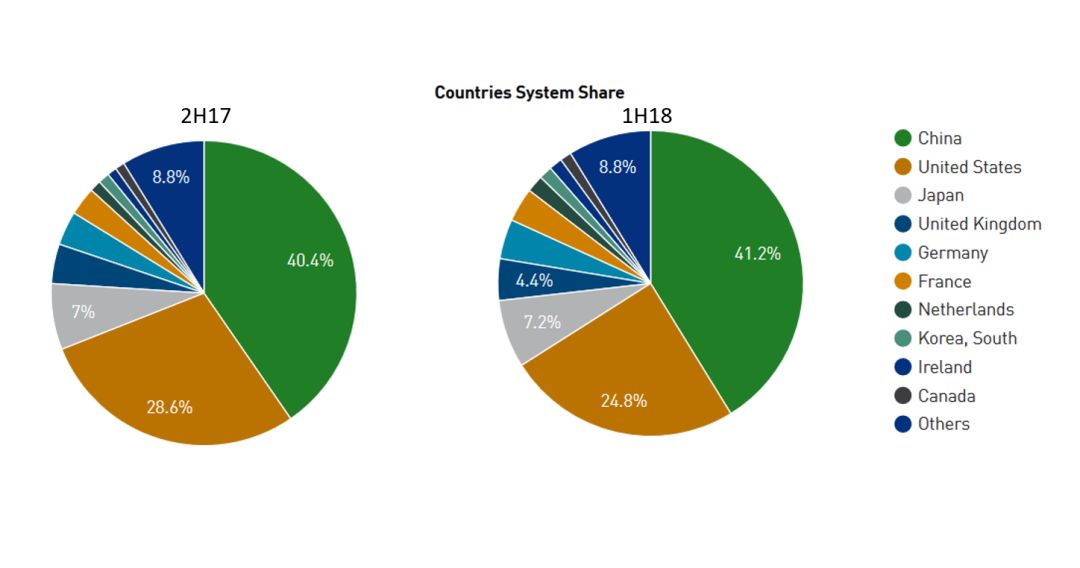
图|虽然美国夺回超算榜首,但中国超算占 Top 500 比重达历史新高
除了榜首的 Summit 超算以外,第三名的 Sierra 超算使用的是与 Summit 类似的 Power 架构+NVIDIA GPU,相较第二名的太湖之光,仅用了不到 1 成的核心就能输出其 8 成的计算性能,明显是走高能效路线。另外,日本超算几乎清一色使用英特尔的平台搭配 GPU 或 Xeon Phi 辅助加速器,自有架构可能要等待年底才会现身。
能耗是另一个值得关注的重点,Green 500 名单亦有重要意义
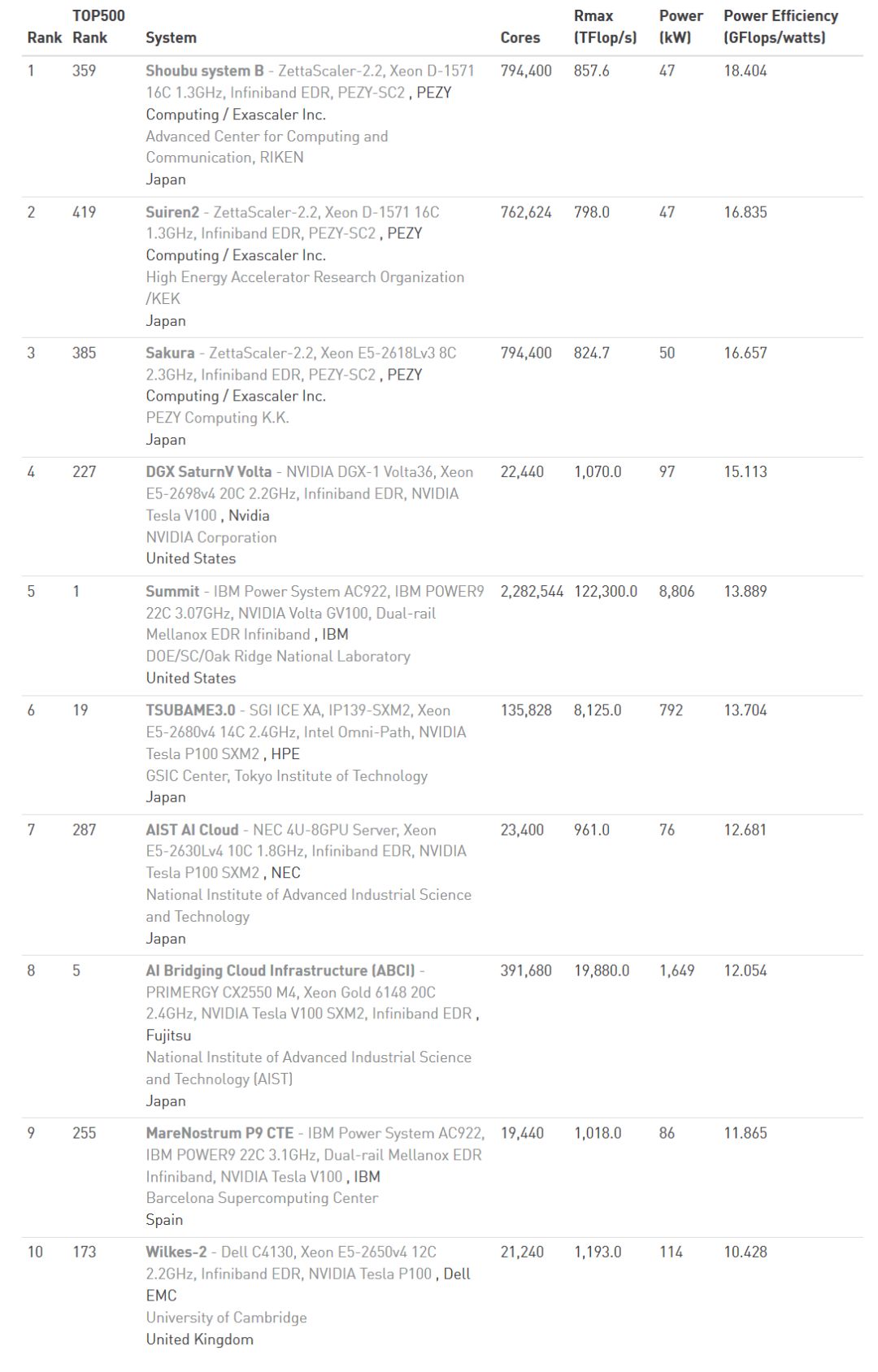
日本仍毫不意外的占据了 Green 500 前 10 大的绝对多数,排名第一的 Shoubu System B 的能效表现已经达到每瓦 18.4G Flops,创下了历史新高。
另外,由于 Summit 超算使用基于 14nm 工艺的 Power 架构加上基于 12nm 的NVIDIA GPU,在每瓦能效表现方面要明显比使用 28nm 工艺芯片的太湖之光更有优势,才用类似架构的第 3 名超算架构也有类似的能效表现。
CPU 仍是超算主角,GPU渗透率虽持续增加但挑战仍大
过去很长一段时间,超算主要架构是以 RISC 芯片为主,而后转往 X86,但随着深度学习等 AI 计算的需求增加,GPU 在超算架构中所占的份量越来越吃重,去年底公布的 Top 500 超算中就有将近 90 款超算平台使用 GPU 来进行加速,这些超算架构也都属于性能领先群。
虽然 GPU 或其他计算加速架构的引入越来越多,但是纯 CPU 的超算架构仍占将近 8 成,而各国在 CPU 架构的推陈出新,也证明了这个传统架构在超算领域仍然还有很大的发挥空间,不仅效能不输给 GPU 加速,甚至能耗表现也能有一流的表现。
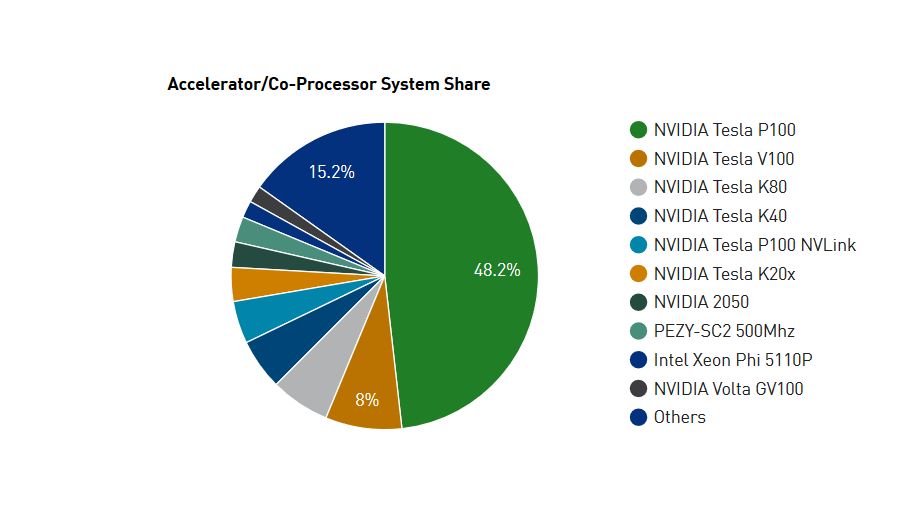
图|在 Top 500 排名中已经有超过98款超算采用 NVIDIA 的 GPU 架构,较 2017 年底的 87 款增加了 11 款。
虽然 GPU 已经在很多计算领域证明了自己的价值,但是在超算平台上,CPU 仍是绝对主流的架构,占了将近 8 成。不只是英特尔的 X86 CPU,MIPS、Arm,甚至是 Power 架构等传统 RISC 架构,以及中国自有的申威核心,都证明面对超算环境,也能输出不下于 GPU 的性能,当然,应用到超算中的 CPU 架构已经不是纯粹的 CPU,更多包含了许多辅助的数学计算核心,甚至英特尔才刚推出的神经网络处理器就整合了 FPGA 架构,这些架构也都证明了自己的效能和效率都不下于 GPU,虽然 NVIDIA 的 GPU 架构在服务器当中拥有崇高的地位,但是在超算领域仍是挑战者。
神威·太湖之光将退役架构改造成一流超算架构
