 一种通用的图像分类方法
一种通用的图像分类方法
这篇文章介绍了作者在Kaggle植物幼苗分类比赛使用的方法,该方法连续几个月排名第一,最终排名第五。该方法非常通用,也可以用于其他图像识别任务。
任务概述
你能区分杂草和作物幼苗吗?
有效做到这一点的能力意味着更高的作物产量和更好的环境管理。
奥尔胡斯大学信号处理小组与南丹麦大学合作发布了一个数据集,其中包含大约960种不同生长阶段的植物的图像,这些植物属于12个物种。
样本植物之一:繁缕样本[3]
该数据集包含有标注的RGB图像,物理分辨率约为每毫米10个像素。
为了规范对数据集获得的分类结果的评价,研究者提出了基于F1分数的基准。
下面的图是数据集中所有12个类的样本:
图像分类任务可以分为5个步骤:
步骤1
机器学习中的第一个也是最重要的任务是在继续使用任何算法之前对数据集进行分析。这对于理解数据集的复杂性非常重要,最终将有助于设计算法。
图像和类的分布如下:

如前所述,共有12个类,4750张图像。但是,从上面的图中可以看出,数据的分布不均匀,类的分布从最大有654张图像到最小只有221张图像。这表明数据不均衡,数据需要均衡才能获得最佳结果。我们将在第3个步骤讲这一点。
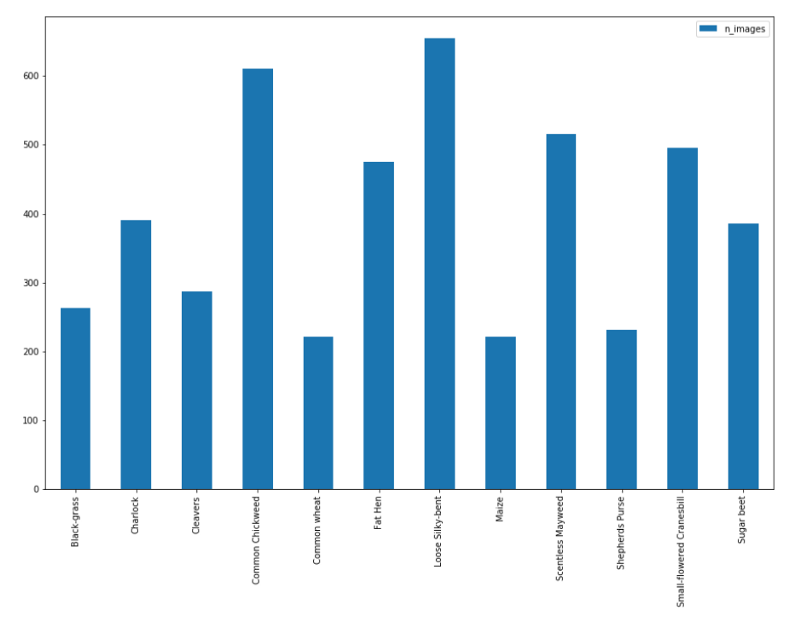
每个类的图像分布
为了更好地理解数据,对图像进行可视化非常重要。因此,每个类中会拿出一些示例图像,以查看图像之间的差异。

