 数据压缩的性能指标
数据压缩的性能指标
数据压缩威廉希尔官方网站 ,就是用最少的数码来表示信号的威廉希尔官方网站 。
在现今的电子信息威廉希尔官方网站 领域,正发生着一场有长远影响的数字化革命。由于数字化的多媒体信息尤其是数字视频、音频信号的数据量特别庞大,如果不对其进行有效的压缩就难以得到实际的应用。因此,数据压缩威廉希尔官方网站 已成为当今数字通信、广播、存储和多媒体娱乐中的一项关键的共性威廉希尔官方网站 。
1.什么是数据压缩
其作用是:能较快地传输各种信号,如传真、Modem通信等;
在现有的通信干线并行开通更多的多媒体业务,如各种增值业务;紧缩数据存储容量,如 CD-ROM、VCD和DVD等;
降低发信机功率,这对于多媒体移动通信系统尤为重要。
由此看来,通信时间、传输带宽、存储空间甚至发射能量,都可能成为数据压缩的对象。
2.数据为何能被压缩
首先,数据中间常存在一些多余成分,既冗余度。如在一份计算机文件中,某些符号会重复出现、某些符号比其他符号出现得更频繁、某些字符总是在各数据块中可预见的位置上出现等,这些冗余部分便可在数据编码中除去或减少。冗余度压缩是一个可逆过程,因此叫做无失真压缩,或称保持型编码。
其次,数据中间尤其是相邻的数据之间,常存在着相关性。如图片中常常有色彩均匀的背影,电视信号的相邻两帧之间可能只有少量的变化影物是不同的,声音信号有时具有一定的规律性和周期性等等。因此,有可能利用某些变换来尽可能地去掉这些相关性。但这种变换有时会带来不可恢复的损失和误差,因此叫做不可逆压缩,或称有失真编码、摘压缩等。
此外,人们在欣赏音像节目时,由于耳、目对信号的时间变化和幅度变化的感受能力都有一定的极限,如人眼对影视节目有视觉暂留效应,人眼或人耳对低于某一极限的幅度变化已无法感知等,故可将信号中这部分感觉不出的分量压缩掉或“掩蔽掉”。这种压缩方法同样是一种不可逆压缩。
对于数据压缩威廉希尔官方网站 而言,最基本的要求就是要尽量降低数字化的在码事,同时仍保持一定的信号质量。不难想象,数据压缩的方法应该是很多的,但本质上不外乎上述完全可逆的冗余度压缩和实际上不可逆的嫡压缩两类。冗余度压缩常用于磁盘文件、数据通信和气象卫星云图等不允许在压缩过程中有丝毫损失的场合中,但它的压缩比通常只有几倍,远远不能满足数字视听应用的要求。在实际的数字视听设备中,差不多都采用压缩比更高但实际有损的嫡压缩威廉希尔官方网站 。
只要作为最终用户的人觉察不出或能够容忍这些失真,就允许对数字音像信号进一步压缩以换取更高的编码效率。摘压缩主要有特征抽取和量化两种方法,指纹的模式识别是前者的典型例子,后者则是一种更通用的摘压缩威廉希尔官方网站 。
3数字音、视频的压缩标准
数字音频压缩威廉希尔官方网站 标准分为电话语音压缩、调幅广播语音压缩和调频广播及CD音质的宽带有频压缩3种。
(1)电话(200HZ-3.4kHZ)语音压缩,主要有国际电信联盟(ITU)的G.711(64kbit/s、G.721(32kbit/s)、G.728(16kbit/s)和G.729(8kbit/的建议等,用于数字电话通信。
(2)调幅广播(50HZ-7kHZ)语音压缩,采用ITU的G.722(64kbit/s)建议,用于优质语音、音乐、音频会议和视频会议等。
(3)调频广播(20HZ-15kHZ)及CD音质(20HZ-20kH)的宽带音频压缩,主要采用MPEG-1或2双杜比AC-3等建议,用于CD、MD、MPC、VCD、DVD、HDTV和电影配音等。
视频压缩威廉希尔官方网站 标准主要有:
①ITU H.261建议,用于ISDN信道的PC电视电话、桌面视频会议和音像邮件等通信终端。
②MPEG-1视频压缩标准,用于 VCD、MPC、PC/TV一体机、交互电视ITV和电视点播VOD。
③MPEG-2/ITU H.262视频标准,主要用于数字存储。视频广播和通信,如HDTV、CATV、DVD、VOD和电影点播MOD等。
④ITU H.263建议,用于网上的可视电话、移动多媒体终端、多媒体可视图文、遥感、电子邮件、电子报纸和交互式计算机成像等。
⑤MPEG-4和 ITU H.VLC/L低码率多媒体通信标准仍在发展之中。
4.数据压缩的实现
