 台积电CoWoS封装A1威廉希尔官方网站
介绍
台积电CoWoS封装A1威廉希尔官方网站
介绍
封装的未来变得模糊 – 扇出、ABF、有机中介层、嵌入式桥接 – 先进封装第 4 部分
2.1D、2.3D 和 2.5D 先进封装的模糊界限。在 IMAPS 2022 上,展示了该领域的许多进步,先进封装行业的未来非常活跃。简要回顾一下,目前有四大类先进封装。
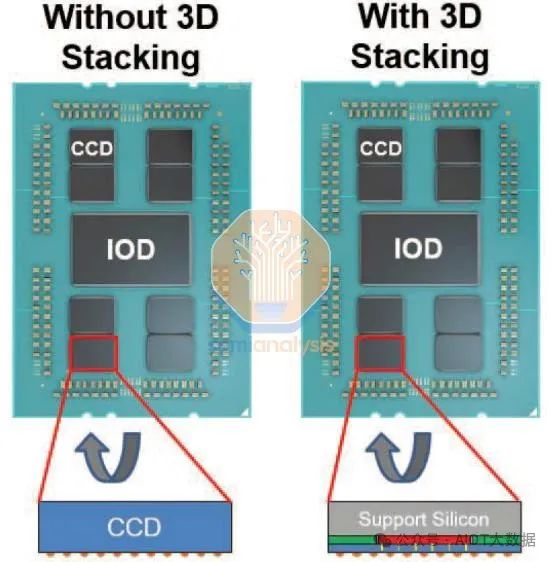
3D = 有源硅堆叠在有源硅上——最著名的形式是利用台积电的 SoIC CoW 的 AMD 3D V-Cache和利用台积电的 SoIC WoW 的 Graphcore IPU BOW。
2.5D = 有源硅堆叠在无源硅上——最著名的形式是使用台积电 CoWoS-S 的带有 HBM 内存的 Nvidia AI GPU和使用英特尔 Foveros 的英特尔 Meteor Lake CPU。
扇出 RDL(环氧模塑料层压板)——最著名的形式是台积电的 InFO,用于苹果的 A 系列、S 系列和 M 系列芯片、ASE FoCoS 和 Amkor WLFO。面板层正在由多家公司开发。
积层 ABF 基板(铜芯覆有味之素积层膜层和 RDL 层)– 最著名的形式是英特尔和 AMD PC 和数据中心芯片。
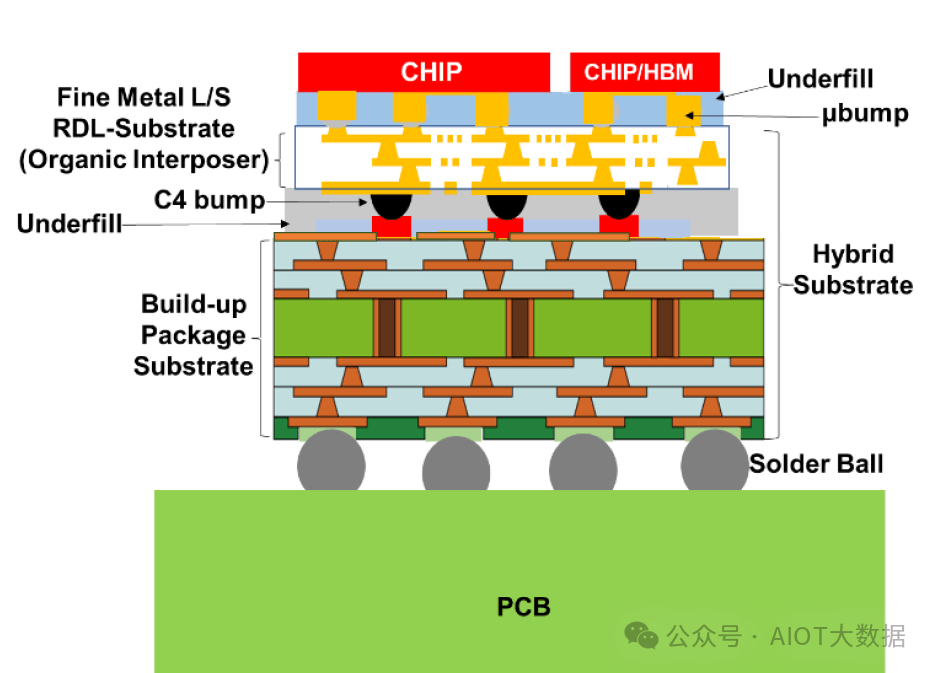
在大多数先进封装中,仍使用积层 ABF 基板。这些基板被称为混合基板。
先进封装的另一个模糊之处是工程师经常使用“有机基板”这个词。ABF 和核心扇出都含有有机环氧化学物质。
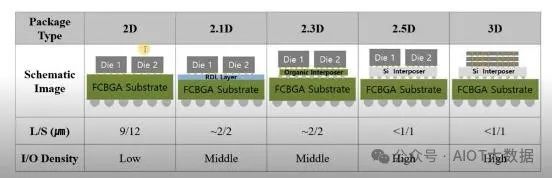
2.5D 到 3D 的分类看似简单,但封装种类的排列组合却非常多,模糊了 2.3D 和 2.1D 之间的界限。此外,随着 2.3D 和 2.1D 封装功能的发展,2.5D 的市场份额将逐渐下降。

英特尔的 EMIB 是在 ABF 基板的腔体内放置硅桥。其主要目的是避免使用昂贵的硅中介层,并使封装超出光罩极限。EMIB 在威廉希尔官方网站 上不是 2.5D 封装,但它确实带来了许多所谓的好处。与纯 2.5D 硅中介层或高密度扇出相比,它在成本和性能方面如何?未来几代产品尚无定论,但第一代产品并不占优势。

AMD 的 MI250X GPU(如上注释)和 Apple 的 M1 Ultra 是同一产品中多种封装类型的示例。GPU 芯片和每个 HBM 之间没有使用硅中介层连接,而是有硅桥。带有嵌入式桥的扇出类似于英特尔的 EMIB,但制造流程完全不同,扇出 RDL 与累积基板。
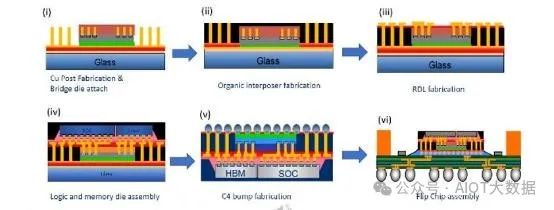
对于 MI250X,两个独立的扇出 RDL 组件与硅桥和 GPU/HBM 封装在大型 ABF 基板的顶部。
虽然由于尽量减少使用昂贵的硅中介层,理论上这种方法的成本较低,但与传统的 2.5D 硅中介层相比,产量损失的可能性更高。
扇出 RDL 并非单一工艺。它可采用多种不同类型的材料构建。此外,它可以是 RDL 优先或 Chip 优先流程。
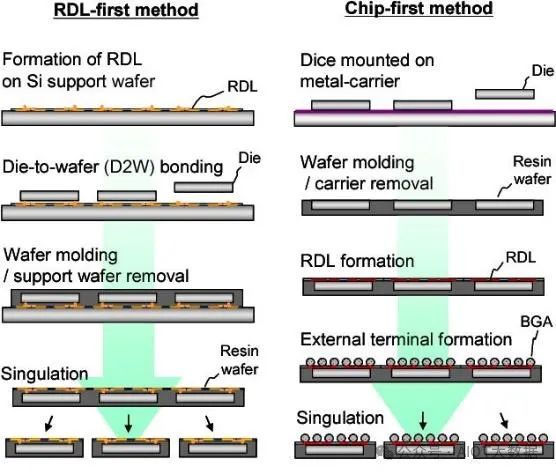
无论扇出 RDL 采用先 RDL 还是先 Chip 工艺流程,在放置芯片之前都无法测试完成的混合基板。如果采用扇出到基板的粘合工艺,可能会丢失好的芯片。尽管扇出 RDL 理论上成本较低,尤其是面板级扇出,但产量损失是继续使用硅中介层的主要原因。由于扇出 RDL 材料、累积基板和硅之间的热膨胀系数 (CTE) 不匹配,这些产量问题可能会延伸到基板翘曲。
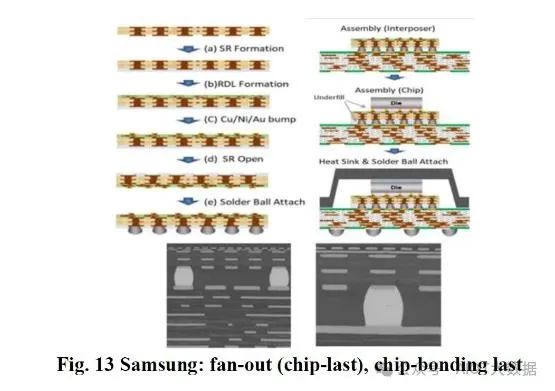
三星、新光、欣兴、矽品和台积电一直在研究封装工艺,首先制造扇出型 RDL;然后将扇出型 RDL 粘合在积层 ABF 基板上。然后对粘合的混合基板进行测试,最后将芯片粘合到其上。这称为扇出型(RDL-First 或 Chip-Last),最后芯片粘合。每家公司都有自己的调整,有些公司使用有机或无机材料。拥有已知的用于先进封装的优质基板可提高组装产量和物流,这是巨大的优势。
数据中心和 PC 行业传统上采用将已知良好基板与已知良好芯片相匹配的供应链。如果可以经济高效地完成,则先进行 RDL/最后进行芯片接合是首选的封装方法。
与扇出型(最后芯片或 RDL 优先)工艺相比,扇出型(先芯片)工艺的 IC 集成更简单,成本更低。问题是,先芯片意味着封装良率会降低更多已知良好的芯片。随着行业转向更昂贵的工艺威廉希尔官方网站 ,这种封装良率损失继续成为封装工艺成本增长的主要因素。此外,扇出型(最后芯片)集成还有其他优势,例如芯片尺寸更大、封装尺寸更大、芯片移位问题更少,以及 RDL 的金属 L/S 更精细。L/S 是线距,指的是金属互连的宽度和它们之间的空间。
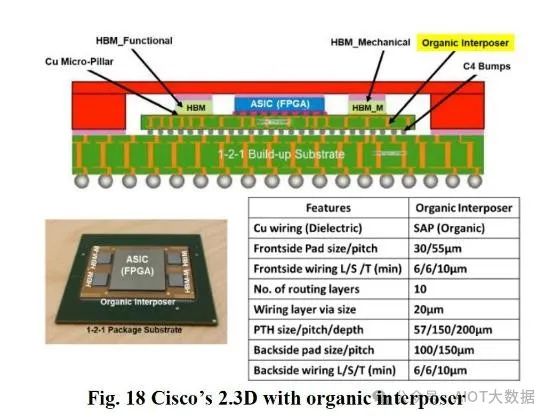
此外,非扇出威廉希尔官方网站 也在不断改进。思科已经展示了与无芯有机基板相关的研究。制造这种有机中介层的主要制造步骤与积层封装基板相同,只是没有铜芯。与带芯的标准积层 ABF 基板相比,思科展示了 10 个布线层,其 L/S 密度更高。

如今,积层 ABF 基板的 L/S 密度高达 10 微米;思科的研究表明,有机基板的 L/S 可降至 6 微米。核心扇出市场的 L/S 在 15 微米范围内。一些先进的扇出,例如AMD 的 RDNA 3 GPU和联发科网络处理器,可降至 2 微米 L/S。EMIB 在第一代中达到 5 微米 L/S,据传未来几代将达到 2 微米 L/S。
随着 ABF 基板的改进,核心扇出和 HD 扇出市场在移动应用之外逐渐受到蚕食。关于介电材料,光成像介电材料 (PID) 目前能够达到更细的间距。尽管如此,ABF 在表面变化方面仍具有许多优势,正如 Unimicron 所展示的那样。
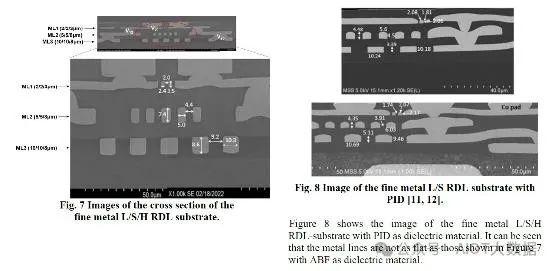
Unimicorn 希望坚持使用改进的 ABF,因为这是他们的核心竞争力。细间距无芯 ABF 坚持其现有的业务模式,即提供已知良好的(混合)基板。它们可以实现 3 微米 L/S,表面变化更好,从而可以扩展到更高的层数。他们的无芯 ABF 基板可能与当前先进的扇出工艺非常有竞争力。它是在面板上完成的,因此与晶圆级相比具有竞争力,并且接近未来的面板扇出工艺。虽然它仅限于 3 个 RDL 层,但扩展到更多层的路径比扇出 RDL 更容易。
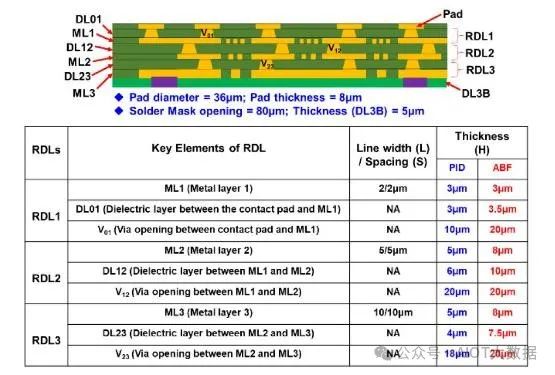
无芯 ABF 基板较厚,这对于移动应用来说可能是一个问题,但对于高性能应用来说,可靠性和性能应该更好。
在追求 L/S 时,Amkor SLIM 和 ASE SPIL NTI 可以实现 0.4 微米和 0.5 微米。两者都仅限于第一层上的这些精细间距。
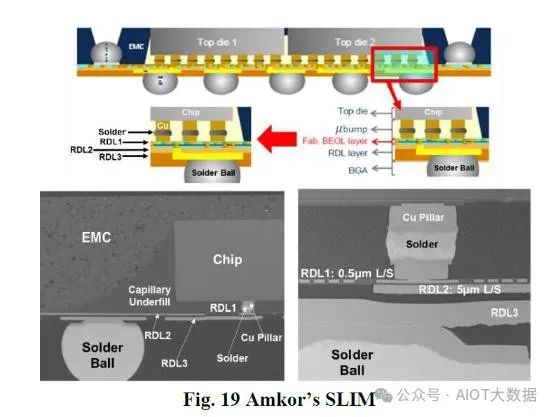
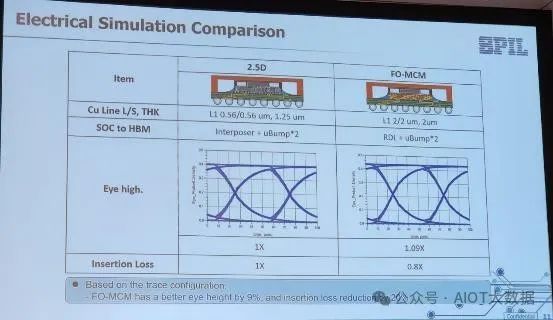
ASE SPIL 表示,其扇出型 RDL 的性能优于 2.5D 高级封装,可用于将 HBM芯片连接到 SOC。ASE SPIL 声称其眼高更佳,损耗减少更少,从而允许更高的信号速率和更低的噪声通过封装。
虽然积层 ABF 基板仍将是先进封装市场的基础,但随着向无芯基板的过渡,它们的性能和密度正在提高。此外,这些基于 ABF 的基板可以达到更高的层数,正如思科所展示的那样,这要归功于 Unimicron 所展示的卓越表面变化特性。在许多用例中,ABF 基板正在赶上并超越扇出型 RDL。
随着 RDL 扇出工艺逐渐进入之前仅由 2.5D 中介层占据的应用领域,成本和产量也是至关重要的因素。采用硅桥的扇出工艺开始逐渐普及,但无需使用硅桥即可将 ASIC 与 HBM 集成的新工艺也即将投入生产。扇出工艺和 ABF 基板方面的这些进步正在迅速模糊先进封装之间的界限。
在评估 2.1D 至 2.5D 领域的先进 IC 封装时,需要考虑多个变量。焊盘间距、L/S 和层数是重要因素,但可靠性、翘曲问题、封装成本、产量和封装尺寸也在考虑范围内。未来,在标准积层 ABF 基板顶部封装无芯 ABF 基板的混合基板可能是某些用例的最佳选择。在其他情况下,在标准积层 ABF 基板顶部封装芯片优先扇出 RDL 可能是另一种用例的最佳选择。随着芯片数量和类型的异构集成多样性,封装所涉及的权衡变得越来越难以评估。
混合键合工艺流程 – 先进封装第五部分
BESI、EV Group、AMAT、TEL、ASMPT、SET、芝浦、SUSS Microtec
混合键合将成为自 EUV 以来半导体制造领域最具变革性的创新。事实上,它对设计流程的影响甚至比 EUV 本身更大,从封装架构到单元设计和布局。IP 生态系统将发生巨大变化,制造流程也将如此。2D 晶体管缩小的时代将继续,但速度会有所放缓,而混合键合将带来一个新时代,芯片设计师将以 3D 思维思考。
随着这首充满炒作的歌谣的结束,我们应该注意到,将混合键合大规模推向市场面临着许多重大的工程和威廉希尔官方网站 挑战,因为目前它只限于少数 AMD 芯片、CMOS 图像传感器和一些供应商的3D NAND。这种转变将重塑供应变化和设计流程。
我们将从基础开始讲解混合键合的高级方面,包括工艺流程、工具、设计用例、挑战、晶圆芯片与晶圆芯片的成本。我们还将介绍我们专有的采用模型,该模型涵盖了各个市场(移动设备、客户端 PC、数据中心 CPU、AI 加速器、HBM 等)的使用情况、工具要求和数量,以及到 2020 年末的公司级采用情况。
在封装史上,上一次重大的范式转变是从引线接合到倒装芯片。从那时起,更先进的封装形式(如晶圆级扇出和 TCB)一直是同一核心原理的渐进式改进。这些封装方法都使用某种带焊料的凸块作为硅片与封装或电路板之间的互连。这些威廉希尔官方网站 可以一直缩小到约 20 微米间距。
到目前为止,我们在多部分先进封装系列中讨论的主要封装类型和工艺流程都是 220 微米到 100 微米规模,并且主要使用焊料作为各种芯片铜互连之间的介质。要进一步扩大规模,需要进行另一种范式转变:采用混合键合的无凸块互连。混合键合的规模超过 10 微米互连间距,并计划向 100 纳米级别发展,并且不使用任何具有更高电阻的中间体,例如焊料。
相反,不同芯片或晶圆之间的互连直接通过铜通孔连接。直接铜连接意味着在向各个芯片发送数据时电阻会大大降低,因此功耗也会降低。再加上连接数量的数量级增加,设计需要彻底重新思考。
回顾第 1 部分,先进封装的重点是什么?我们可以看到,封装威廉希尔官方网站 的进步旨在实现更高的互连密度(单位面积上更多的互连),减少走线长度以降低延迟和每比特传输的能量。我们可以看到混合键合如何解决这两个问题:显著缩短走线长度,因此延迟尽可能低,而无需在芯片上,在某些情况下比芯片上的全局舍入更短,并且互连间距可以远低于 10 微米以增加密度。
混合键合到底是什么?