中国的神威・太湖之光,采用了纯 CPU 计算架构的组合,不使用英特尔的处理芯片,也不使用目前火热的 GPU 计算架构,但其达到的算力却超越除了 Summit 超算以外的其他架构的组合,不过在能耗方面略显弱势。
太湖之光所使用的申威 26010 在单一芯片中整合了超过 260 个核心,在整个超算系统中使用了 40960 颗芯片,核心数量高达 10649600 个,单纯就数量而言,比上次排名第 4 的日本晓光 (Gyoukou) 超算少,但持续输出性能远远超过同为中国产的超算平台第 2 名天河二将近 3 倍之多,更是日本晓光超算性能的 4 倍。
图|申威架构虽非原创,但在研究人员的巧手下化身中国自有高效能超算核心
申威 26010 处理器架构来源是出自于已经退出市场的 DEC Alpha 微架构,不过在经过研发人员的彻底改造之后,转而变成类似 IBM Power 微架构的芯片,成为针对大规模平行计算环境优化的高效率计算架构,单芯片 260 个核心同时运作的功耗只有 15.371 W。虽然其威廉希尔官方网站 出处并非原创,但是在超算这种大规模计算环境中得以凸显其优势,甚至超越了以英特尔与 NVIDIA 为主流组合的众多超算架构。
但是申威 26010 架构因为过于特化,其单核心的效率非常低,甚至比英特尔的 Atom 和主流 Arm 架构还要低,也不适合用在主流的一般消费性计算上。其优势在于强大的互联与协同工作能力,突破过去超算架构在计算芯片数量达到一定程度时,计算效能的增长就会逐步降低的传统天险。
不过申威架构在太湖之中也不是完全没有后顾之忧。目前太湖之光使用的光纤互联威廉希尔官方网站 还是来自美国,而且是属于上一代的威廉希尔官方网站 ,虽然能在中国超算中发扬光大,但也代表这方面的威廉希尔官方网站 还是受制于人。
MIPS 与 Arm 助力日本主打最高能效比的自有架构
从 2017 年底的 Top 500 的排名当中,我们可以看到日本的超算架构虽然性能不是最优,但是在能耗方面,前 10 大能耗比最高的超算平台中,日本就占了 7 个,而今年 Top 500 性能排第 359 名的 Shoubu System B,在能耗排名中也高达第 1 名,相较之下,太湖之光虽然性能第 2,但能耗方面仅拿到第 23 名,换算每瓦虽然也算是很靠前的 6GFlops,但日本 Shoubu System B 则是达到每瓦 18.4GFlops 的惊人程度。
然而到 2018 上半年的排名,日本仍维持混用英特尔、NVIDIA 以及自有 PEZY 计算架构的混合计算型态,虽然最佳排名是 AI Bridging Cloud Infrastructure (ABCI) 的第 5 名,性能仍然离榜首有段距离,但多款超算的能效表现仍成功在 Green 500 排名中的前 10 名拿下 6 个席次。
