 Transformer模型的具体应用
Transformer模型的具体应用
如果想在 AI 领域引领一轮新浪潮,就需要使用到 Transformer。
尽管名为 Transformer,但它们不是电视银幕上的变形金刚,也不是电线杆上垃圾桶大小的变压器。
在上一篇《什么是 Transformer 模型(一)》中,通过对 Transformer 模型进行的深入剖析,展开了一幅 AI 领域的创新画卷,本篇文章将聚焦于该模型在现实世界各个领域中的具体应用,以及这些应用如何改变我们的生活和工作方式,展望其在未来人工智能发展中的潜在影响。
让 Transformer 发挥作用
很快,Transformer 模型就被应用于科学和医疗领域。
伦敦的 DeepMind 使用一种名为 AlphaFold2 的 Transformer 加深了对蛋白质这一生命基础要素的理解。最近《自然》期刊上的一篇文章对该 Transformer 进行了描述。这种 Transformer 能够像处理文本字符串一样处理氨基酸链,为描述蛋白质的折叠方式打开了新的思路,这项研究可以加快药物发现的速度。
阿斯利康和 NVIDIA 共同开发了一个专为药物发现量身定制的 Transformer MegaMolBART。MegaMolBART 是该制药公司 MolBART Transformer 的一个版本,使用 NVIDIA Megatron 在一个大型、无标记的化合物数据库上训练,以创建大规模 Transformer 模型。
阅读分子和医疗记录
阿斯利康分子 AI、发现科学和研发部门负责人 Ola Engkvist 在 2020 年宣布这项工作时表示:“正如 AI 语言模型可以学习句子中单词之间的关系一样,我们的目标是使在分子结构数据上训练而成的神经网络能够学习现实世界分子中原子之间的关系。”
为了从大量临床数据中提炼洞察,加快医学研究的速度,佛罗里达大学学术健康中心与 NVIDIA 研究人员联合创建了 GatorTron 这个 Transformer 模型。
Transformer 增长
在研究过程中,研究人员发现大型 Transformer 性能更好。
慕尼黑工业大学 Rostlab 的研究人员推动着 AI 与生物学交叉领域的前沿研究,他们利用自然语言处理威廉希尔官方网站 来了解蛋白质。该团队在 18 个月的时间里,从使用具有 9000 万个参数的 RNN 升级到具有 5.67 亿个参数的 Transformer 模型。
Rostlab 研究人员展示了在没有标记样本的情况下训练的语言模型所捕捉到的蛋白质序列信号
OpenAI 实验室的生成式预训练 Transformer(GPT)证明了模型的规模越大越好。其最新版本 GPT-3 有 1750 亿个参数,而 GPT-2 只有 15 亿个。
凭借更多的参数,GPT-3 即使在没有经过专门训练的情况下,也能回答用户的问询。思科、IBM、Salesforce 等公司已经在使用 GPT-3。
巨型 Transformer 的故事
NVIDIA 和微软在 2022 年 11 月发布了拥有 5300 亿个参数的 Megatron-Turing 自然语言生成模型(MT-NLG)。与它一起发布的框架 NVIDIA NeMo Megatron 旨在让任何企业都能创建自己的十亿或万亿参数 Transformer,为自定义聊天机器人、个人助手以及其他能理解语言的 AI 应用提供助力。
MT-NLG 首次公开亮相是作为 Toy Jensen(TJ)虚拟形象的大脑,帮助 TJ 在 NVIDIA 2021 年 11 月的 GTC 上发表了一部分主题演讲。
负责 NVIDIA 团队训练该模型的 Mostofa Patwary 表示:“当我们看到 TJ 回答问题时,他作为我们的首席执行官展示我们的工作成果,那一刻真是令人振奋。”
创建这样的模型并非易事。MT-NLG 使用数千亿个数据元素训练而成,整个过程需要数千颗 GPU 运行数周时间。
Patwary 表示:“训练大型 Transformer 模型既昂贵又耗时,如果前一两次没有成功,项目就可能被取消。”
万亿参数 Transformer
如今,许多 AI 工程师正在研究万亿参数 Transformer 及其应用。
Patwary 表示:“我们一直在研究这些大模型如何提供更好的应用。我们还在研究它们会在哪些方面失败,这样就能创建出更好、更大的模型。”
为了提供这些模型所需的算力,NVIDIA 的加速器内置了一个 Transformer 引擎并支持新的 FP8 格式,既加快了训练速度,又保持了准确性。
黄仁勋在 GTC 2022 上表示,通过这些及其他方面的进步,“Transformer 模型的训练时间可以从数周缩短到数天。”