混合键合用于芯片的垂直(或 3D)堆叠。混合键合的显著特点是无凸块。它摒弃了基于焊料的凸块威廉希尔官方网站 ,转而采用直接铜对铜连接。这意味着顶部芯片和底部芯片彼此齐平。两个芯片都只有铜垫,而不是凸块,可以缩小到超细间距。没有焊料,因此避免了与焊料相关的问题。

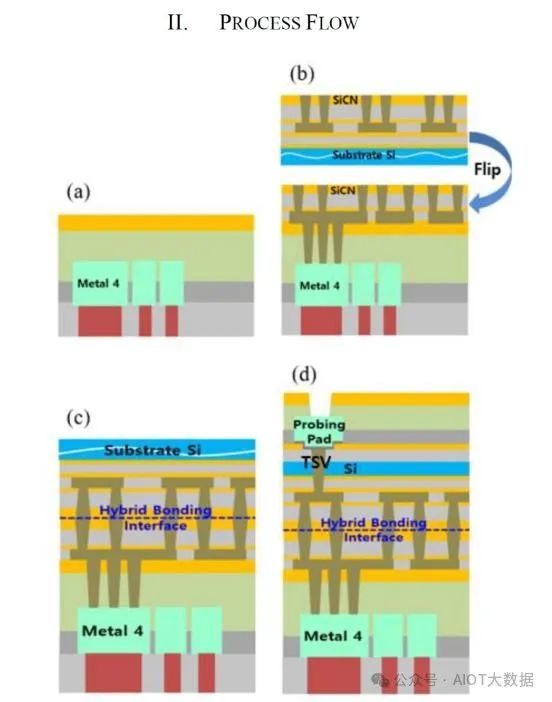
从上图中,我们可以看到 AMD 3D V-Cache 的横截面,它采用了台积电的 SoIC-X 芯片到晶圆混合键合。顶部和底部硅之间的键合界面是混合键合层,位于硅芯片的金属层顶部。混合键合层是一种电介质(现在最常见的是 SiO 或 SiCN),上面有铜垫和通孔,间距通常小于 10 微米。
电介质的作用是隔离每个焊盘,使焊盘之间不会发生信号干扰。铜焊盘通过硅通孔 (TSV) 连接到芯片金属层。TSV 需要将电源和信号传输到堆栈中的另一个芯片。由于底部芯片“面朝下”放置,因此需要这些通孔连接顶部芯片上的金属层,穿过晶体管层到达底部芯片上的金属层。
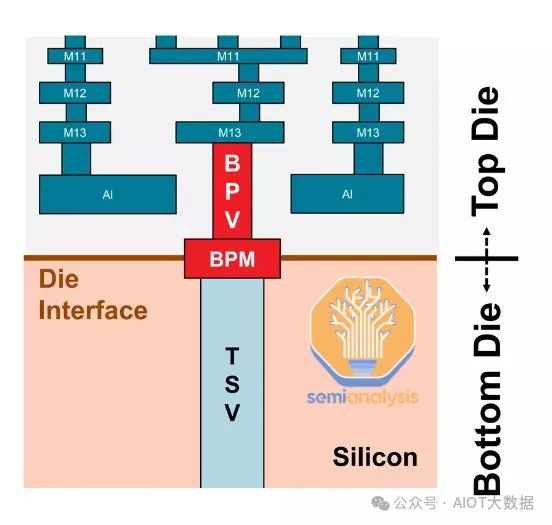
信号正是通过这些铜垫来实现芯片间通信。之所以称之为“混合”键合,是因为它是电介质-电介质键合和直接铜-铜键合的组合。键合界面之间无需使用额外的粘合剂或材料。
关键工艺条件
与以前的基于凸点的互连相比,引入了一系列全新的威廉希尔官方网站 和工艺挑战。为了实现高质量的键合,对表面光滑度、清洁度和键合对准精度有非常严格的要求。我们将首先描述其中一些挑战,因为工艺流程是围绕缓解这些挑战而设计的。记住这些将帮助您更好地理解流程为何如此,以及不同方法的优缺点。
颗粒和清洁度
在任何有关混合键合的讨论中,都会提到颗粒。这是因为颗粒是混合键合中产量的敌人。由于混合键合涉及将两个非常光滑和平坦的表面齐平地粘合在一起,因此键合界面对任何颗粒的存在都非常敏感。
仅 1 微米高的颗粒就会导致直径为 10 毫米的键合空隙,从而导致键合缺陷。对于基于凸块的互连,由于使用了底部填充或非导电膜,因此设备和基板之间总会存在间隙,而间隙可以容忍一些颗粒。
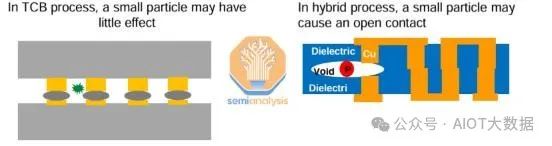
保持清洁至关重要,而且非常具有挑战性。晶圆切割、研磨和抛光等许多步骤都会产生颗粒。任何类型的摩擦也会产生颗粒,这是一个问题,尤其是因为混合键合涉及机械拾取芯片并将其放置在其他芯片之上。来自芯片键合头和芯片翻转器的工具中有很多运动。颗粒是不可避免的,但有几种威廉希尔官方网站 可以减轻产量影响。
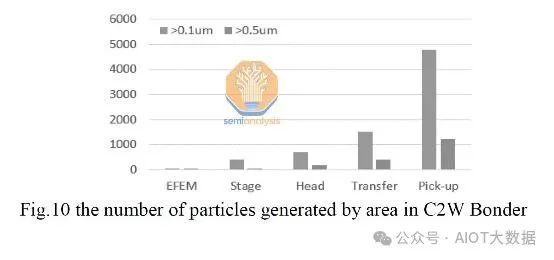
当然,晶圆清洗是定期进行的,以去除污染物。然而,清洗并不完美,无法一次性去除 100% 的污染物,因此最好从一开始就避免污染物。混合键合所需的洁净室比其他形式的先进封装所需的洁净室先进得多。
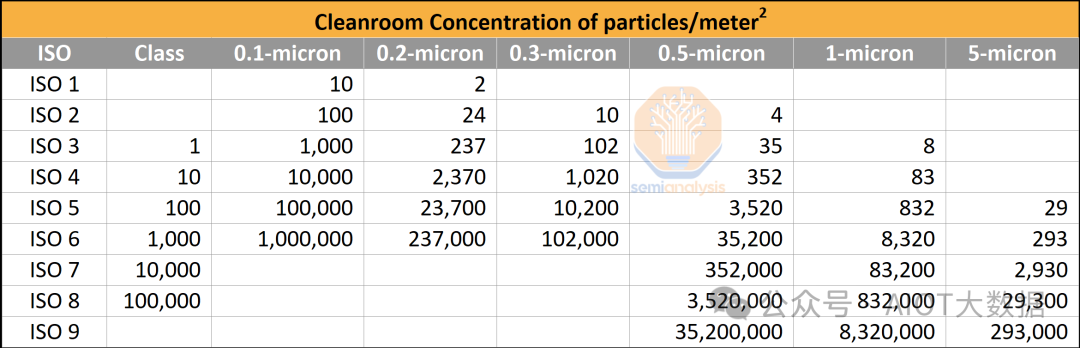
因此,混合键合通常需要 1 级 / ISO 3 级或更高级别的洁净室和设备。例如,台积电和英特尔正在全力实现 ISO 2 级或 ISO 1 级。这是混合键合被视为“前端”工艺的一个主要原因,即它发生在类似于晶圆厂的环境中,而不是传统封装厂商(OSAT)的环境中。鉴于清洁度要求的升级,OSAT 很难进行混合键合。如果 OSAT 想要参与混合键合,大多数 OSAT 都需要建造更新、更先进的洁净室,而台积电和英特尔等公司可以使用较旧的晶圆厂或按照与现有晶圆厂类似的标准建造。
混合键合的工艺流程还涉及许多传统上仅由晶圆厂独家使用的工具。 ASE 和 Amkor 等外包装配和测试公司 (OSAT) 在化学气相沉积 (CVD)、蚀刻、物理气相沉积 (PVD)、电化学沉积 (ECD)、化学机械平坦化 (CMP) 和表面处理/活化方面的经验相对较少。
清洁度要求和工具增加导致成本大幅增加。与其他形式的封装相比,混合键合工艺并不便宜。我们将在下面介绍工艺流程。
平滑度
混合键合层的表面光滑度也极其关键。HB 界面同样对任何类型的表面形状都很敏感,这会导致空洞和无效键合。一般来说,电介质的表面粗糙度阈值为 0.5nm,铜垫的表面粗糙度阈值为 1nm。为了达到这种光滑度,需要进行化学机械平坦化 (CMP),这是混合键合的关键工艺。
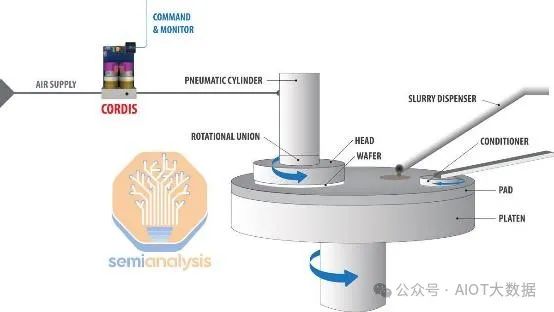
抛光后,整个流程都需要保持这种光滑度。应避免任何可能损坏该表面的步骤,例如粗暴清洗。甚至晶圆分类探测也需要进行调整,以免损坏表面。
晶圆到晶圆 (W2W) 或芯片到晶圆 (D2W)
首先,讨论一下 W2W 或 D2W。混合键合可以通过晶圆对晶圆 (W2W) 或芯片对晶圆 (W2W) 工艺完成。W2W 意味着将两个制造好的晶圆直接键合在一起。W2W 提供更高的对准精度、产量和键合良率。鉴于其相对容易,目前绝大多数混合键合都是通过 W2W 完成的。
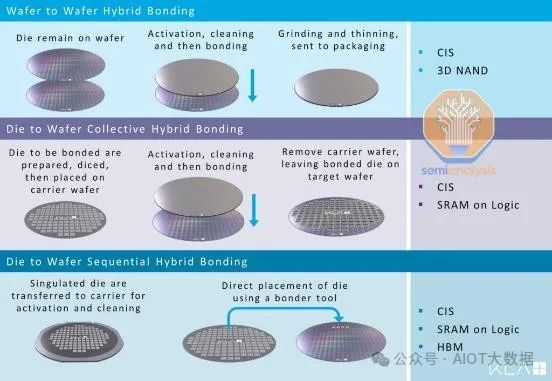
W2W 键合良率更高的原因是对准和键合步骤是分开的。在 W2W 工具中,有一个单独的腔室用于执行对准。一旦顶部和底部晶圆对准,它们就会被移入键合腔室(处于真空中),在那里用一点力将它们压在一起,大约 20 分钟后,初始预键合就形成了。
W2W 的关键在于它是一种更清洁的工艺,步骤更少。在对准和键合之前,可以清洁晶圆以去除大部分颗粒。芯片分离(颗粒污染源)仅在键合后发生。由于它是晶圆级工艺,因此对准步骤也有更多的时间,因此更长的对准时间不会像芯片级工艺那样损害产量。
腔内也没有太多移动,因此腔内污染物较少。目前,W2W 键合机可以实现 50nm 以下的对准精度。W2W 键合已经是一种成熟的工艺,而且成本并不高。证据是,我们看到它在大众市场产品中得到广泛采用,例如 3 层图像传感器和 NAND。