从上面的图中得不到什么理解,因为所有的图像看起来都差不多。因此,我决定使用被称为t分布随机邻域嵌入(t-SNE)的可视化威廉希尔官方网站 来查看图像的分布。
t-SNE是降维的一种威廉希尔官方网站 ,特别适用于高维数据集的可视化。该威廉希尔官方网站 可以通过Barnes-Hut近似实现,使其可以应用于大型真实世界的数据集[14]。
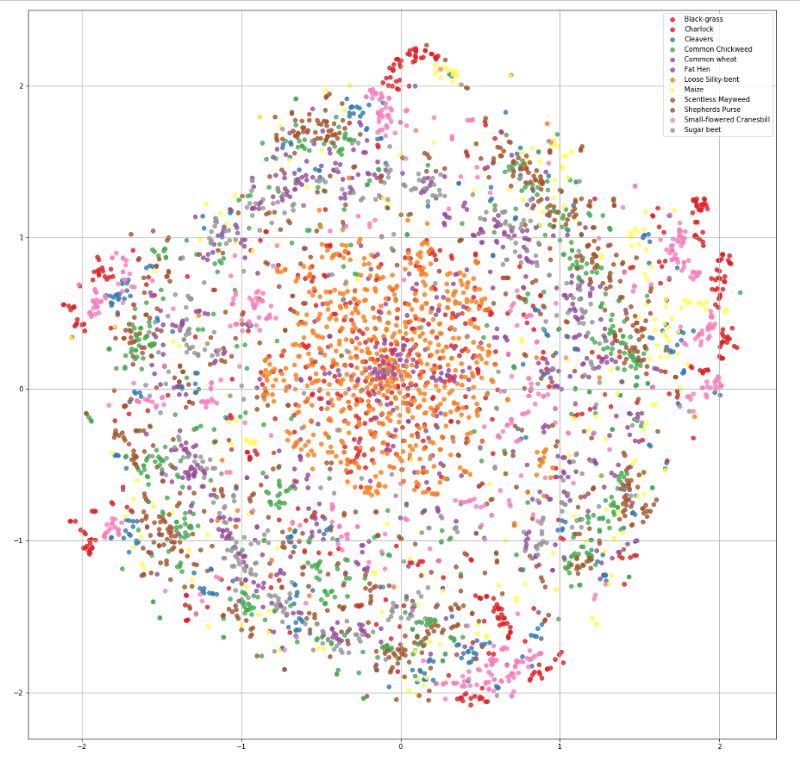
数据集的t-SNE可视化
现在,仔细观察后,我们几乎看不出不同类之间的差异。数据的差异是只对人类来说很难区分,还是不管对人类还是对机器学习模型来说都很难区分,了解这一点很重要。因此,我们将做一个基本的benchmark。
训练集和验证集
在开始使用模型基准之前,我们需要将数据划分为训练数据集和验证数据集。在模型在原始测试集上进行测试之前,验证集扮演测试数据集的角色。因此,基本上一个模型在训练数据集上进行训练,在验证集上进行测试,然后在验证集上对模型进行改进。当我们对验证集的结果满意,我们就可以将模型应用到真实测试数据集上。这样,我们可以在验证集上看到模型是过拟合还是欠拟合,从而帮助我们更好地拟合模型。
对有4750张图像的这个数据集,我们将80%的图像作为训练数据集,20%作为验证集。
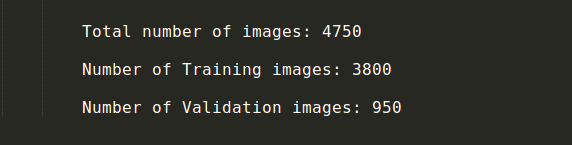
分开训练数据和验证数据
步骤2
有了训练集和验证集后,我们开始对数据集进行基准测试。这是一个分类问题,在给出一个测试数据时,我们需要将它分到12个类中的一个。我们将使用卷积神经网络(CNN)来完成这个任务。
创建CNN模型有几种方法,但对于第一个基准,我们将使用Keras深度学习库。我们将在Keras中使用现有的预训练好的模型,我们将对其进行微调以完成我们的任务。
从头开始训练CNN是低效的。因此,我们使用一个在有1000个类的ImageNet上预训练的CNN模型的权重,通过冻结某些层,解冻其中一些层,并在其上进行训练,对其进行微调。这是因为顶层学习简单的基本特征,我们不需要训练那些层,它们可以直接应用到我们的任务中。需要注意的是,我们需要检查我们的数据集是否与ImageNet相似,以及我们的数据集有多大。这两个特性将决定我们如何进行微调。
在这个例子中,数据集很小,但有点类似于ImageNet。因此,我们可以首先直接使用ImageNet的权重,只需添加一个包括12个类的最终输出层,以查看第一个基准。然后我们将解冻一些底部的层,并且只训练这些层。
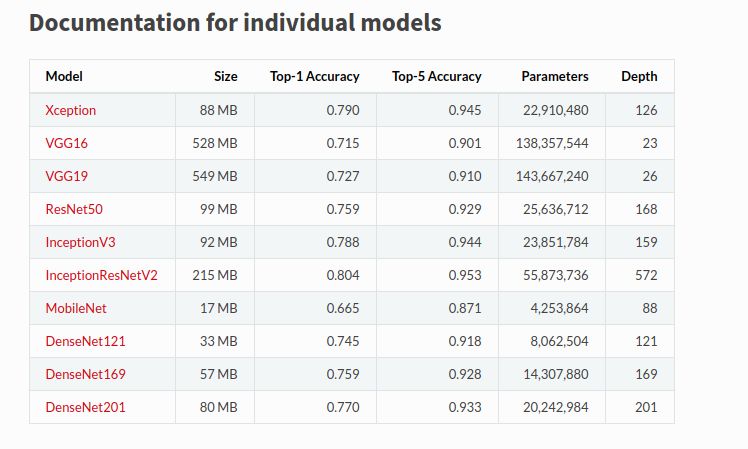
我们将使用Keras作为初始基准,因为Keras提供了许多预训练模型。我们将使用ResNet50和InceptionResNetV2来完成我们的任务。使用一个简单的模型和一个非常高的终端模型对数据集进行基准测试是很重要的,可以了解我们是否在给定模型上过拟合/欠拟合数据集。

