 比特币源码威廉希尔官方网站
分析
比特币源码威廉希尔官方网站
分析
比特币客户端所有的序列化函数均在seriliaze.h中实现。其中,CDataStream类是数据序列化的核心结构。
CDataStream
CDataStream拥有一个字符类容器用来存放序列化之后的数据。它结合一个容器类型和一个流(stream)界面以处理数据。它使用6个成员函数实现这一功能:
[cpp]view plaincopy
classCDataStream
{
protected:
typedefvector
vector_typevch;
unsignedintnReadPos;
shortstate;
shortexceptmask;
public:
intnType;
intnVersion;
//......
}
vch存有序列化后的数据。它是一个拥有自定义内存分配器的字符容器类型。该内存分配器将由该容器的实现在需要分配/释放内存时调用。该内存分配器会在向操作系统释放内存前清空内存中的数据以防止本机的其他进程访问此数据,从而保证数据存储的安全性。该内存分配器的实现在此不进行讨论,读者可于serialize.h自行查找。
nReadPos是vch读取数据的起始位置。
state是错误标识。该变量用于指示在序列化/反序列化当中可能出现的错误。
exceptmask是错误掩码。它初始化为ios::badbit | ios::failbit。与state类似,它被用于指示错误种类。
nType的取值为SER_NETWORK,SER_DISK,SER_GETHASH,SER_SKIPSIG,SER_BLOCKHEADERONLY之一,其作用为通知CDataStream进行具体某种序列化操作。这5个符号被定义在一个枚举类型enum里。每个符号均为一个int类型(4字节),并且其值为2的次方。
[cpp]view plaincopy
enum
{
SER_NETWORK=(1<< 0),
SER_DISK=(1<< 1),
SER_GETHASH=(1<< 2),
//modifiers
SER_SKIPSIG=(1<< 16),
SER_BLOCKHEADERONLY=(1<< 17),
};
nVersion是版本号。
CDataStream::read()与CDataStream::write()
成员函数CDataStream::read()和CDataStream::write()是用于执行序列化/反序列化CDataStream对象的低级函数。
[cpp]view plaincopy
CDataStream&read(char*pch,intnSize)
{
//Readfromthebeginningofthebuffer
assert(nSize>=0);
unsignedintnReadPosNext=nReadPos+nSize;
if(nReadPosNext>=vch.size())
{
if(nReadPosNext>vch.size())
{
setstate(ios::failbit,"CDataStream::read():endofdata");
memset(pch,0,nSize);
nSize=vch.size()-nReadPos;
}
memcpy(pch,&vch[nReadPos],nSize);
nReadPos=0;
vch.clear();
return(*this);
}
memcpy(pch,&vch[nReadPos],nSize);
nReadPos=nReadPosNext;
return(*this);
}
CDataStream&write(constchar*pch,intnSize)
{
//Writetotheendofthebuffer
assert(nSize>=0);
vch.insert(vch.end(),pch,pch+nSize);
return(*this);
}
CDataStream::read()从CDataStream复制nSize个字符到一个由char* pch所指向的内存空间。以下是它的实现过程:
计算将要从vch读取的数据的结束位置,unsigned int nReadPosNext = nReadPos + nSize。
如果结束位置比vch的大小更大,则当前没有足够的数据供读取。在这种情况下,通过调用函数setState()将state设为ios::failbit,并将所有的零复制到pch。
否则,调用memcpy(pch, &vch[nReadPos], nSize)复制nSize个字符,从vch的nReadPos位置开始,到由pch指向的一段预先分配的内存。接着从nReadPos向前移至下一个起始位置nReadPosNext(第22行)。
该实现表明1)当一段数据被从流中读取之后,该段数据无法被再次读取;2)nReadPos是第一个有效数据的读取位置。
CDataStream::write()非常简单。它将由pch指向的nSize个字符附加到vch的结尾。
宏READDATA()和WRITEDATA()
函数CDataStream::read()与CDataStream::write()的作用是序列化/反序列化原始类型(int,bool,unsigned long等)。为了序列化这些数据类型,这些类型的指针将被转换为char*。由于这些类型的大小目前已知,它们可以从CDataStream中读取或者写入至字符缓冲。两个用于引用这些函数的宏被定义为助手。