与太湖之光不同的是,日本的超算架构并没有坚持自有路线,由 PEZY Computing 所打造的芯片架构主要还是作为辅助计算之用。最新的 SC2 整合了 2,048 个内核以及每个内核 8 路 SMT 支持,总共 16,384 个线程,是其前身的两倍。PEZY-SC2 是 2017 年底帮助日本多款超算打进顶级 Green500 超算能效排名的最大背后功臣,通过 PEZY-SC2 与英特尔与 NVIDIA 芯片的混搭使用,达到更高层次的能效表现。

图|以个别芯片为单位来比较,二代 PEZY 核心在互联与功耗控制能力方面仍略胜太湖之光的申威架构一筹
日本自有的 PEZY 核心包含了 6 个 P-Class P6600 MIPS(MIPS64R6) 处理器,并拥有 128 个称为 city 的辅助计算单元。相较之下,旧版 PEZY-SC 仅依靠 2 个轻量级的 ARM926 内核,成为性能的最大瓶颈。SC2 拥有 40 MIB 共享最后缓存,不仅可以在所有处理核心区块共享,还可以通过 MIPS 内核共享。为了进一步提高性能,MIPS 内核和 PEZY 内核现在共享相同的地址空间,从而减少数据传输开销。值得注意的是,通过使用功能强大的 MIPS 内核以及异构计算核心,PEZY Computing 在与其他计算架构搭配之后,在成本与能耗方面达到世界一流水平。
虽然初代 PEZY 核心因为 Arm 架构的落后而表现不佳,但日本也没有放弃 Arm 架构超算潜力的挖掘。
由富士通所推出,曾帮助日本夺得 Top 500 超算第一名的 Kyo 核心,就从 SPARC 转向Arm 架构。前不久富士通宣佈推出自主研发的 ARMv8 SVE(可伸缩矢量扩展) 的新款 Kyo 超算芯片,使用了512bit 浮点运算单元,每个节点使用 48 核+2 辅助核,IO 及计算节点则是 48 核+4 辅助核结构。而其效能评估是目前仍佔据超算 Top 500 第 10 名的 Kyo超算的 100 倍,而功耗只增加了 3 倍。
通过新版的 Kyo 的推出,富士通可望扭转近年日本超算核心在性能落后中美的状况,不仅理论性能超越中国太湖之光 10 倍以上,也能压倒美国 Summit 超算的算力表现。
图|由富士通研发的新一代 Kyo 超算平台誓言要让日本重回 Top 500 超算榜首
IDM Power 架构协同 NVIDIA 的纯美国芯重回 Top 500 榜首
带领美国重回超算 Top 500 榜首的Summit 超算中,包括了 4,608 个服务主机,搭载了超过 9,000 个 IBM 的 22 核心 Power9 处理器和超过 27,000 个 NVIDIA Tesla V100 GPU。采用的 IBM Power 9 架构,可以说是完全针对 NVIDIA 的 GPU 架构优化而来,其采用的 NVLINK 2.0 规格可带来高达 300GB/s 的频宽表现,很大程度上解决了资料传输过程的瓶颈,且因为 NVLIN 支援了快取一致性设计,也同时能够有效提升 GPU 的计算性能。