此外,我们可以在ImageNet数据集上检查这些模型的性能,并检查每个模型的参数数量,以选择我们的基准模型。
对于第一个基准测试,我删除了最后一个输出层,只添加了一个带有12个类的最终输出层。此外,还打印了模型摘要和参数的数量,下面是最后几层的截图。

添加一个dense层以得到第一个基准
模型运行了10个epochs,6个epochs后结果达到饱和。训练精度达到88%,验证精度达到87%。

为了进一步提高性能,我们从底部解冻了一些层,并以指数衰减的学习率训练了更多的层。这个过程将精度提高了2%。

从底层开始训练几层后的结果
此外,该过程中还使用了以下超参数:

步骤3
准备好基本的基准后,就可以改进它了。我们可以从增加更多数据开始,增加数据集中图像的数量。
没有数据,就没有机器学习!
但首先这个数据集不均衡,需要进行均衡,以便每批都使用偶数个图像作为模型的训练数据。
现实生活中的数据集从来都不是均衡的,模型在少数类上的性能也不是很好。因此,将少数类的样本错误地归类到正常类样本的成本通常要比正常类错误的成本高得多。
我们可以用两种方法来均衡数据:
1.ADASYN采样方法:
ADASYN为样本较少的类生成合成数据,其生成的数据与更容易学习的样本相比,更难学习。
ADASYN的基本思想是根据学习难度的不同,对不同的少数类的样本使用加权分布。其中,更难学习的少数类的样本比那些更容易学习的少数类的样本要产生更多的合成数据。因此,ADASYN方法通过以下两种方式改善了数据分布的学习:(1)减少由于类别不平衡带来的偏差;(2)自适应地将分类决策边界转移到困难的例子[5]。
2.合成少数类过采样威廉希尔官方网站 (SMOTE):
SMOTE涉及对少数类进行过采样(over sampling),并对大多数类进行欠采样(under sampling)以获得最佳结果。
对少数(异常)类进行过采样和对大多数(正常)类进行欠采样的方法的组合,相比仅仅对大多数类进行欠采样可以得到更好的分类器性能(在ROC空间中)。
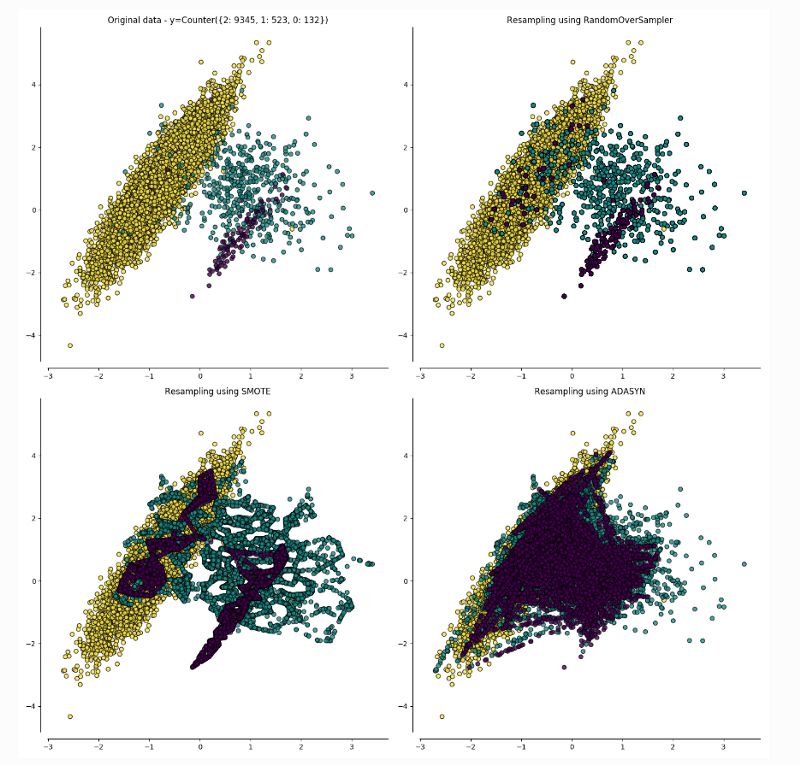
对于这个用例,SMOTE的结果被证明更好,因此SMOTE比ADASYN更受欢迎。一旦数据集达到平衡,我们就可以继续进行数据增强(data augmentation)。