W2W 键合很棒,但一个主要限制是无法进行晶圆分类以选择已知良好芯片 (KGD)。这会导致不良结果,即有缺陷的芯片与良好芯片键合,从而浪费优质硅片。
鉴于此,W2W 用于良率较高的晶圆,这通常意味着较小的设计。在下图中,我们可以看到 W2W 和 D2W 的芯片面积与成本之间的关系。晶圆尺寸越小,W2W 越便宜,因为晶圆良率会更高。然而,随着晶圆尺寸的增大,W2W 成本曲线会变得更加陡峭,这主要是由丢失的良品晶圆的成本所致。随着芯片尺寸的增大,每个晶圆的良品晶圆比例会减少,从而导致有缺陷的晶圆和良品晶圆的结合更多。

我们可以看到,W2W 用于具有高产量的较小芯片:CMOS 图像传感器、3D NAND,以及到目前为止仅用于Graphcore Bow IPU的逻辑。
虽然 Graphcore Bow IPU 是一款更大的 HPC 芯片,但顶部芯片不是前沿逻辑,而是用于供电的无源电容芯片,因此其良率应该相当高,而且硅片更便宜。W2W 的另一个缺点是顶部芯片和底部芯片的尺寸必须一致,因此这限制了异构集成选项的灵活性。
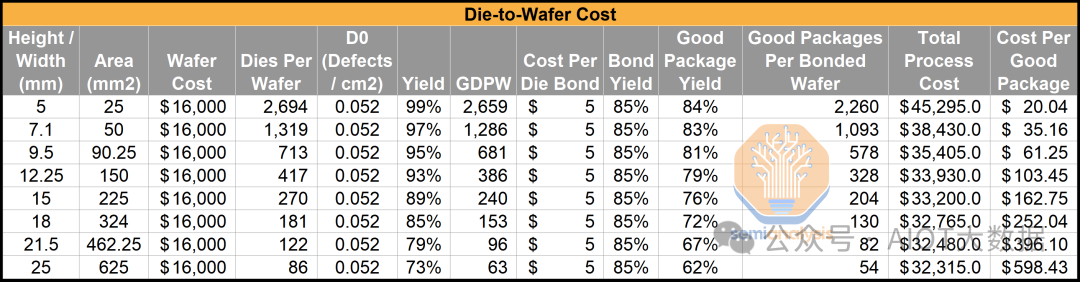
成本有多种影响因素。主要因素包括晶圆成本、D0(缺陷密度)和键合良率。每个因素都可能导致成本增加或降低。请注意,这些是示例数字,用于强调这一点。请勿使用下表,因为它未显示键合的实际成本。如需了解当今产品的实际成本,请联系我们获取 AMD MI300X 成本报告或 Zen 3、Zen 4 和 Zen 5 混合键合成本报告。
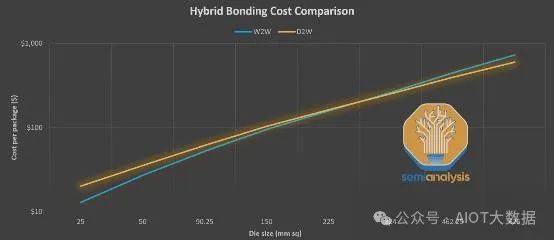
可以看出,D2W 在小型芯片上的成本更高,但对于大型芯片,情况则相反。W2W 更昂贵。能够测试和粘合已知良好芯片 (KGD),而不是冒着缺陷堆积和浪费良好硅片的风险,这一点至关重要,这也是为什么晶圆上芯片 (D2W) 是第一个实现产品化的方法。它可以处理较差的产量,但仍具有商业上可行的产品。
为了突破限制,我们需要采用 D2W。D2W 键合更具挑战性。在完成晶圆分类后,KGD 从顶部晶圆分离出来,并通过拾取和放置工具单独附着到底部晶圆上。这在键合方面更具挑战性,因为每个晶圆需要更多键合步骤。这些额外的步骤会引入更多的颗粒污染,尤其是来自芯片分离和拾取和放置过程中键合头的移动。
D2W 可以是一个“集体”过程,其中 KGD 被对准并首先临时键合到重构的载体晶圆上。然后将重构的载体晶圆键合到基片上进行实际预键合。这是为了像 W2W 一样将对准和键合分开,并允许在最终预键合之前进行清洁步骤以去除任何已积累的污染物。缺点是涉及额外的步骤,额外的 W2W 键合步骤会增加对准误差的可能性。
这实际上是一个简化的流程,因为底部芯片也可以在载体晶圆上重建。因此,顶部和底部芯片都是从原始硅晶圆上切割下来的,并对 KGD 进行分类。两组芯片都粘合到各自载体上的精确位置。然后,使用 W2W 工艺将 2 个载体晶圆粘合。这是在 TSMC SOIC 中完成的。因此,每个 AMD 3D V 缓存芯片(底部 CPU 芯片到载体、3D V 缓存芯片到载体、2x 虚拟硅到载体)和晶圆对晶圆使用 5 个粘合步骤。
重构工艺还可用于更极端的异构集成选项。英特尔在 IEDM 2022 上展示了“准单片芯片 (QMC)”。他们展示的 QMC 应用的一个例子是顶部和底部各有 2 个异质集成芯片的封装。对于顶部和底部,每个芯片都连接到载体晶圆上。然后用厚无机氧化物(如 SiO2)模制晶圆。进行 W2W 键合。然后将模制的芯片单片化并连接到封装基板上以完成流程。
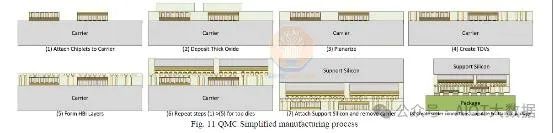
请注意,重建的区域内可能存在 TSV。
直接 D2W 键合是将单个芯片直接放置在目标晶圆上进行预键合。直接 D2W 不太成熟,但由于流程简化,似乎未来直接 D2W 会得到更多使用。集体 D2W 的一个好处是可以进行清洁,然后直接送入对准室以减少污染。最近推出了 D2W 集群工具(将在下文讨论),它可以重现这种流程,从而降低这种集体过程的好处。此外,由于对准变得更具挑战性,D2W 更适合更细的焊盘间距,因此消除 W2W 步骤是有好处的,因为 W2W 步骤会在 W2W 步骤中引入额外的错位风险。
鉴于 D2W 混合键合的工艺挑战和成本,目前的应用有限。AMD 是 2022 年的首批采用者,并且至今仍是唯一采用者。我们将在稍后讨论未来的应用、各公司的采用率、工艺步骤数量等。
需要注意的一点是,W2W 在对准方面远远领先于 D2W,因此如果您的设计不是异质的,并且晶圆良率足够高,那么它实际上将是一种更精确、良率更高的工艺。这种更精细的间距还将解锁许多 D2W 尚未突破的新用例。
混合键合工艺流程
接下来让我们更详细地了解 D2W 和 W2W 的流程。

TSV 形成
正如我们上面提到的,TSV 需要为封装中的所有芯片提供电源和信号。想象一下传统的倒装芯片封装。芯片只需要一侧的互连即可接收电源并与封装基板进行数据通信。该互连层具有连接到无源布线层(也称为“金属层”或“线路后端”/BEOL)的凸块,这些凸块为切换和处理数据的晶体管层提供电源和信号。
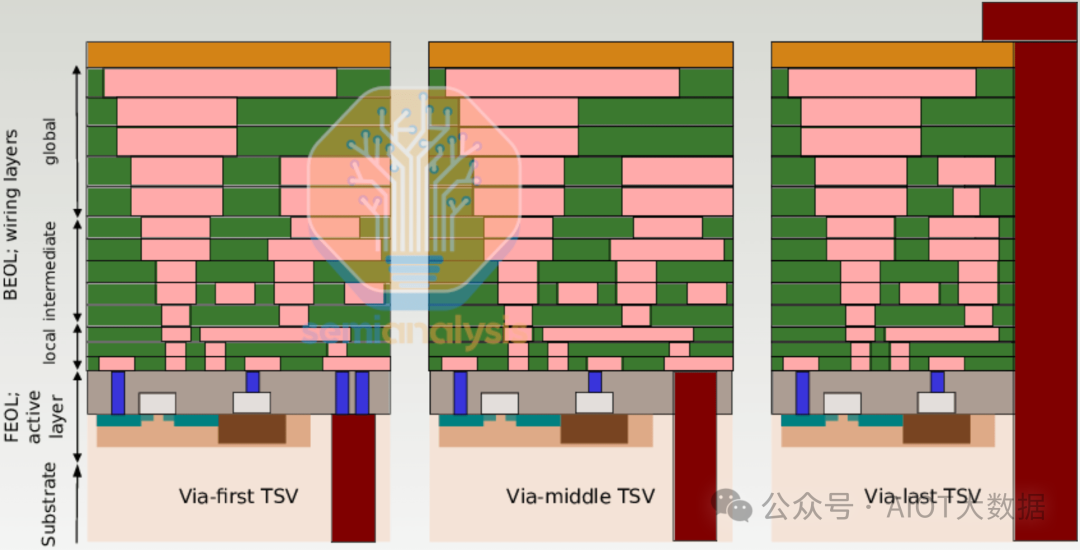
对于 3DIC,底部的芯片需要能够与其下方的封装基板以及其上方的芯片进行通信,因此芯片的两侧都需要互连。这就是 TSV 发挥作用的地方。TSV 有多种变体,具体取决于它们在流程中的制造时间。TSV 可以是“先通孔”的,即在晶体管层之前先在硅片中制造;“中通孔”的,即在晶体管层完成后、金属层之前制造;或“后通孔”的,即在 BEOL 之后。
对于 3DIC 来说最常见的是“中间通孔”方法,因为 TSV 运行在金属层之间,穿过晶体管层并显露出芯片的背面,这样现在芯片两侧都有一层互连,我们将对此进行描述。
我们在这里讨论了 TSV 流程,但将在本报告中重新进行概括。
