 基于AX650N/AX630C部署多模态大模型InternVL2-1B
基于AX650N/AX630C部署多模态大模型InternVL2-1B
背景
InternVL2是由上海人工智能实验室OpenGVLab发布的一款多模态大模型,中文名称为“书生·万象”。该模型在多学科问答(MMMU)等任务上表现出色,并且具备处理多种模态数据的能力。
本文将通过走马观花的方式,基于InternVL2家族中最小的InternVL2-1B模型来介绍其威廉希尔官方网站 特点。同时也将分享基于爱芯元智的AX650N、AX630C两款端侧AI芯片适配InternVL2-1B的基本操作方法,向业界对端侧多模态大模型部署的开发者提供一种新的思路,促进社区对端侧多模态大模型的探索。
威廉希尔官方网站 特性
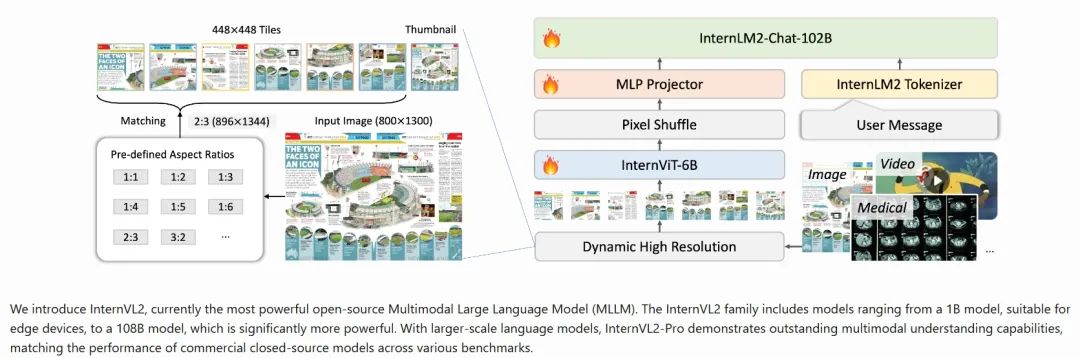
多模态处理能力:与更大规模的版本一样,InternVL2-1B支持图像和文本数据的联合处理,旨在理解和生成跨模态的内容。
轻量化设计:1B参数规模意味着相对较小的模型尺寸,这使得InternVL2-1B更适合部署在资源受限的环境中,如移动设备或边缘计算场景中。尽管参数较少,通过精心设计,它仍能保持良好的性能。
渐进式对齐训练策略:采用从小到大、从粗到精的方式进行训练,这样可以利用更少的计算资源达到较高的效果,同时也促进了模型的知识迁移能力。
高效的架构设计:为了在有限的参数下实现最佳性能,InternVL2-1B可能采用了特别优化的网络结构或注意力机制,确保即使在较低参数量的情况下也能有效地捕捉复杂的视觉语言关联性。
支持多种下游任务:尽管是较小型号,InternVL2-1B应该仍然能够执行一系列基本的视觉-语言任务,比如图像描述生成、视觉问答等,为用户提供了一定程度的功能多样性。
开放源代码与模型权重:如果遵循OpenGVLab的一贯做法,那么InternVL2-1B的代码及预训练模型应该也是开源提供的,方便研究者和开发者使用。
性能指标
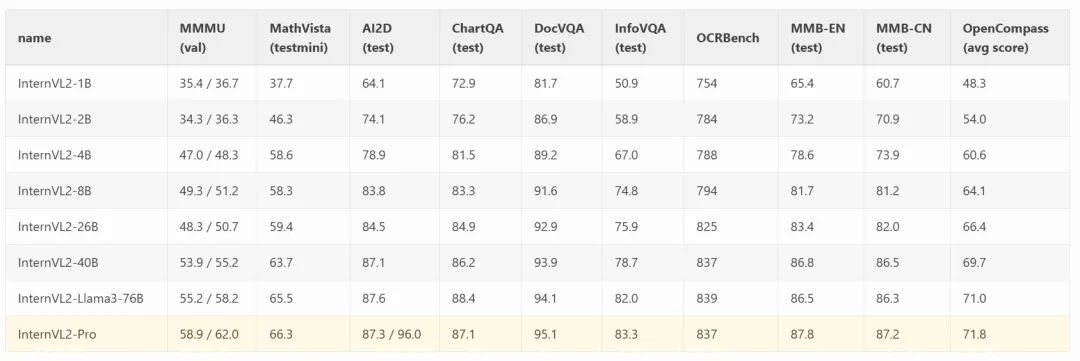
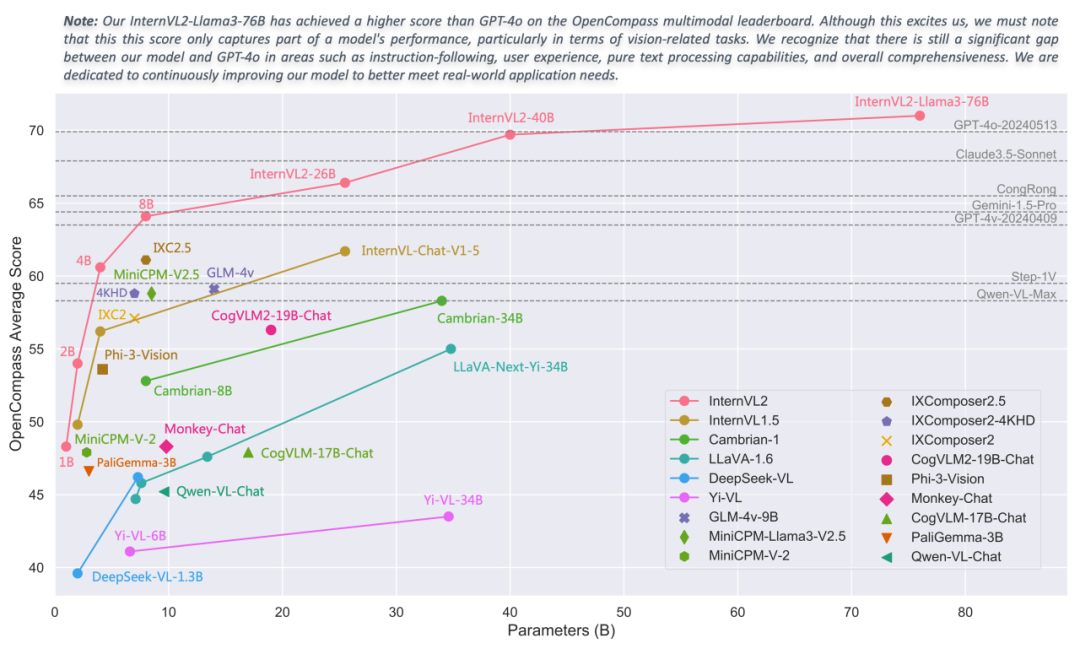
AX650N
爱芯元智第三代高能效比智能视觉芯片AX650N。集成了八核Cortex-A55 CPU,高能效比NPU,支持8K@30fps的ISP,以及H.264、H.265编解码的 VPU。接口方面,AX650N支持64bit LPDDR4x,多路MIPI输入,千兆Ethernet、USB、以及HDMI 2.0b输出,并支持32路1080p@30fps解码内置高算力和超强编解码能力,满足行业对高性能边缘智能计算的需求。通过内置多种深度学习算法,实现视觉结构化、行为分析、状态检测等应用,高效率支持基于 Transformer结构的视觉大模型和语言类大模型。提供丰富的开发文档,方便用户进行二次开发。
