 搜狗的AI之路与挑战
搜狗的AI之路与挑战
翻译是很重要的一件事情,中国有13亿人,是最大的汉语群体。我们非常有意愿和英语世界以及其他的语言做更多的交流。
5月19日,在2018全球人工智能威廉希尔官方网站 大会上,搜狗首席执行官、清华大学天工智能计算研究院联席院长王小川发表了题为“搜狗的AI之路与挑战”的演讲。
下为王小川在本次大会中的演讲实录,经整理后发布。
王小川:刚才朱老师说接地气,我觉得在这个会议上我们就没地气。为了这个地气是有损失的,所以大家在99年、2000年开始进入到互联网,当时有机会可以继续在清华大学读博士,现在有机会来弥补这样的不足。
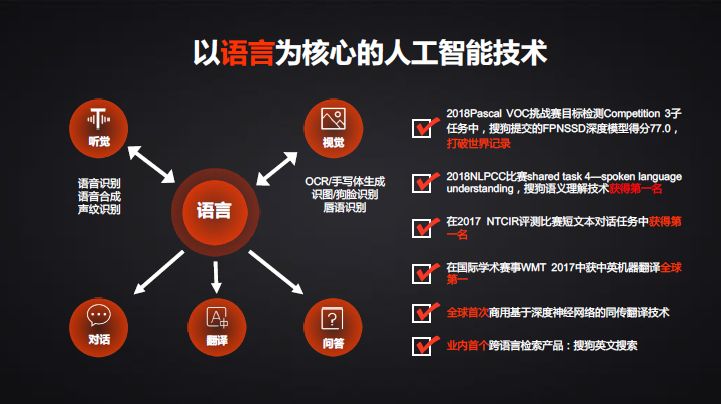
今天的报告给大家介绍的是“搜狗的AI之路与挑战”。和今天的主题非常贴切,不仅是人工智能,核心是围绕我们的语言展开。
提到搜狗公司,大家更多知道的是搜狗输入法。
从用户规模来看,我们在中国互联网排在第四位,仅次于腾讯、百度和阿里巴巴。我们的搜索引擎在中国也是第二位,有超过18%的市场份额,而且每一年还会增加2%-3%。在全球应该是第三大,除了Google、百度,我们的用户规模和搜索量是第三。更自豪的是搜狗输入法是当之无愧的第一名。

这两个产品都有一个特点,输入法是帮助你表达信息,把你的想法变成文字。而搜索引擎是帮你获得信息,把你的文字变成更多你需要的知识。这两个产品的核心点是在语言上,我们不排斥有语音或者其他的因素,但最终的核心是在语言。因此围绕语言我们会展开很多的工作,包括语音识别、语音合成、声纹识别、个性化语音合成等等。也有视觉方面的工作,包括OCR,包括我们跟清华合作的手写体合成功能,自己写几个字,试图把你写的字变成机器模仿的体系,有识图功能,尤其在狗脸识别做的特别好,拍一张狗就可以告诉你是什么样的品种。搜狗嘛,在威廉希尔官方网站 里面可以玩出花来。甚至是唇语识别,不用语音,只看你的嘴唇运动就可以知道你在说什么。这是在语音和图像上和语言相关的工作。另外更多的是在做对话、翻译、问答。

也许这些加起来还不能构成一个完整的交互,但我们觉得这个方向我们展开了大量的研究,更多的是这个研究工作和我们的产品有高度的结合。
今天更多的想放在语言、翻译、对话和问答上,简单讲一下在语音图像方面干的有意思的活,唇语识别,我们有大量的主持人或者其他数据训练,现在在通用语义里,能到60%的唇语识别准确度。在专业领域里,比如说读唐诗或者安防、电梯工作间,识别率可以超过90%。
把声音过滤掉,核心就是用嘴唇的图像的视觉能力来做。我们知道和语音识别有类似的基础,一个是波形,一个是图像,本身而言是相通的,只是看一下我们在能力上的思考。
今天的主题定位在语言处理,认知领域里自然语言处理的工作。
翻译是很重要的一件事情,中国有13亿人,是最大的汉语群体。我们非常有意愿和英语世界以及其他的语言做更多的交流,尤其刚才提到,我们是帮助大家表达和获取信息。以前表达和获取信息是和中文表达,未来是和世界做整个的连接。
我们在前面发布了我们同声传译的系统,第一次发布是在乌镇世界互联网大会上。去年时我们做了升级,不仅用文字展示,开始把语音合成做了展示,去年用我个人的语音做了合成,我们甚至想尝试是否能做情感的迁移。也就是说我今天在这里演讲时,我有抑扬顿挫、重音、发怒、调侃的语气,不是简单的变成文字翻译成英文,而是能够把语音、语调、重音、热情一块儿翻译过去,这个领域就可以超越人。工作进展到目前还有一些挑战和困难,所以理想是希望做出一些工作,不止在文字里面。

