 基于蒙特卡罗方法的理论
基于蒙特卡罗方法的理论
▌4.1 基于蒙特卡罗方法的理论
本章我们学习无模型的强化学习算法。
强化学习算法的精髓之一是解决无模型的马尔科夫决策问题。如图4.1所示,无模型的强化学习算法主要包括蒙特卡罗方法和时间差分方法。本章我们阐述蒙特卡罗方法。

图4.1 强化学习方法分类
学习蒙特卡罗方法之前,我们先梳理强化学习的研究思路。首先,强化学习问题可以纳入马尔科夫决策过程中,这方面的知识已在第2章阐述。在已知模型的情况下,可以利用动态规划的方法(动态规划的思想是无模型强化学习研究的根源,因此重点阐述)解决马尔科夫决策过程。第3章,阐述了两种动态规划的方法:策略迭代和值迭代。这两种方法可以用广义策略迭代方法统一:即先进行策略评估,也就是计算当前策略所对应的值函数,再利用值函数改进当前策略。无模型的强化学习基本思想也是如此,即:策略评估和策略改善。
在动态规划的方法中,值函数的计算方法如图4.2所示。
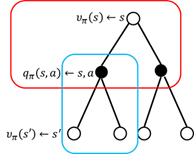
图4.2值函数计算方法
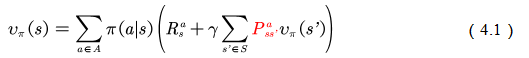
动态规划方法计算状态 s处的值函数时利用了模型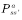 ,而在无模型强化学习中,模型
,而在无模型强化学习中,模型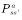 是未知的。无模型的强化学习算法要想利用策略评估和策略改善的框架,必须采用其他的方法评估当前策略(计算值函数)。
是未知的。无模型的强化学习算法要想利用策略评估和策略改善的框架,必须采用其他的方法评估当前策略(计算值函数)。
我们回到值函数最原始的定义公式(参见第2章):
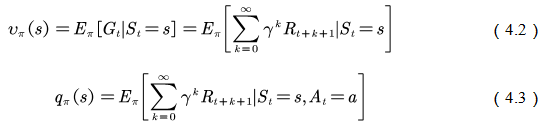
状态值函数和行为值函数的计算实际上是计算返回值的期望(参见图4.2),动态规划的方法是利用模型计算该期望。在没有模型时,我们可以采用蒙特卡罗的方法计算该期望,即利用随机样本估计期望。在计算值函数时,蒙特卡罗方法是利用经验平均代替随机变量的期望。此处,我们要理解两个词:经验和平均。
首先来看下什么是“经验”。
当要评估智能体的当前策略时,我们可以利用策略产生很多次试验,每次试验都是从任意的初始状态开始直到终止,比如一次试验(an episode)为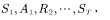 计算一次试验中状态处的折扣回报返回值为
计算一次试验中状态处的折扣回报返回值为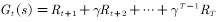 ,那么“经验”就是指利用该策略做很多次试验,产生很多幕数据(这里的一幕是一次试验的意思),如图4.3所示。
,那么“经验”就是指利用该策略做很多次试验,产生很多幕数据(这里的一幕是一次试验的意思),如图4.3所示。

