 深度学习工作负载中GPU与LPU的主要差异
深度学习工作负载中GPU与LPU的主要差异
当前,生成式AI模型的参数规模已跃升至数十亿乃至数万亿之巨,远远超出了传统CPU的处理范畴。在此背景下,GPU凭借其出色的并行处理能力,已成为人工智能加速领域的中流砥柱。然而,就在GPU备受关注之时,一个新的竞争力量——LPU(Language Processing Unit,语言处理单元)已悄然登场,LPU专注于解决自然语言处理(NLP)任务中的顺序性问题,是构建AI应用不可或缺的一环。
本文旨在探讨深度学习工作负载中GPU与LPU的主要差异,并深入分析它们的架构、优势及性能表现。
GPU 架构
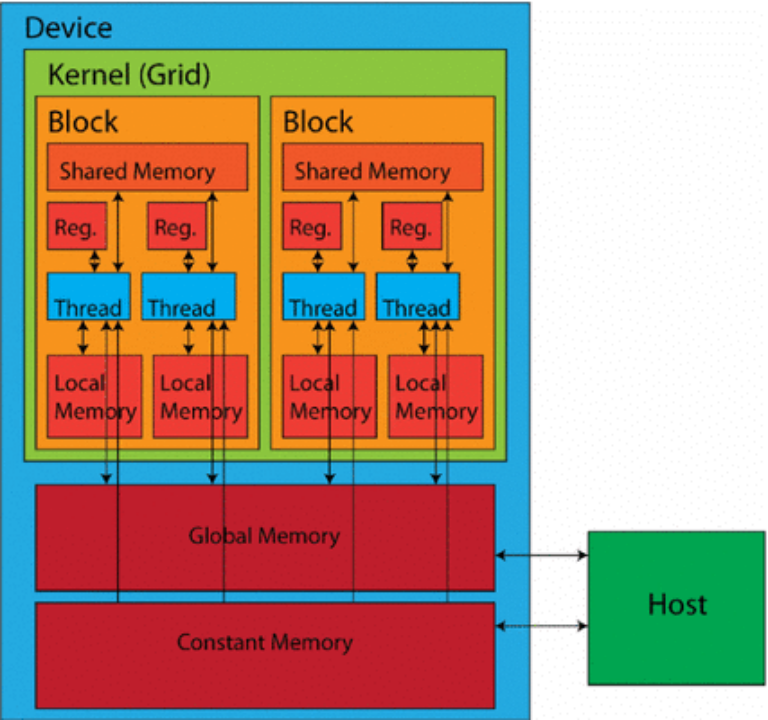
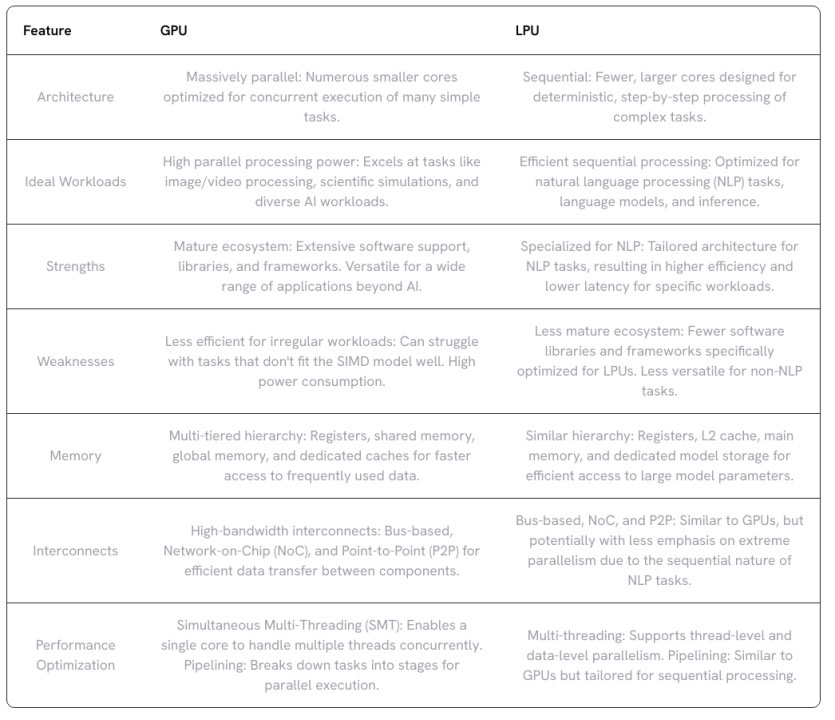
GPU 的核心是计算单元(也称为执行单元),其中包含多个处理单元(在 NVIDIA GPU中称为流处理器或 CUDA 核心),以及共享内存和控制逻辑。在某些架构中,尤其是为图形渲染而设计的架构中,还可能存在其他组件,例如光栅引擎和纹理处理集群 (TPC)。
每个计算单元由多个小型处理单元组成,能够同时管理和执行多个线程。它配备有自己的寄存器、共享内存和调度单元。计算单元通过并行操作多个处理单元,协调它们的工作以高效处理复杂任务。每个处理单元负责执行基本算术和逻辑运算的单独指令。
处理单元和指令集架构 (ISA)
计算单元中的每个处理单元被设计用于执行由GPU的指令集架构(ISA)定义的一组特定指令。ISA确定处理单元可以执行的操作类型(算术、逻辑等)以及这些指令的格式和编码。不同的 GPU 架构可能具有不同的 ISA,这会影响其在特定工作负载下的性能和功能。某些 GPU 为特定任务(例如图形渲染或机器学习)提供专用 ISA,以优化这些用例的性能。
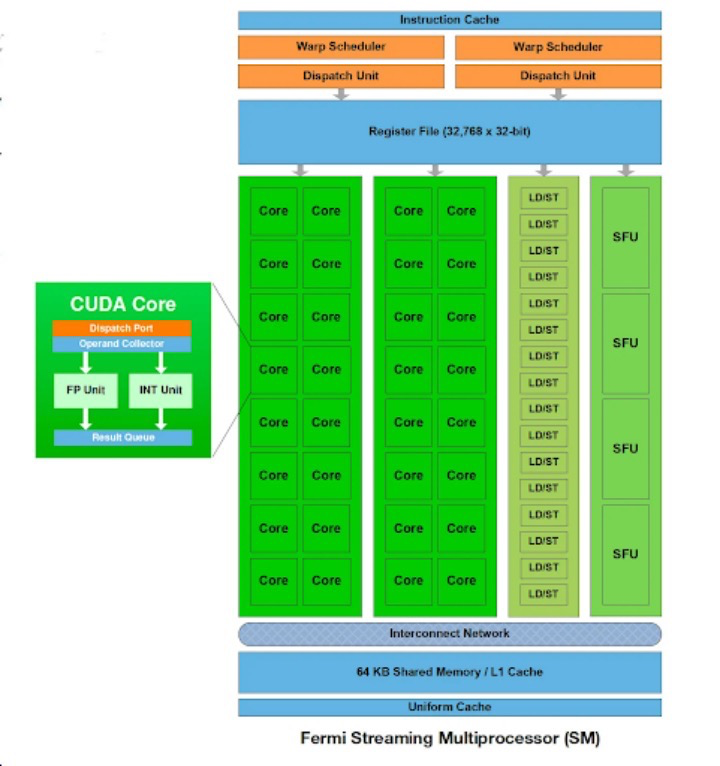
虽然处理单元可以处理通用计算,但许多 GPU 还包含专门的单元来进一步加速特定的工作负载(例如,Double-Precision Units处理高精度浮点计算)。此外,专为加速矩阵乘法设计的Tensor Core(NVIDIA)或Matrix Core(AMD)现在是计算单元的组成部分。