在各种数据类型中,最难实现的是数字机频的实时压缩,因为视频信号尤其是HDTV信号所占据的带宽甚宽,实时压缩需要很高的处理速度。现在,视频解码以及音频的编码、解码多依赖于专用芯片或数字信号处理器(DSP)未完成,并已有许多厂商推出了音视合一的单片MPEG-1、MPEG-2解码器。我国在发展数据压缩威廉希尔官方网站 过程中,则充分利用了软件人才优势。
在软件实现方面,由于PC主机的处理能力正在飞速提高,直接利用主CPU编程实现各种视听压缩和解码算法对于桌面系统及家用多媒体将越来越有吸引力。
1996年上半年,Intel向全球软件界发布了它的微处理器媒体扩展(MMX)威廉希尔官方网站 。这种威廉希尔官方网站 主要是在Pentium或Pentium Pro芯片中增加了8个64位寄存器和57条功能强大的新指令,以提高多媒体和通信应用程序中某些计算密集的循环速度。MMX采用单指令多数据(SIMD)威廉希尔官方网站 并行处理多个信号采样值,可使不同的应用程序性能成倍提高。如:视频压缩可提高1.5倍,图像处理可提高40倍,音频处理可提高3.7偌,语音识别可提高1.7倍,三维动画可提高20倍。
与Pentium完全兼容的P55C芯片是1998年3月正式推出的。以后推出的Pentium、Pentium pro或P7等CPU,均将支持MMX指令。
在数据压缩的硬件实现方面,根本的出路是要有自己的音像压缩芯片(特别是解压芯片),不管是专用集成电路(ASIC)实现,还是借助于通用DSP来编程。
而这一类芯片,目前还只是“雾里看花”。
不过我们相信,在不久的将来,这些也会成为现实。
不同压缩算法的性能比较
JDK GZIP ——这是一个压缩比高的慢速算法,压缩后的数据适合长期使用。JDK中的java.util.zip.GZIPInputStream / GZIPOutputStream便是这个算法的实现。
JDK deflate ——这是JDK中的又一个算法(zip文件用的就是这一算法)。它与gzip的不同之处在于,你可以指定算法的压缩级别,这样你可以在压缩时间和输出文件大小上进行平衡。可选的级别有0(不压缩),以及1(快速压缩)到9(慢速压缩)。它的实现是java.util.zip.DeflaterOutputStream / InflaterInputStream。
LZ4压缩算法的Java实现——这是本文介绍的算法中压缩速度最快的一个,与最快速的deflate相比,它的压缩的结果要略微差一点。如果想搞清楚它的工作原理,我建议你读一下这篇文章。它是基于友好的Apache 2.0许可证发布的。
Snappy——这是Google开发的一个非常流行的压缩算法,它旨在提供速度与压缩比都相对较优的压缩算法。我用来测试的是这个实现。它也是遵循Apache 2.0许可证发布的。
压缩测试
要找出哪些既适合进行数据压缩测试又存在于大多数Java开发人员的电脑中(我可不希望你为了运行这个测试还得个几百兆的文件)的文件也着实费了我不少工夫。最后我想到,大多数人应该都会在本地安装有JDK的文档。因此我决定将javadoc的目录整个合并成一个文件——拼接所有文件。这个通过tar命令可以很容易完成,但并非所有人都是Linux用户,因此我写了个程序来生成这个文件:
public class InputGenerator {
private static final String JAVADOC_PATH = “your_path_to_JDK/docs”;
public static final File FILE_PATH = new File( “your_output_file_path” );
static
{
try {
if ( !FILE_PATH.exists() )
makeJavadocFile();
} catch (IOException e) {
e.printStackTrace();
}
}
private static void makeJavadocFile() throws IOException {
try( OutputStream os = new BufferedOutputStream( new FileOutputStream( FILE_PATH ), 65536 ) )