图4.3 蒙特卡罗中的经验
再来看什么是“平均”。
这个概念很简单,平均就是求均值。不过,利用蒙特卡罗方法求状态处的值函数时,又可以分为第一次访问蒙特卡罗方法和每次访问蒙特卡罗方法。
第一次访问蒙特卡罗方法是指在计算状态处的值函数时,只利用每次试验中第一次访问到状态s时的返回值。如图4.3中第一次试验所示,计算状态s处的均值时只利用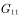 ,因此第一次访问蒙特卡罗方法的计算公式为
,因此第一次访问蒙特卡罗方法的计算公式为
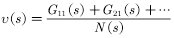
每次访问蒙特卡罗方法是指在计算状态s处的值函数时,利用所有访问到状态s时的回报返回值,即
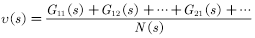 ,
,
根据大数定律: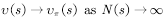 。
。
由于智能体与环境交互的模型是未知的,蒙特卡罗方法是利用经验平均来估计值函数,而能否得到正确的值函数,则取决于经验——因此,如何获得充足的经验是无模型强化学习的核心所在。
在动态规划方法中,为了保证值函数的收敛性,算法会逐个扫描状态空间中的状态。无模型的方法充分评估策略值函数的前提是每个状态都能被访问到,因此,在蒙特卡洛方法中必须采用一定的方法保证每个状态都能被访问到,方法之一是探索性初始化。
探索性初始化是指每个状态都有一定的几率作为初始状态。在学习基于探索性初始化的蒙特卡罗方法前,我们还需要先了解策略改善方法,以及便于进行迭代计算的平均方法。下面我们分别介绍蒙特卡罗策略改善方法和可递增计算均值的方法。
(1)蒙特卡罗策略改善。
蒙特卡罗方法利用经验平均估计策略值函数。估计出值函数后,对于每个状态s,它通过最大化动作值函数来进行策略的改善。即
(2)递增计算均值的方法如(4.4)式所示。
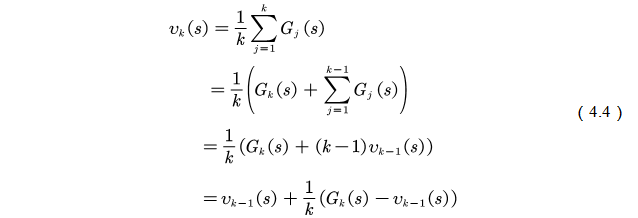
如图4.4所示是探索性初始化蒙特卡罗方法的伪代码,需要注意的是:
第一,第2步中,每次试验的初始状态和动作都是随机的,以保证每个状态行为对都有机会作为初始状态。在评估状态行为值函数时,需要对每次试验中所有的状态行为对进行估计;
第二,第3步完成策略评估,第4步完成策略改善。

图4.4探索性初始化蒙特卡罗方法
我们再来讨论一下探索性初始化。
探索性初始化在迭代每一幕时,初始状态是随机分配的,这样可以保证迭代过程中每个状态行为对都能被选中。它蕴含着一个假设:假设所有的动作都被无限频繁选中。对于这个假设,有时很难成立,或无法完全保证。
我们会问,如何保证在初始状态不变的同时,又能保证每个状态行为对可以被访问到?
答:精心设计你的探索策略,以保证每个状态都能被访问到。
可是如何精心地设计探索策略?符合要求的探索策略应该是什么样的?
答:策略必须是温和的,即对所有的状态s和a满足: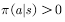 。也就是说,温和的探索策略是指在任意状态下,采用动作集中每个动作的概率都大于零。典型的温和策略是
。也就是说,温和的探索策略是指在任意状态下,采用动作集中每个动作的概率都大于零。典型的温和策略是 策略:
策略:
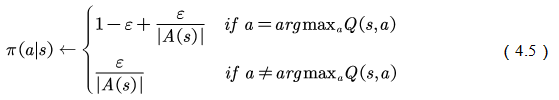
根据探索策略(行动策略)和评估的策略是否为同一个策略,蒙特卡罗方法又分为on-policy和off-policy两种方法。
若行动策略和评估及改善的策略是同一个策略,我们称为on-policy,可翻译为同策略。
若行动策略和评估及改善的策略是不同的策略,我们称为off-policy,可翻译为异策略。
接下来我们重点理解这on-policy方法和off-policy方法。
(1)同策略。
同策略(on-policy)是指产生数据的策略与评估和要改善的策略是同一个策略。比如,要产生数据的策略和评估及要改善的策略都是 策略。其伪代码如图4.5所示。
策略。其伪代码如图4.5所示。