[cpp]view plaincopy
#defineWRITEDATA(s,obj)s.write((char*)&(obj),sizeof(obj))
#defineREADDATA(s,obj)s.read((char*)&(obj),sizeof(obj))
这里是如何使用这些宏的例子。下面的函数将序列化一个unsigned long类型。
[cpp]view plaincopy
[cpp]view plaincopy
template
把WRITEDATA(s, a)用自身的定义取代,以下是展开以后的函数:
[cpp]view plaincopy
该函数接受一个unsigned long参数a,获取它的内存地址,转换指针为char*并调用函数s.write()。
CDataStream中的操作符 << 和 >>
CDataStream重载了操作符<< 和 >>用于序列化和反序列化。
[cpp]view plaincopy
template
CDataStream&operator<<(const T& obj)
{
//Serializetothisstream
::Serialize(*this,obj,nType,nVersion);
return(*this);
}
template
CDataStream&operator>>(T&obj)
{
//Unserializefromthisstream
::Unserialize(*this,obj,nType,nVersion);
return(*this);
}
头文件serialize.h包含了14个重载后的这两个全局函数给14个原始类型(signed和unsigned版本char,short,int,long和long long,以及char,float,double和bool)以及6个重载版本的6个复合类型(string,vector,pair,map,set和CScript)。因此,对于这些类型,你可以简单地使用以下代码来序列化/反序列化数据:
[cpp]view plaincopy
CDataStreamss(SER_GETHASH);
ss<
ss>>obj3>>obj4;//反序列化
如果没有任何实现的类型符合第二个参数obj,则以下泛型T全局函数将会被调用。
[cpp]view plaincopy
template
inlinevoidSerialize(Stream&os,constT&a,longnType,intnVersion=VERSION)
{
a.Serialize(os,(int)nType,nVersion);
}
对于该泛型版本,类型T应该用于实现一个成员函数和签名T::Serialize(Stream, int, int)。它将通过a.Serialize()被调用。
怎样实现一个类型的序列化
在之前的介绍当中,泛型T需要实现以下三个成员函数进行序列化。
[cpp]view plaincopy
unsignedintGetSerializeSize(intnType=0,intnVersion=VERSION)const;
voidSerialize(Stream&s,intnType=0,intnVersion=VERSION)const;
voidUnserialize(Stream&s,intnType=0,intnVersion=VERSION);
这三个函数将由它们相对应的带泛型T的全局函数调用。这些全局函数则由CDataStream中重载的操作符<<和>>调用。
一个宏IMPLEMENT_SERIALIZE(statements)用于定义任意类型的这三个函数的实现。
[cpp]view plaincopy
#defineIMPLEMENT_SERIALIZE(statements)\
unsignedintGetSerializeSize(intnType=0,intnVersion=VERSION)const\
{\
CSerActionGetSerializeSizeser_action;\
constboolfGetSize=true;\
constboolfWrite=false;\
constboolfRead=false;\
unsignedintnSerSize=0;\
ser_streamplaceholders;\
s.nType=nType;\
s.nVersion=nVersion;\
{statements}\
returnnSerSize;\
}\
template
voidSerialize(Stream&s,intnType=0,intnVersion=VERSION)const\
{\
CSerActionSerializeser_action;\
constboolfGetSize=false;\
constboolfWrite=true;\
constboolfRead=false;\
unsignedintnSerSize=0;\
{statements}\
}\
template
voidUnserialize(Stream&s,intnType=0,intnVersion=VERSION)\
{\
CSerActionUnserializeser_action;\
constboolfGetSize=false;\
constboolfWrite=false;\
constboolfRead=true;\
unsignedintnSerSize=0;\
{statements}\