GPU 使用多层内存层次结构来平衡速度和容量。最靠近处理核心的是小型片上寄存器,用于临时存储经常访问的数据和指令。这种寄存器文件提供最快的访问时间,但容量有限。
共享内存是一种快速、低延迟的内存空间,可在计算单元集群内的处理单元之间共享。共享内存促进了计算过程中的数据交换,从而提高受益于线程块内数据重用的任务的性能。
全局内存作为主内存池适用于片上存储器无法容纳的较大数据集和程序指令。全局内存比寄存器或共享存储器提供更大的容量,但访问时间较慢。
GPU 内的通信网络
GPU性能的关键在于处理单元、内存及其他组件间的高效通信。为此,GPU采用了多种互连威廉希尔官方网站 和拓扑结构。以下是它们的分类及工作原理:
高带宽互连
基于总线的互连:这是GPU中常见的连接方式,它提供了组件间数据传输的共享路径。尽管实现简单,但在高流量情况下,由于多个组件要争夺总线访问权,可能会形成瓶颈。
片上网络 (NoC) 互连:高性能GPU则倾向于采用NoC互连,这种方案更具可扩展性和灵活性。NoC 由多个互连的路由器组成,负责在不同组件之间路由数据包,相较于传统的总线系统,它能提供更高的带宽和更低的延迟。
点对点 (P2P) 互连:P2P 互连支持特定组件(例如处理单元和内存库)之间的直接通信,无需共享公共总线,因此可以显著减少关键数据交换的延迟。
互连拓扑
交叉开关(Crossbar Switch):该拓扑允许任意计算单元与任意内存模块通信,提供了灵活性,但当多个计算单元需要同时访问同一个内存模块时,可能会形成瓶颈。
Mesh网络:该拓扑中每个计算单元都以网格状结构与其相邻单元相连,减少了资源争用,并实现了更高效的数据传输,尤其适用于本地化通信模式。
环形总线:计算单元和内存模块以循环方式连接。这样数据就可以单向流动,与总线相比,可以减少争用。虽然广播效率不如其他拓扑,但它仍然可以使某些通信模式受益。
此外,GPU还需与主机系统(CPU和主内存)通信,这通常通过PCI Express(PCIe)总线完成,它是一种高速接口,支持GPU与系统其他部分之间的数据传输。