这一块我们在行业里相对是成熟的,很自豪来讲,在现在能够使用的翻译和同声传译系统,不管是从威廉希尔官方网站 指标还是工程方面,我们走在世界最前面,甚至可以说是在第一名的位置。
同声传译这个系统只能在大会里用,如果有翻译人员,机器和翻译人员还是有距离。我们内部研发人员认为,在2020年时,可以在一些指标上和真人做平,一些地方更好,一些地方还有不足,有两年的目标。现在看起来还是很有挑战的事情,尤其是在延迟方面。目前大会是搜狗提供的同声传译系统,通常是中文已经一整句话识别清楚之后再翻译英文,而翻译人员有更多的经验,能够很快的做翻译。但他们有时候会丢句子,比如说翻译不了就丢掉,我们以前觉得那是一个错误。但我们和同声传译的专业老师沟通之后知道那是他们的技巧。所以机器和人的处理还是有很大的差别。
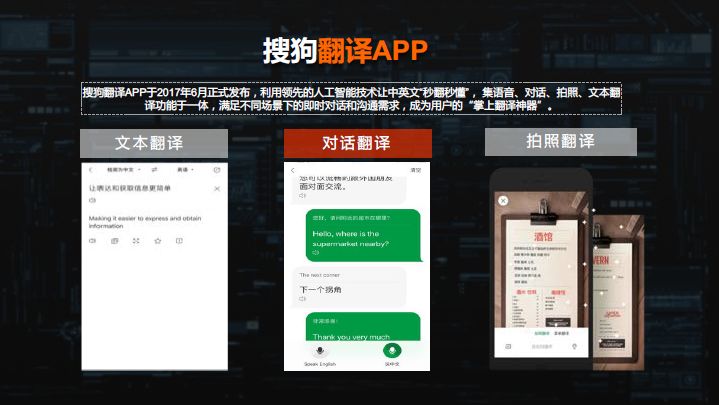
我们今年连续发布了两款和翻译相关的产品,一款是搜狗的旅行翻译宝,3月份上市的,售价在1498。第二款是五天前发布的第二款产品搜狗录音翻译笔,售价398块。这两个产品上市当天直接卖断货,有我们产能跟不上的问题,也可以看到大家的热情。产品区别是,翻译宝不需要联网,把整个深度学习的模型,不管是语音还是图像、翻译,都集成在这个设备中,你出国的时候没有网络,不用交费也可以工作。

录音翻译笔是手机的配件,更多的是有很强的收音能力,比如说你在教室里,老师在前面讲课,你坐在教室最后一排,中间可能相隔三四米,没有问题,可以把声音录下来,这是可以取代今天的录音笔。我内心当中,这是录音笔的颠覆。录音笔录的音,大家马上想到需要做内容的简写、存储的管理和检索,但传统录音笔是不智能的,我们做了很多这样的功能。上市之后,老师 自媒体 学生很多人开始关注这样的产品。
我们在硬件中希望通过这样的做法,更快的把一些威廉希尔官方网站 落地使用。

输入法之间结合翻译的能力,你用语音说时,说中文,可能上屏就是英文。也可以敲一段中文,点两个键就翻译成英文发出去。输入法不仅是变成中文沟通的方式,利用它可以很方便的和英文、日文、韩文等沟通。
搜狗的搜索也支持翻译的功能。现在可以实现用中文输入检索全球的英文信息,最后再让你用中文阅读。尤其在医疗、娱乐方面获得一个世界上最前沿的信息,已经可以做到。搜狗的使命是表达和获取,通过这样的方式连接到整个世界,我们对翻译这个系统非常认真。

当然有独立的APP,有文本对话翻译,尤其我们开始做拍照翻译。实景你拍一张菜单,自己可以变成中文的菜单。中文变英文也可以。我们在努力开发离线计算能力,使得你AR翻译,当你扫描到一个路牌时,实时变成中文,怎么样降低延迟和准确性。Google之前发布了一个翻译系统,速度很快,但准确率很低,我们在这方面也做了很多的投入。
所以,我们翻译的挑战:
第一,语音方面怎么做的更好,完成情感迁移。
第二,在搜索里有一个现象,把中文翻成英文检索完了之后再翻译成中文有可能出现翻译成中文的词和原始的词对不上,这就是稳定性的问题,也是搜索里独有需要解决的事情。

