 如何使用FP8新威廉希尔官方网站
加速大模型训练
如何使用FP8新威廉希尔官方网站
加速大模型训练
利用 FP8 威廉希尔官方网站 加速 LLM 推理和训练越来越受到关注,本文主要和大家介绍如何使用 FP8 这项新威廉希尔官方网站 加速大模型的训练。
使用 FP8 进行大模型训练的优势

FP8 是一种 8 位浮点数表示法,FP8 的详细介绍可以参考此链接:
https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/examples/fp8_primer.html#Introduction-to-FP8
其中,使用 FP8 进行大模型训练具有以下优势:
新一代 GPU 如NVIDIA Ada Lovelace、Hopper架构配备了最新一代的 Tensor Core,可以支持 FP8 数据精度的矩阵运算加速。相比之前的 FP16 或 BF16 的数据类型,FP8 的 Tensor Core 可提供两倍的 TFlops 算力。
除了计算上的性能加速之外,FP8 本身的数据类型占用的比特数比 16 比特或 32 比特更少,针对一些内存占用比较大的 Operation,可以降低内存占用消耗。
FP8 数据类型不仅适用于模型的训练,同样也可用于推理加速,相对于以前常见的 INT8 的推理方法,使用 FP8 进行模型的训练和推理,可以保持训练和推理阶段模型性能及数据算法的一致,带来了更好的精度保持,避免了使用 INT8 进行额外的精度校正。

当然,FP8 对比 FP16 或者 FP32 在数值表示范围上引入了新的挑战,从上面的表格中可以看到,FP8 数据类型所能表示的数值范围较小,精度较低。因此需要针对 FP8 引入更细粒度的算法改进,如针对每个 Tensor 进行 Scaling 的方法。对于 FP8 训练中的挑战,NVIDIA 提出了一种 Delayed Scaling 的方法针对 FP8 Tensor 在训练过程中引入动态 Scaling,使得在 FP8 训练过程中在加速矩阵运算的同时借助 per-Tensor scaling 的方法保持精度。

上述方法目前已被 NVIDIA 威廉希尔官方网站 团队实现,并集成到了Transformer Engine软件包中。Transformer Engine 是 NVIDIA 提供的开源的训练工具包,专门针对 FP8 大模型训练实现了一系列功能,包含针对大模型所常见模型结构如 Transformer 层等,同时针对 FP8 提供了 Delayed Scaling 这一方法的实现。