通过结合不同的互连威廉希尔官方网站 和拓扑,GPU 可以优化各个组件之间的数据流和通信,从而实现跨各种工作负载的高性能。为了最大限度地利用其处理资源,GPU 使用了两种关键威廉希尔官方网站 :多线程和流水线。
多线程:GPU 通常采用同步多线程(SMT),允许单个计算单元同时执行来自相同或不同程序的多个线程,从而能够更好地利用资源,即使任务具有一些固有的串行部分。GPU支持两种形式的并行性:线程级并行(TLP)和数据级并行(DLP)。TLP涉及同时执行多个线程,常采用单指令多线程(SIMT)模型;而DLP则利用矢量指令在单个线程内处理多个数据元素。
流水线:通过将复杂任务分解为更小的阶段来进一步提高效率,然后在计算单元内的不同处理单元上同时进行处理,从而减少总体延迟。GPU通常采用深度流水线架构,指令被分解为众多小阶段,流水线不仅在处理单元内部实现,还应用于内存访问和互连中。
综上所述,众多流处理器、针对特定工作负载设计的专用单元、多层内存结构以及高效的互连组合,共同赋予了GPU同时处理大量数据的能力。
LPU的架构
LPU 是市场上的新产品,尽管目前知名度不高,但其性能却极为出色,专为满足自然语言处理(NLP)工作负载的独特计算需求而设计。这里重点讨论 Groq 的 LPU。
Groq LPU采用了Tensor Streaming Processor(TSP)架构,这一设计特别针对顺序处理进行了优化,与 NLP 工作负载的性质完美契合。与GPU在处理NLP任务时可能因内存访问模式不规则而遇到的挑战不同,TSP擅长处理数据的顺序流,从而能够更快、更有效地执行语言模型。
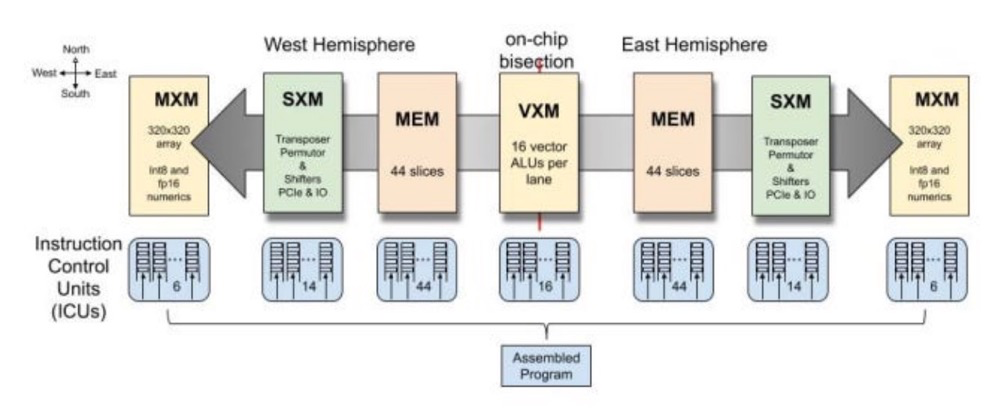
LPU 架构还解决了大规模 NLP 模型中经常遇到的两个关键瓶颈:计算密度和内存带宽。通过精心管理计算资源并优化内存访问模式,LPU 可确保有效平衡处理能力和数据可用性,从而显著提高 NLP 任务的性能。
LPU 尤其擅长推理任务,包括使用预训练的语言模型来分析和生成文本。其高效的数据处理机制和低延迟设计使其成为聊天机器人、虚拟助手和语言翻译服务等实时应用的理想选择。LPU 还集成了专用硬件来加速注意力机制等关键操作,这对于理解文本数据中的上下文和关系至关重要。
