 对于模型和数据的可视化及可解释性的研究方法进行回顾
对于模型和数据的可视化及可解释性的研究方法进行回顾
一年一度的CVPR在盐湖城开幕啦!最新的消息:
今年的最佳论文,授予了来自斯坦福大学和 UC Berkeley 的 Amir R. Zamir等人的“Taskonomy: Disentangling Task Transfer Learning”。
最佳学生论文则被来自CMU的Hanbyul Joo等人凭借“Total Capture: A 3D Deformation Model for Tracking Faces, Hands, and Bodies”摘得。
同时,也要恭喜昨天刚被我“门”蹭热度的Kaiming大神荣获PAMI 年轻学者奖.
除了明星奖项的揭晓,会议第一天最吸引人的除了workshop外就是一个个专题tutorial了:
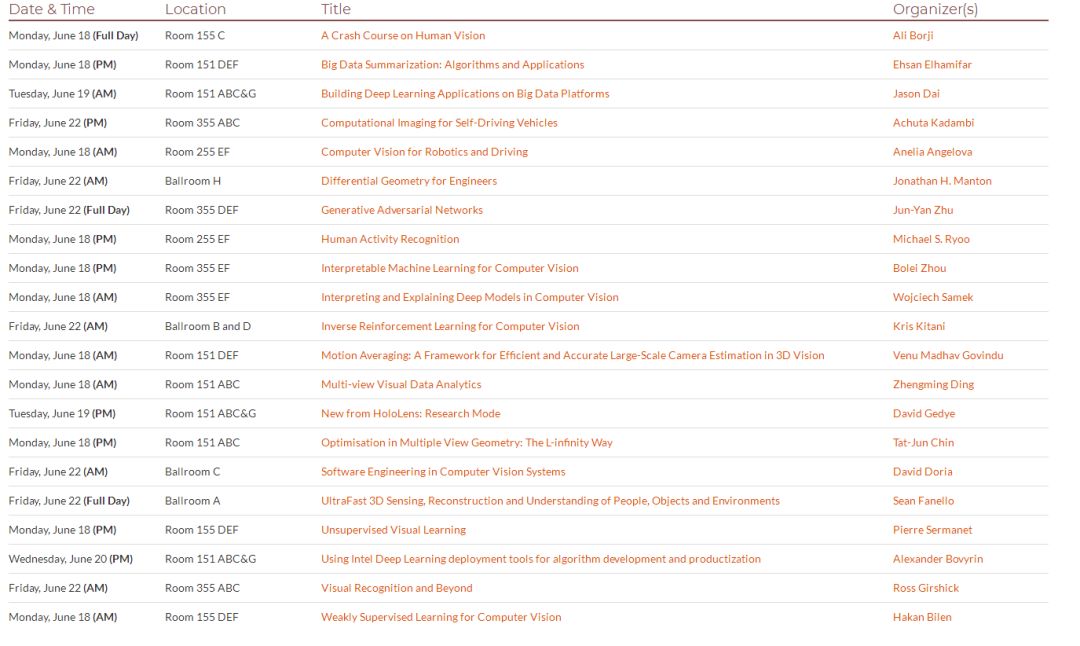
周一的会议共开设了11个专题tutorial,我们下面就为大家介绍其中一些有趣的tutorial。
一些已经放出来的tutorials slides下载见附件:
https://pan.baidu.com/s/1yv8orYTbsYLNnlTlCVc_Pw
机器学习的可解释性对于研究人员来说有着十分重要的作用,它除了可以帮助我们理解模型运行的机理外,还能帮助我们有的放矢地提高模型的表现甚至启发我们开发新的模型。Tutorial:Interpretable Machine Learning for Computer Vision就为我们带来了这方面的内容。

这个tutorial着眼于复杂的机器学习模型在计算机视觉方面的应用。计算机视觉在物体识别、标注和视觉问答等方面有着广泛的应用,但很多时候深度学习模型和神经网络的运作机理对我们来说还像黑箱一样无法清晰透彻的了解。随着近年来模型的深度加深,我们理解模型及其预测结果的过程变得日益困难。
这一tutorial将通过模型的可解释性广泛回顾计算机视觉的各个研究领域,除了介绍可解释性的基本知识及其重要性外,还将就目前对于模型和数据的可视化及可解释性的研究方法进行回顾。
Tutorial包含了四个演讲,分别是:
来自谷歌大脑的Been Kim带来了“机器学习中可解释的介绍”;
来自FAIR的Laurens van der Maaten作的“利用t分布随机邻近嵌入方法用于视觉模型理解的准则”;
来自MIT的周博磊带来的:“重新审视深度网络中单一单位(Single Units )的重要性”;
最后是来自牛津大学的Andrea Vedaldi带来的“利用自然原像、有意义扰动和矢量嵌入来理解深度网络”。
https://interpretablevision.github.io/
除了这个tutorial之外还有一个类似的tutorial:Interpreting and Explaining Deep Models in Computer Vision。