目前,Transformer Engine 已支持 PyTorch、JAX、Paddle 等主流框架,并与其它框架相兼容,且为了支持大模型训练,还实现了对模型及 Sequence Level 并行的方法。
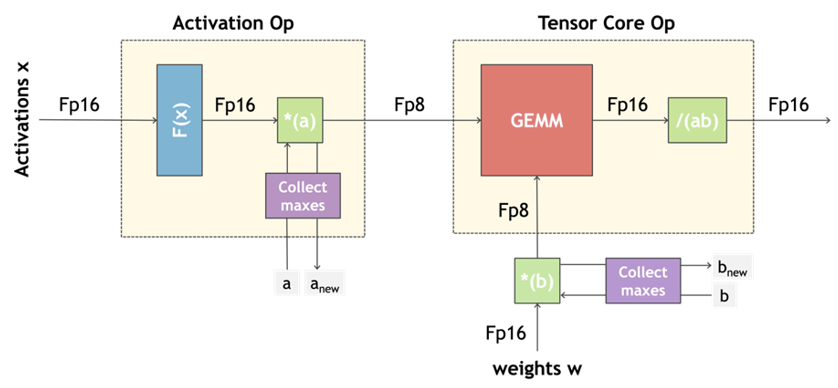
使用 Transformer Engine 十分简单方便,只需调用 Layer 层或 Transformer 层,并将 FP8 的 Delayed Scaling Recipe 包含在模型的定义的 context 中。剩下的训练过程中,所有 Tensor 的 Scaling 以及额外的辅助操作都可由 Transformer Engine 进行处理,无需额外操作 (参考上图右侧的示例)。

当前 Transformer Engine 已与NVIDIA NeMo、Megatron-LM以及HuggingFace 等业界开源社区训练框架融合,便于在大模型的训练中根据自己的需求方便调用 FP8 训练能力。比如:
在 NeMo 中想要打开 FP8 训练,只需要在配置文件中将 transformer_engine 和 FP8 分别设为 True,就可以方便的增加 FP8 的支持
在 Megatron-LM 中,只需要将 config 文件中的 FP8 设置为 hybrid,就可以用 FP8 进行大模型加速训练的过程。
FP8 旨在提升模型训练速度,目前已在 Hopper GPU 上对 Llama 系列模型进行 FP8 训练性能测评,结果显示在 7B、13B 到 70B 等不同大小的模型下,使用 FP8 进行训练吞吐对比 BF16 其性能可提升 30% 至 50%。
FP8 在大模型训练中的特点,可简单总结为以下几点:
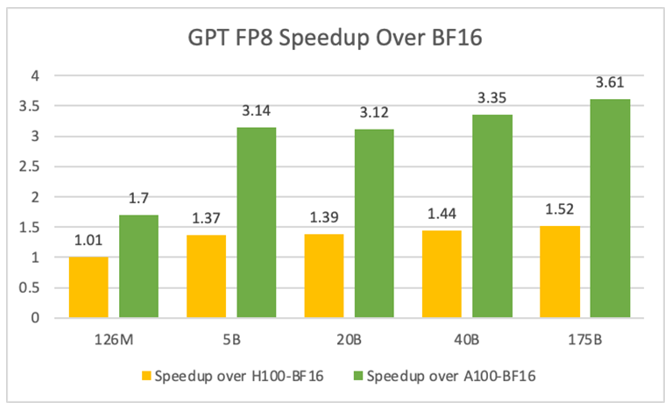
与之前的一些更高精度的方法相比,比如 FP32、TF32、FP16、BF16 等格式,FP8 具有更高的 Flops 数值。理论估计 FP8 相比 FP32 有四倍的算力提升,比 BF16 有两倍的提升。在下面的表格中可以看到,在实际端到端训练任务的过程中,在不同的模型规模下,训练速度可以获得约 1.37 倍到 1.52 倍的加速。
与更高精度的表示方法相比,FP8 有 E5M2 和 E4M3 两种表示方式 (其中 E 为指数位,M 为尾数位)。E5M2 的指数位更多,意味着其数值表示范围更大,梯度通常数值跨度更大,因此 E5M2 更适合用在 backward 当中。而 E4M3 是一种精度更高但动态范围较小的表达方式,因此它更适合在 forward 过程中处理 weights 和 activations。这种混合形式,可以在大模型的训练过程中根据情况灵活的运用这两种方式。