 集合通信与AI基础架构
集合通信与AI基础架构
人工智能集群的性能,尤其是机器学习训练集群,受到神经网络处理单元NPUs(即GPU或TPU)之间并行计算能力的显著影响。在我们称为纵向扩展scale-up和横向扩展scale-out设计中,NPUs之间网络的特性成为定义整个系统性能的关键因素之一。通过定义不同的并行策略,NPUs需要定期相互交换数据,对模型的各个层输出,或者梯度进行数据通信,从而更快速地完成前向和反向的训练过程。
根据并行方案和机器学习框架的具体细节,数据通信的要求可能会有所不同。通常,NPUs之间的数据传输被称为集合通信。集合通信原理已将其形式化为几种类型,具体取决于数据的初始和最终位置,以及是否需要在过程中执行数学运算。常用的类型包括广播和收集、ReduceScatter和AllGather、AllReduce和AlltoAll。操作名称中存在“Reduce”关键字表示该操作对数据进行计算。
集合通信算子
集合通信可以通过多种算法来实现。其中一些算法较为简单,因此性能较低;有些算法利用操作的性质,通常是网络拓扑,完成得更快。AllReduce的知名算法包括单向环和双向环、双二进制树以及Halving-Double算法,每种算法根据NPUs的数量以及它们如何互连,表现出不同的性能。
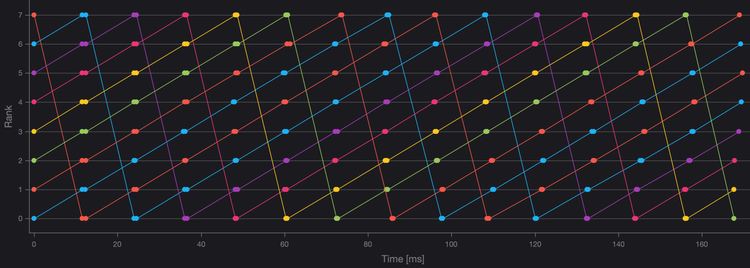
图1、8个计算节点的AllReduce单向环
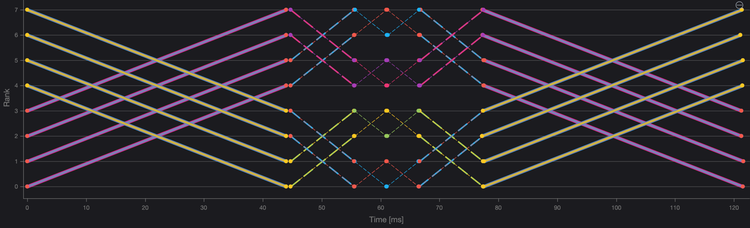
图2、8个计算节点的AllReduce Halving-Double
Rank 与通信集群大小
在集合通信中,每个参与交换数据消息的单元称为一个Rank。在大多数实际应用中,每个参与操作的NPU通常对应一个Rank。集合中所有Rank总数称为通信集群大小,用n表示,Rank是使用从0开始的整数ID进行顺序编号的,因此,最大的Rank ID是n - 1。在像广播(Broadcast)和收集(Gather)这样的集合通信操作中,有一个专门的发送者或接收者,称为根,默认情况下使用Rank ID 0作为根。
集合通信库
用于在人工智能集群中实现集合操作的软件通常称作“集合通信库”(Collective Communication Library)。其中一个最早的库 NCCL由NVIDIA开发。NCCL有多个衍生版本,其中一些是公开的,而其他一些则是私有的。
通信完成时间
集群完成集合通信操作的速度越快,训练任务就能越快地在昂贵的NPUs上进行下一轮计算。因此,我们致力于改进的是操作完成时间,即集合完成时间(Collective Completion Time,CCT),我们通常以秒为单位进行测量。
通信数据大小
集合通信操作的目标是移动数据,因此数据的大小显著影响操作所需的时间。在集合通信基准测试方法中,我们将一个Rank的通信数据大小定义为S,并以字节(B)为单位进行设置。
根据具体的操作和实现方式,集合通信算法会将数据大小S划分为多个算法数据块,每个块的大小为c,并且每个块在集合的Rank之间移动时都会遵循特定的路径。块的概念对于表达和理解集合操作算法的逻辑非常有用。
数据大小S参数具有几个值得注意的特性:
在大多数集合通信操作中,所有Rank的数据大小S都是一致的。但也有一些例外,例如在广播操作中,只有一个Rank提供输入数据。在AlltoAll-v操作中,每个NPU的数据大小S可能不同。
每个Rank通过网络发送的有效负载量D通常与S不同。这取决于具体的集合操作和所采用的算法。例如,在AlltoAll并行操作中,每个秩会保留一个大小为c = S/n的块给自己,并通过网络发送D = c * (n – 1)的数据。而在AllReduce环形操作中,每个秩将发送的数据量是D = 2 * c *(n – 1),因为这个操作是由ReduceScatter和AllGather两个步骤组成的复合操作。
在真实的AI/ML训练作业中,集合通信操作使用的数据大小受同一作业内部和不同作业之间的多种因素影响。由于AI集群基础设施在其生命周期内需要支持不断变化的作业,因此我们需要了解集合通信操作的性能如何随数据大小变化。这就是为什么集合通信基准测试方法会遍历不同的数据大小,以测量每个S值的关键指标的主要原因。
在AI集群中,大多数操作移动的是位于与NPUs直接连接的内存中的数据,而不是CPU内存中的数据。因此,我们可以通过检查现代NPUs的内存量来确定S的上限,这样做的实际意义在于基准测试。以NVIDIA H100 SXM为例,它拥有80GB的内存。由于这部分内存需要在AI模型的权重、训练数据和梯度之间共享,因此在这种情况下,32GB可能是一个实际的数据大小限制。
算法带宽
集合通信操作领域的研究人员不断发现新的算法,这些算法显著提高了集合通信完成时间(CCT),这通常归功于对底层网络拓扑的理解——即拓扑感知。由于CCT直接依赖于数据大小S,而S是特定于任务的,因此引入一个新的指标来衡量算法性能是很有帮助的,这个指标可以在不同的任务之间进行比较。类似于我们通过速度而不是旅行时间来比较汽车的性能,这个指标就是算法带宽(algbw)。它定义为数据大小S除以CCT,并以千兆字节每秒(GB/s)为单位进行测量。
请注意,尽管飞机的平均速度高于汽车,但由于等待时间,我们并不使用它们进行短距离旅行。类似地,当数据大小太小,无法完全加载网络时,CCT的一大部分时间将花费在启动和停止数据传输上。在这种情况下,algbw将不是一个有意义的指标,因为它会在不同的数据大小之间显著变化。在比较哪个算法性能更好时,您可能需要回到使用CCT。
为了说明这一点,图3是一个基准测试输出,其中在较小的数据大小上,CCT保持在7毫秒左右,但algbw每次数据大小翻倍时都会翻倍。另一方面,在较大的数据大小上,algbw趋于稳定在25GB/s,而CCT则随着数据大小的增加而继续增加。
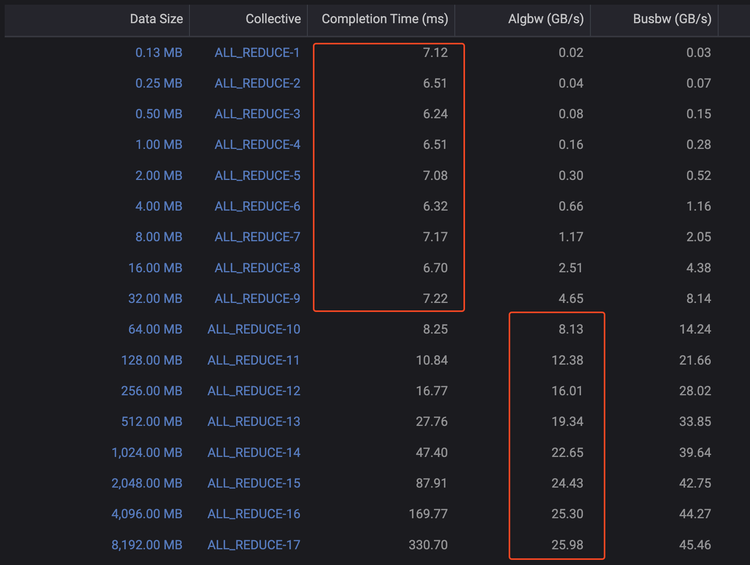
图3、不同集合通信大小下的算法带宽表现
注意:由于算法在执行时实际传输的有效负载D与数据大小S之间的区别,将算法带宽(algbw)与网络接口的理论速度进行比较是不恰当的。
总线带宽
虽然CCT和algbw依赖于数据大小S,但通信集群大小n的影响就不那么明显了。根据算法的不同,这种依赖性可能更直接或更间接。例如,对于AlltoAll并行操作,在保持相同数据大小的情况下增加集合中的Rank数,会导致算法数据块c = S / n变小。因此,更大的带宽比例会浪费在数据包头上,CCT大约会增加相同的比例。相比之下,对于AllReduce环形操作,通信集群中的Rank数越多,每个数据块为了完成环形需要穿越的跳数就越多,导致CCT线性增加。我们需要一个指标来描述通信集群的性能,这个指标与训练作业的大小无关。