这一tutorial就视觉领域的可解释性进行了概览,提供了如何在实践中使用这些威廉希尔官方网站 的例子,并对不同的威廉希尔官方网站 进行了分类。其主要内容如下:
可解释性的定义;
理解深度表示的威廉希尔官方网站 和解释DNN中个体预测;
定量评测可解释性的方法;
实践中应用可解释性;
利用可解释模型在复杂系统中得到新的见解。
另一个有趣的tutorial是:Computer Vision for Robotics and Driving,这一tutorial主要由来自谷歌大脑的Anelia Angelova和来自多伦多大学的Sanja Fidler进行讲解,主要讲解了计算机视觉深度学习在机器人(以及自动驾驶)方面的发展、应用和新的研究机会。

机器人视觉的特殊性主要在于数据和任务上,首先输入数据是多模态(多传感器)数据,而输出则需要三维数据(很多情况下是稀疏的)。在实际情况中,需要在实时性、启发式理解、环境交互方面有着良好的表现。
这一领域中新的研究机会主要在以下几个方面:
多传感器、多输入、数据相关性的研究;
结构化特征的使用和学习;
自监督学习;
联合感知、规划和行为;
主动感知威廉希尔官方网站 ;
同时就机器人在三维空间中的学习问题和自动驾驶中的深度学习问题进行了深入的报告。希望研究机器人或者感兴趣的朋友们可以从中获得需要的信息。
除此之外,对于发展势头越来越旺的非监督学习谷歌大脑和谷歌Research联合推出了一个tutorial:Unsupervised Visual Learning。

这一tutorial从非监督学习的各种优点谈起,从新的特征表示到擅长处理的特定问题,从加速学习过程到减少样本使用量等各个方面进行了展开。随后利用一个报告详细阐述了如何从视频(时序相关)和图像(空间相关)数据中学习特征表示,并在另一个报告中延伸了如何从真实世界的3D数据中进行学习,包括特征、深度的学习以及特征点的匹配问题。最后阐述了自监督学习在机器人中的应用,并用了三个例子进行了阐述:
从深度信息中进行在线自监督学习;
用于抓取的自监督学习过程;
模仿学习;
几何和三维重建是计算机视觉的重要部分,今年也有多个相关的tutorial进行了深入地探讨。
首先来自印度理学院的Venu Madhav Govindu介绍了基于Motion Averaging的方法进行大规模三维重建的方法,其tutorial系统的介绍了基于李群的方法,并归纳了不同的motion averaging方法,同时还对算法进行了最佳实践。这一tutorial旨在帮助研究人员们在新环境中使用这一方法用于大规模SFM以及三维稠密建模。
另一个tutorial则从优化方面介绍了一种基于L无穷的最小化方法来解决一系列L2最小化所面临的问题。这一tutorial讲解了基于L-infinity的几何视觉优化方法,通过数学和算法概念以及应用来深入理解如何使用这种新的优化概念。
在感知层面,多视角视觉数据分析tutorial主要着重于常见的多视角视觉数据的分析及其主要的应用,包括多视角聚类、分类和零样本学习,并讨论了目前和未来将要面对的挑战。

另一个相关的tutorial着重于超快的3D感知、重建和理解,将在22号举办。对于3D环境的捕捉、重建了理解使得人们需要建立高质量的传感器和高效的算法。研究人员们建立了一套高帧率的深度传感器系统,超快的帧率(~1000fps)使得帧间移动大幅减少,同时使得多传感器的融合变得简单。基于此研发出了高效的重建、跟踪和理解算法。Tutorial介绍了从零开发这一传感器的来龙去脉。

对于视觉本质的理解Tutorial:A Crash Course on Human Vision
从low,Mid,High level提供了不同层次的理解。它讲解了人类的视觉系统,并提供了认识了理解视觉系统的方法,以助于前沿计算机视觉的研究。Tutorial分为两个部分,首先从Low-level开始,讲述了光的物理本质、视网膜的生理构成,以及颜色、感受野、V1过程和运动感知;第二部分从感知深度和大小、视觉注意力和以及以及识别等方面及进行了阐述。
最后一个关于人类行为识别的Tutorial:Human Activity Recognition。这一领域的研究热点主要集中在一下几个方面:
行为可靠的时空定位;
行为的端到端模型;
群体行为识别;
行为预测;
大规模数据集和卷积模型的的建立;
-
机器人
+关注
关注
211文章
28398浏览量
206988 -
深度学习
+关注
关注
73文章
5502浏览量
121124
原文标题:知识点 | CVPR 2018 最佳论文揭晓,Tutorials首日速览(附下载)
文章出处:【微信号:thejiangmen,微信公众号:将门创投】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
机器学习模型可解释性的结果分析
什么是“可解释的”? 可解释性AI不能解释什么
【大语言模型:原理与工程实践】核心威廉希尔官方网站 综述
【大规模语言模型:从理论到实践】- 阅读体验
机器学习模型的“可解释性”的概念及其重要意义
Explainable AI旨在提高机器学习模型的可解释性
机器学习模型可解释性的介绍
图神经网络的解释性综述
《计算机研究与发展》—机器学习的可解释性

使用RAPIDS加速实现SHAP的模型可解释性
文献综述:确保人工智能可解释性和可信度的来源记录





 工商网监
工商网监
评论