{
appendDir(os, new File( JAVADOC_PATH ));
}
System.out.println( “Javadoc file created” );
}
private static void appendDir( final OutputStream os, final File root ) throws IOException {
for ( File f : root.listFiles() )
{
if ( f.isDirectory() )
appendDir( os, f );
else
Files.copy(f.toPath(), os);
}
}
}
在我的机器上整个文件的大小是354,509,602字节(338MB)。
测试
一开始我想把整个文件读进内存里,然后再进行压缩。不过结果表明这么做的话即便是4G的机器上也很容易把堆内存空间耗尽。
于是我决定使用操作系统的文件缓存。这里我们用的测试框架是JMH。这个文件在预热阶段会被操作系统加载到缓存中(在预热阶段会先压缩两次)。我会将内容压缩到ByteArrayOutputStream流中(我知道这并不是最快的方法,但是对于各个测试而言它的性能是比较稳定的,并且不需要花费时间将压缩后的数据写入到磁盘里),因此还需要一些内存空间来存储这个输出结果。
下面是测试类的基类。所有的测试不同的地方都只在于压缩的输出流的实现不同,因此可以复用这个测试基类,只需从StreamFactory实现中生成一个流就好了:
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
@Fork(1)
@Warmup(iterations = 2)
@Measurement(iterations = 3)
@BenchmarkMode(Mode.SingleShotTime)
public class TestParent {
protected Path m_inputFile;
@Setup
public void setup()
{
m_inputFile = InputGenerator.FILE_PATH.toPath();
}
interface StreamFactory
{
public OutputStream getStream( final OutputStream underlyingStream ) throws IOException;
}
public int baseBenchmark( final StreamFactory factory ) throws IOException
{
try ( ByteArrayOutputStream bos = new ByteArrayOutputStream((int) m_inputFile.toFile().length());
OutputStream os = factory.getStream( bos ) )
{
Files.copy(m_inputFile, os);
os.flush();
return bos.size();
}
}
}
这些测试用例都非常相似(在文末有它们的源代码),这里只列出了其中的一个例子——JDK deflate的测试类;
public class JdkDeflateTest extends TestParent {
@Param({“1”, “2”, “3”, “4”, “5”, “6”, “7”, “8”, “9”})
public int m_lvl;
@Benchmark
public int deflate() throws IOException
{
return baseBenchmark(new StreamFactory() {
@Override
public OutputStream getStream(OutputStream underlyingStream) throws IOException {
final Deflater deflater = new Deflater( m_lvl, true );