图4.5 同策略蒙特卡罗强化学习方法
图4.5中产生数据的策略以及评估和要改善的策略都是 策略。
策略。
(2)异策略。异策略(off-policy)是指产生数据的策略与评估和改善的策略不是同一个策略。我们用 表示用来评估和改善的策略,用
表示用来评估和改善的策略,用 表示产生样本数据的策略。
表示产生样本数据的策略。
异策略可以保证充分的探索性。例如用来评估和改善的策略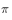 是贪婪策略,用于产生数据的探索性策略
是贪婪策略,用于产生数据的探索性策略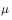 为探索性策略,如
为探索性策略,如 策略。
策略。
用于异策略的目标策略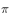 和行动策略
和行动策略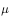 并非任意选择的,而是必须满足一定的条件。这个条件是覆盖性条件,即行动策略
并非任意选择的,而是必须满足一定的条件。这个条件是覆盖性条件,即行动策略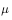 产生的行为覆盖或包含目标策略
产生的行为覆盖或包含目标策略
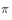 产生的行为。利用式子表示:满足
产生的行为。利用式子表示:满足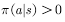 的任何
的任何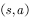 均满足
均满足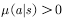 。
。
利用行为策略产生的数据评估目标策略需要利用重要性采样方法。下面,我们介绍重要性采样。
我们用图4.6描述重要性采样的原理。重要性采样来源于求期望,如图4.6所示:

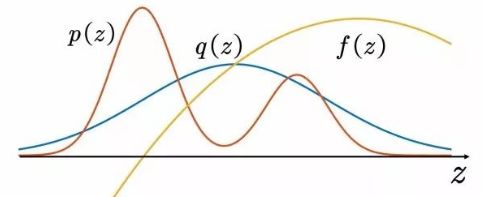
图4.6 重要性采样
如图4.6所示,当随机变量z的分布非常复杂时,无法利用解析的方法产生用于逼近期望的样本,这时,我们可以选用一个概率分布很简单,很容易产生样本的概率分布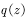 ,比如正态分布。原来的期望可变为
,比如正态分布。原来的期望可变为
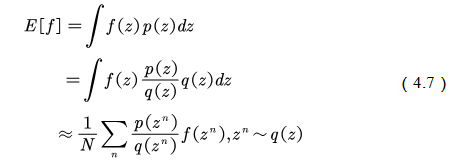
定义重要性权重: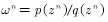 ,普通的重要性采样求积分如方程(4.7)所示为
,普通的重要性采样求积分如方程(4.7)所示为
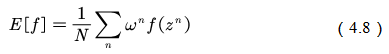
由式(4.7)可知,基于重要性采样的积分估计为无偏估计,即估计的期望值等于真实的期望。但是,基于重要性采样的积分估计的方差无穷大。这是因为原来的被积函数乘了一个重要性权重,改变了被积函数的形状及分布。尽管被积函数的均值没有发生变化,但方差明显发生改变。
在重要性采样中,使用的采样概率分布与原概率分布越接近,方差越小。然而,被积函数的概率分布往往很难求得、或很奇怪,因此没有与之相似的简单采样概率分布,如果使用分布差别很大的采样概率对原概率分布进行采样,方差会趋近于无穷大。一种减小重要性采样积分方差的方法是采用加权重要性采样:
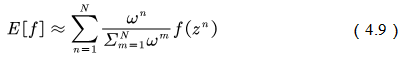
在异策略方法中,行动策略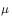 即用来产生样本的策略,所产生的轨迹概率分布相当于重要性采样中的
即用来产生样本的策略,所产生的轨迹概率分布相当于重要性采样中的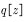 ,用来评估和改进的策略
,用来评估和改进的策略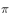 所对应的轨迹概率分布为
所对应的轨迹概率分布为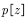 ,因此利用行动策略
,因此利用行动策略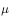 所产生的累积函数返回值来评估策略
所产生的累积函数返回值来评估策略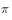 时,需要在累积函数返回值前面乘以重要性权重。
时,需要在累积函数返回值前面乘以重要性权重。
在目标策略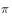 下,一次试验的概率为
下,一次试验的概率为

在行动策略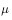 下,相应的试验的概率为
下,相应的试验的概率为
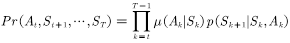
因此重要性权重为
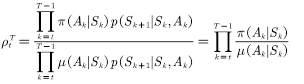
(4.10)
普通重要性采样的值函数估计如图4.7所示:
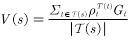 (4.11)
(4.11)