另外我们还会做问答的系统,我自己有一个断言:搜索的未来是问答。因为语音只是让你表达更多的方便,但中间一定要有一种知识推理或者对知识检索的能力,不是给你一个网页,而是给你提供一个答案。
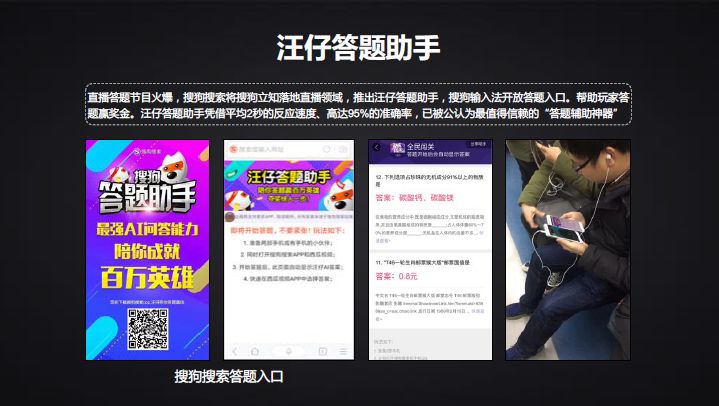
给大家看一个视频,去年一个问答机器人汪仔参加了《一战到底》的比赛。
我们这个系统能够把整个互联网当作它的数据库,IBM的系统是一个本地的数据,它可以解决的是一些垂直领域、封闭领域的问题,你要告诉它这个问题是明星,这个问题问的是运动员。而搜狗的系统是纯开放的,你可以问任何的问题,只要是跟事实类相关的就可以做回答。但节目里的水平是不断的提高,确实看到最后已经超越了顶尖的人类选手。《一站到底》中间也是选拔最优秀的问答选手参加比赛,到最后比赛我们已经做到了一开始让人三分开始启动。做这个系统的时候,不懂威廉希尔官方网站 的会觉得很简单,只是一个数据库检索。即便懂得也会担心后面是不是有作弊?你和这样的节目串通在一块儿。

在今年年初国内出现了一种很火热的互相答题模式《直播答题》,一个网站拍100万人民币,12道题,如果你都答对了,一个人答对了100万都给你,有100万个人答对了就给你1块钱,在今年年初成为一个现象级的活动。在这个活动当中,搜狗做了一个答题助手,从对方服务器直接把视频流引到我们的服务器,在视频流当中检索主持人的问题,然后去找到答案,并且把答案推送给我们自己的应用。所以如果用户拿两个手机,一个手机参加直播答题,一个手机打开搜狗的答题助手,它可以在出题后2-3秒的时间里把答案提供给用户。这个产品非常成功,答题水平比大多数人好很多,大概有90%的准确性。使得每天有100万人使用答题助手,甚至和一些网站产生了对抗,这个网站努力把题出的语句更加复杂,想让你的机器听不懂,我们的工程师更努力解码你的题目,最后反映到这个题目长到用户已经看不懂机器还可以读。我们公司有同学跟我说,这个事情是否足够正义?我觉得这本来就是一个游戏的活动,又不是高考。两三个人坐一块儿答题也可以,为什么不可以机器帮助?只可以人吗?我们要适应,未来凡是机器擅长的事情让机器做,这是今年答题助手更严肃论证了我们在问答领域里威廉希尔官方网站 的领先性和可用性。
学术界做了非常多的关于答题研究,通常原来的测试题是默认你问的问题就是问题,而且你问题就是有答案,并且这个答案在之前给到你的数据集里面。对于做搜索的公司做这件事情的时候,不仅仅是做阅读理解,因为里面有很多的问题是不确认的,所以我们的问答是搜索加上阅读理解的威廉希尔官方网站 。
这个上线之后会使得原来的准确度巨大下降,原来做到80%多,甚至90%。但如果对于开放性的搜索引擎,会瞬间掉到10%-20%。20多到头了,有更大的努力空间