对比以前进行的混合精度或低精度训练,TF32 可以无缝替换 FP32,但到了 BF16 的 AMP 阶段,我们不仅需要处理计算的低精度,还需对整个 Loss 和梯度进行 scaling。在 FP16 AMP 中,我们会针对整个网络维护一个 loss scale factor,而精度降至 8 比特时,就需要更精细地制定一套 recipe 来维护 FP8 的精度表现,即在 FP8 训练过程中,我们需要进行 per-tensor scaling。但是在进行 per-tensor 时,会引入数值不稳定的问题,因此我们需要谨慎处理。
NVIDIA Transformer Engine 为用户提供了相应的 recipe,通过简单传入参数,即可方便地利用 FP8 的高算力,同时保持模型收敛性的表现。需要注意的是,并不是训练中的每个算子都要使用到 FP8,其主要应用于线性层中的前向与后向矩阵乘运算中。而对于某些精度敏感的层,我们仍会使用高精度计算,比如梯度更新、softmax 激活等。Transformer Engine 集成了很多 FP8 所需的可以保证精度的 recipe,并且 Transformer Engine 还集成到如 PyTorch、TensorFlow、Jax、Paddlepaddle 等更上层的训练框架,同时一些针对 LLM 训练的框架,如 Megatron-LM、NeMo Framework、DeepSpeed 等,也都集成了 FP8 能力。

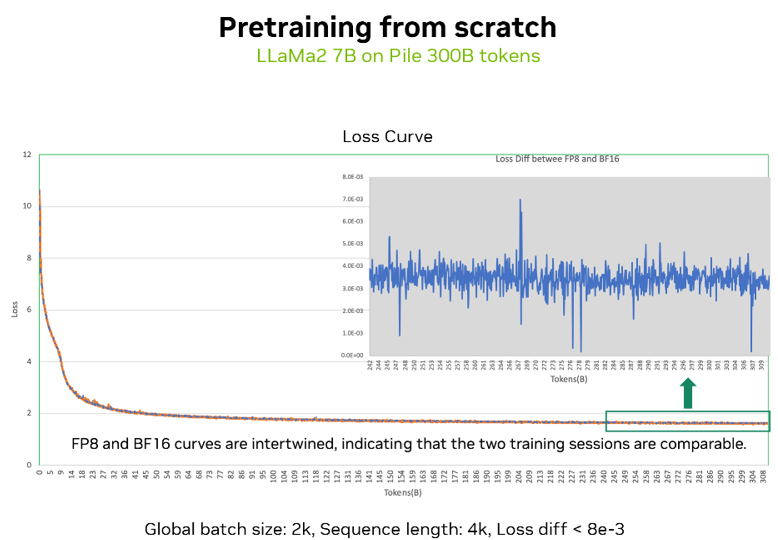
我们也针对大模型训练的不同场景,对 FP8 的收敛性进行了测试和验证。
上图展示了一个从零开始预训练的损失曲线验证,使用 Llama2 7B 模型,在 Pile 的 300 billion tokens 预训练数据集上,分别进行了 FP8 和 BF16 两种精度下的模型训练,可以看到两种精度的损失曲线吻合度极高,数值差异不到 1%。
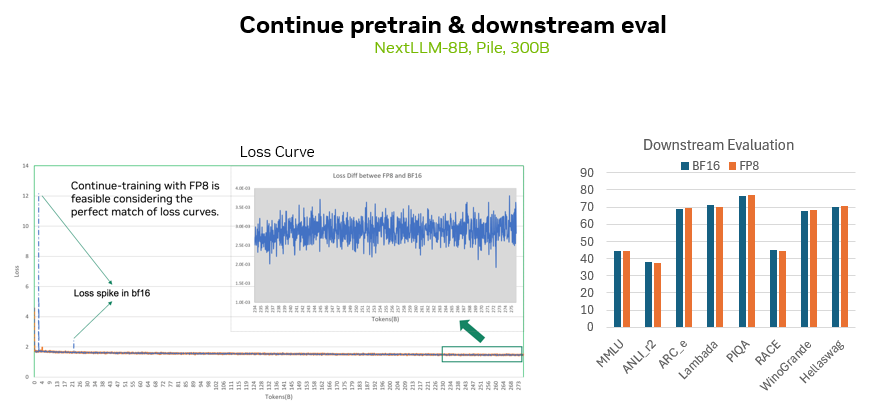
此外,我们还使用 NVIDIA 开发的一个 8B 模型进行了继续预训练测试,数据集同样为 300 billion tokens,也可以看到 FP8 精度下和 BF16 的损失曲线差距也是很小的。同时在包括 MMLU 等多个下游任务上,也可以看到两种精度所训练的模型的下游精度也是比较吻合的。
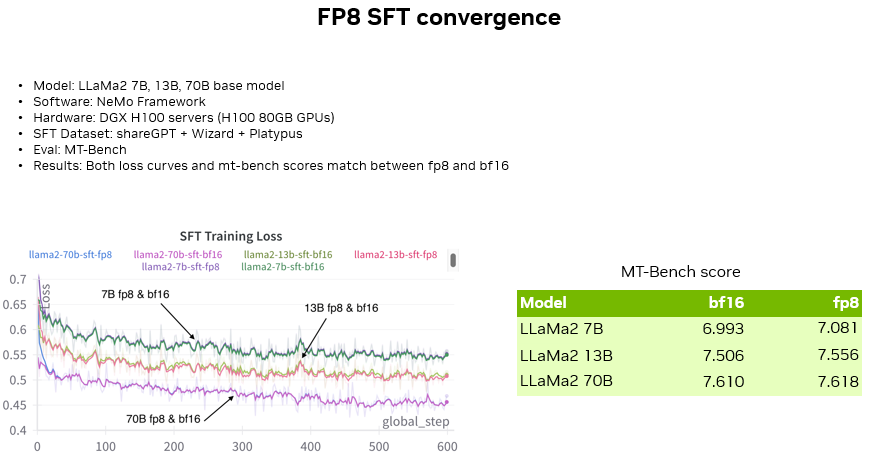