图4.7 普通重要性采样计算公式
现在举例说明公式(4.11)中各个符号的具体含义。
如图4.8所示,t是状态s访问的时刻,T(t)是访问状态s相对应的试验的终止状态所对应的时刻。T(s)是状态s发生的所有时刻集合。在该例中,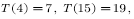
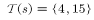

图4.8 重要性采样公式举例解释
加权重要性采样值函数估计为
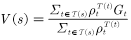 (4.12)
(4.12)
最后,我们给出异策略每次访问蒙特卡罗算法的伪代码,如图4.9所示。

图4.9 蒙特卡罗方法伪代码
注意:此处的软策略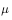 为
为 策略,需要改善的策略
策略,需要改善的策略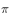 为贪婪策略。
为贪婪策略。
总结一下:本节重点讲解了如何利用MC的方法估计值函数。与基于动态规划的方法相比,基于MC的方法只是在值函数估计上有所不同,在整个框架上则是相同的,即评估当前策略,再利用学到的值函数进行策略改善。本节需要重点理解on-policy 和off-policy的概念,并学会利用重要性采样来评估目标策略的值函数。
▌4.2 统计学基础知识
为什么要讲统计学?
我们先看一下统计学的定义。统计学是关于数据的科学,它提供的是一套有关数据收集、处理、分析、解释并从数据中得出结论的方法。
联系我们关于强化学习算法的概念:强化学习是智能体通过与环境交互产生数据,并把从中学到的知识内化为自身行为的过程。学习的过程其实就是数据的处理和加工过程。尤其是值函数的估计,更是利用数据估计真实值的过程,涉及样本均值,方差,有偏估计等,这些都是统计学的术语。下面做些简单介绍。
总体:包含所研究的全部数据的集合。
样本:从总体中抽取的一部分元素的集合。在episode强化学习中,一个样本是指一幕数据。
统计量:用来描述样本特征的概括性数字度量。如样本均值,样本方差,样本标准差等。在强化学习中,我们用样本均值衡量状态值函数。
样本均值:
设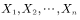 为样本容量为n的随机样本,它们是独立同分布的随机变量,则样本均值为
为样本容量为n的随机样本,它们是独立同分布的随机变量,则样本均值为
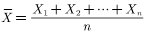 ,
,
样本均值也是随机变量。
样本方差:
设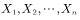 为样本容量为n的随机样本,它们是独立同分布的随机变量,则样本方差为
为样本容量为n的随机样本,它们是独立同分布的随机变量,则样本方差为
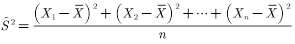
无偏估计:若样本的统计量等于总体的统计量,则称该样本的统计量所对应的值为无偏估计。如总体的均值和方差分别为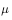 和
和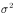 时,若
时,若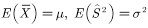 ,则
,则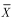 和
和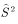 称为无偏估计。
称为无偏估计。
蒙特卡罗积分与随机采样方法[3]:
蒙特卡罗方法常用来计算函数的积分,如计算下式积分。
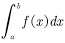 (4.13)
(4.13)
如果f(x)的函数形式非常复杂,则(4.13)式无法应用解析的形式计算。这时,我们只能利用数值的方法计算。利用数值的方法计算(4.13)式的积分需要取很多样本点,计算f(x)在这些样本点处的值,并对这些值求平均。那么问题来了:如何取这些样本点?如何对样本点处的函数值求平均呢?
针对这两个问题,我们可以将(4.13)式等价变换为
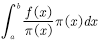 (4.14)
(4.14)
其中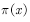 为已知的分布。将(4.13)式变换为等价的(4.14)式后,我们就可以回答上面的两个问题了。
为已知的分布。将(4.13)式变换为等价的(4.14)式后,我们就可以回答上面的两个问题了。
问题一:如何取样本点?
答:因为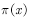 是一个分布,所以可根据该分布进行随机采样,得到采样点
是一个分布,所以可根据该分布进行随机采样,得到采样点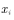 。
。
问题二:如何求平均?
答:根据分布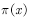 采样