return new DeflaterOutputStream( underlyingStream, deflater, 512 );
}
});
}
}
测试结果
输出文件的大小
首先我们来看下输出文件的大小:
||实现||文件大小(字节)|| ||GZIP||64,200,201|| ||Snappy (normal)||138,250,196|| ||Snappy (framed)|| 101,470,113|| ||LZ4 (fast)|| 98,316,501|| ||LZ4 (high) ||82,076,909|| ||Deflate (lvl=1) ||78,369,711|| ||Deflate (lvl=2) ||75,261,711|| ||Deflate (lvl=3) ||73,240,781|| ||Deflate (lvl=4) ||68,090,059|| ||Deflate (lvl=5) ||65,699,810|| ||Deflate (lvl=6) ||64,200,191|| ||Deflate (lvl=7) ||64,013,638|| ||Deflate (lvl=8) ||63,845,758|| ||Deflate (lvl=9) ||63,839,200||
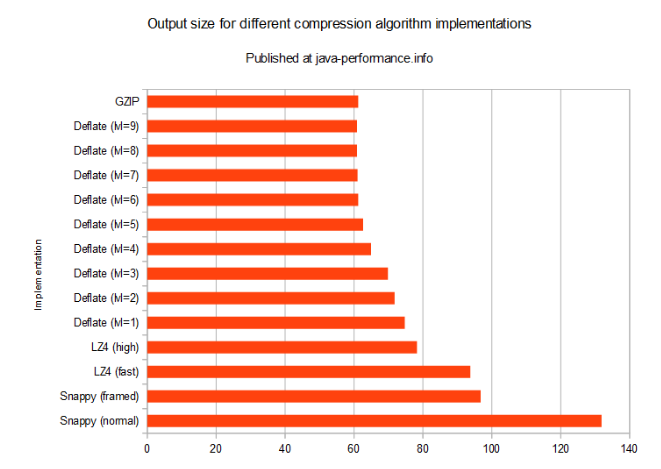
可以看出文件的大小相差悬殊(从60Mb到131Mb)。我们再来看下不同的压缩方法需要的时间是多少。
压缩时间
||实现||压缩时间(ms)|| ||Snappy.framedOutput ||2264.700|| ||Snappy.normalOutput ||2201.120|| ||Lz4.testFastNative ||1056.326|| ||Lz4.testFastUnsafe ||1346.835|| ||Lz4.testFastSafe ||1917.929|| ||Lz4.testHighNative ||7489.958|| ||Lz4.testHighUnsafe ||10306.973|| ||Lz4.testHighSafe ||14413.622|| ||deflate (lvl=1) ||4522.644|| ||deflate (lvl=2) ||4726.477|| ||deflate (lvl=3) ||5081.934|| ||deflate (lvl=4) ||6739.450|| ||deflate (lvl=5) ||7896.572|| ||deflate (lvl=6) ||9783.701|| ||deflate (lvl=7) ||10731.761|| ||deflate (lvl=8) ||14760.361|| ||deflate (lvl=9) ||14878.364|| ||GZIP ||10351.887||
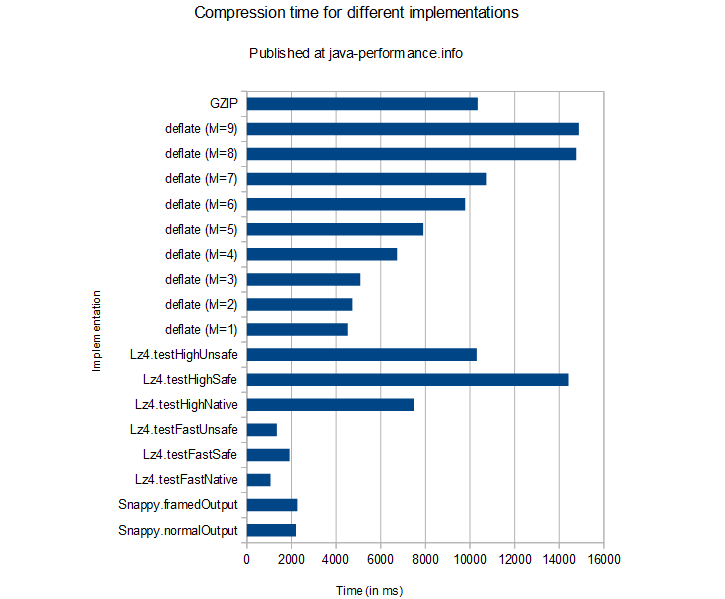
我们再将压缩时间和文件大小合并到一个表中来统计下算法的吞吐量,看看能得出什么结论。
吞吐量及效率
||实现||时间(ms)||未压缩文件大小||吞吐量(Mb/秒)||压缩后文件大小(Mb)|| ||Snappy.normalOutput ||2201.12 ||338 ||153.5581885586 ||131.8454742432|| ||Snappy.framedOutput ||2264.7 ||338 ||149.2471409017 ||96.7693328857|| ||Lz4.testFastNative ||1056.326 ||338 ||319.9769768045 ||93.7557220459|| ||Lz4.testFastSafe ||1917.929 ||338 ||176.2317583185 ||93.7557220459|| ||Lz4.testFastUnsafe ||1346.835 ||338 ||250.9587291688 ||93.7557220459|| ||Lz4.testHighNative ||7489.958 ||338 ||45.1270888301 ||78.2680511475|| ||Lz4.testHighSafe ||14413.622 ||338 ||23.4500391366 ||78.2680511475|| ||Lz4.testHighUnsafe ||10306.973 ||338 ||32.7933332124 ||78.2680511475|| ||deflate (lvl=1) ||4522.644 ||338 ||74.7350443679 ||74.7394561768|| ||deflate (lvl=2) ||4726.477 ||338 ||71.5120374012 ||71.7735290527|| ||deflate (lvl=3) ||5081.934 ||338 ||66.5101120951 ||69.8471069336|| ||deflate (lvl=4) ||6739.45 ||338 ||50.1524605124 ||64.9452209473|| ||deflate (lvl=5) ||7896.572 ||338 ||42.8033835442 ||62.6564025879|| ||deflate (lvl=6) ||9783.701 ||338 ||34.5472536415 ||61.2258911133|| ||deflate (lvl=7) ||10731.761 ||338 ||31.4952969974 ||61.0446929932|| ||deflate (lvl=8) ||14760.361 ||338 ||22.8991689295 ||60.8825683594|| ||deflate (lvl=9) ||14878.364 ||338 ||22.7175514727 ||60.8730316162|| ||GZIP ||10351.887 ||338 ||32.651051929 ||61.2258911133||
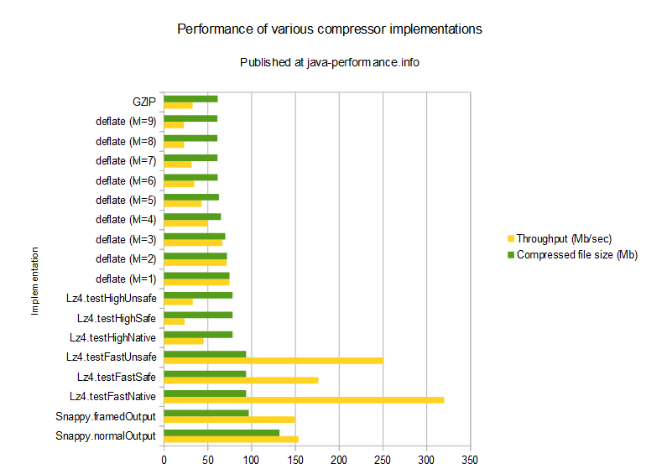
可以看到,其中大多数实现的效率是非常低的:在Xeon E5-2650处理器上,高级别的deflate大约是23Mb/秒,即使是GZIP也就只有33Mb/秒,这大概很难令人满意。同时,最快的defalte算法大概能到75Mb/秒,Snappy是150Mb/秒,而LZ4(快速,JNI实现)能达到难以置信的320Mb/秒!
从表中可以清晰地看出目前有两种实现比较处于劣势:Snappy要慢于LZ4(快速压缩),并且压缩后的文件要更大。相反,LZ4(高压缩比)要慢于级别1到4的deflate,而输出文件的大小即便和级别1的deflate相比也要大上不少。
因此如果需要进行“实时压缩”的话我肯定会在LZ4(快速)的JNI实现或者是级别1的deflate中进行选择。当然如果你的公司不允许使用第三方库的话你也只能使用deflate了。你还要综合考虑有多少空闲的CPU资源以及压缩后的数据要存储到哪里。比方说,如果你要将压缩后的数据存储到HDD的话,那么上述100Mb/秒的性能对你而言是毫无帮助的(假设你的文件足够大的话)——HDD的速度会成为瓶颈。同样的文件如果输出到SSD硬盘的话——即便是LZ4在它面前也显得太慢了。如果你是要先压缩数据再发送到网络上的话,最好选择LZ4,因为deflate75Mb/秒的压缩性能跟网络125Mb/秒的吞吐量相比真是小巫见大巫了(当然,我知道网络流量还有包头,不过即使算上了它这个差距也是相当可观的)。
总结
如果你认为数据压缩非常慢的话,可以考虑下LZ4(快速)实现,它进行文本压缩能达到大约320Mb/秒的速度——这样的压缩速度对大多数应用而言应该都感知不到。
如果你受限于无法使用第三方库或者只希望有一个稍微好一点的压缩方案的话,可以考虑下使用JDK deflate(lvl=1)进行编解码——同样的文件它的压缩速度能达到75Mb/秒。
-
数据压缩
+关注
关注
0文章
31浏览量
10135 -
性能指标
+关注
关注
0文章
14浏览量
7900
发布评论请先 登录
相关推荐






 工商网监
工商网监
评论