除了预训练阶段,我们也对 SFT 阶段的 FP8 训练精度进行了验证,包括对 Llama2 7B、13B、70B 模型分别进行了 SFT (使用 NeMo 框架,数据集为开源社区中三个流行的英文数据集,MT-Bench 作为 SFT 精度验证)。
可以看到对比了三种不同大小模型在两种精度下的 SFT Loss 曲线,可以看到 Loss 曲线吻合度非常高,并随着模型大小的增大,损失曲线明显下降。
除了 Loss 曲线,也可以看到在 MT-Bench 测评集上三个模型在两种精度下的 Score 也非常接近。
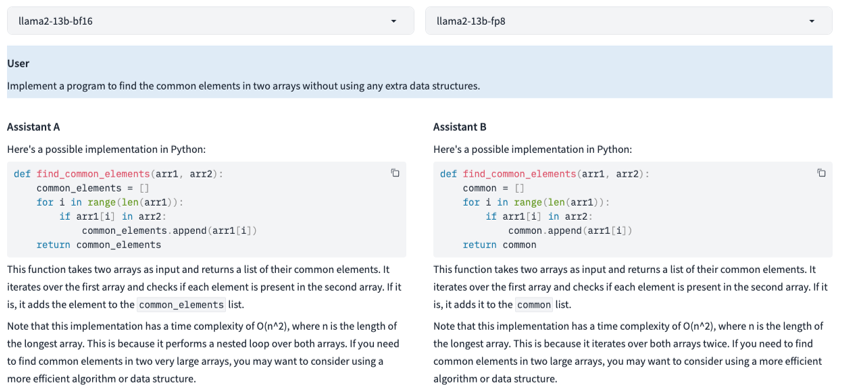
上图是一个 SFT 模型生成效果的对比示例,可以看到在使用 13B 模型时,Prompt 为一个简单编程任务的情况下,可以看到 FP8 和 BF16 生成的内容也是非常接近和类似。
FP8 训练案例分享
零一万物的双语 LLM 模型:
FP8 端到端训练与推理的卓越表现
零一万物是一家专注于大语言模型的独角兽公司,他们一直致力于在 LLM 模型,及其基础设施和应用的创新。其可支持 200K 文本长度的开源双语模型,在 HuggingFace 预训练榜单上,与同等规模的模型中对比表现出色[1]。在零一万物发布的千亿模型 AI Infra 威廉希尔官方网站 上,他们成功地在 NVIDIA GPU 上进行了端到端 FP8 训练和推理,并完成了全链路的威廉希尔官方网站 验证,取得了令人瞩目的成果。
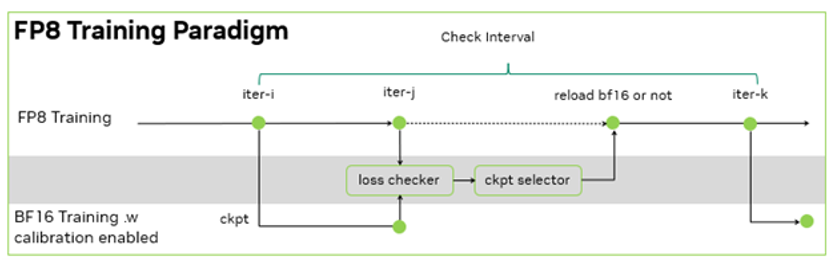
零一万物的训练框架是基于 NVIDIA Megatron-LM 开发的 Y 训练框架, 其 FP8 训练基于 NVIDIA Transformer Engine。在此基础上,零一万物团队进一步的设计了训练容错方案:由于没有 BF16 的 baseline 来检查千亿模型 FP8 训练的 loss 下降是否正常,于是,每间隔一定的步数,同时使用 FP8 和 BF16 进行训练,并根据 BF16 和 FP8 训练的 loss diff 和评测指标的差异,决定是否用 BF16 训练修正 FP8 训练。
由于 FP8 训练的过程中需要统计一定历史窗口的量化信息,用于 BF16 到 FP8 的数据裁切转换,因此在 BF16 训练过程中,也需要在 Transformer Engine 框架内支持相同的统计量化信息的逻辑,保证 BF16 训练可以无缝切换到 FP8 训练,且不引入训练的效果波动。在这个过程中,零一万物基于 NVIDIA 软硬结合的威廉希尔官方网站 栈,在功能开发、调试和性能层面,与 NVIDIA 团队合作优化,完成了在大模型的 FP8 训练和验证。其大模型的训练吞吐相对 BF16 得到了 1.3 倍的性能提升。