采样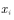 后,在样本点处计算
后,在样本点处计算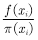 ,并对所有样本点处的值求均值:
,并对所有样本点处的值求均值:
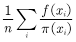 (4.15)
(4.15)
以上就是利用蒙特卡罗方法计算积分的原理。
我们再来看看期望的计算。设X表示随机变量,且服从概率分布,计算函数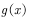 的期望。函数
的期望。函数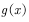 的期望计算公式为
的期望计算公式为
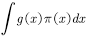
利用蒙特卡罗的方法计算该式很简单,即不断地从分布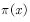 中采样
中采样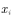 ,然后对这些
,然后对这些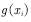 取平均便可近似
取平均便可近似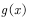 的期望。这也是4.1节中估计值函数的方法。只不过那里的一个样本是一个episode,每个episode 产生一个状态值函数,蒙特卡罗的方法估计状态值函数就是把这些样本点处的状态值函数加起来求平均,也就是经验平均。
的期望。这也是4.1节中估计值函数的方法。只不过那里的一个样本是一个episode,每个episode 产生一个状态值函数,蒙特卡罗的方法估计状态值函数就是把这些样本点处的状态值函数加起来求平均,也就是经验平均。
然而,当目标分布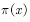 非常复杂或未知时,我们无法得到目标分布的采样点,无法得到采样点就无法计算(4.15)式,也就无法计算平均值。这时,我们需要利用统计学中的各种采样威廉希尔官方网站
。
非常复杂或未知时,我们无法得到目标分布的采样点,无法得到采样点就无法计算(4.15)式,也就无法计算平均值。这时,我们需要利用统计学中的各种采样威廉希尔官方网站
。
常用的采样方法有两类。第一类是指定一个已知的概率分布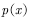 用于采样,指定的采样概率分布称为提议分布。这类采样方法包括拒绝采样和重要性采样。此类方法只适用于低维情况,针对高维情况常采用第二类采样方法,即马尔科夫链蒙特卡罗的方法。该方法的基本原理是从平稳分布为的马尔科夫链中产生非独立样本。下面我们简单介绍这些方法。
用于采样,指定的采样概率分布称为提议分布。这类采样方法包括拒绝采样和重要性采样。此类方法只适用于低维情况,针对高维情况常采用第二类采样方法,即马尔科夫链蒙特卡罗的方法。该方法的基本原理是从平稳分布为的马尔科夫链中产生非独立样本。下面我们简单介绍这些方法。
(1)拒绝采样。
当目标分布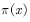 非常复杂或未知时,无法利用目标分布给出采样点,那么怎么办呢?一种方法是采用一个易于采样的提议分布
非常复杂或未知时,无法利用目标分布给出采样点,那么怎么办呢?一种方法是采用一个易于采样的提议分布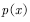 ,如高斯分布进行采样。可是,如果用提议分布
,如高斯分布进行采样。可是,如果用提议分布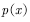 采样,那么所产生的样本服从提议分布
采样,那么所产生的样本服从提议分布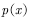 而不服从目标分布
而不服从目标分布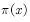 。所以,为了得到符合目标分布
。所以,为了得到符合目标分布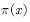 的样本,需要加工由提议分布
的样本,需要加工由提议分布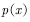 得到的样本。接收符合目标分布的样本,拒绝不符合目标分布的样本。
得到的样本。接收符合目标分布的样本,拒绝不符合目标分布的样本。
(2)重要性采样。
重要性采样我们已经在4.1节做了比较详细的介绍。
(3)MCMC方法。
MCMC方法被视为二十世纪Top 10的算法。MCMC方法全称为马尔科夫链蒙特卡罗方法。当采样空间的维数比较高时,拒绝采样和重要性采样都不实用。MCMC采样的方法原理与拒绝采样、重要性采样的原理有本质的区别。拒绝采样和重要性采样利用提议分布产生样本点,当维数很高时难以找到合适的提议分布,采样效率差。MCMC的方法则不需要提议分布,只需要一个随机样本点,下一个样本会由当前的随机样本点产生,如此循环源源不断地产生很多样本点。最终,这些样本点服从目标分布。
如何通过当前样本点产生下一个样本点,并保证如此产生的样本服从原目标分布呢?
