 AI时代核心存力HBM(上)
AI时代核心存力HBM(上)
一、HBM 是什么?
1、HBM 是 AI 时代的必需品作为行业主流存储产品的动态随机存取存储器 DRAM 针对不同的应用领域定义了不同的产 品,几个主要大类包括 LPDDR、DDR、GDDR 和 HBM 等,他们虽然均使用相同的 DRAM 存储单 元(DRAM Die),但其组成架构功能不同,导致对应的性能不同。手机、汽车、消费类等 对低功耗要求高主要使用 LPDDR,服务器和 PC 端等有高传输、高密度要求则使用 DDR,图 形处理及高算力领域对高吞吐量、高带宽、低功耗等综合性要求极高则使用 GDDR 和 HBM。 HBM(High Bandwidth Memory),意为高带宽存储器,是一种面向需要极高吞吐量的数据密集型应用程序的 DRAM,常被用于高性能计算、网络交换及转发设备等需要高存储器带宽的领域。那么 HBM 到底优势在哪呢?通过 TSV 威廉希尔官方网站 ,堆叠方案解决内存墙的问题。基于冯·诺依曼理论的传统计算机系统架构一直存在“内存墙”的问题。
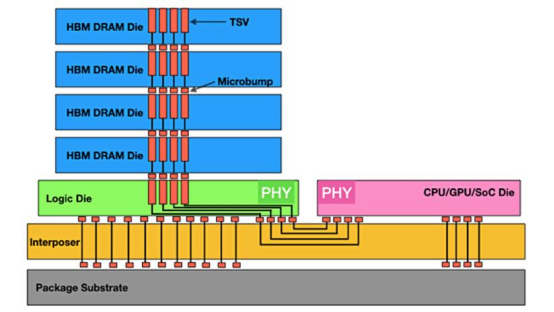
HBM 通过硅中介层和 TSV 来运行
主要归因于:第一存储与计算单元分离,存储与处理器之间通过总线传输数据,这容易导致存储的带宽计算单元的带宽,从而导致 AI 算力升级较慢;
第二,是高功耗,在处理器和存储之间频繁传输数据,会产生较多的能耗,也会使传输速率下降。相较于传统 GDDR,HBM 具有更高速,更低耗,更轻薄等诸多优点。HBM 凭借独特的 TSV 信号纵向连接威廉希尔官方网站
,其内部将数个 DRAM 芯片在缓冲芯片上进行立体 堆叠,其内部堆叠的 DDR 层数可达 4 层、8 层以至 12 层,从而形成大容量、高位宽的 DDR 组合阵列。
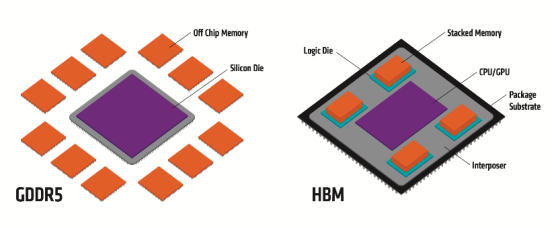
GDDR 与 HBM 结构分布
TSV 是在 DRAM 芯片上搭上数千个细微孔并通过垂直贯通的电极连接上下芯片的威廉希尔官方网站
。该威廉希尔官方网站
在缓冲芯片上将数个 DRAM 芯片堆叠起来,并通过贯通所有芯片层的柱状 通道传输信号、指令、电流。相较传统封装方式,该威廉希尔官方网站
能够缩减 30%体积,并降低 50% 能耗。
凭借 TSV 方式,HBM 大幅提高了容量和位宽(I/O 数量)。与传统内存威廉希尔官方网站
相比,HBM 具有更高带宽、更多 I/O 数量、更低功耗、更小尺寸等特征。