AX630C
爱芯元智第四代智能视觉芯片AX630C,该芯片集成新一代智眸4.0AI-ISP,最高支持4K@30fps实时真黑光,同时集成新一代通元4.0高性能、高能效比NPU引擎,使得产品在低功耗、高画质、智能处理和分析等方面行业领先。提供稳定易用的SDK软件开发包,方便用户低成本评估、二次开发和快速量产。帮助用户在智能家居应用和其他AIoT项目中发挥更大的价值。
AX630C应该是目前能效比&性价比&能跑LLM/VLM的最佳的端侧AI芯片了,因此有客户基于AX630C出品了LLM Module,欢迎关注/试用。
模型转换
经常在AI芯片上部署AI算法模型的同学都知道,想要把模型部署到芯片上的NPU中运行,都需要使用芯片原厂提供的NPU工具链,这里我们使用的是Pulsar2。
Pulsar2是爱芯元智的新一代NPU工具链,包含模型转换、离线量化、模型编译、异构调度四合一超强功能,进一步强化了网络模型高效部署的需求。在针对第三代、第四代NPU架构进行了深度定制优化的同时,也扩展了算子&模型支持的能力及范围,对Transformer结构的网络也有较好的支持。
从Pulsar2 3.2版本开始,已经增加了大语言模型编译的功能,隐藏在pulsar2 llm_build的子命令中。
模型获取
git clone https://github.com/AXERA-TECH/ax-llm-build.git cd ax-llm-build pip install -U huggingface_hub huggingface-cli download --resume-download OpenGVLab/InternVL2-1B/ --local-dir OpenGVLab/InternVL2-1B/
ax-llm-build:用于暂存编译LLM、VLM时所依赖的各种辅助小工具、脚本文件(持续更新)。
一键编译
qtang@gpux2:~/huggingface$ pulsar2 llm_build --input_path OpenGVLab/InternVL2-1B/ --output_path OpenGVLab/InternVL2-1B-ax650 --kv_cache_len 1023 --hidden_state_type bf16 --prefill_len 