晶圆上涂有光刻胶,然后使用光刻威廉希尔官方网站 进行图案化。然后,使用深反应离子蚀刻 (DRIE) 将 TSV 蚀刻到硅中,以在晶圆深处形成高纵横比沟槽,但不会穿透整个晶圆。使用化学气相沉积 (CVD) 沉积绝缘层 (SiOX、SiNx) 和阻挡层 (Ti 或 Ta)。这些层用于防止铜扩散到硅中。然后,使用物理气相沉积 (PVD) 沉积铜种子层。该种子层沉积在沟槽中,然后使用电化学沉积 (ECD) 填充沟槽。这形成了 TSV。但是,该过程尚未完成,因为背面的通孔尚未露出。为了露出 TSV,TSV 的背面被抛光,在某些情况下还被蚀刻以减薄背面并随后露出 TSV。完成后,晶圆可以继续形成 BEOL。
TSV 的形成并非易事,而且可能非常耗时,尤其是由于需要深度蚀刻。我们了解到,TSV 的形成是 HBM 和 CoWoS 生产的瓶颈。一些客户从硅中介层转向 CoWoS-R 的原因之一是为了避免硅中介层中昂贵的 TSV 工艺。
混合键层形成
在晶圆的键合界面之后,在晶圆的 BEOL 顶部制造混合键合层。无论是 W2W 还是 D2W,这都是相同的。这是一层用细间距铜通孔图案化的介电膜。电介质,通常是碳氮化硅 (SiCN),通过 PECVD 沉积。然后形成焊盘。使用光刻威廉希尔官方网站 对铜焊盘的孔进行图案化并蚀刻掉。沉积阻挡层和种子层,然后使用典型的铜镶嵌工艺镀铜。
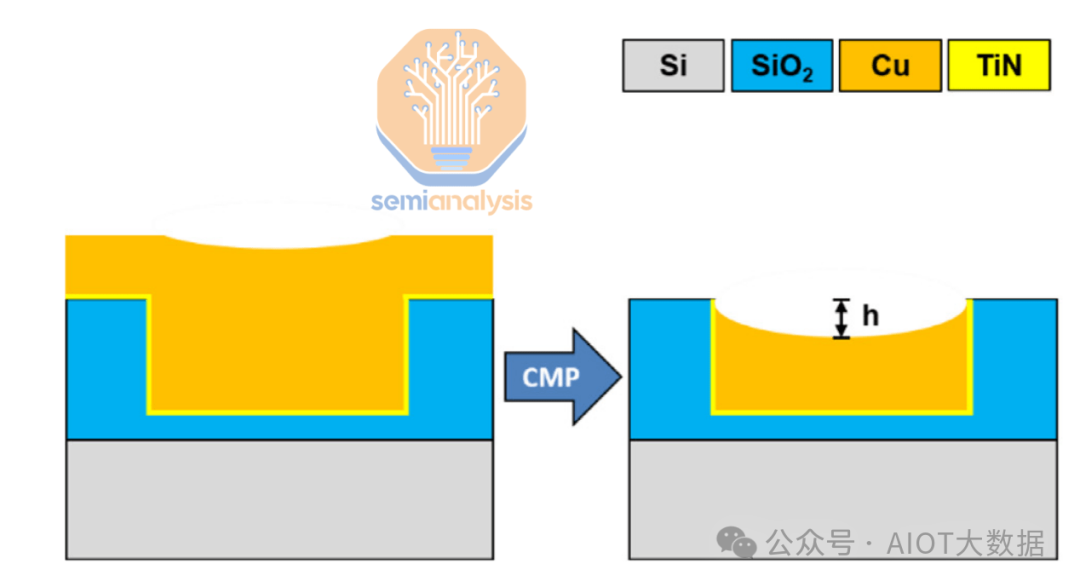
然后,进行 CMP 步骤以研磨和平滑电介质表面,并获得正确的铜轮廓。铜垫的一个显着特点是它们凹陷至约 1 微米间距。如前所述,光滑的表面对于形成良好的粘合至关重要。电介质的粗糙度必须控制在 0.5nm 以内,铜垫的粗糙度必须控制在 1nm 以内。
HB 接口的一个特点是铜垫最初凹进介电层下方约 5 纳米。这是为了确保在退火过程中铜不会妨碍初始介电层-介电层键合。如果铜凹进得太深,则 Cu-Cu 键合可能无法正常形成。
在对铜和其他金属进行 CMP 时,由于过度抛光以及金属和电介质的软度不同,经常会出现凹陷。虽然这不是理想情况,但这种现象并不严重,可以解决。需要控制凹陷的确切轮廓,以防止在粘合过程中出现铜过度生长/不足的情况。
为了获得正确的凹陷轮廓,需要结合低和高 Cu 去除浆料的多个 CMP 步骤。CMP 是混合键合实现非常光滑的表面和最佳轮廓的关键工艺。
在 ECTC 上,索尼展示了当间距减小到 1 微米时,让铜突出比让铜凹进效果更好。
晶圆分类/分离
仅对于 D2W,执行晶圆分类,并将 KGD 单独化并在载体晶圆或胶带框架上重组,以便进一步处理。如上所述,HB 为传统晶圆分类过程带来了新的复杂性。晶圆分类涉及用探针探测晶圆凸块或焊盘以进行电气测试。
探测会在铜焊盘表面造成少量损坏,从而破坏 CMP 工艺过程中表面的光滑度。虽然对焊盘的损坏很小,在大多数情况下通常可以接受,但 HB 对少量地形变化非常敏感,因为这些变化会影响键合质量。解决此问题的一种方法是在初始 CMP 中对此进行补偿,然后进行另一轮 CMP 后探测以抛光探测造成的任何损坏。
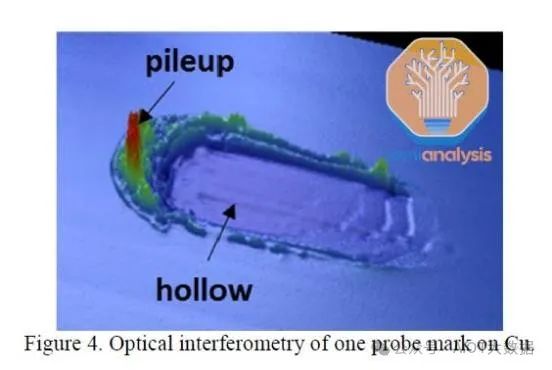
对于单片化/切割,一个问题是工艺中产生的颗粒。刀片切割通常不使用,因为它最脏:会产生大量颗粒并造成大量产量损失。激光切割和等离子切割比刀片切割更受欢迎,因为它们是更清洁的工艺,但仍会产生颗粒物。等离子切割是最极端的方法,其机制类似于蚀刻掉分隔芯片的划线。然而,考虑到蚀刻整个晶圆所需的时间,这种方法的产量要低得多。

Disco 是这个领域的领导者。自从我们报道他们以来,他们的股票已经上涨了两倍多。
一种缓解威廉希尔官方网站 是首先在晶圆上涂上一层保护层涂层。颗粒落在保护层上,可以在剥离保护层时与保护层一起被去除。虽然这有助于解决分割过程中的颗粒问题,但可能会有保护层的残留物,剥离过程也可能对 HB 层造成一些表面损坏,从而增加表面粗糙度。
等离子活化和清洁:
现在对 2 片晶圆进行处理,为粘合做好准备。它们用 N2 等离子体处理以激活表面。等离子体处理改变了表面的特性,增加了表面能,使其更加亲水。使两个表面都更加亲水可以使表面促进氢键。这有助于实现下一步在室温下发生的初始弱电介质-电介质预粘合。
处理后,进行最后的清洁以去除任何累积的颗粒。在键合之前,重要的是,传入的晶圆应尽可能干净。清洁需要彻底,但也不能损坏,以保持 HB 界面的完整性。最好的方法似乎是使用去离子水基清洁,辅以超声波。使用洗涤器或等离子清洁可能会造成太大的损害和/或引入污染物。
粘合
现在开始键合步骤。更准确地说,它更像是“预键合”,因为此步骤仅形成初始电介质-电介质键,而这只是一种弱范德华键。我们将分别介绍 W2W 和 D2W 方法的流程。
W2W 键合
使 W2W 键合良率更高的原因是对准和键合步骤是分开的。首先是对准步骤。W2W 对准有多种威廉希尔官方网站 。过去,人们会使用红外扫描仪来检查两个晶圆之间的对准。限制在于一个晶圆必须对红外线透明。这对 CMOS 晶圆不起作用,因为红外线无法穿透金属层。
EVG 在 W2W 键合领域占据主导地位,拥有其专利的 SmartView 对准威廉希尔官方网站 。有 2 个摄像头相互校准,一个放在目标晶圆上方,一个放在下方。固定顶部晶圆的卡盘移动,以便底部摄像头可以识别对准标记,并且系统记录对准标记的位置。顶部晶圆缩回,然后底部晶圆在摄像头之间移动,直到顶部摄像头可以识别对准标记。对准器现在可以通过计算 2 个对准标记的相对位置来对准 2 个晶圆。为了帮助保持准确性和控制力,晶圆彼此非常接近(50 微米以内),并且卡盘仅在 X 和 Y 平面上移动,Z 轴(垂直)没有移动,直到预键合。
对准后,将晶圆移入键合室,在那里以较小的压力将它们压在一起,持续约 20 分钟以形成初始键合。
粘合后检查可通过声学方法在现场完成,如果对准不充分,则也可重新粘合。
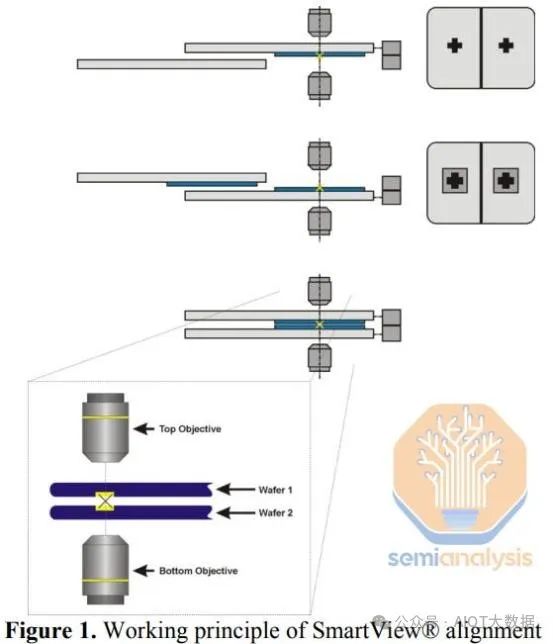
