 Python 爬取CSDN的极客头条
Python 爬取CSDN的极客头条
这两周花了点时间读了《Python网络数据采集》,内容不多,不到200页,但是非常丰富,有入门,有提高,有注意事项,有经验之谈,有原理,有分析,读完受益匪浅。书中讲了很多反爬虫、图片验证码之类的东西,不过感谢csdn的开放性,这些都没有。所以第一个练习,就是爬取csdn的极客头条的更新文章。
1、思路
思路比较简单,首先是登录,然后爬取页面的更新文章名称和链接。要注意的一点是,极客头条的列表刷新是动态的,只有页面有滚动条并且往下拉的时候,才会加载新的文章列表。我用竖屏显示器试了下,没有滚动条的情况下,默认显示20条的文章列表,结果不能加载新的文章列表,应该算是bug。
2、准备
通过浏览器的开发人员工具抓包,可以发现极客头条申请新列表的时候URL格式如下:
http://geek.csdn.net/service/news/get_news_list?jsonpcallback=jQuery203014439105321047596_1516862462757&username=[账户名]&from=-&size=20&type=hackernewsv2_new&_=1516862462758
请求参数:
jsonpcallback:
jQuery20302827217349787545_1516863701413 #该参数是jQuery框架自动生成的匿名回调函数的函数名,用于ajax获取数据时的数据处理,看网页源代码,应该是利用getJSON,所以是页面端生成的参数,可以随意填写
username: [账户名]
from:
6:252765 #这个参数代表的是下一次请求文章列表时,文章的起始编号,如果是第一次请求列表,则这里填‘-’(短杠),和上面例子中一样,下次编号会在本次请求返回的JSON数据中携带
size:
20 #本次请求的文章条目数,我试过1000都成功了。。。
type:
hackernewsv2_new #文章类型,类型在首页的“最热 最新 业界”等等那一行小标题,选择的分类不同,这个参数不同,具体抓包可见
_:
1516863701415 #没什么用,就是第一个参数下短杠后面的数字累加,实际测试没有也可以
通过查找资料和抓包,发现csdn的登录还是很简单的,只要用户名密码,不需要验证码等等,抓包可以看到请求参数:
gps:
39.890503,116.431339
username:
[账户名]
password:
[密码] #抓包的话这里是明码,发出去的话应该是加密的
rememberMe:
true #是否记住密码
lt:
LT-448149-vgNusKFi3i7wBRIZUrzCFLDfoDVP34 #这个参数是在登录主页面中的,需要自己解析出来,数值随机,每次登录需要获取
execution:
e3s1 #目前是固定值,和网文对比这个值不同,所以还是每次登录获取的好
_eventId:
submit #固定值,就是代表提交
登录时要注意的是,csdn为了防爬虫,要求HTTP头的User-Agent字段必须是真实的,所以我用了抓包里面真实的浏览器填充的字段,否则会一直登录失败,返回登录页。
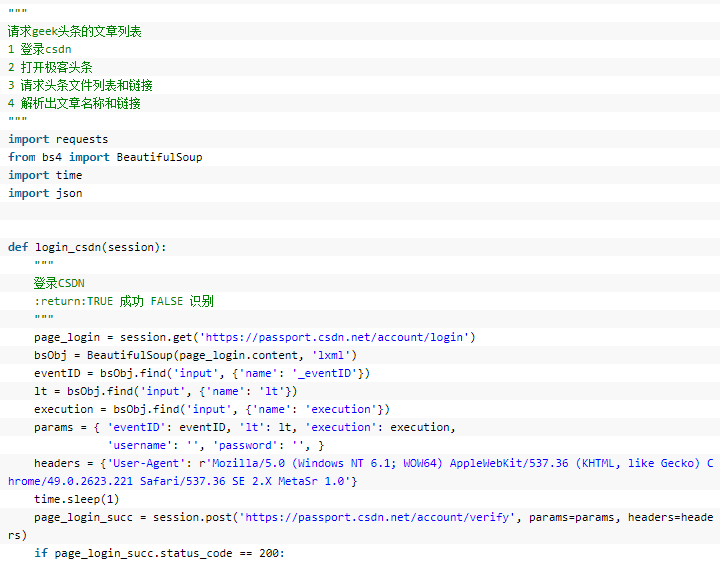
通过抓包可以看到,请求文章后,返回的是json数据,其中‘from’自动用于下次请求,‘html’字段就是返回的网页,utf-8编码的Unicode字符串,Python默认用的就是Unicode,所以取出html字段的数据后自动转为了汉字、符号等,然后解析其中的class类型为‘title’的链接,就可以获得文章链接和名称。
3、代码(非常短)


-
python
+关注
关注
56文章
4793浏览量
84631 -
csdn
+关注
关注
2文章
16浏览量
6844
原文标题:Python 爬取CSDN的极客头条
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
python实现网页爬虫爬取图片
百度92年程序员因“篡改数据”被抓
python基础语法及流程控制
豆瓣电影Top250信息爬取
Python如何爬取实时变化的WebSocket数据

华为发布麒麟 990 芯片;苹果召回部分电源插头转换器;KDevelop 5.4.2 发布 | 极客头条...






 工商网监
工商网监
评论