在推理方面,零一万物基于NVIDIA TensorRT-LLM开发了 T 推理框架。这个框架提供了从 Megatron 到 HuggingFace 模型的转化,并且集成了 Transformer Engine 等功能,能够支持 FP8 推理,大大减小了模型运行时需要的显存空间,提高了推理速度,从而方便社区的开发者来体验和开发。具体过程为:
将 Transformer Engine 层集成到 Hugging Face 模型定义中。
开发一个模型转换器,将 Megatron 模型权重转换为 HuggingFace 模型。
加载带有校准额外数据的 HuggingFace 模型,并使用 FP8 精度进行基准测试。取代 BF16 张量以节省显存占用,并在大批量推理中获得 2 至 5 倍的吞吐提升。
Inflection AI 的 FP8 训练
Inflection AI 是一家专注于 AI 威廉希尔官方网站 创新的公司,他们的使命是创造人人可用的 AI,所以他们深知大模型的训练对于 AI 生成内容的精准性和可控性至关重要。因此,在他们推出的 Inflection-2 模型中,采用了 FP8 威廉希尔官方网站 对其模型进行训练优化。
与同属训练计算类别的 Google 旗舰模型 PaLM 2 相比,在包括知名的 MMLU、TriviaQA、HellaSwag 以及 GSM8k 等多项标准人工智能性能基准测试中,Inflection-2 展现出了卓越的性能,成功超越了 PaLM 2,彰显了其在模型训练方面的领先性,同时也印证了 FP8 混合精度训练策略能够保证模型正常收敛并取得良好的性能[2]。
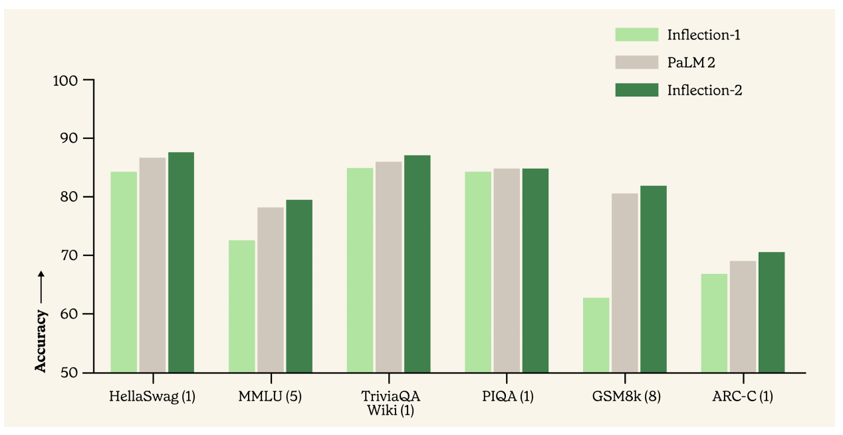
此图片由Inflection AI 制作,
如果您有任何疑问或需要使用此图片,
结语
FP8 威廉希尔官方网站 在推动 AI 模型的高效训练和快速推理方面有巨大的潜力,NVIDIA 的威廉希尔官方网站 团队也在和我们的客户一起不断探索完善应用 FP8 训练和推理方法,未来我们也会持续为大家进行介绍以及最佳实践分享。
-
大模型
+关注
关注
2文章
2427浏览量
2647 -
LLM
+关注
关注
0文章
286浏览量
327
原文标题:如何使用 FP8 加速大模型训练
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
什么是大模型、大模型是怎么训练出来的及大模型作用

FP8数据格式在大型模型训练中的应用

PyTorch GPU 加速训练模型方法
FP8模型训练中Debug优化思路






 工商网监
工商网监
评论