软件堆栈
为了弥补LPU专用硬件与NLP软件之间的差距,Groq提供了全面的软件堆栈。专用的编译器能够优化并翻译NLP模型和代码,使它们在LPU架构上高效运行。该编译器兼容流行的NLP框架,如TensorFlow和PyTorch,让开发人员能够无需大幅改动,即可利用他们现有的工作流程和专业知识。
LPU的运行时环境负责执行期间的内存分配、线程调度和资源利用率管理。它还为开发人员提供了API,方便他们与LPU硬件进行交互,从而轻松实现定制和集成到各种NLP应用程序中。
内存架构
Groq LPU 采用多层内存架构,确保数据在计算的各个阶段都随时可用。最靠近处理单元的是标量和矢量寄存器,它们为频繁访问的数据(如中间结果和模型参数)提供快速的片上存储。LPU 使用更大、更慢的二级 (L2) 缓存来存储不常访问的数据,减少了从较慢的主内存中获取数据的需要。
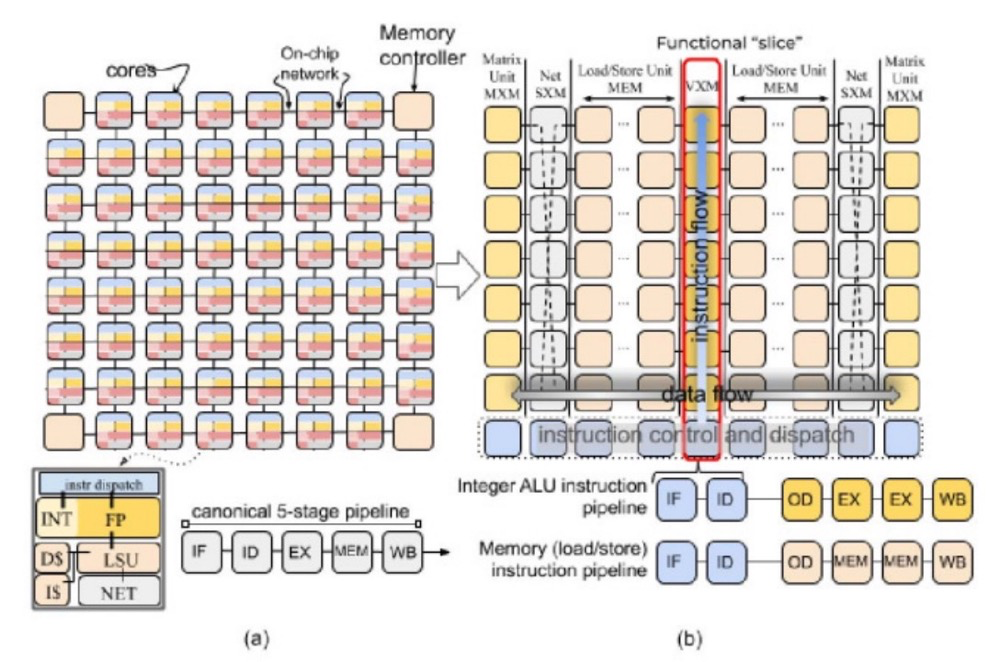
大容量数据的主要存储是主存储器,用于存储预训练模型以及输入和输出数据。在主存储器中分配了专用的模型存储以确保高效访问预训练模型的参数。
此外,LPU 还集成了高带宽片上 SRAM,进一步减少了对外部存储器的依赖,从而最大限度地减少延迟并提高了吞吐量。这对于处理大量数据的任务,如语言建模,尤为关键。
互连威廉希尔官方网站
Groq LPU 使用互连威廉希尔官方网站 以促进处理单元和内存之间的高效通信。基于总线的互连可处理一般通信任务,而片上网络 (NoC) 互连可为要求更高的数据交换提供高带宽、低延迟通信。点对点 (P2P) 互连可实现特定单元之间的直接通信,从而进一步降低关键数据传输的延迟。
性能优化
为了最大限度地利用处理资源,LPU 采用了多线程和流水线威廉希尔官方网站 。神经网络处理集群 (NNPC) 将专门为 NLP 工作负载设计的处理单元、内存和互连分组。每个 NNPC 可以同时执行多个线程,从而显著提高吞吐量并实现线程和数据级并行。
流水线威廉希尔官方网站 将复杂任务分解为多个小阶段,允许不同的处理单元同时处理不同的阶段,从而进一步提高效率。这可减少总体延迟并确保数据通过 LPU 的连续流动。
性能比较
LPU 和 GPU 具有不同的用例和应用。