128 --chip AX650 Config( model_name='InternVL2-1B', model_type='qwen2', num_hidden_layers=24, num_attention_heads=14, num_key_value_heads=2, hidden_size=896, intermediate_size=4864, vocab_size=151655, rope_theta=1000000.0, max_position_embeddings=32768, rope_partial_factor=1.0, rms_norm_eps=1e-06, norm_type='rms_norm', hidden_act='silu', hidden_act_param=0.03, scale_depth=1.4, scale_emb=1, dim_model_base=256, origin_model_type='internvl_chat' ) 2024-10-31 0030.400 | SUCCESS | yamain.command.llm_build109 - prepare llm model done! building vision model ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/1 024 building llm decode layers ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 24/24 013 building llm post layer ━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 1/1 027 2024-10-31 0036.175 | SUCCESS | yamain.command.llm_build185 - build llm model done! 2024-10-31 0051.955 | SUCCESS | yamain.command.llm_build364 - check llm model done!
embed提取和优化
chmod +x ./tools/fp32_to_bf16 chmod +x ./tools/embed_process.sh ./tools/embed_process.sh OpenGVLab/InternVL2-1B/ OpenGVLab/InternVL2-1B-ax650
最终InternVL2-1B-ax650目录下包含以下内容:
qtang@gpux2:~/huggingface$ tree -lh OpenGVLab/InternVL2-1B-ax650/ [1.6K] OpenGVLab/InternVL2-1B-ax650/ ├── [325M] intervl_vision_part_224.axmodel // vit-l model ├── [259M] model.embed_tokens.weight.bfloat16.bin // embed file ├── [ 16M] qwen2_p128_l0_together.axmodel // llm layer ├── [ 16M] qwen2_p128_l10_together.axmodel ├── [ 16M] qwen2_p128_l11_together.axmodel ├── [ 16M] qwen2_p128_l12_together.axmodel ...... ├── [ 16M] qwen2_p128_l5_together.axmodel ├── [ 16M] qwen2_p128_l6_together.axmodel ├── [ 16M] qwen2_p128_l7_together.axmodel ├── [ 16M] qwen2_p128_l8_together.axmodel ├── [ 16M] qwen2_p128_l9_together.axmodel └── [141M] qwen2_post.axmodel
上板示例
相关材料
为了方便大家快速试用,我们在网盘中已经提供好了预编译模型和基于AX650N、AX630C两种芯片平台的预编译示例:

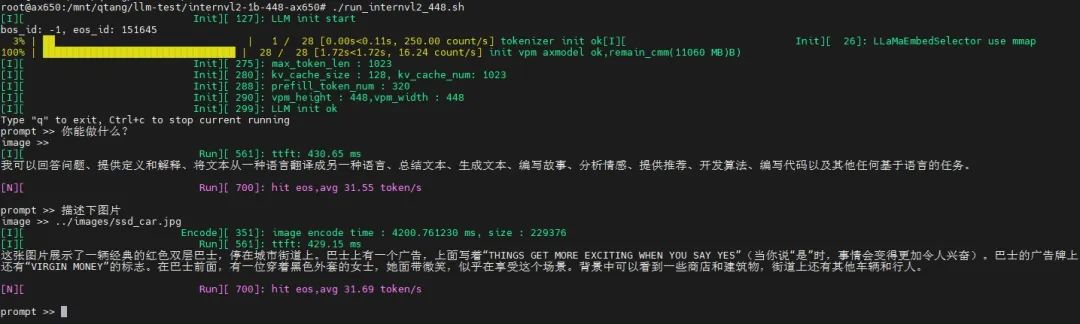
大尺寸
基于AX650N,展示输入图片尺寸为448*448的示例,图片信息量大,解读更详细,甚至展示了其OCR、中英翻译的能力。
小尺寸
基于AX630C,展示输入图片尺寸为224*224的示例:
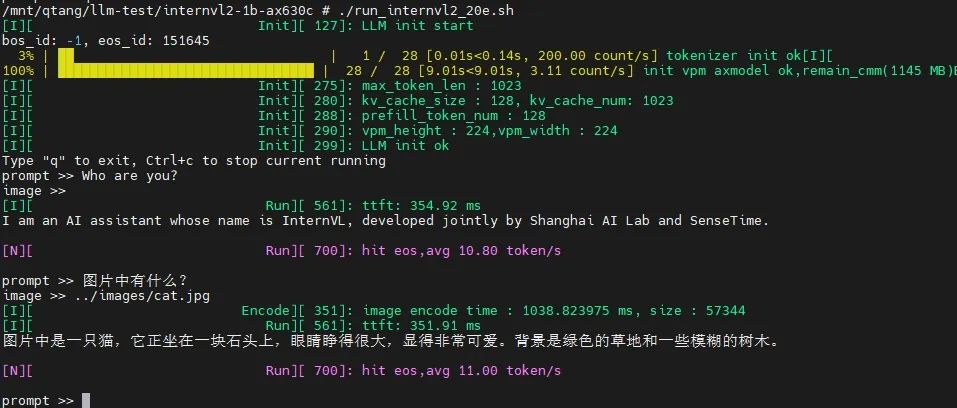
目前我们暂时未对Vision Part模块的ViT-L模型进行量化加速,所以图片编码的速度稍微有点慢。但是本身AX650N、AX630C计算ViT模型的效率是非常高的,后续我们会持续优化推理耗时。
部署优化探讨
输入图片越大,Vision Part(Image Encoder)生成的特征向量越多,计算量越大,即使是InternVL2 Family中最小的1B版本,其Vision Part也是采用的基于ViT-Large规模的图像编码模型。