在 W2W 工具中,有一个单独的腔室用于执行对准。一旦顶部和底部晶圆对准,它们就会被移入键合腔室(处于真空中),在那里用一点力将它们压在一起,大约 20 分钟后,初始预键合就形成了。W2W 的关键在于它是一个更清洁的工艺,因为步骤更少。在对准和键合之前,可以清洁晶圆以去除大部分颗粒。芯片分离是颗粒污染的来源,仅在键合之后发生。
由于这是晶圆级工艺,因此对准步骤也有更多的时间,因此较长的对准时间不会像芯片级工艺那样对产量造成太大影响。腔内也没有太多移动,因此腔内产生的污染物较少。目前,W2W 键合机可以实现50nm 以下的对准精度。W2W 键合已经是一种成熟的工艺,而且成本并不高。证据是,我们看到它被广泛应用于大众市场产品中,例如索尼、Omnivison 和三星的图像传感器,以及长江存储、西部数据和铠侠的 NAND。
D2W 粘合
D2W 粘合是通过拾取和放置工具完成的。
底部目标晶圆位于晶圆夹盘上。要粘合的芯片面朝上放置在胶带框架上。翻转臂收集单个芯片并将其翻转,使芯片背面朝上放置在翻转器上。上方有一个粘合臂,它使用粘合头上的真空吸力拾取翻转的芯片。
CoWoS-S(主要变体)的关键制造步骤
CoWoS 是台积电的一项“2.5D”封装威廉希尔官方网站 ,其中多个有源硅片(通常的配置是逻辑和 HBM 堆栈)集成在无源硅片中介层上。中介层充当顶部有源芯片的通信层。然后将中介层和有源硅片连接到包含 I/O 的基板上,以放置在系统 PCB 上。CoWoS是 GPU 和 AI 加速器最流行的封装威廉希尔官方网站 ,因为它是共同封装 HBM 和逻辑以获得最佳训练和推理工作负载性能的主要方法。
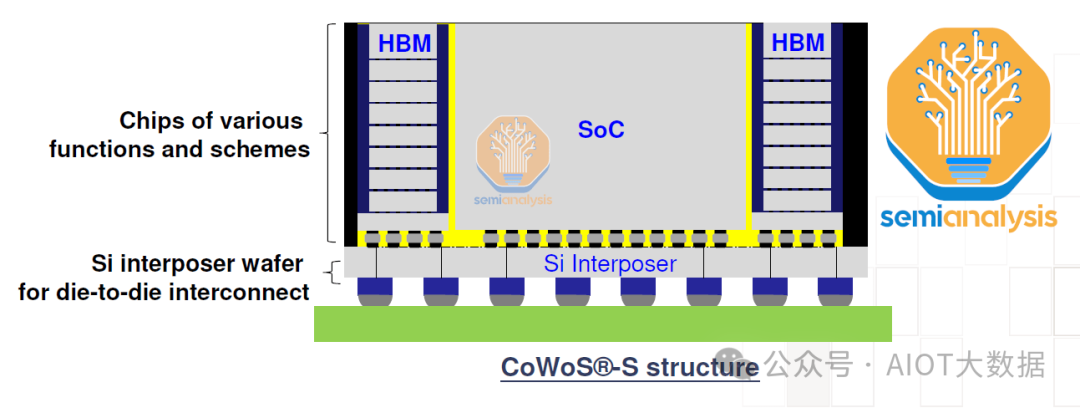
我们现在将详细介绍 CoWoS-S(主要变体)的关键制造步骤。
硅中介层关键工艺步骤
第一部分是制造硅中介层,其中包含连接芯片的“线路”。这种硅中介层的制造类似于传统的前端晶圆制造。人们经常声称硅中介层是采用 65nm 工艺威廉希尔官方网站 制造的,但这并不准确。CoWoS 中介层中没有晶体管,只有金属层,可以说与金属层间距相似,但事实并非如此。
这就是为什么 2.5D 封装通常由领先的代工厂内部完成,因为他们可以生产硅中介层,同时还可以直接使用尖端硅。虽然 ASE 和 Amkor 等其他 OSAT 已经完成了类似于 CoWoS 或 FOEB 等替代方案的先进封装,但他们必须从 UMC 等代工厂采购硅中介层/桥接器。
硅中介层的制造始于取一块空白硅晶圆并制作硅通孔 (TSV)。这些 TSV 穿过晶圆以提供垂直电气连接,从而实现中介层顶部的有源硅片(逻辑和 HBM)与封装底部的 PCB 基板之间的通信。这些 TSV 是芯片向外界发送 I/O 的方式,也是芯片接收电源的方式。
为了形成 TSV,需要将光刻胶涂在晶圆上,然后使用光刻威廉希尔官方网站 进行图案化。然后使用深反应离子蚀刻 (DRIE) 将 TSV 蚀刻到硅中,以实现高纵横比蚀刻。使用化学气相沉积 (CVD) 沉积绝缘层 (SiOX、SiNx) 和阻挡层 (Ti 或 TA)。然后使用物理气相沉积 (PVD) 沉积铜种子层。然后使用电化学沉积 (ECD) 用铜填充沟槽以形成 TSV。通孔不穿过整个晶圆。
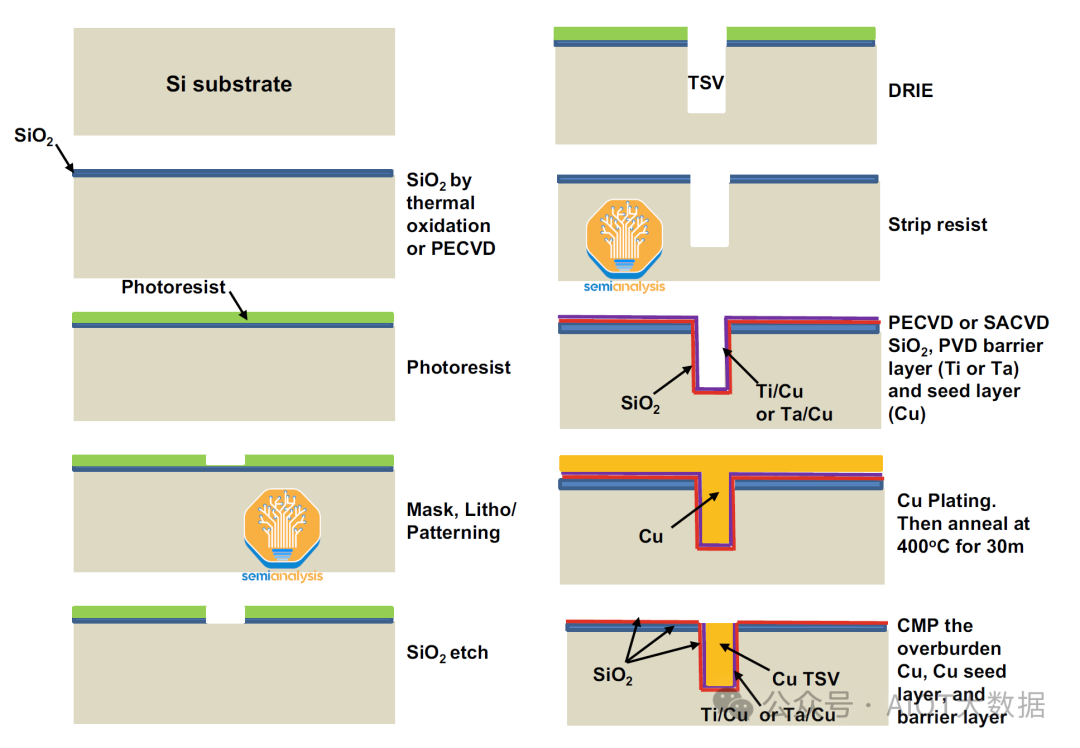
TSV 制造完成后,在晶圆的顶部形成重分布层 (RDL)。将 RDL 视为将各种有源芯片连接在一起的多层线路。每个 RDL 都由一个较小的通孔和实际的 RDL 组成。
通过 PECVD 沉积二氧化硅 (SiO2),然后涂上光刻胶,使用光刻威廉希尔官方网站 对 RDL 进行图案化,然后使用反应离子蚀刻去除 RDL 通孔的二氧化硅。此过程重复多次,以在顶部形成更大的 RDL 层。
在典型的配方中,钛和铜被溅射,铜则使用电化学沉积 (ECD) 进行沉积。然而,我们认为台积电使用极低 k 电介质(可能是 SiCOH)而不是 SiO2 来降低电容。然后使用 CMP 去除晶圆上多余的镀层金属。这主要是标准的双镶嵌工艺。对于每个额外的 RDL,都会重复这些步骤。

在顶部 RDL 层上,通过溅射铜形成凸块下金属化 (UBM) 焊盘。涂上光刻胶,用光刻威廉希尔官方网站 曝光以形成铜柱图案。对铜柱进行电镀,然后用焊料覆盖。剥离光刻胶并蚀刻掉多余的 UBM 层。UBM 和随后的铜柱是芯片与硅中介层连接的方式。
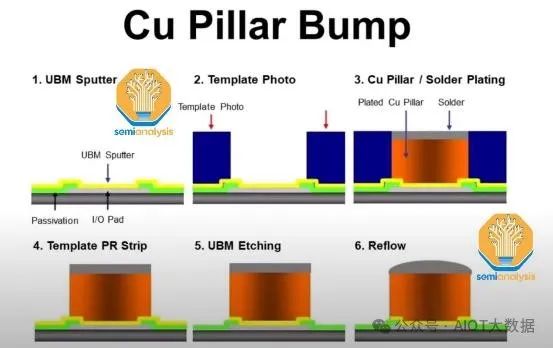
晶圆上芯片关键工艺步骤
现在,使用传统的倒装芯片回流焊工艺将已知良好的逻辑和 HBM 芯片连接到中介层晶圆上。在中介层上涂上助焊剂。然后,倒装芯片接合器将芯片放置在中介层晶圆的焊盘上。然后将放置了所有芯片的晶圆放入回流焊炉中烘烤,使凸块焊料和焊盘之间的连接固化。清除多余的助焊剂残留物。
然后用树脂填充有源芯片和中介层之间的缝隙,以保护微凸块免受机械应力。然后再次烘烤晶圆以固化底部填充物。
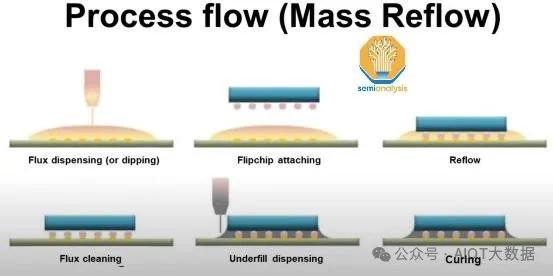
接下来,用树脂模制顶部芯片以将其封装起来,并使用 CMP 来平滑表面并去除多余的树脂。现在将模制的中介层翻转并通过研磨和抛光减薄至约 100um 厚度,以露出中介层背面的 TSV。
附着在中介晶圆顶部的顶部芯片和封装尽管变薄了,但仍可以为晶圆提供足够的结构支撑和稳定性,因此并不总是需要载体晶圆来支撑。
晶圆基板关键工艺步骤
中介层背面镀上 C4 焊料凸块,然后切割成每个单独的封装。然后使用倒装芯片将每个中介层芯片再次安装到积层封装基板上,以完成封装。
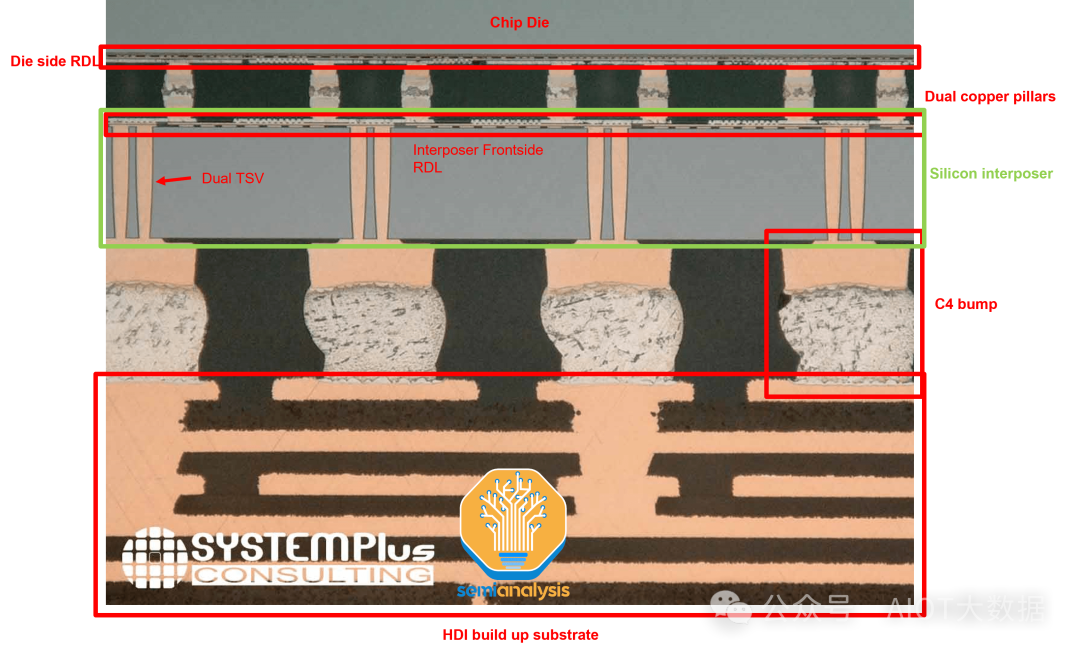
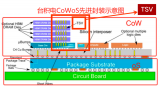
在下面的 Nvidia A100 横截面中,我们可以看到 CoWoS 封装的所有各种元素。