为了这个目的,我们可以想象由集合通信算法定义的数据块移动类似于汽车在城市中的移动,其中停车场、车道、道路和交叉口分别代表内存、NIC、电线和开关,而汽车就是数据块。当与城市街道相比较时,这里唯一真正的延伸是所有数据块都沿着完全相同的模式移动,并且不会分心。有了这个类比,我们可以很有把握地猜测,汽车到达最终目的地所需的时间将很大程度上受到其路径上最慢路段的影响——瓶颈路段。当瓶颈路段达到其容量时,需要通过的汽车数量翻倍,它们通过所需的时间也将翻倍。换句话说,瓶颈的峰值吞吐量不依赖于城市中停车场的数量(通信集群大小n)或汽车的数量(通信数据大小S)。
这个类比的另一个用处是,尽管瓶颈的峰值吞吐量不依赖于相邻街道和汽车移动的模式(拓扑和算法),但所有汽车完成旅行所需的时间将非常取决于它们所采取的路线,以及它们在城市中的数量。
总结来说,只要汽车(数据块)以峰值数量穿越瓶颈,达到其容量(带宽),它将决定我们城市基础设施(AI集群)的性能——有效负载的移动速率无法超越系统中瓶颈的峰值容量。描述AI基础设施对集合通信操作瓶颈的指标称为总线带宽(busbw),并以千兆字节每秒(GB/s)为单位测量。
对比理想CCT
一些集合通信基准测试工具无法深入了解底层的L1-4 OSI堆栈,因此无法在测试过程中提供网络利用率的信息,也无法判断是否还有优化空间。在创建AI Data Center Builder软件时,Keysight团队考虑到了这一点,并融入了对底层的洞察。KAI Collective Benchmarks应用程序会计算每个集合通信算法的理想CCT,并将其与实际测量得到的CCT值进行比较。因此,由KAI Collective Benchmarks产生的数据包含了与理想CCT值的比较,指标形式为百分比。
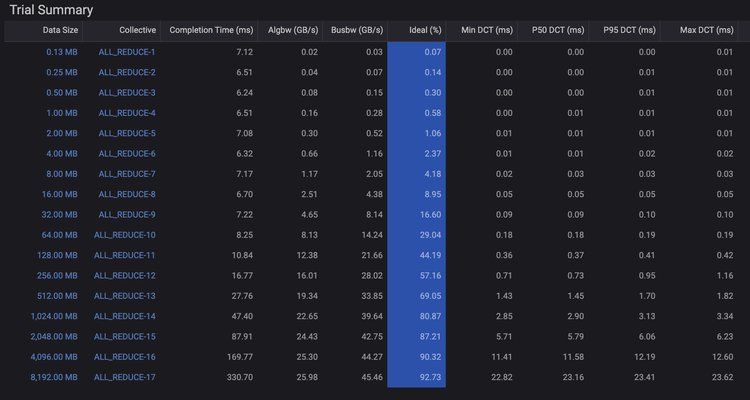
图4、KAI Collective Benchmarks 综合结果中的理想百分比
数据块完成时间分布
许多集合通信算法在每次Rank移动数据块时都展现出对称性。这是一个重要结论:当系统为每个数据块分配相等带宽时,即实现了带宽公平性,此时性能最佳。缺乏公平性会导致数据移动的尾延迟增加。一种评估公平性的方法是测量每个数据块的完成时间(DCT),并报告最小值、最大值,以及第50和第95百分位数。在具有带宽公平性的系统中,最小和最大DCT值应当较为接近。如果它们相差较大,您可以通过检查P50和P95的结果来判断异常值是更多地出现在快速还是慢速一侧。这些指标对于网络工程师来说非常熟悉,并且比学术文献中提到的其他公平性指标更容易在团队和组织之间使用。
请注意,只有在集合算法中所有数据块的大小相等时,报告DCT百分位数才是有意义的。
结论
集合通信操作的基准测试是理解分布式AI基础设施性能极限的基础性方法。它是AI集群设计和优化过程中寻找改进方案的有用工具。无论是开源还是商业实现,这些工具都围绕着一组共同的输入参数和测量指标进行操作。在本文中,我们提供了这些参数的定义,并详细阐述了它们的含义,以助力术语的标准化。
术语和定义一览表
术语