有几种方法可以实行数据增强。比较重要的一些是:
缩放
裁剪
翻转
旋转
平移
添加噪音
改变照明条件
先进的威廉希尔官方网站 ,如GAN
已经有一些很好的博客解释了这些威廉希尔官方网站 [8][9],所以本文不再详细解释。在这个任务中,除GAN外,以上所有数据增强威廉希尔官方网站 都使用到。
步骤4
现在,为了进一步提高成绩,我们使用了学习率,包括周期性学习率(cyclical learning rate)和热重启学习率(learning rate with warm restarts)。但在此之前,我们需要找到模型的最佳学习率。这是通过绘制学习率和损失函数之间的图,来检查损失从哪里开始减少。
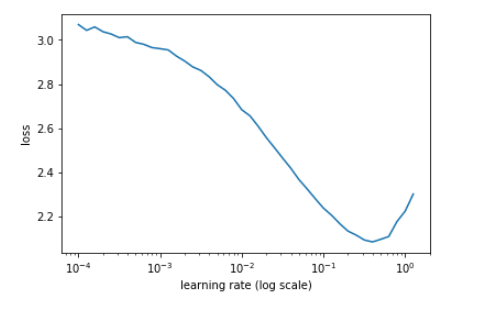
学习率与损失的关系图
在我们的例子中,1e-1看起来是一个完美的学习率。但是,随着我们越来越接近全局最小值,我们希望采取更短的步骤。一种方法是学习率退火(learning rate annealing),但是我采用了热重启学习率,启发自SGDR: Stochastic Gradient Descent with Warm Restarts[10]这篇论文。同时将优化器从Adam改为SGD,实现SGDR。
现在,可以使用上述威廉希尔官方网站 来训练多个架构,然后将结果合并在一起。这称为模型融合(Model Ensemble),是流行的威廉希尔官方网站 之一,但是计算量非常大。
因此,我决定使用一种称为snapshot ensembling[12]的威廉希尔官方网站 ,通过训练单个神经网络,使其沿着优化路径收敛到多个局部最小值,并保存模型参数,从而实现集成的目的。
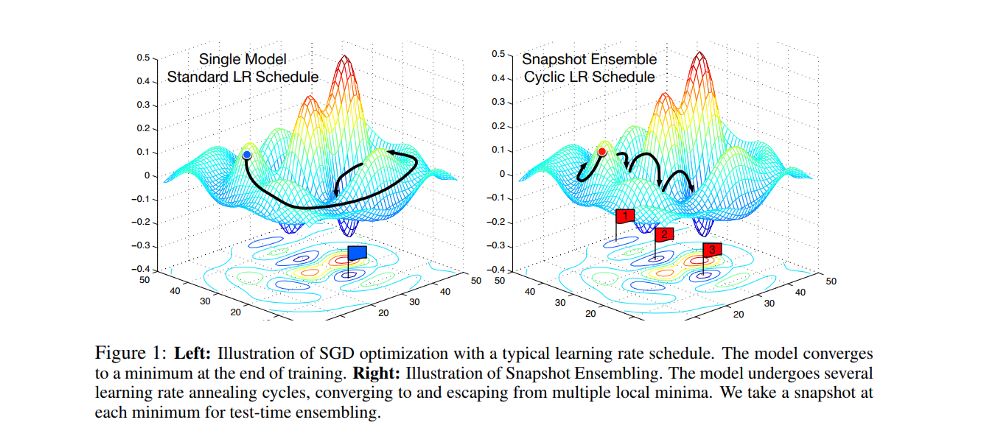
一旦确定了学习率的方法,就可以考虑图像的大小。我用64 * 64大小的图像(微调了ImageNet)训练模型,解冻了一些层,应用 cyclic learning rate和snapshot ensembling,采用模型的权重,改变图片尺寸为299 * 299,再以64*64图像的权重进行微调,执行snapshot ensembling和热重启学习率。