顶部是带有 RDL 的芯片芯片和铜柱微凸块,这些微凸块与硅中介层正面的微凸块粘合在一起。然后是顶部带有 RDL 的硅中介层。我们可以看到 TSV 穿过中介层,下面每个 C4 凸块有 2 个 TSV。底部是封装基板。
请注意,A100 在中介层正面只有一面 RDL。A100 的架构更简单,只有内存和 GPU,因此布线要求更简单。MI300由内存、CPU 和 GPU 组成,全部位于 AID 之上,因此需要更复杂的 CoWoS 布线,从而影响成本和产量。
先进封装的各大玩家的威廉希尔官方网站 发展路线图
台积电的 CoWoS-R+、台积电的第四代 SoIC(3 微米间距混合键合)、英特尔和 CEA-LETI 自对准集体芯片到晶圆混合键合、三星对单片、MCM、2.5D、3D 的研究(包括混合键合)、将在 DRAM 中商业化的 SK 海力士晶圆上晶圆混合键合、ASE 的共封装光学先进封装、思科共封装光学、Xperi 超薄芯片处理、东京电子晶圆上晶圆混合键合晶圆处理、索尼 1 微米混合键合、AMD Zen 3 上的 V-Cache 混合键合以及联发科 InFO-oS 网络 SOC 可靠性。
台积电的 CoWoS-R+
正如我们在高级封装入门系列中所讨论的那样,CoWoS 是一种芯片后封装威廉希尔官方网站 。CoWoS 通常通过将有源硅片放置在无源硅中介层之上来实现,但这样做成本相当高。因此,台积电开发了 CoWoS-R,它使用带有 RDL 层的有机基板,这是一种更便宜的威廉希尔官方网站 。CoWoS-R 尚未上市,但一些产品即将上市。我们知道的第一款此类产品来自 AMD,将在仅限订阅者的部分中进行讨论,包括其系统架构。坦率地说,它真是太棒了。
台积电并没有止步于 CoWoS R,CoWoS-R+ 也在这项威廉希尔官方网站 的基础上不断发展。
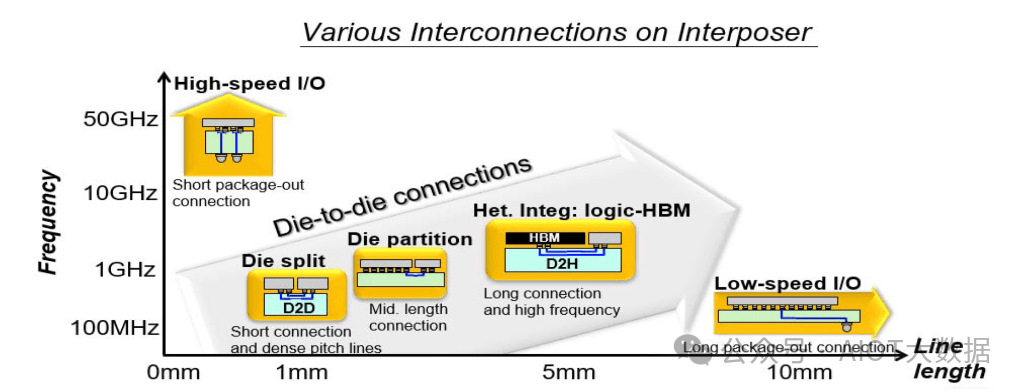
要理解的关键概念之一是芯片到芯片的连接距离。HBM 目前是将内存带宽提高到 AI 和高性能计算合理水平的唯一方法。这方面的进步迅速,最初的 HBM 为每焊盘 1Gbps,而随着 HBM2 的出现,这一速度迅速增长到 2.4Gbps,随着 HBM2E 的出现,这一速度增长到 3.2Gbps。HBM3 的速度将一路增长到 6.4Gbps。封装宽度也从 HBM2 的 7.8 毫米增加到 HBM2E 的 10 毫米,再到 11 毫米,这意味着互连长度现在增长到大约 5.5。
简单来说,电线需要传输更快的数据速率,同时还要传输更长的距离。这是非常困难的,而且会产生很大的噪音,从而降低信号完整性。另一个问题是,随着摩尔定律的放缓与日益增长的性能需求相冲突,芯片的功率正在爆炸式增长。Nvidia 的 Hopper 已经有 700W,但未来封装将膨胀到千瓦范围。HBM3 也比 HBM2E 更耗电。通过封装的更多功率也可能产生更多噪音,从而降低信号完整性。台积电已经开发出一种新的高密度 IPD 来解决这个问题。简而言之,台积电客户可以在 CoWoS R+ 上实现 6.4Gbps HBM3,但不能在 CoWoS R 上实现。高密度 IPD 对于增加额外的电容以平滑电力传输非常重要。例如,Graphcore 只需使用台积电的 SoIC 混合键合添加大量电容器,便可将时钟频率提高 40%,而无需增加功率,我们在此详细介绍了这一点。
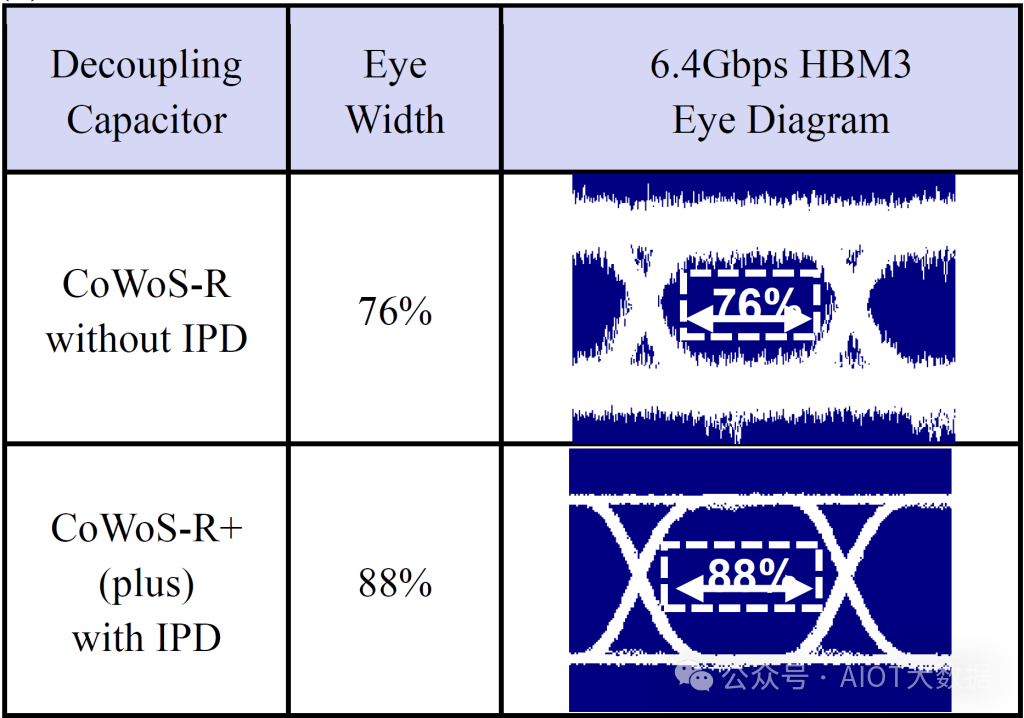
台积电还分享了嵌入式桥接芯片功能的更多进展。桥接芯片和顶部有源芯片之间的互连可以达到 24 微米。台积电现在可以实现 3 倍光罩极限,与 CoWoS-S(全无源硅中介层)相匹配。未来,他们的路线图将光罩尺寸提高到 45 倍,这意味着使用芯片后道工艺的复杂芯片可用于晶圆级封装。与此同时,CoWoS-S 明年才会扩展到 4 倍。
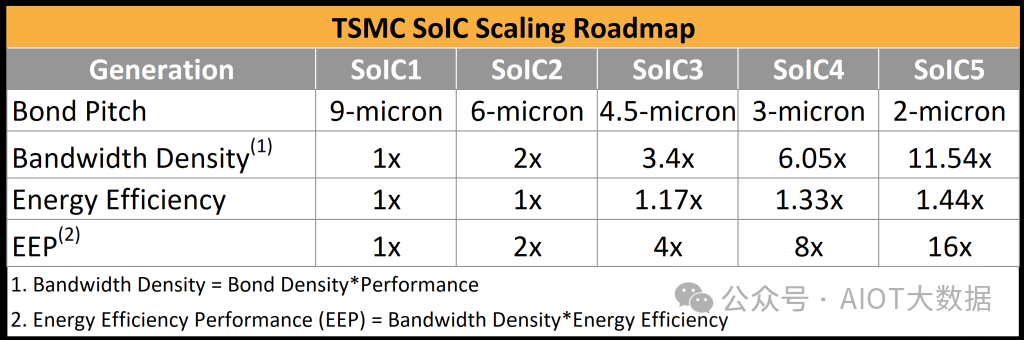
台积电第四代 SoIC 3 微米间距混合键合
台积电展示了其第四代混合键合威廉希尔官方网站 的研究成果,该威廉希尔官方网站 可以实现每平方毫米 100,000 个键合焊盘。鉴于目前只有 AMD 和台积电交付了一款 SoIC 设备,很高兴看到未来取得切实进展。该设备在 17 微米下明显更轻松,而第一代 SoIC 可以达到 9 微米。
台积电的混合键合工艺基本相同。他们从完成的晶圆开始,形成一个新的键合垫层,蚀刻它,沉积种子层,电镀。接下来,他们将顶部芯片晶圆削薄并切割。特别注意保持它们的清洁。进行等离子活化,然后键合芯片。
台积电的论文展示了 SoIC 的良率,这相当有趣。这是在尺寸为 6 毫米 x 6 毫米的测试芯片上使用菊花链测试结构,这恰好与 AMD 的 VCache 芯片尺寸相同。晶圆上芯片混合键合中最慢的步骤之一是当 BESI 工具物理拾取芯片并将其放置在底部晶圆上时。此键合步骤严重受到准确性的影响,而吞吐量与准确性之间的较量是一场非常激烈的较量。台积电采用 3 微米 TSV 间距,展示的良率没有差异,并且在小于 0.5 微米的错位时电阻没有显着变化,键合良率为 98%。从 0.5 微米到 1 微米,他们的结构确实有良率,但菊花链结构的最后 10% 的电阻急剧增加。当间距大于 1 微米时,他们的良率为 60%,所有测量的结构都超过了他们的电阻规格。 0.5 微米是一个非常重要的水平,因为 BESI 声称其 8800 Ultra 工具的精度为 <200 纳米,尽管我们听说它更像是 0.5 微米,并且即使吞吐量只有该工具额定规格的一半,也存在很大的差异。
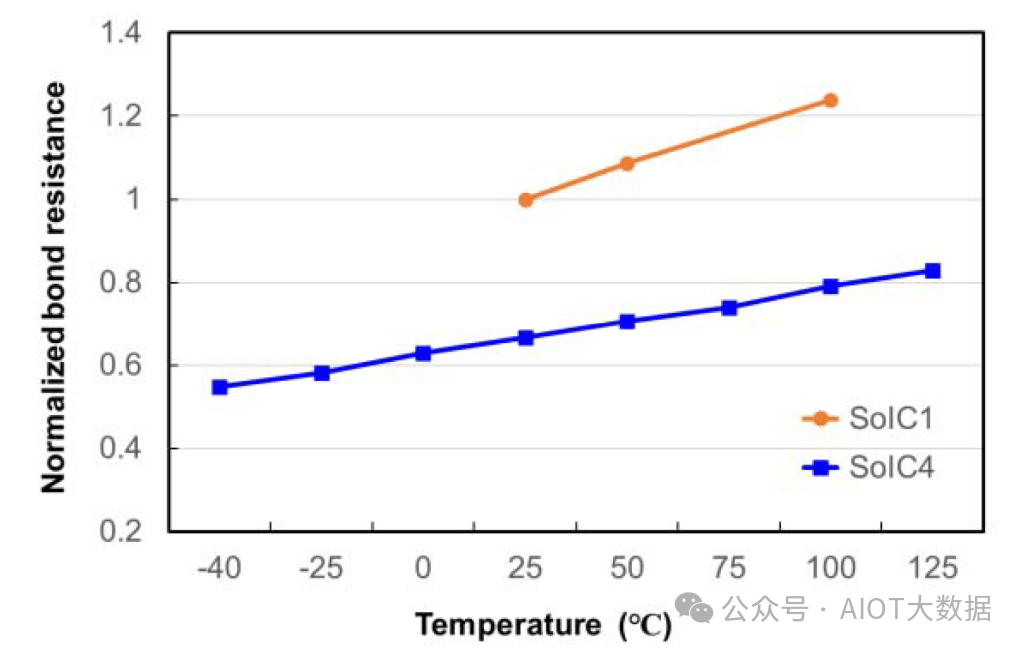
台积电还展示了由于阻隔层更薄,整个堆栈的接触电阻更低。此外,台积电认为 SoIC 更可靠。这包括更广泛的工作温度范围。当 AMD 完全锁定其 5800X3D 台式机芯片的超频和功率修改时,许多人感到失望。这可能只是第一代芯片的一个小问题。随着台积电的铜合金得到改进,并且 SoIC 第四代的间距减小,似乎他们正在提高其可靠性和产量。