LPU 被设计为NLP算法的推理引擎,因此很难在相同的基准上直接将这两类芯片进行并排比较。Groq的LPU在加速AI模型推理方面的表现尤为出色,其速度远超当前市场上的任何GPU,其每秒最多可生成五百个推理令牌,这意味着用它来撰写一本小说,可能仅需几分钟的时间。
相比之下,GPU并非专为推理而设计,它们的应用范围更为广泛,涵盖了整个AI生命周期,包括推理、训练和部署各种类型的AI模型。此外,GPU还广泛应用于数据分析、图像识别和科学interwetten与威廉的赔率体系 等领域。
在处理大型数据集时,LPU和GPU都表现出色。LPU能够容纳更多数据,从而进一步加快推理过程。而GPU在通用并行处理方面也表现出色。它能够加速涉及大型数据集和并行计算的各种任务,因此在数据分析、科学模拟和图像识别等领域中发挥着不可替代的作用。
总体而言,如果你的工作负载高度并行,且需要在各种任务中实现高计算吞吐量,那么GPU可能是更好的选择。特别是当你需要处理从开发到部署的整个AI流程时,GPU无疑是最值得投资的硬件选择。但如果你主要关注NLP应用,特别是那些涉及大型语言模型和推理任务的应用程序,那么LPU的专门架构和优化可以在性能、效率和潜在降低成本方面提供显著优势。
-
gpu
+关注
关注
28文章
4729浏览量
128891 -
深度学习
+关注
关注
73文章
5500浏览量
121113
原文标题:GPU 与 LPU:哪个更适合 AI 工作负载?
文章出处:【微信号:SDNLAB,微信公众号:SDNLAB】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
相比GPU和GPP,FPGA是深度学习的未来?
深度学习框架TensorFlow&TensorFlow-GPU详解
Mali GPU支持tensorflow或者caffe等深度学习模型吗
什么是深度学习?使用FPGA进行深度学习的好处?
深度学习方案ASIC、FPGA、GPU比较 哪种更有潜力

优化用于深度学习工作负载的张量程序

深度学习的GPU共享工作
深度学习如何挑选GPU?

GPU在深度学习中的应用与优势







 工商网监
工商网监
评论