它背后的定理是:目标分布为马氏链平稳分布。那么,何为马氏链平稳分布?
简单说就是该目标分布存在一个转移概率矩阵,且该转移概率满足:
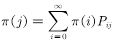
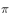 是方程
是方程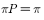 的唯一非负解。
的唯一非负解。
当转移矩阵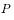 满足上述条件时,从任意初始分布
满足上述条件时,从任意初始分布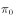 出发,经过一段时间迭代,分布
出发,经过一段时间迭代,分布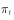 都会收敛到目标分布
都会收敛到目标分布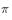 。因此,假设我们已经知道了满足条件的状态转移概率矩阵
。因此,假设我们已经知道了满足条件的状态转移概率矩阵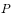 ,那么我们只要给出任意一个初始状态,则可以得到一个转移序列
,那么我们只要给出任意一个初始状态,则可以得到一个转移序列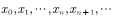 。如果该马氏链在第n步已经收敛到目标分布
。如果该马氏链在第n步已经收敛到目标分布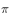 ,那么我们就得到了服从目标分布的样本
,那么我们就得到了服从目标分布的样本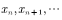 。
。
现在问题转化为寻找与目标分布相对应的转移概率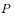 ,那么如何构造转移概率呢?
,那么如何构造转移概率呢?
转移概率和分布应该满足细致平稳条件。所谓细致平稳条件,即
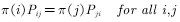
接下来,如何利用细致平衡条件构造转移概率呢?
我们可以这样考虑:加入已有的一个转移矩阵为Q的马氏链,这样任意选的转移矩阵通常情况下并不满足细致平衡条件,也就是
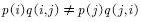
既然不满足,我们就可以改造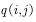 ,使之满足。改造的方法是加入一项使得
,使之满足。改造的方法是加入一项使得
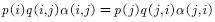
问题是如何取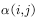 呢?一个简单的想法是利用式子的对称性,即
呢?一个简单的想法是利用式子的对称性,即
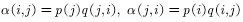
其中被称为接受率。
MCMC采样算法可总结为以下步骤。
①初始化马氏链初始状态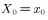 ;
;
②对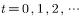 ,循环以下第③~⑥步,不断采样;
,循环以下第③~⑥步,不断采样;
③第t时刻的马氏链状态为 ,采样;
,采样;
④从均匀分布中采样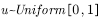 ;
;
⑤如果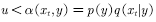 ,则接受转移
,则接受转移 ,即下一时刻的状态
,即下一时刻的状态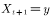 ;
;
⑥否则不接受转移,即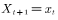 。
。
为了提高接受率,使得样本多样化,MCMC的第5行接受率通常可改写为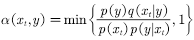 ,采样这种接受率的算法称为Metropolis- Hastings算法。
,采样这种接受率的算法称为Metropolis- Hastings算法。
在这一节中,我们用Python和蒙特卡罗方法解决机器人找金币的问题。
蒙特卡罗方法解决的是无模型的强化学习问题,基本思想是利用经验平均代替随机变量的期望。因此,利用蒙特卡罗方法评估策略应该包括两个过程:interwetten与威廉的赔率体系 和平均。
模拟就是产生采样数据,平均则是根据数据得到值函数。下面我们以利用蒙特卡罗方法估计随机策略的值函数为例做详细说明。
1.随机策略的样本产生:模拟
图4.10为蒙特卡罗方法的采样过程。该采样函数包括两个大循环,第一个大循环表示采样多个样本序列,第二个循环表示产生具体的每个样本序列。需要注意的是,每个样本序列的初始状态都是随机的。因为评估的是随机均匀分布的策略,所以在采样的时候,动作都是根据随机函数产生的。每个样本序列包括状态序列,动作序列和回报序列。