Collective Operation
定义
集合通信算子,这些通信模式涉及一组进程间的数据交换,是扩展型AI/ML集群中网络通信的基本单元,负责在GPU之间移动数据。
单位/值
Broadcast
Gather
Scatter
ReduceScatter
AllGather
AllReduce
AlltoAll
术语
Rank
定义
在集合通信操作中交换消息的端点的标识符。通常,一个Rank代表一个GPU。在某些情况下,一个GPU可以有多个Rank。
单位/值
从0开始的整数
术语
Collective Size(n)
定义
集合通信中Rank的数量
单位/值
2或大于2的整数
术语
Data Size(S)
定义
集合通信操作中,单个Rank输入的数据大小
单位/值
Bytes
术语
Collective Completion Time (CCT)
定义
集合通
集合通信操作完成所需的时间,尤其适用于比较不同集合通信算法在处理不同数据大小时的性能表现。
单位/值
秒
术语
Algorithm Bandwidth (algbw)
定义
一种用于比较不同数据大小下集合通信算法性能的指标。算法带宽(algbw)= 数据大小S / 集合完成时间(CCT)
单位/值
GB/s
术语
Bus Bandwidth (busbw)
定义
描述了集合通信算法在AI基础设施中的瓶颈性能。该公式是特定于算法的。
单位/值
GB/s
术语
Ideal %
定义
将测量的集合通信完成时间(CCT)与给定算法、传输开销和网络接口速度的最小理论值进行比较。
单位/值
秒
术语
Data chunk Completion Time (DCT)
定义
在两个Rank之间传输一个数据块所需的时间。测量集合通信操作中每个数据块完成时间(DCT)的值,并报告最小值、最大值、第50百分位数(P50)和第95百分位数(P95)有助于理解系统中的带宽公平性。
单位/值
秒
关于是德科技
是德科技(NYSE:KEYS)启迪并赋能创新者,助力他们将改变世界的威廉希尔官方网站 带入生活。作为一家标准普尔 500 指数公司,我们提供先进的设计、仿真和测试解决方案,旨在帮助工程师在整个产品生命周期中更快地完成开发和部署,同时控制好风险。我们的客户遍及全球通信、工业自动化、航空航天与国防、汽车、半导体和通用电子等市场。我们与客户携手,加速创新,创造一个安全互联的世界。
-
通信
+关注
关注
18文章
6042浏览量
136138 -
gpu
+关注
关注
28文章
4752浏览量
129057 -
AI
+关注
关注
87文章
31111浏览量
269435 -
人工智能
+关注
关注
1792文章
47412浏览量
238926 -
机器学习
+关注
关注
66文章
8424浏览量
132766
原文标题:集合通信与AI基础架构
文章出处:【微信号:是德科技KEYSIGHT,微信公众号:是德科技KEYSIGHT】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【CC3200AI实验教程14】疯壳·AI语音人脸识别-AI人脸系统架构
中国联通正式启用OSS融合通信系统进行扩容
面向5G的光纤无线融合通信威廉希尔官方网站






 工商网监
工商网监
评论