事实类的问题只占3%,还有口语化、相关化的问题。并且问的问题很难判断,比如说“苍天饶过谁”,这听起来是一个问题,但对不起,其实它是一个电视剧。所以如果你没有做好知识的准备就会判断错误。“皮肤暗黄调理”,用户问的是皮肤暗黄怎么调理?问题的判断变得很困难,包括答案的判断和相关Passage的检索计算。可以看到各种各样的问题,这个问题和我们的测试题不一样,是用户真实问的问题,而且大家给的答案好像问不对题,但其实有我想要的。比如说“王者荣耀排位上分最好的时间段在哪?”最佳的答案完全不是考虑时间的问题,它说你一定要组团,有实力相当的队友。网络上的数据和我们理想当中的答案是两回事,怎么理解这样的问题?这是搜索当中的问答和我们阅读理解不一样的地方,和网上数据有很大的差异化。

我们之前做了搜狗问答比赛,我们和学术界之外也有合作,做了最真实的中文问答的数据库。如果你用这个数据库,可能就能够真实搜索里的问答环境。这是我们现在在搞的活动,现在和行业也做了更多的数据库,之前和清华合作发布的搜狗数据,现在这个也可以公开,希望可以帮助到研究界解决问题,帮助到研究界,研究界也帮到我们。

之后谈一下关于“对话”。
前两周Google的I/O大会刚刚发布了一个让大家非常震撼的语音帮助你订餐的系统,这种对话系统有各种门类,有任务型的对话(如苹果的SIRI);也有聊天机器人的对话(如微软的小冰)。Google发布的理念和搜狗非常一致,我们称之为辅助人,帮人做这样的对话。事实上这个系统之前已经有很多的概念设计,并且已经上线,给大家放一个小视频。

这里面提到了一个大的概念,输入法演化方向,大家会认为输入是靠语音,靠说,这是一个方向,帮你更省力。另外我们提到的核心逻辑是辅助输入,从填空题变成选择题。机器帮你做选择、侯选,然后你再点选。
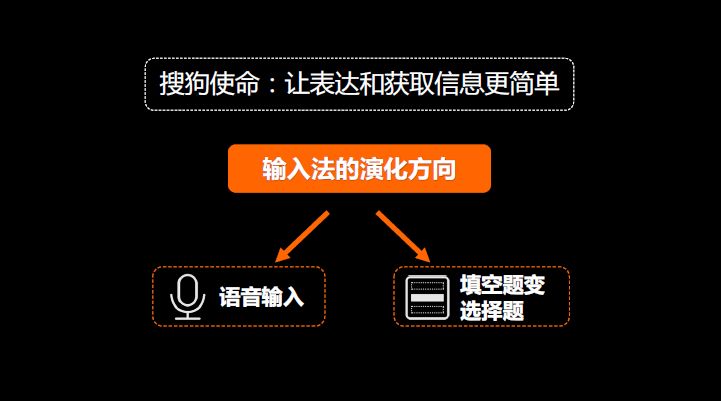
这个和我们今天讲到的无人驾驶概念更加接近,无人驾驶是机器取代人,帮你开车、说话。但其实在很长时间里需要一个辅助驾驶的阶段,需要人机结合在一块儿,所以我们强调的是机器和人一块儿提升你的工作效率。尤其是人完全被机器取代帮你说话是一件非常可怕的事情。
我们做了很多年的工作,我们在三四年前启动了辅助对话的研究项目。
辅助对话和聊天机器人有什么样的区别?
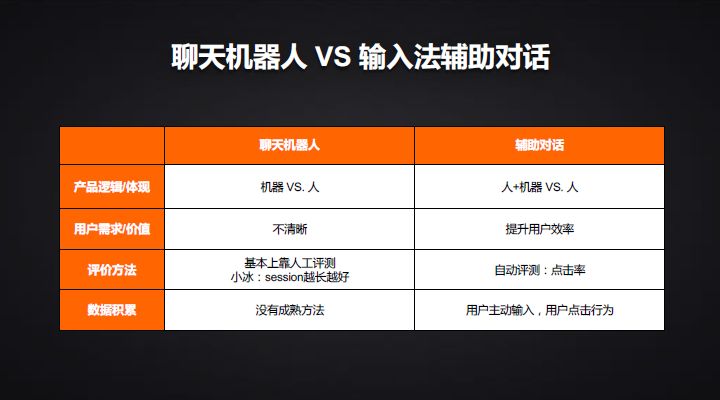
聊天机器人不管是任务型还是纯聊天的,其实是一个机器和一个人做沟通。而辅助对话是人加上一个机器跟人做沟通,你也可以说是机器帮助到人了,帮我做的更好,是人的辅助。但换一种视角,也是人在帮助机器,机器给了几个答案,不确认哪个更好,人在点选的时候,也是辅助机器做这样一个对话,这样会非常美妙。
从用户价值上来讲,之前的纯聊天机器人的目标不清楚,怎么叫做更好?而我们辅助对话很确认,是提升用户的效率,不是取代人,是在帮助你改进你的效率。