图片生成的特征向量越多,输入LLM的prompt就越长,input tokens越多,TTFT耗时越大。

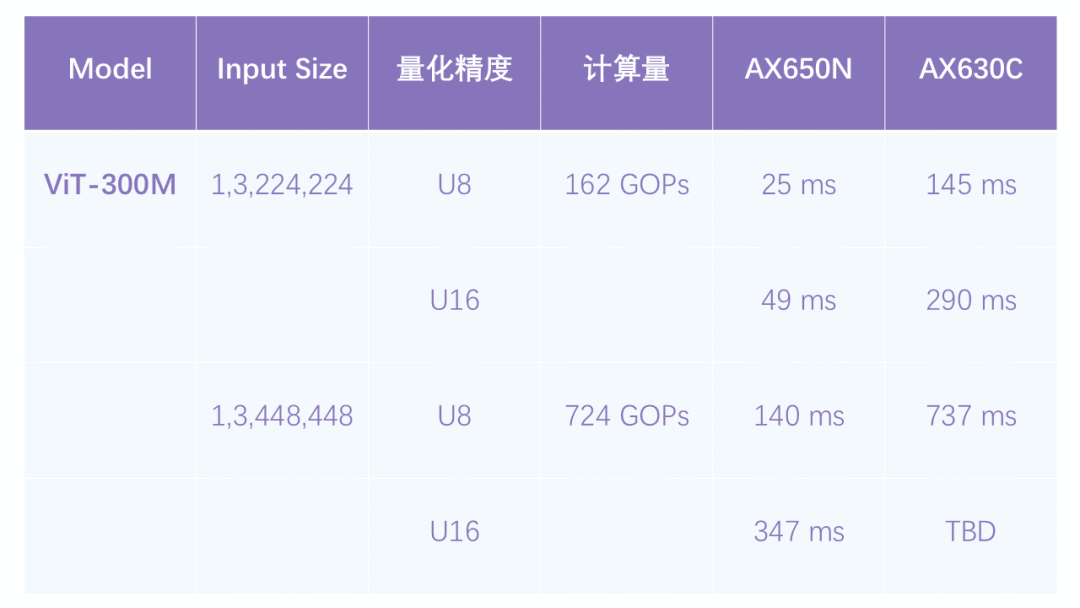
我们顺便统计了224与448两种输入尺寸采用U8、U16量化后的推理耗时,提升还是很明显。
结束语
虽然我们只尝试了最小的InternVL2-1B部署,但能在原本定位于低成本家用摄像头芯片(AX630C)上本地流畅运行VLM已经是一个重大突破,例如无需联网(包括蓝牙)的智能眼镜、智能的“拍立得”、以及各种有趣的穿戴设备。
随着大语言模型小型化的快速发展,越来越多有趣的多模态AI应用已经从云端服务迁移到端侧设备。我们会紧跟行业最新动态,适配更多的端侧大模型,欢迎大家持续关注。
-
人工智能
+关注
关注
1791文章
47200浏览量
238269 -
AI芯片
+关注
关注
17文章
1880浏览量
34994 -
爱芯元智
+关注
关注
1文章
78浏览量
4830 -
大模型
+关注
关注
2文章
2425浏览量
2645
原文标题:爱芯分享 | 基于AX650N/AX630C部署多模态大模型InternVL2-1B
文章出处:【微信号:爱芯元智AXERA,微信公众号:爱芯元智AXERA】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
基于AX650N/AX630C部署端侧大语言模型Qwen2
爱芯元智发布第三代智能视觉芯片AX650N,为智慧生活赋能

【爱芯派 Pro 开发板试用体验】篇一:开箱篇
【爱芯派 Pro 开发板试用体验】爱芯元智AX650N部署yolov5s 自定义模型
【爱芯派 Pro 开发板试用体验】爱芯元智AX650N部署yolov8s 自定义模型
【爱芯派 Pro 开发板试用体验】ax650使用ax-pipeline进行推理
CAT-AX41-C8422B CRADLE N 继电器 V23162
CAT-AX41-D1B AXICOM D2N 灵敏型

爱芯元智第三代智能视觉芯片AX650N高能效比SoC芯片
基于AX650N部署EfficientViT
基于AX650N部署视觉大模型DINOv2
爱芯元智发布新一代IPC SoC芯片AX630C和AX620Q

爱芯元智AX620E和AX650系列芯片正式通过PSA Certified安全认证

基于AX650N芯片部署MiniCPM-V 2.0高效端侧多模态大模型






 工商网监
工商网监
评论