英特尔与 CEA-LETI 联合实现芯片到晶圆混合键合
在我们的先进封装系列中,我们将更深入地探讨晶圆上芯片、晶圆上芯片和集体晶圆上芯片键合,包括工具生态系统、成功案例和 TCO,但这里先做一个简短的解释。晶圆上芯片的精确度远低于晶圆上芯片键合。它也慢得多。例如,尽管 Besi 声称每小时可放置 2,000 个芯片,但为了达到 1 微米的精度,吞吐量会下降到每小时放置 1,000 个芯片以下。另一方面,晶圆上芯片键合也存在许多问题,与无法进行异构集成以及无法在键合步骤之前对芯片进行装箱/测试有关。集体晶圆上芯片键合比晶圆上芯片键合具有更高的精确度和吞吐量,同时还提供测试、装箱和实现异构集成的能力。
英特尔和 CEA-LETI 将集体芯片到晶圆与自对准威廉希尔官方网站 相结合,实现了 150nm 的平均错位(比芯片到晶圆更精确),并且吞吐量更高。自对准威廉希尔官方网站 非常酷。他们利用水滴的毛细力使对准更精确,然后经过改进的拾取和放置工具将其快速、不太准确地放置在所需位置。随着水的蒸发,直接键合就形成了,无需任何其他中间材料。然后,键合后的晶圆进入标准退火步骤,以加强键合。
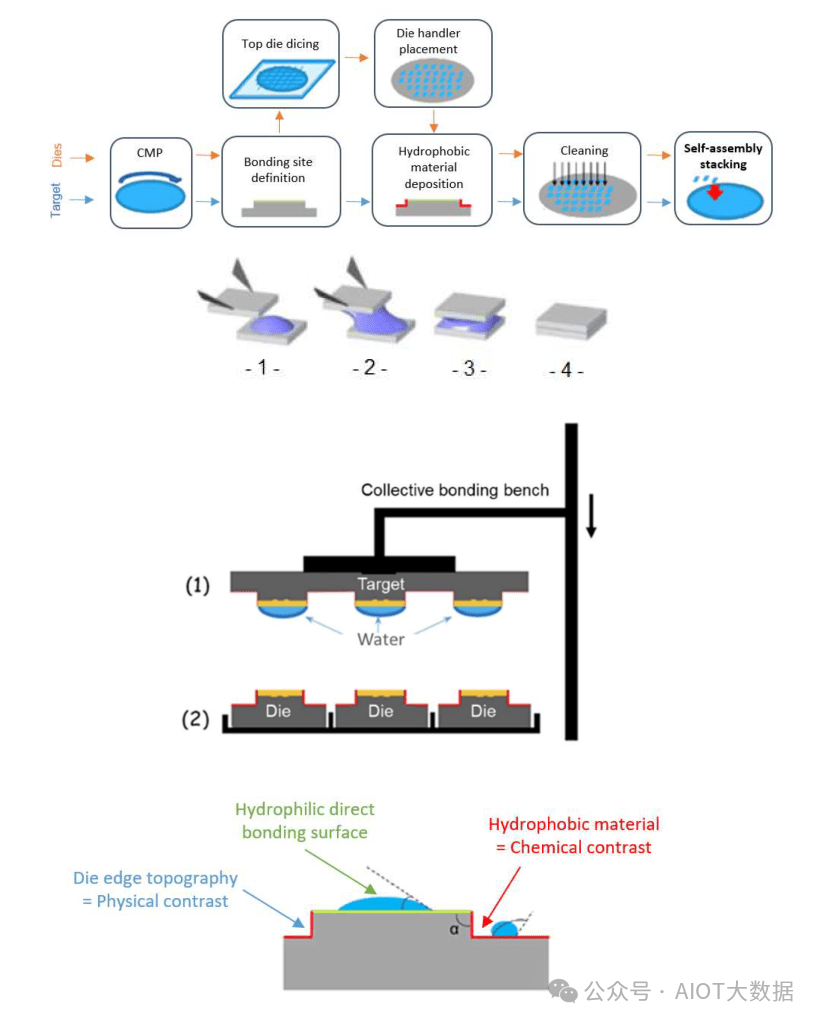
除了水滴沉积之外,唯一独特的步骤是在粘合点处应用亲水和疏水材料,这些材料可以通过光刻定义,精度达到纳米级。这不是一个没有问题的过程。有很多问题与分配水、液滴特性、冷凝和粘合过程有关。英特尔和 CEA-LETI 用 3 个指标展示了结果。收集良率是指被捕获在芯片上的水滴。粘合良率是指成功粘合的芯片数量。对准良率是指具有亚微米精度的芯片数量。
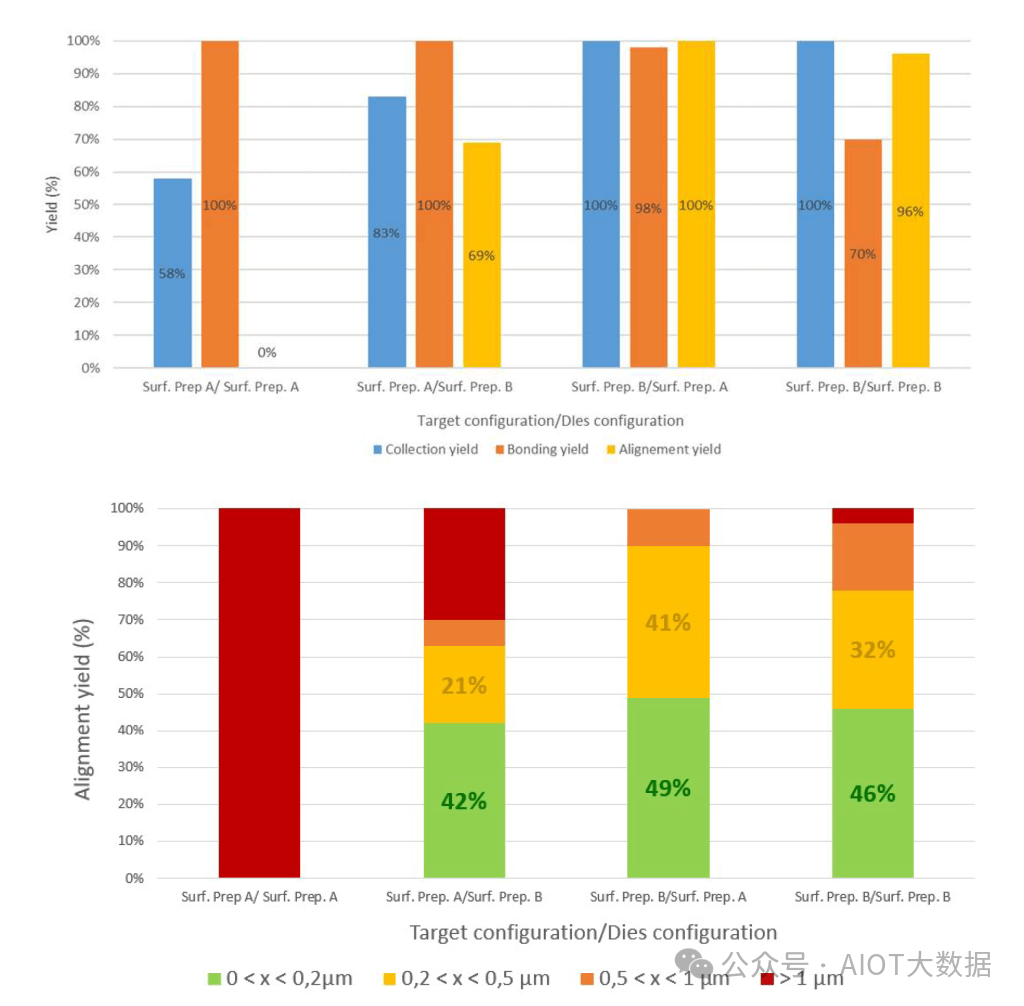
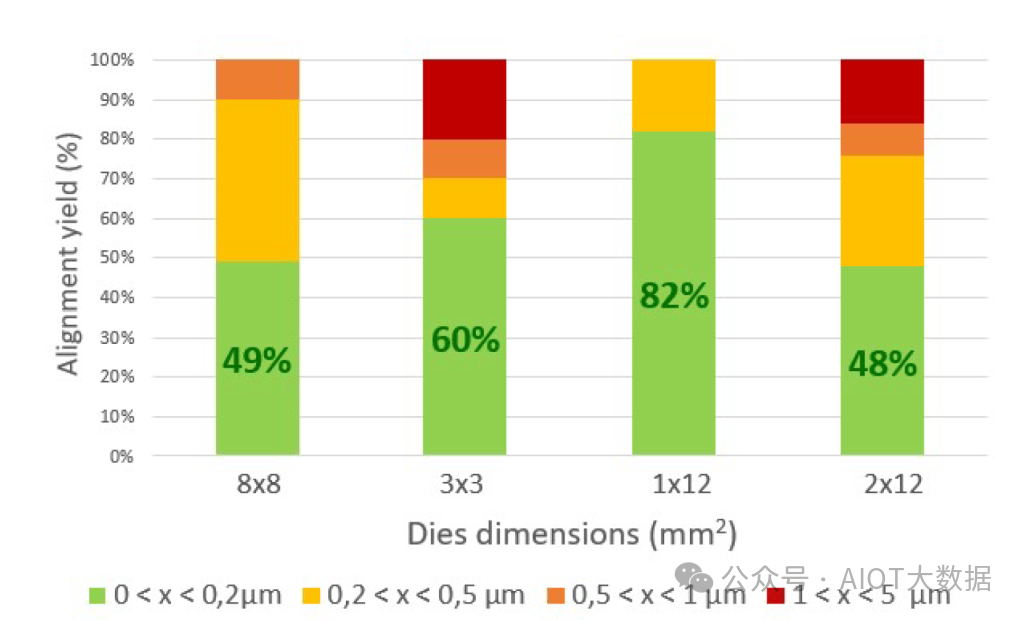
他们尝试了各种工艺,其中最好的工艺在键合时实现了 98% 的良率,在其他步骤中实现了 100% 的良率。总对准精度简直令人惊叹,所有芯片的对准精度都小于 1 微米,大多数芯片的对准精度低于 0.2 微米。英特尔和 CEA-LETI 尝试了多种不同尺寸的芯片,这种工艺在非常高的纵横比芯片上确实大放异彩,非常有趣。
三星单片与 MCM 与 2.5D 与 3D 包括混合键合
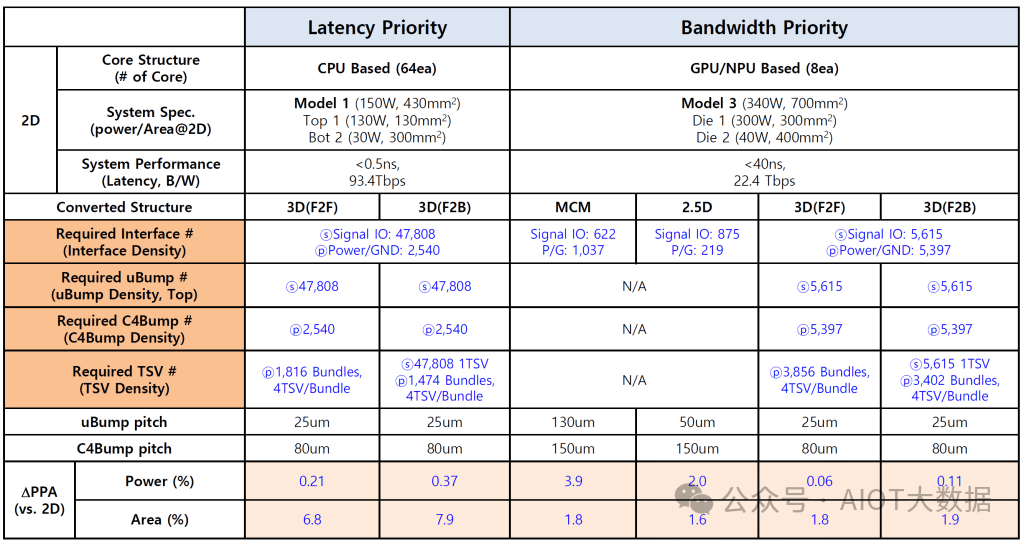
三星在先进封装的面积和功耗成本方面进行了一项非常有趣的研究。他们比较了两种主要设计类型,一种是带宽受限的(HPC/AI),另一种是延迟受限的(CPU)。
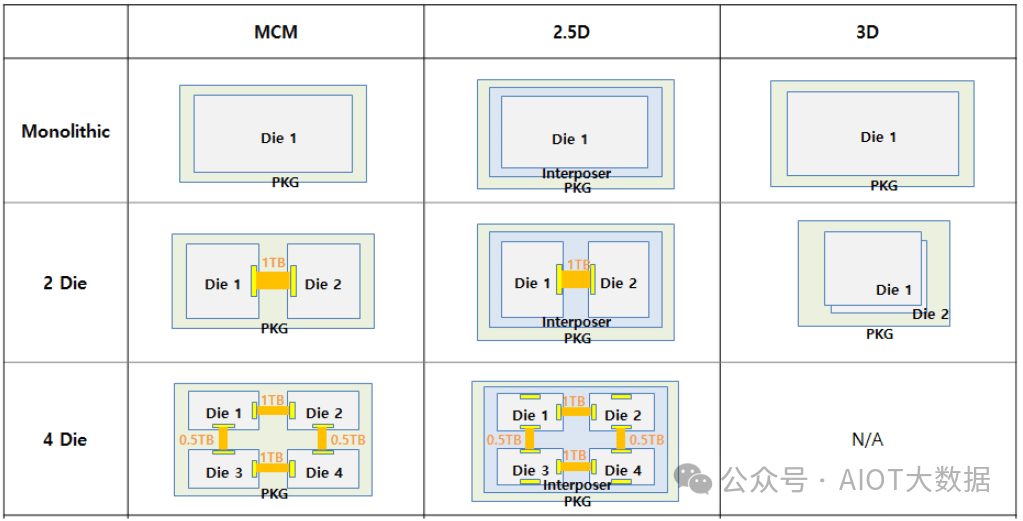
用于 HPC 和 AI 比较的单片 2D 芯片为 450mm2。它被切成薄片并使用先进的封装将其粘合在一起。MCM 变体的功耗增加了 2.1%,芯片面积增加了 5.6%。2.5D 设计的功耗增加了 1.1%,面积增加了 2.4%。3D 设计的功耗增加了 0.04%,但面积增加了 2.4%。这些结果当然是理想的,在现实世界中,与平面图和布局问题相关的开销会更多。
SK Hynix 晶圆上晶圆混合键合 DRAM
SK Hynix 介绍了其晶圆上晶圆混合键合工艺的研究。用于先进封装的晶圆上晶圆键合威廉希尔官方网站 已经非常普遍。索尼、三星和 Omnivison 都在 CMOS 图像传感器中采用了该威廉希尔官方网站 。长江存储的 XStacking威廉希尔官方网站 也将其应用于 NAND Flash 中。Graphcore和台积电也在其 BOW 芯片中采用了该威廉希尔官方网站 。我们独家透露,SKHynix 将在其 16 层 HBM堆栈中使用混合键合。SKHynix 并未直接说明产量,但他们似乎对这项威廉希尔官方网站 的商业化抱有很高的希望。
ASE 共封装光学元件
从威廉希尔官方网站 角度来看,ASE 所展示的内容并不具有开创性,但对投资者的影响却不容小觑。这是因为过去主要的 OSAT 一直远离光网络产品。我们认为,这项研究对 Fabrinet 这样的公司来说并不好,而我们通常都喜欢 Fabrinet。话虽如此,这只是研究,市场动向更为重要。无论如何,如果 ASE 正在研究这一点,他们很可能也会试图获得市场份额。现在来看看 ASE 所展示的内容。
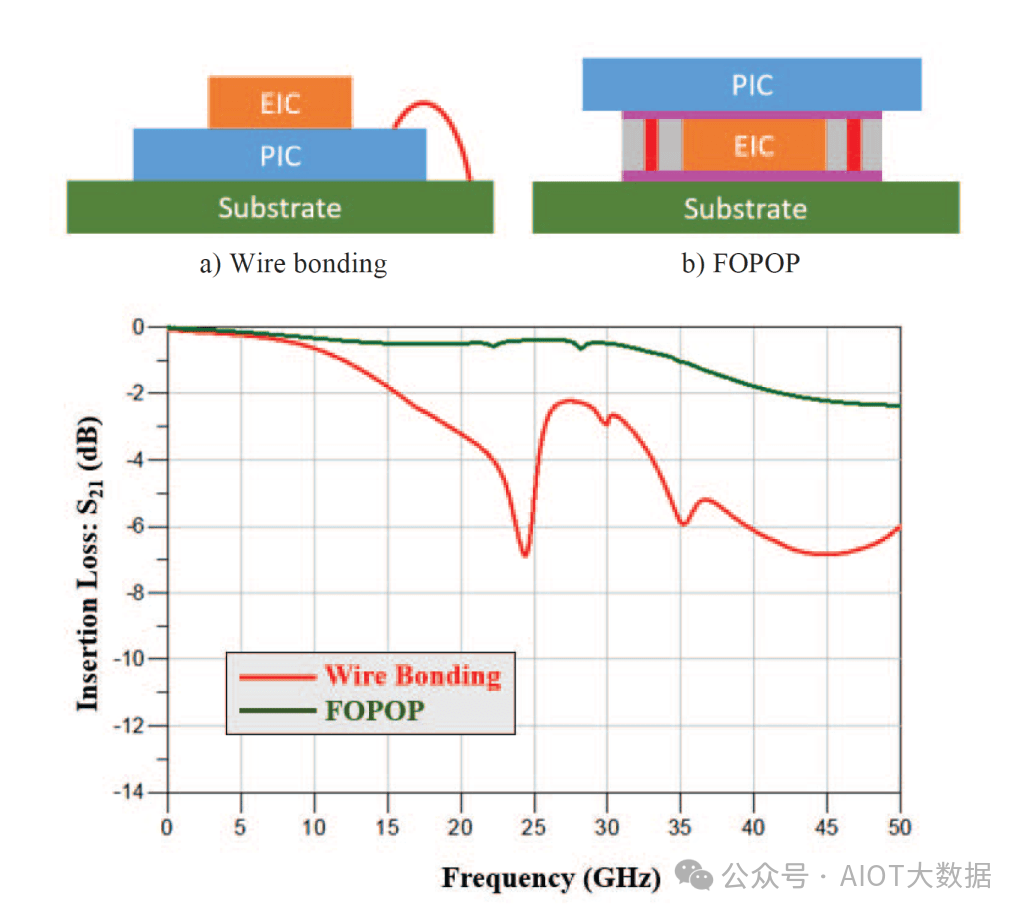
引线接合一直是 100G 代的主要威廉希尔官方网站 ,但随着我们向 400G 和 800G 代过渡,它开始遇到瓶颈。其他公司也已经进行了一段时间的转型,例如英特尔和 Fabrinet 已在最近几代产品中停止了 PIC 和 EIC 的引线接合。思科也已从引线接合转向倒装芯片,今年他们甚至展示了采用 TSV 的 3D 组装,这比 ASE 展示的先进得多。我们将在仅限订阅者的部分讨论思科及其制造合作伙伴。
ASE 的论文总体上讨论了光学制造的独特挑战,包括污染工艺的差异以及所使用的独特切割和蚀刻威廉希尔官方网站 。晶圆制造后的工艺也不同,例如凸块下金属化和硅等。论文还讨论了独特的测试要求。ASE 进入光学制造领域还有很长的路要走,但重要的是要继续关注他们,因为他们是电信和数据中心市场光学组装和封装领域中一个潜在的非常有能力和令人生畏的新进入者。
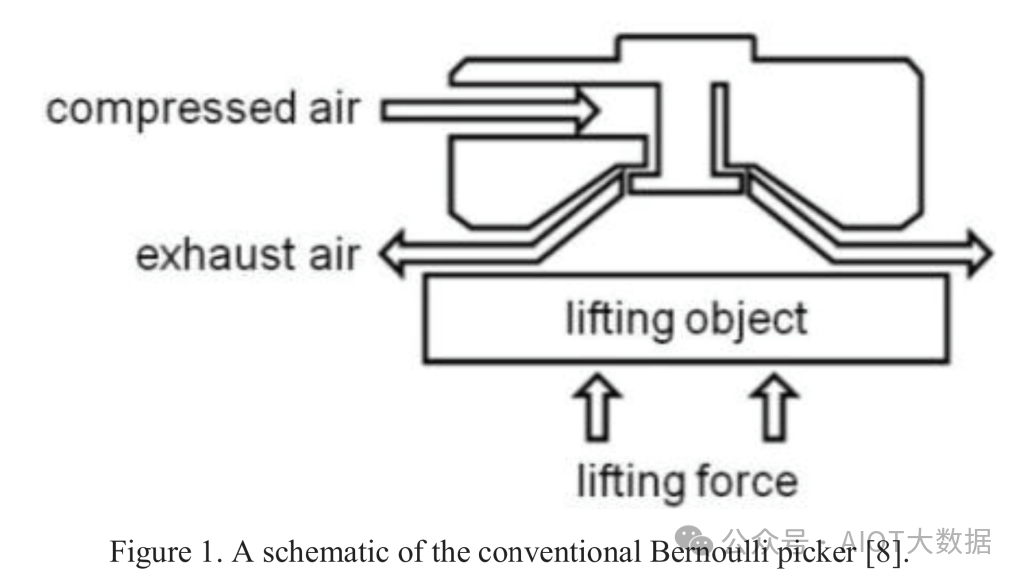
Xperi 超薄模具处理
在大多数混合键合中,芯片必须非常薄。在即将推出的 16 层 HBM 中,芯片厚度甚至可以达到 30 微米,不到人类头发厚度的一半。硅芯片极其脆弱,因此无法正常提起。因此,Xperi 介绍了使用伯努利夹具提起芯片的研究,该夹具使用高速气流和低静压来粘附在物体上而无需物理接触。然后,夹持器将芯片放置在另一个芯片上,精度为 1 微米或更低。该论文详细介绍了芯片翘曲和处理。这里没有什么突破性的进展,但我们只是认为这是一种处理超薄芯片的很酷的机制。