如果我们改变图像大小,需要再次运行学习率vs损失函数以获得最佳学习率。
步骤5
最后一步是将结果可视化,以检查哪些类具有最佳性能,哪些表现最差,并且可以采取必要的步骤来改进结果。
理解结果的一个很好的方法是构造一个混淆矩阵(confusion matrix)。
在机器学习领域,特别是统计分类问题中,混淆矩阵(也称为误差矩阵)是一种特定的表格布局,能够可视化算法的性能,通常是监督学习(在无监督学习中通常称为匹配矩阵)。矩阵的每一行表示预测类中的实例,而每列表示实际类中的实例(反之亦然)。这个名字源于这样一个事实:它可以很容易地看出系统是否混淆了两个类别。
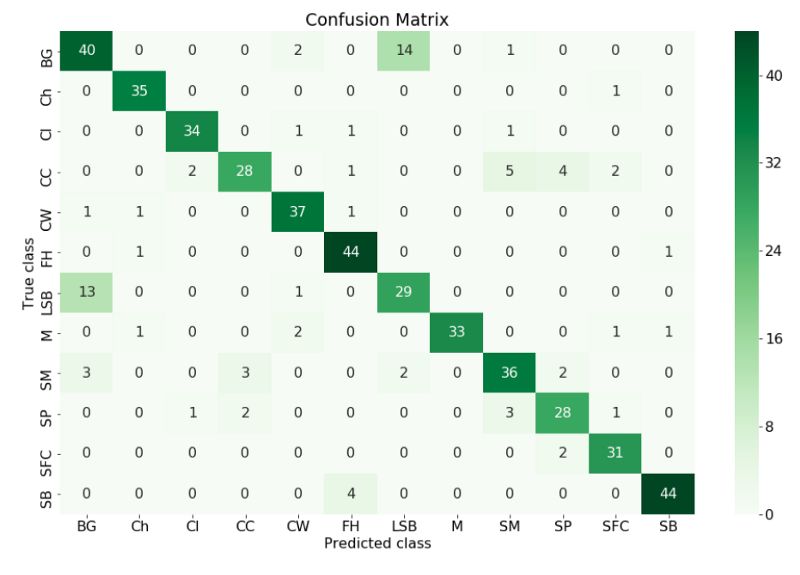
真实类vs在混淆矩阵中预测类
我们可以从混乱矩阵中看出模型预测标签与真实标签不同的所有类,我们可以采取措施来改进它。我们可以做更多的数据增强来尝试让模型学习这个类。
最后,将验证集合并到训练数据中,利用所获得的超参数对模型进行最后一次训练,并在最终提交之前对测试数据集进行评估。
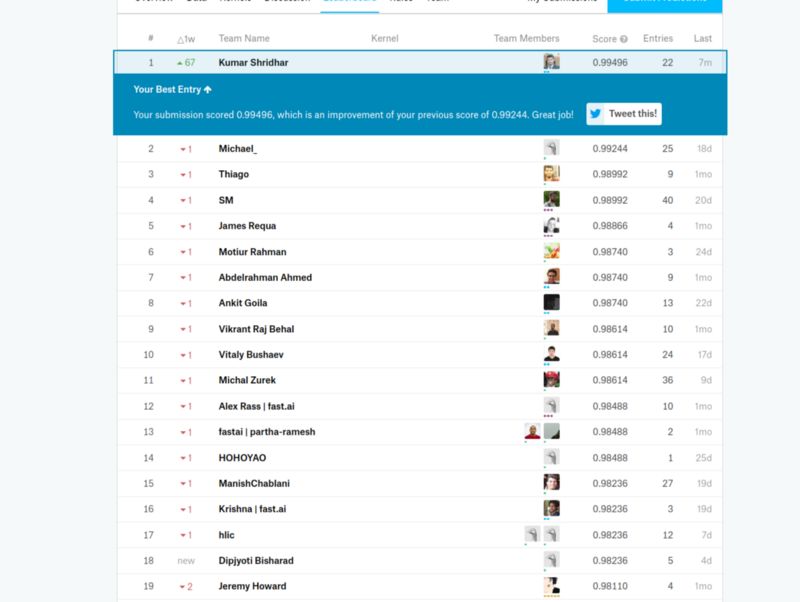
最终提交后排名第一
注意:在训练中使用的增强需要出现在测试数据集中,以获得最佳结果。
-
神经网络
+关注
关注
42文章
4771浏览量
100721 -
图像分类
+关注
关注
0文章
90浏览量
11915 -
数据集
+关注
关注
4文章
1208浏览量
24691
原文标题:从0上手Kaggle图像分类挑战:冠军解决方案详解
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一种新的图像定位和分类系统实现方案
基于Brushlet和RBF网络的SAR图像分类
一种基于Web挖掘的音乐流派分类方法
一种改进的小波变换图像压缩方法
一种具有反馈机制的名片信息分类方法
基于数据挖掘的医学图像分类方法
一种旋正图像使用中心点进行指纹分类的方法

一种坚固特征级融合和决策级融合的分类方法

一种全新的遥感图像描述生成方法






 工商网监
工商网监
评论