然而Power 架构的优势还不止于此,根据官方资料,IBM Power 9 的最大 I/O 频宽是 Intel x86 处理器的 9.5 倍,可支援存储器容量是 2.6 倍,高效能核心数量为 x86 的 2 倍,存储器频宽则是 x86 的 1.8 倍。更重要的是,通过 NVLINK 2.0,CPU 与 GPU 之间的互连频宽达到 X86 服务器目前使用的 PCIe 3.0 的 9 倍,大大舒缓了 GPU 等待资料传输所造成的计算能力浪费。
图|通过与 NVIDIA 的紧密合作,IBM 的 Power 架构在超算领域成功重夺众人目光
Power 9 也不是指标对了 NVIDIA 的计算架构作优化,事实上,它针对的是所有平台,Summit 中使用的 Power9 AC922 服务器采用的是 OpenCAPI 威廉希尔官方网站 。OpnCAPI 是 IBM 与 AMD、Google、Mellanox、Micron、Xilinx 等行业巨头联合发布一种全新的“OpenCAPI”(开放式一致性加速器界面) 标准,由此推动一致性高性能总线界面,满足高性能异构计算的需求。
不过基于 Power 架构+NVIDIA 美国芯组合的 Summit 超算还只是刚开始,美国目前已经决定要提高下一期先进计算领域的预算达 39%,期望能通过资本投入的增加,继续维持其在超算地位的领先。
潜力架构:英特尔的 Nervana 平台
虽然在此次 Top 500 名单中没有太多表现,但英特尔的 Nervana 在计算上的潜力仍不容忽视。
目前英特尔在超算领域其实面对的挑战越来越多,不只是 IBM 的 Power 架构,中国的申威,甚至连行将就木的 MIPS 也都把英特尔的架构,而过去总被认为只能在移动计算领域的 Arm,如今也成为 Kyo 的架构核心,其能效表现更把目前的英特尔远远抛在脑后。
如果继续维持现有的 CPU 计算架构,那么英特尔早晚会被超算架构所淘汰,而英特尔自然也不能够坐以待毙。前几年收购 Altera 与 Nervana 也将迎来开花结果。
英特尔其实钻研专用加速计算架构已经有相当久的历史,其成果包含 Xeno Phi 系列,该架构采用的是庞大数量的小核心所组合起来的单一芯片架构,其实与申威、PEZY 的作法相当类似,但是成本高,而能效也没有特别出色,导致使用率一直无法有效提高,Xeon Phi 最新架构 Lake Crest 虽然性能较就款已有成长,但相较起对手的成长幅度,已经有明显落后的趋势,因此英特尔今年改端出基于与 Altera FGPA 架构作异质整合,代号为 Spring Crest 的新一代 Nervana 神经网络处理器,根据英特尔给的数据,该神经网络架构的性能已经是 Lake Crest 架构 Xeon Phi 的 3 倍以上。
过去 Xeon Phi 在 Top 500 超算中的应用比例远低于 NVIDIA,主要还是性能价格比较弱,及针对目前已经成为主流的 AI 加速应用的生态完整度还是有落差,英特尔期望能通过结合 Nervana、Altera 以及既有优势 CPU 威廉希尔官方网站 的 Spring Crest 架构,确保其在服务器领域的优势地位能够维持下去。