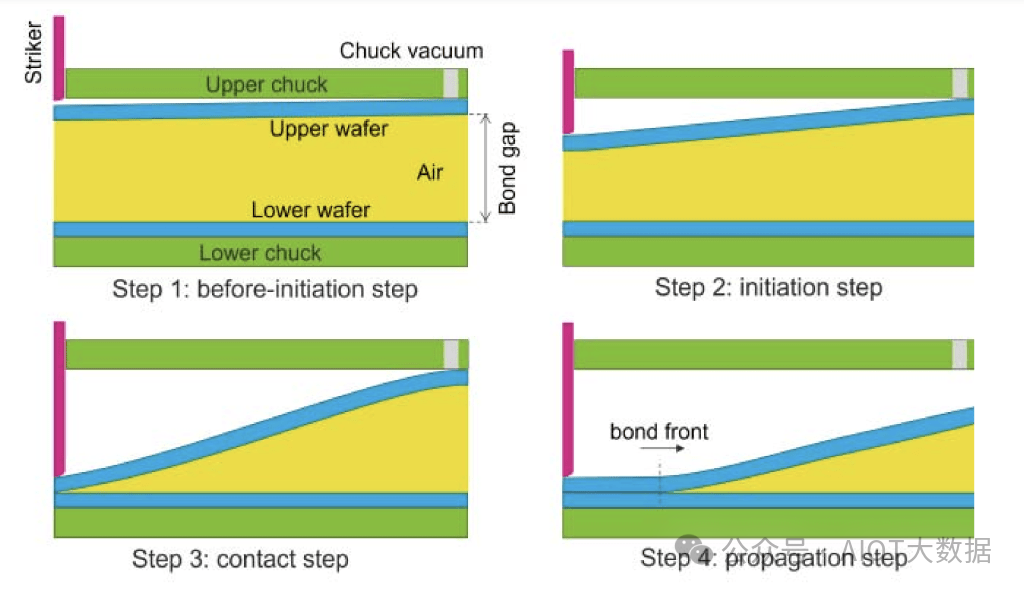
东京电子晶圆上晶圆混合键合
我们独家向我们的订阅者介绍了他们在世界上最大的代工厂取得的一项重大胜利,即他们的晶圆对晶圆混合键合工具和工艺流程。虽然我们不知道这项研究是否会商业化,但我们认为这是另一种有趣的晶圆处理威廉希尔官方网站 。晶圆太薄,所以它很松软,当你把它放低进行键合时,可能会有空气滞留,从而影响产量。东京电子提出了一种避免这种情况的方法。这是研究,而不是他们目前键合工具的工艺。
索尼领先的 1 微米间距混合键合
索尼继续展示他们为何是混合键合领域的领导者。他们于 2017 年首次在大批量产品中推出该威廉希尔官方网站 。他们目前每年出货数百万个 CMOS 图像传感器,这些传感器采用 6.3 微米间距混合键合,堆叠了 3 个芯片,而其他芯片的间距要小得多,产量也小得多。索尼的产量完全是晶圆对晶圆混合键合。今年,索尼展示了 1 微米间距面对面混合键合和 1.4 微米面对面混合键合。索尼目前同时采用面对面和面对面混合键合。
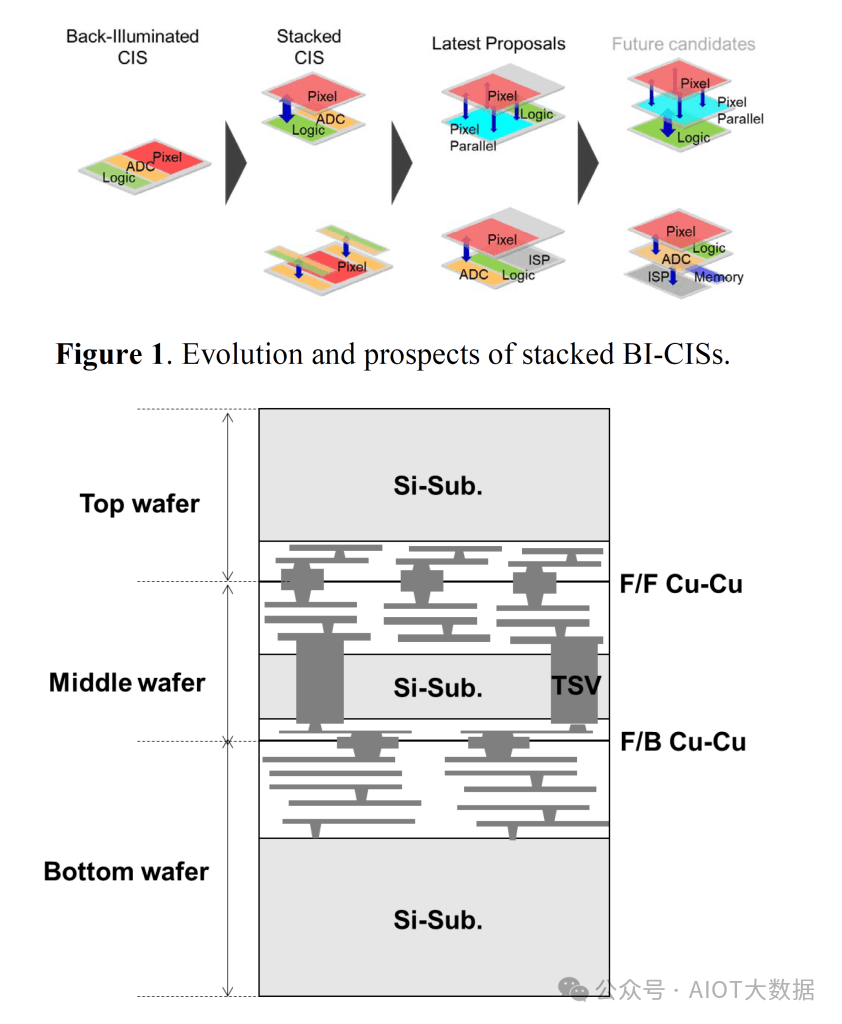
索尼如此积极推进混合键合的简短解释是,索尼希望继续分解和堆叠图像传感器像素的功能,以捕获更多的光线,并能够捕获更多的数据并将其转化为实际的照片和视频。
他们展示的威廉希尔官方网站 非常有趣。所有混合键合工艺都需要非常平坦的表面,但在 CMP 工艺中,铜和 SiO2 的抛光速度不同。在大多数工艺中,这意味着铜的研磨程度低于 SiO2。这通常称为凹陷。必须精确控制该工艺,因为 SiO2 和铜的热膨胀系数也不同。台积电采用的一种威廉希尔官方网站 是使用铜合金代替纯铜来控制凹陷程度,并使 CMP 工艺更容易进行。
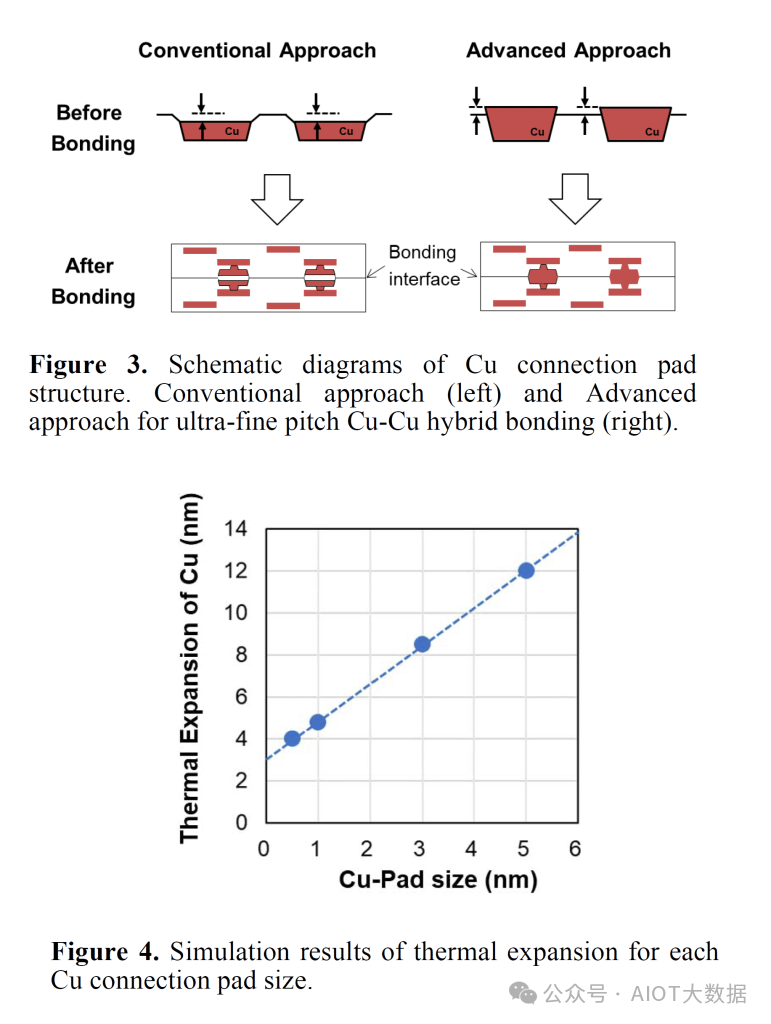
随着索尼的间距比业内其他公司小得多,他们想出了相反的策略。在他们的先进方法中,二氧化硅抛光得比铜抛光得更深。这需要一种完全不同的专有 CMP 工艺。
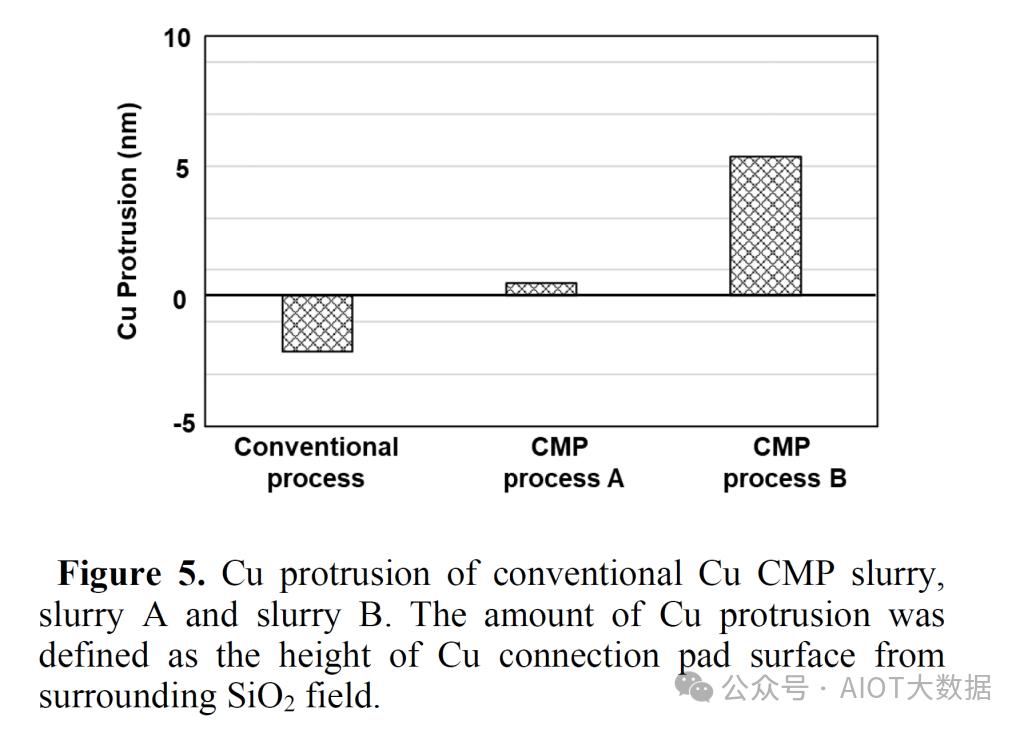
索尼还通过改变 ECD 工艺中的晶粒尺寸实现了类似的铜控制和突出效果。通过我们的消息来源,我们可以在订阅者专区独家详细介绍他们在此工艺中使用的工具。
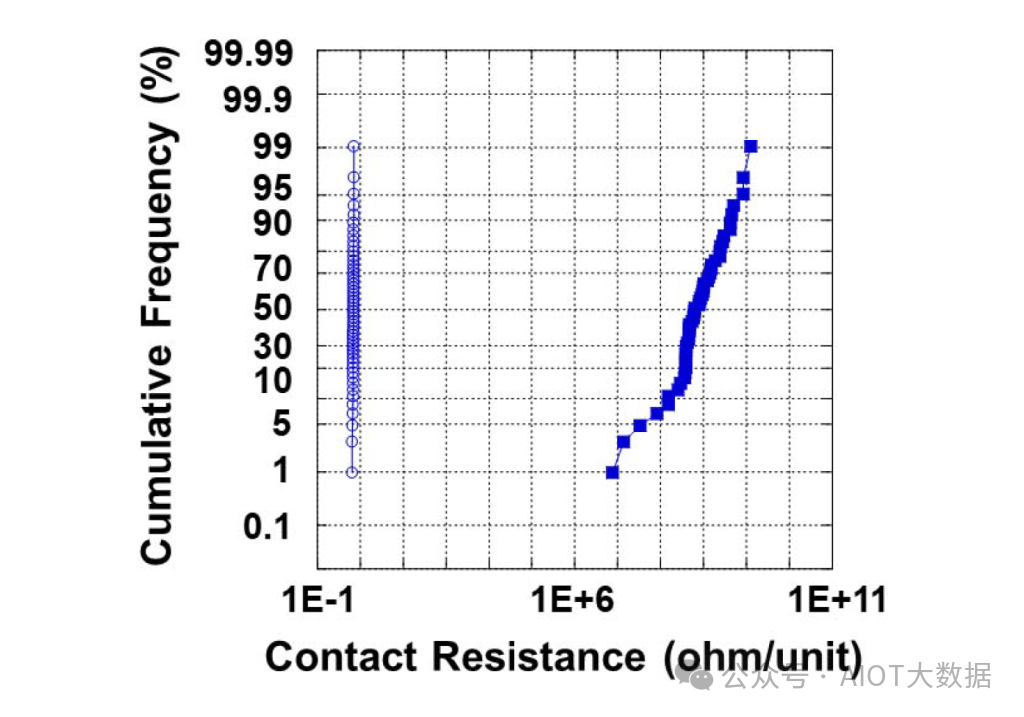
由此得到的结果令人难以置信。与传统工艺相比,接触电阻提高了多个数量级。这是在 200,000 个菊花链式 Cu-Cu 连接上进行的测试。这些是 1 微米面对面键合的结果,但 1.4 微米面对面键合也显示出令人印象深刻的结果。
Zen 3 上的 AMD V-Cache SoIC 混合绑定
AMD 重申了很多事情,但也有一些新的事情。此外,我们将在此处插入我们的推特并提及我们注意到AMD 的 V-Cache 混合绑定和高架扇出桥首席工程师离开 AMD 加盟微软。我们对微软芯片的未来感到兴奋,因为他们一直在从整个行业招募大量人才。
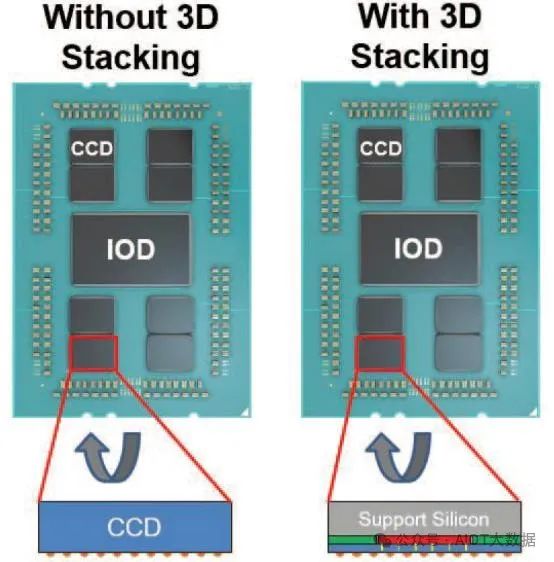
v-cache 的物理结构非常有趣。AMD 和 TSMC 不仅有 CPU CCD 芯片、SRAM 芯片和支撑芯片,而且在整个组件的顶部还有最后一块第五块支撑硅片。IBM的 Tom Wassick独立证实了这一结构。乍一看,这似乎是在浪费额外的硅片,但这样做是因为 TSMC 的混合键合工艺需要减薄芯片。这最后一块支撑硅片是必要的,它能使最终的芯片组件具有刚性,并且与没有混合键合 SRAM 的标准 CCD 具有同等高度。
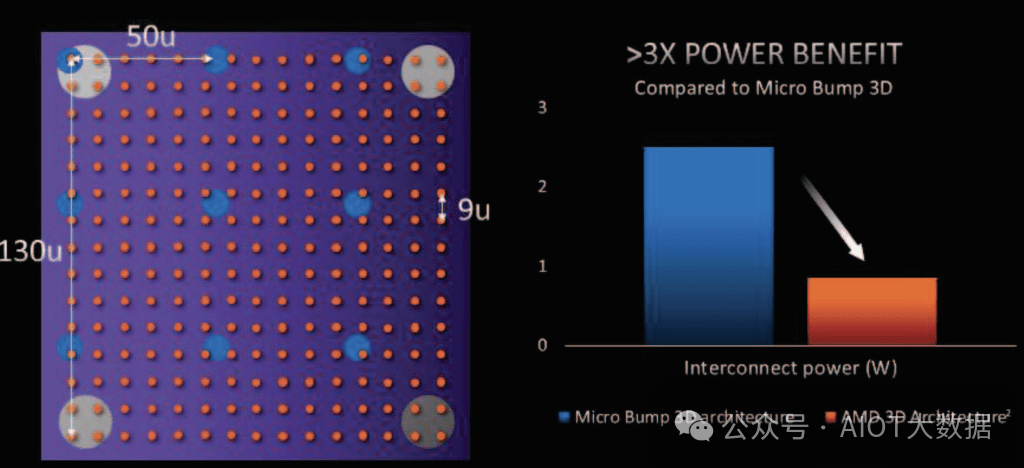
AMD 将 9 微米间距混合键合与 36 微米间距微凸块 3D 架构进行了比较。AMD 指的是将在 Ponte Vecchio GPU 和 Meteor Lake CPU 上使用的 Foveros。AMD 声称互连能效提高了 3 倍,互连密度提高了 16 倍,并且由于 TSV 和接触电容/电感较低,信号/电源完整性也更好。奇怪的是,他们使用 9 微米间距作为比较。这种比较有点不诚实,因为TechInsights发现 V-Cache 的生产版本是在 17 微米间距上完成的。这种间距的放松会削弱一些优势。
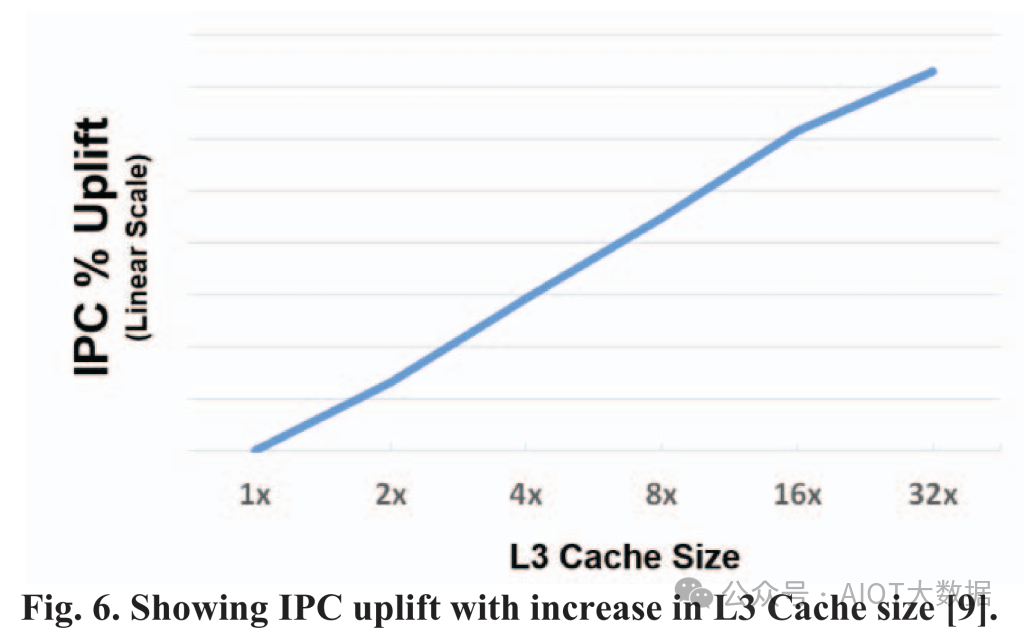
这张图表很有趣,尽管非常笼统。Zen 3 有 32MB 的 L3 缓存,而 V-Cache 为每个芯片增加了 64MB。目前只堆叠了 1 个芯片,这导致 IPC 大幅增加。我想知道 AMD 使用了什么interwetten与威廉的赔率体系 和基准测试来获得这个 IPC % Uplift 数字。AMD 还展示了一些与可靠性相关的数据,表明在正常电压下没有问题。
联发科技网络 SOC 可靠性
联发科发表了一篇题为“高性能计算应用的高密度扇出型封装的可靠性挑战”的论文。没有提到的是,这是联发科通过其定制 ASIC 部门在中国销售的用于网络应用的真正芯片。
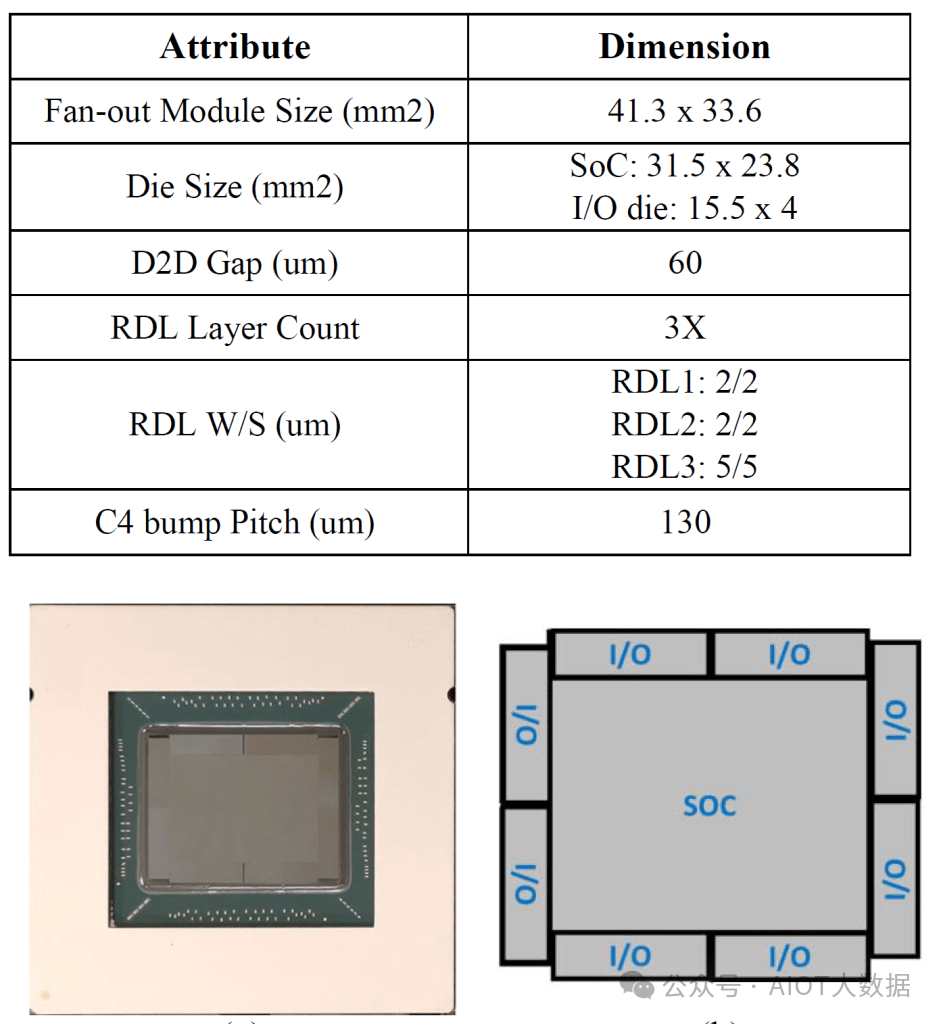
联发科也没有直接说明,但我们知道他们使用了台积电的 InFO-oS 威廉希尔官方网站 。该论文讨论了温度、翘曲和其他可靠性问题,但有趣的是他们宣传了这款芯片。
-
台积电
+关注
关注
44文章
5632浏览量
166414 -
封装
+关注
关注
126文章
7873浏览量
142896 -
CoWoS
+关注
关注
0文章
138浏览量
10485
原文标题:威廉希尔官方网站 前沿:台积电CoWoS 封装A1
文章出处:【微信号:深圳市赛姆烯金科技有限公司,微信公众号:深圳市赛姆烯金科技有限公司】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论