TJ 在 GTC 2022 上表示:“Megatron 能帮助我回答黄仁勋抛给我的所有难题。”
MoE 对于 Transformer 的意义更大
谷歌研究人员 2021 年介绍的 Switch Transformer 是首批万亿参数模型之一。该模型利用 AI 稀疏性、复杂的混合专家(MoE)架构等先进威廉希尔官方网站 提高了语言处理性能并使预训练速度加快了最多 7 倍。
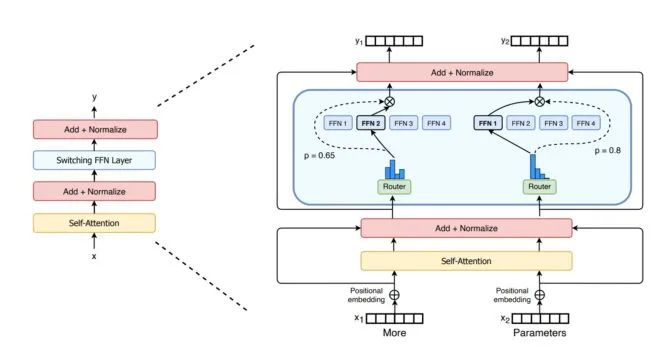
首个拥有多达一万亿个参数模型 Switch Transformer 的编码器
微软 Azure 则与 NVIDIA 合作,在其翻译服务中使用了 MoE Transformer。
解决 Transformer 所面临的挑战
如今,一些研究人员的目标是开发出性能与那些最大的模型相同、但参数更少并且更简单的 Transformer。
Cohere 的 Gomez 以 DeepMind 的 Retro 模型为例:“我看到基于检索的模型将大有可为并实现弯道超车,对此我感到非常兴奋。”
基于检索的模型通过向数据库提交查询来进行学习。他表示:“这很酷,因为你可以对放到知识库中的内容进行选择。”
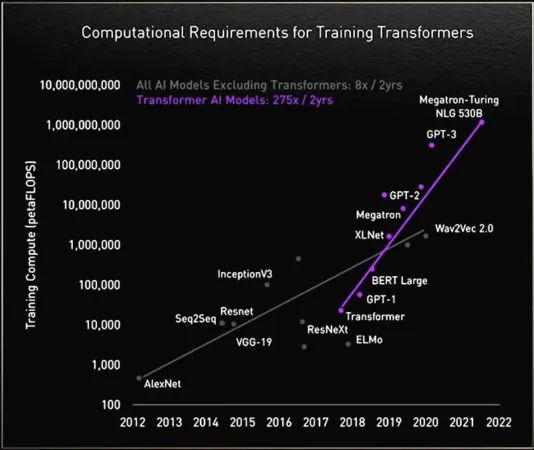
在追求更高性能的过程中,Transformer 模型的规模也在不断扩大
Vaswani 现在是一家隐形 AI 初创公司的联合创始人,他表示最终目标是“让这些模型像人类一样,在现实世界中使用极少的数据就能从上下文中学习。”
他想象未来的模型可以在前期进行更多计算,从而减少对数据的需求,使用户能够更好地提供反馈。
“我们的目标是创建能够在日常生活中帮助人们的模型。”
安全、负责任的模型
其他研究人员正在研究如何在模型放大错误或有害语言时消除偏见或有害性,例如斯坦福大学专门创建了基础模型研究中心探究这些问题。
NVIDIA 研究科学家 Shrimai Prabhumoye 是业内众多研究这一领域的人士之一。他表示:“这些都是在安全部署模型前需要解决的重要问题。”
“如今,大多数模型需要的是特定的单词或短语。但在现实生活中,这些内容可能会以十分微妙的方式呈现,因此我们必须考虑整个上下文。”
Gomez 表示:“这也是 Cohere 最关心的问题。如果这些模型会伤害到人,就不会有人使用它们,所以创建最安全、最负责任的模型是最基本的要求。”
展望未来
在 Vaswani 的想象中,未来能够自我学习、由注意力驱动的 Transformer 最有可能成为 AI 的“杀手锏”。
他表示:“我们现在有机会实现人们在创造‘通用人工智能’一词时提到的一些目标,我觉得这给我们带来了巨大的启发。”
“在当前这个时代,神经网络等各种简单的方法正在赋予我们大量新的能力。”
小结
本文通过对 Transformer 模型的应用案例进行了梳理,并对其未来的发展方向进行了预测。从生物医药到科学研究,该模型不仅在威廉希尔官方网站 上取得了突破,更在实际应用中展现了其深远的影响力和广阔的前景。本文系列内容到此已经对 Transformer 模型如何扩展我们对于机器学习和 AI 的想象进行了深入介绍。随着威廉希尔官方网站 的不断进步,Transformer 模型将在 AI 的新时代中扮演着更加关键的角色,推动各行各业的创新与变革。
-
NVIDIA
+关注
关注
14文章
4981浏览量
102997 -
AI
+关注
关注
87文章
30763浏览量
268908 -
模型
+关注
关注
1文章
3229浏览量
48813 -
Transformer
+关注
关注
0文章
143浏览量
5997
原文标题:什么是 Transformer 模型(二)
文章出处:【微信号:NVIDIA_China,微信公众号:NVIDIA英伟达】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
【「大模型启示录」阅读体验】如何在客服领域应用大模型
自动驾驶中一直说的BEV+Transformer到底是个啥?

【《大语言模型应用指南》阅读体验】+ 基础知识学习
Transformer能代替图神经网络吗
Transformer语言模型简介与实现过程
llm模型有哪些格式
Transformer模型在语音识别和语音生成中的应用优势
使用PyTorch搭建Transformer模型
大语言模型:原理与工程时间+小白初识大语言模型
【大语言模型:原理与工程实践】大语言模型的基础威廉希尔官方网站
【大语言模型:原理与工程实践】探索《大语言模型原理与工程实践》
基于Transformer模型的压缩方法

一文详解Transformer神经网络模型

大语言模型背后的Transformer,与CNN和RNN有何不同






 工商网监
工商网监
评论