评价方法上,传统的聊天机器人基本上靠人工评测,没有特别好的自动评价好不好的方法。微软的小冰有一个方法,聊天聊的时间越长越好,对话的回合数更多。它的理论是别把天给聊死了,这个作为它的考评指标,我觉得也挺无聊的。而辅助对话的评价指标靠最后的覆盖度点击率,我提供了这个侯选之后,人是否点了,点了第一个还是第二个?或者一个也没有点开始他自己的输入?这个事情有明确的对它好不好的评价,能帮它做数据的积累和迭代。在数据积累和迭代中,传统的方法比较困难。用辅助对话是在用户的主动输入、主动点击行为都可以构成到我们这样的数据库。
2014年10月份,我们在短信上推出我们自己的APP,集成了我们的聊天工具。2016年两年后做到了日活800万+,月活2000万+的水平。这个功能核心是防止电话骚扰等。收集到了大量的数据,最终做到了展现率,对方说话之后,展现率超过54.02%,点击率是8.59%,不算特别高,但是这个值已经接近联想的值。我认为还没有展示出机器魅力。
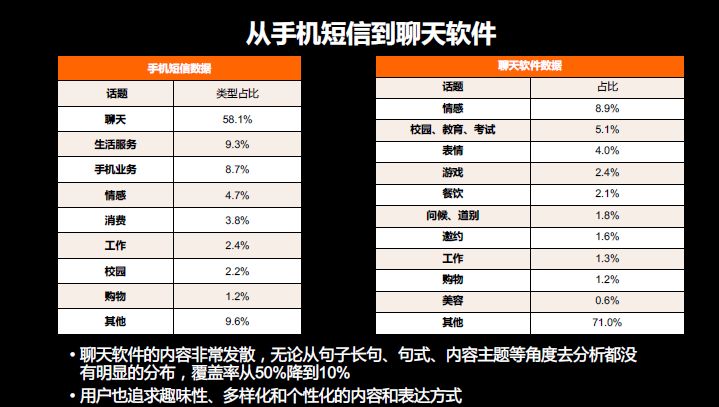
后来从手机短信转向了聊天软件,核心是QQ。我们做数据分析对比这两类大家的话题很不一样。手机新还是以效率优先,是一些简单的事务,主要的聊天和事相关。到了聊天软件之后,本身很发散,从句子的长度都非常发散,从原有的套过来,覆盖率瞬间从50%降低到10%。用原来的不够了,用户更加追求趣味多样化的表达。所以我们开始做一些复杂的模型,有检索的模型、深度学习的模型等等开始做,用各种混合的方式来解决这个问题。
现在这个聊天软件用了搜狗覆盖的3%的QQ用户用这个功能,只开3%做尝试。每天的数据集是4300万,每个月会收集3亿的对话数据,这个数据中既有人在里面怎么聊,也有机器聊的好不好和点击率、展现率的反馈。现在回到好的效果,展现率52%,点击率8%。我们希望这个值还能有5倍的提升。这是辅助聊天软件做的尝试。
除此之外,我们会把这个系统用到以后的垂直领域,比如客服领域。今天大家说是机器取代人去客服,我们的理念是机器和人是协作的,可能一开始坐席用的是搜狗定制版的输入法,它帮你做客服,以后慢慢工位上开始使用机器,不要脱离环境,总是保持一部分的工位上是人机结合,一部分是自动的。这是我们做的一个威廉希尔官方网站 ,今年年底前会看到很有意思的效果。