图4.10 蒙特卡罗样本采集
图4.11为蒙特卡罗方法进行策略评估的Python代码实现。该函数需要说明的地方有三处。
第一处:对于每个模拟序列逆向计算该序列的初始状态处的累积回报,也就是说从序列的最后一个状态开始往前依次计算,最终得到初始状态处的累积回报为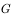 ,计算公式为
,计算公式为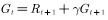
第二处:正向计算每个状态所对应的累积函数,计算公式为。
第三处:求均值,即累积和对该状态出现的次数求均值。相应于第1节中的每次访问蒙特卡罗方法。
图(4.10)和图(4.11)中的Python代码合起来组成了基于蒙特卡罗方法的评估方法。下面,我们实现基于蒙特卡罗的强化学习算法。
如图4.12和图4.13所示为蒙特卡罗方法的伪代码,其中关键代码在图4.13中实现。比较图4.13和蒙特卡罗策略评估图4.11,我们不难发现,蒙特卡罗强化学习每次迭代评估的都是 策略。
策略。

图4.11 蒙特卡罗策略评估
如图4.12和图4.13所示是蒙特卡罗强化学习算法的Python实现。

图4.12 蒙特卡罗方法伪代码及Python代码

图4.13 蒙特卡罗方法伪代码及Python代码
-
函数
+关注
关注
3文章
4329浏览量
62588 -
蒙特卡罗
+关注
关注
0文章
11浏览量
21185
原文标题:一文学习基于蒙特卡罗的强化学习方法(送书)
文章出处:【微信号:AI_Thinker,微信公众号:人工智能头条】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
一文解析开关电源的蒙特卡罗电路仿真实验
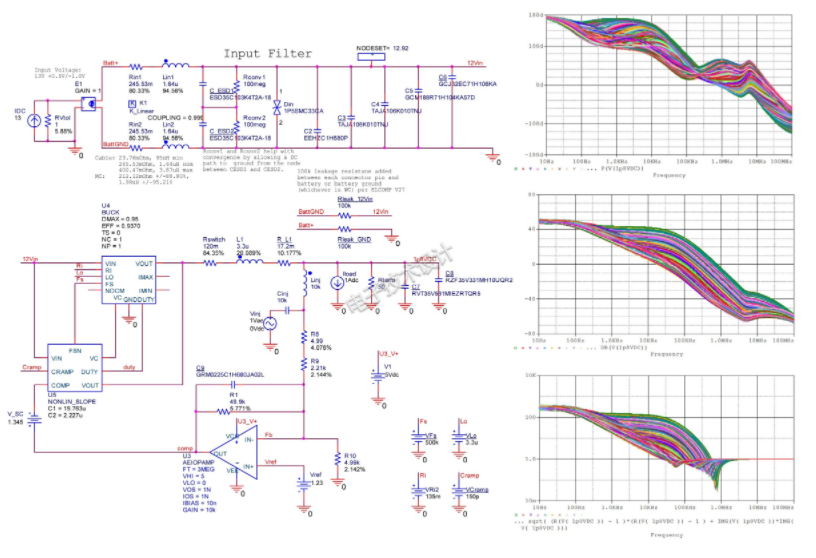
蒙特卡罗模拟估计
利用OrCAD 16.5-PSpice进行蒙特卡罗分析和最坏情况分析
如何使用蒙特卡罗方法设计领域驱动的设备云?
LTspice中使用蒙特卡罗和高斯分布进行容差分析和最差情况分析的方法
烟雾粒子的识别及其激光散射特性的蒙特卡罗模拟
烟雾粒子检测与识别系统的蒙特-卡罗模拟
赝火花开关放电的蒙特卡罗粒子模拟
基于蒙特卡罗仿真的多种二进制通信系统性能分析
基于蒙特卡罗模拟修正的随机矩阵去噪方法
人工智能领域的蒙特卡罗方法MCM概述
蒙特卡罗方法(MCM)的基本概念与应用介绍
如何使用蒙特卡罗分析法
如何在LTspice中进行蒙特卡罗分析?






 工商网监
工商网监
评论