 聚类分析基本概念梳理
聚类分析基本概念梳理
聚类分析:简称聚类(clustering),是一个把数据对象划分成子集的过程,每个子集是一个簇(cluster),使得簇中的对象彼此相似,但与 其他簇中的对象不相似。聚类成为自动分类,聚类可以自动的发现这些分组,这是突出的优点。
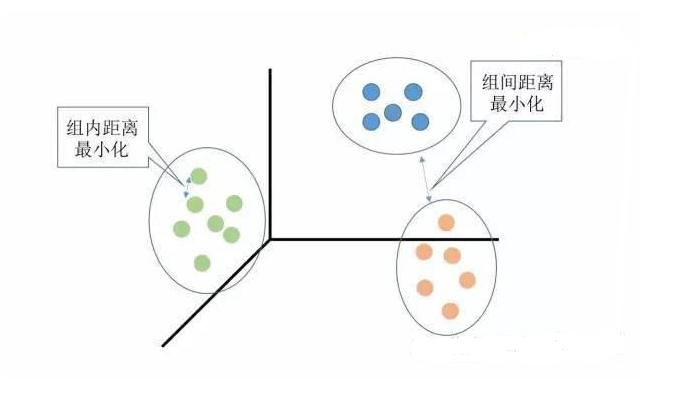
聚类分析是没有给定划分类别的情况下,根据样本相似度进行样本分组的一种方法,是一种非监督的学习算法。聚类的输入是一组未被标记的样本,聚类根据数据自身的距离或相似度划分为若干组,划分的原则是组内距离最小化而组间距离最大化,如下图所示:
常见的聚类分析算法如下:
K-Means: K-均值聚类也称为快速聚类法,在最小化误差函数的基础上将数据划分为预定的类数K。该算法原理简单并便于处理大量数据。
K-中心点:K-均值算法对孤立点的敏感性,K-中心点算法不采用簇中对象的平均值作为簇中心,而选用簇中离平均值最近的对象作为簇中心。
系统聚类:也称为层次聚类,分类的单位由高到低呈树形结构,且所处的位置越低,其所包含的对象就越少,但这些对象间的共同特征越多。该聚类方法只适合在小数据量的时候使用,数据量大的时候速度会非常慢。
基本概念梳理
监督学习:分类成为监督学习(supervised learning),因为给定了类标号的信息,即学习算法是监督的,因为它被告知每个训练元素的 类隶属关系。
无监督学习(unsupervised learning):因为没有提供类标号信息。
数据挖掘对聚类的典型要求如下:可伸缩性、处理不同属性类的能力、发现任意形状的簇、处理噪声数据的能力、簇的分离性
基本聚类方法描述:
1.划分方法:(这是聚类分析最简单最基本的方法)采取互斥簇的划分,即每个对象必须恰好属于一个组。划分方法是基于距离的,给定要构建的分区数k,划分方法首先创建一个初始划分,然后它采用一种迭代的重定位威廉希尔官方网站 ,通过把对象从一个组移动到另一个组来改进划分。一个好的划分准则是:同一个簇中的相关对象尽可能相互“接近”或相关,而不同簇中的对象尽可能地“远离”或不同。(什么是启发式方法?启发式方法指人在解决问题时所采取的一种根据经验规则进行发现的方法。其特点是在解决问题时,利用过去的经验,选择已经行之有效的方法,而不是系统地、以确定的步骤去寻求答案。 如k-均值(k-means)和k-中心点(k-mediods)方法)。
2.层次方法:层次方法创建给定数据对象集的层次分解。层次方法可以分为凝聚和分裂的方法。凝聚的方法,也称自底向上的方法,开始将每个对象作为单独的一组,然后逐次合并相近的对象或组,直到所有的组合并成为一个组。分裂的方法,也成为自顶向下的方法,开始将所有的对象置于一个簇中,在每次的迭代中,一个簇被划分为更小的簇,直到每个最终每个对象在单独的一个簇中。
3.基于密度的方法:大部分划分方法基于对象之间的距离进行聚类,这样的方法只能发现球状簇,而在发现任意形状簇时遇到了困难。已经开发的基于密度的聚类方法,其主要思想是:只要“邻域”中的密度(对象或数据点的数目)超过了某个阈值(用户自定义),就继续增长给定的簇。
4.基于网格的方法:把对象空间量化为有限个单元,形成一个网格结构。所有的聚类操作都在这个网格上进行。这种方法的主要优点是处理速度快。
划分方法:
k-均值方法是怎样工作的:k-均值方法把簇的形心定义为簇内点的均值。流程如下:在D中随机的选择k个对象,每个对象代表一个簇的初始均值或中心。对剩下的每个对象,根据其各个簇中心的欧氏距离,将它分配到最相似的簇。然后该算法迭代的改善簇内变差。对于每个簇,它使用上次迭代分配到该簇的对象,计算新的均值。然后使用更新后的均值作为新的簇中心,重新分配所有对象。这个过程被称为迭代的重定位(iterative relocation)。 缺点:对利群点比较敏感。
k-均值算法流程:
1.从数据集D中选择k个对象作为初始簇的中心
2.根据簇中对象的均值,将每个对象分配到最相似的簇。然后更新簇的均值,也就是重新计算每个簇的对象的均值。直到簇中的均值不再发生变化时算法结束
k-中心点算法对k-均值方法的优化:为了降低k-均值算法对离群点的敏感性,研究了k-中心点方法。我们可以不采用簇中对象的均值作为参考点,而是使用实际对象来代表簇,每个簇使用一个代表对象。其余每个对象被分配到与其最为相似的代表性对象所在的簇中。
k-中心点算法:从数据集D中随机选择k个对象作为初始的代表对象或种子 2.将每个剩余的对象分配到最近的代表对象所代表的簇,并随机的选择一个非代表对象o并计算用o代替代表对象oj的总代价S,如果S《0,则o替换oj,形成新的k个代表对象的集合 3.当簇内的成员不再发生变化时则结束算法。
k-means VS k-mediods:当存在噪声利群点时,k-中心点方法比k-均值方法更棒,这是因为中心点不像均值那样容易受到利群点或其他极端值的影响。然而k-中心点每次迭代的复杂度是O(k(n-k)^2) 。当n合k比较大时,这种计算开销变得相当大,远高于k-均值方法。
基于密度的方法:
DBSCAN(一重基于高密度连通区域的基于密度的聚类):该算法找出核心对象,也就是其邻域稠密的对象。它连接核心对象和它们的邻域,形成稠密区域作为簇。
DBSCAN如何确定对象的邻域?:用户先指定一个参数e》0用来指定每个对象的邻域半径。对象o的e-邻域是以o为中心、以e为半径的空间。
DBSCAN算法流程:
1.首先标记所有的对象为“未探索”
2.然后随机选择一个为探索的对象p并标记为“已探索”
3.如果p的e-邻域至少有MinPts(邻域密度阈值)个对象,则创建一个新的簇C,并把p添加到C中,并把它们记作N,遍历N中的每个成员p‘,如果p’的邻域也至少有MinPts个对象则保留,否则把p‘从N中删除。
4.否则标记p为噪声 5.直到把所有的对象都遍历完为止
-
聚类分析
+关注
关注
0文章
16浏览量
7411
发布评论请先 登录
相关推荐
RAM威廉希尔官方网站 的基本概念
STM32的中断系统基本概念
spss聚类分析树状图
FPGA设计中时序分析的基本概念

介绍时序分析基本概念MMMC





 工商网监
工商网监
评论