之前是上下文做的训练,往下的几个要点要考虑:
第一,知识放上去。这个系统有一个问题,机场安检的充电宝最大容量是多少?在你以前的聊天环境中没有这个数据,是否把问答的引擎接进去?或者晚上在哪里吃饭?再把你个性化地址接进去。最爱习惯的餐厅。过敏性鼻炎犯了怎么办?商业化能力怎么介入 推荐电影去哪里看?把超越用户自己的知识放进去,甚至用户自己都想不到的答案,提供一个更好的答案,这是我们努力的方向。
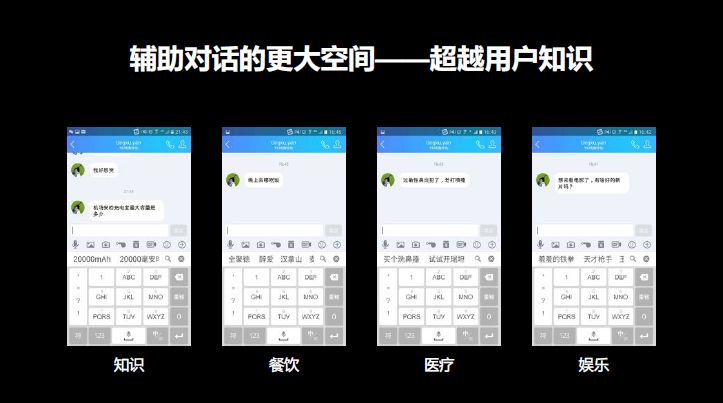
第二,挑战。包括用户个性化风格的问题。之前我们给的通用系统问问题了之后有四个答案,不认识、不认得、认不得、我不认识啊。你给了这四个答案,怎么说也没错,但其实对用户来说是一个很大的骚扰或者他觉得你很笨,怎么学会用户自己的口头表达方式?这是中间的一个挑战。

另外是用户的自己,比如用户问我你在哪?第一次回复是否记住了?第二次被人问到你在哪的时候,就知道给你生成侯选答案。可以把我的习惯和行为作为一个学习。去年10月份搜狗IPO的时候,上市之后特别多的祝福短信 微信 过来到我的手机上,我有强迫症,我觉得人家既然问候了你上市成功这件事情我就应该有一个回复,我每天要处理2000-3000条的回复,处理了之后就睡觉,第二天爬起来手机就爆掉了。我就说手机能不能帮我回复?老师来了怎么回复,同学来了怎么回复同事来了怎么回复。

然后是能否在客户端上训练数据,一个是上下文里有多个上下文,也就是长文章里训练。现在有时候在群里或者用户聊天中,聊的可能是多线程的。两个人聊好几个事,对方问的话,你回答的是前面一个问题,这种情况下怎么样做数据的训练和抽取。
最后是策略问题,今天做的工作核心还是放在服务器上,这样更好的迭代。但是这件事情对性能、隐私都有更大的挑战,怎么样把模型压缩小了放在设备里去,这是我们考虑的一个问题。
这是讲到我们在对话里的努力方向是辅助对话,有别于大多数公司在做的任务。
这个任务首先和搜狗的特长结合的特别好。
第二,理念里面帮助到人,让人 更强。和Google最近发布的这件事情是非常一致的。
最后提到我们的模式,搜狗内部有两个做研究的机构:
一、搜狗输入法。自然交互。
二、搜狗搜索。知识计算。
第一,自然交互和人更好的沟通,搜狗每天有超过3亿次的语音识别请求,这是我们在招股书里承诺的,不能含有水分,这个是全中国排名第一的,以前不敢说,百度最近财报里提到了,说的是语音请求数是2亿次,搜狗每次做的在线识别量是全中国最大的。
自然交互用新的智能硬件做承载,包括像ECHO小音箱,一年内我们还会有三款智能硬件的发布,一款比一款更加惊艳。超出大家想象。
第二,知识计算不仅来自于互联网,在医学知识、法律知识来自于知识图谱和线下的特别文献,可以在里面做更多精准的推理分析。从输入和搜索两个头,一头离用户更近,一头是更深的知识。
合在一块儿,最后打造的还是虚拟的个人助理,一年之内我们会不断的发新的智能硬件产品,会在各种领域做垂直的个人助理,帮助你表达、更好获取信息的一个新的产品平台。这是搜狗基于现在的能力做的几件事情。
今天给大家的报告到这里,谢谢!
-
搜狗
+关注
关注
0文章
90浏览量
13927 -
AI
+关注
关注
87文章
30817浏览量
268967
原文标题:2018GAITC演讲实录丨王小川:搜狗的AI之路与挑战
文章出处:【微信号:CAAI-1981,微信公众号:中国人工智能学会】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
亿铸科技熊大鹏探讨AI大算力芯片的挑战与解决策略
AI如何助力EDA应对挑战

AI for Science:人工智能驱动科学创新》第4章-AI与生命科学读后感
《AI for Science:人工智能驱动科学创新》第二章AI for Science的威廉希尔官方网站 支撑学习心得
NVIDIA为AI城市挑战赛构建合成数据集

万物智联时代,RISC-V与AI的融合之路该如何走?

AI普及给嵌入式设计人员带来新挑战

数据中心的AI时代转型:挑战与机遇







 工商网监
工商网监
评论