}
以下例子示范怎样使用该宏。
[cpp]view plaincopy
#include
#include"serialize.h"
usingnamespacestd;
classAClass{
public:
AClass(intxin):x(xin){};
intx;
IMPLEMENT_SERIALIZE(READWRITE(this->x);)
}
intmain(){
CDataStreamastream2;
AClassaObj(200);//一个x为200的AClass类型对象
cout<<"aObj="<
asream2<
AClassa2(1);//另一个x为1的对象
astream2>>a2
cout<<"a2="<
return0;
}
这段程序序列化/反序列化AClass对象。它将在屏幕上输出下面的结果。
[cpp]view plaincopy
aObj=200
a2=200
AClass的这三个序列化/反序列化成员函数可以在一行代码中实现:
IMPLEMENT_SERIALIZE(READWRITE(this->x);)
宏READWRITE()的定义如下
[cpp]view plaincopy
#defineREADWRITE(obj)(nSerSize+=::SerReadWrite(s,(obj),nType,nVersion,ser_action))
该宏的展开被放在宏IMPLEMENT_SERIALIZE(statements)的全部三个函数里。因此,它一次需要完成三件事情:1)返回序列化后数据的大小,2)序列化(写入)数据至流;3)从流中反序列化(读取)数据。参考宏IMPLEMENT_SERIALIZE(statements)中对这三个函数的定义。
想要了解宏READWRITE(obj)怎样工作,你首先需要明白它的完整形式当中的nSerSize,s,
nType,nVersion和ser_action是怎么来的。它们全部来自宏
IMPLEMENT_SERIALIZE(statements)的三个函数主体部分:
nSerSize是一个unsigned int,在三个函数当中初始化为0;
ser_action是一个对象在三个函数当中均有声明,但为三种不同类型。它在三个函数当中
分别为CSerActionGetSerializeSize、CSerActionSerialize和
CSerActionUnserialize;
s在第一个函数中定义为ser_streamplaceholder类型。它是第一个传入至另外两个函数
的参数,拥有参数类型Stream;
nType和nVersion在三个函数中均为传入参数。
因此,一旦宏READWRITE()扩展至宏IMPLEMENT_SERIALIZE(),所有它的符号都将被计算,
因为它们已经存在于宏IMPLEMENT_SERIALIZE()的主体中。READWRITE(obj)的扩展调用
一个全局函数::SerReadWrite(s, (obj), nType, nVersion, ser_action)。
这里是这个函数的全部三种版本。
[cpp]view plaincopy
template
inlineunsignedintSerReadWrite(Stream&s,constT&obj,intnType,intnVersion,CSerActionGetSerializeSizeser_action)
{
return::GetSerializeSize(obj,nType,nVersion);
}
template
inlineunsignedintSerReadWrite(Stream&s,constT&obj,intnType,intnVersion,CSerActionSerializeser_action)
{
::Serialize(s,obj,nType,nVersion);
return0;
}
template
inlineunsignedintSerReadWrite(Stream&s,T&obj,intnType,intnVersion,CSerActionUnserializeser_action)
{
::Unserialize(s,obj,nType,nVersion);
return0;
}
如你所见,函数::SerReadWrite()被重载为三种版本。取决于最后一个参数,它将会调分别用全局函数::GetSerialize(),::Serialize()和::Unserialize();这三个函数在前面章节已经介绍。
如果你检查三种不同版本的::SerReadWrite()的最后一个参数,你会发现它们全部为空类型。
这三种类型的唯一用途是区别::SerReadWrite()的三个版本,
继而被宏IMPLEMENT_SERIALIZE()定义的所有函数使用。
-
比特币
+关注
关注
57文章
7005浏览量
140523
原文标题:比特币源码威廉希尔官方网站 分析-2
文章出处:【微信号:C_Expert,微信公众号:C语言专家集中营】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐




时代周刊:为什么比特币是自由的源泉?
关于比特币源码威廉希尔官方网站 的分析
比特币现金BCH才是原始的比特币区块链
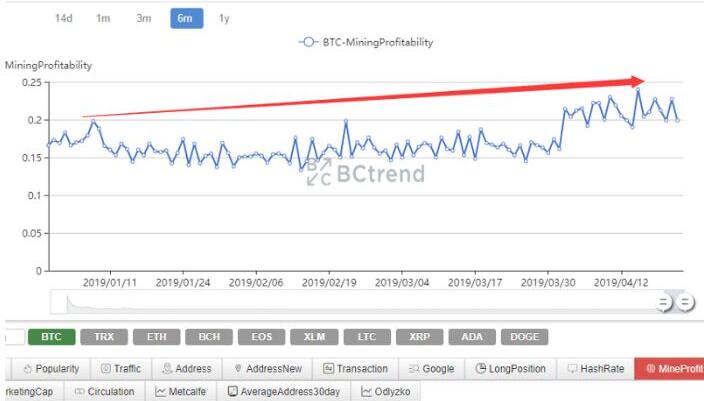
比特币价格的上涨推动了比特币矿业的利润





 工商网监
工商网监
评论