其他挑战者
当然,目前还有更多计算架构仍在发展中,比如说量子计算、光子计算,甚至是光量子计算,这种性能超越传统计算从百倍到百万倍的新架构预计也会对未来的超算架构产生一定的影响。
尤其是在能耗方面,传统半导体架构带来的热和运作能耗是难以解决的问题,这也导致超算的持续运作维持成本可能要高于建构成本,若运作成本持续攀高,恐怕会限制未来超算的发展空间。而这也是超算排名有了依照绝对性能排名的 Top 500,还要另外有以能耗比例为比较基准的 Green 500 的原因。
超算竞争的背后是个别国家基础科学发展的擘划,但也成为推动人类成长的动力
为何发展超算如此重要?超算的性能可以衡量一个国家的威廉希尔官方网站 实力,但这是个狭义的衡量标准,因为速度只是计算性能的要素之一。另一个重要元素在于软件,软件可以赋予计算机生命,通过软件的发展,我们就可以把算力分散到各种产业,协助产业的发展。
图|超算代表的是一个国家对自己威廉希尔官方网站 根基的投入程度,和国力的展现
前面也提到,目前从基础科学、材料、生医、金融、航天、军事,甚至未来的宇宙理论与太空探勘发展,都需要庞大算力的支持,过去土法炼钢,或分头进击的方式已经没有效率可言,而通过国家力量的投入,超算已经形成未来推动人类视野发展的最大武器。
目前超算的算力竞争很多还是出自于期望借相关发展来提高对核心威廉希尔官方网站 的掌握与对基础科研的支持,从而帮助各自产业的发展,虽然出自私心,但其实也在相当程度上共同推动了人类社会的发展。
-
半导体产业
+关注
关注
6文章
509浏览量
34334 -
超级计算机
+关注
关注
2文章
462浏览量
41945 -
超算
+关注
关注
1文章
115浏览量
9071
原文标题:最新“全球超算500强”今宣布:美国时隔五年重夺榜首,中国位列第二!
文章出处:【微信号:Anxin-360ic,微信公众号:芯师爷】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
TOP500第二台E级超算出现,AMD要在HPC上逆袭英特尔?

NVIDIA加速全球大多数超级计算机推动科技进步

丹麦推出首台AI超级计算机Gefion
NVIDIA助力丹麦发布首台AI超级计算机
【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】--全书概览
名单公布!【书籍评测活动NO.43】 算力芯片 | 高性能 CPU/GPU/NPU 微架构分析
借助NVIDIA超级计算机加速量子计算发展
马斯克计划打造超级计算机推动AI发展
Green500全球最节能超级计算机榜单:采用NVIDIA威廉希尔官方网站 包揽前三
NVIDIA和Recursion利用AI超级计算机加快新药研发





 工商网监
工商网监
评论