具体来看:(1)存储带宽问题:由于存储的制成与封装工艺与 CPU 的制成封装工艺不同,CPU 使用的是 SRAM 寄存器,速度快,双稳态电路,而存储器使用的是 DRAM 寄存器,速度慢,单稳态电路。这样的工艺不同拉大了两者间的差距,在过去 20 年内,CPU 的峰值计算能力增加了 90000 倍,内存/硬件互存宽带却只是提高了 30 倍。存储的带宽通过总线一直限制着计算单位的带宽,最新型的 GDDR6 单颗带宽上限在 96GB/s,而最新型的单栈HBM3E 带宽上限近 1.2TB/s,在 AI 应用中,每个 SoC 的带宽需求都会超过几 TB/s,上百倍的数据传输差距使得传统 DRAM 远不能满足 AI 训练所需的算力缺口。(2)传输效能问题:由于分离距离问题,数据存算间(I/O)会有很大的延误,一步数据计算过后的大部分时间都在读取内存,查询所用的大量时间与吞吐量影响用户体验,数据传输能量消耗占总数据存算的 60-90%,严重浪费效能。(3)占用空间问题:传统 GDDR 由于是 2D 平面分布,占用空间大,无法满足目前消费电子轻量化与便携化的需求。
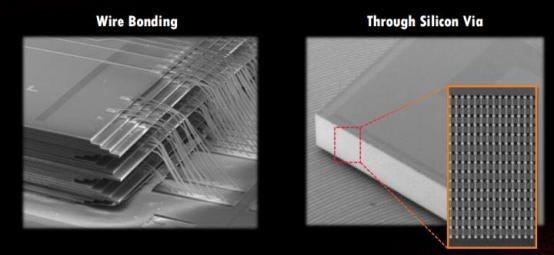
传统打线与 TSV 穿孔区别
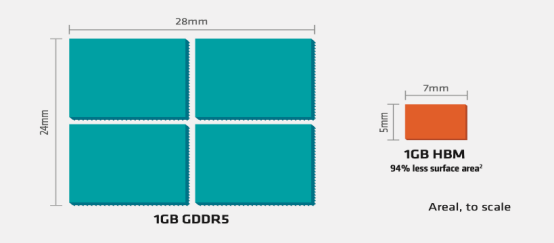
GDDR 与 HBM 占用空间对比
HBM 包括多层 DRAM 芯片和一层基本逻辑芯片,不同 DRAM 以及逻辑芯片之间用 TSV 与微凸 块威廉希尔官方网站 实现通道连接,每个 HBM 芯片可与多达 8 条通道与外部连接,每个通道可单独访问 1 组 DRAM 阵列,通道间访存相互独立。逻辑芯片可以控制 DRAM 芯片,并提供与处理器芯 片连接的接口,主要包括测试逻辑模块与物理层(PHY)接口模块,其中 PHY 接口通过中 间介质层与处理器直接连通,直接存取(DA)端口提供 HBM 中多层 DRAM 芯片的测试通道。
中间介质层通过微凸块连接到封装基板,从而形成 SiP 系统。
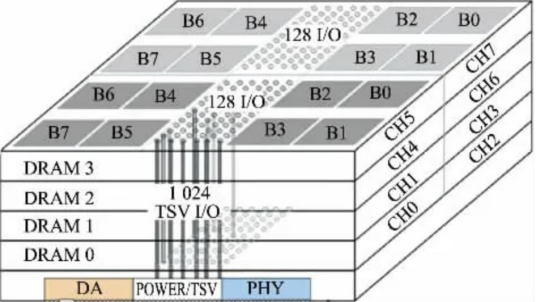
HBM 架构详解
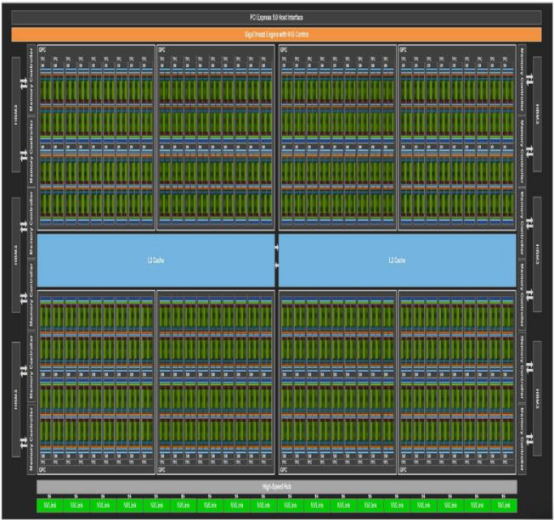
HBM3 在 NVIDIA Hopper 架构的应用AI 时代存力的首选自 ChatGPT 爆火之后,国内外大厂争相竞逐 AI 大模型。而 AI 大模型的基础,就是靠海量 数据和强大算力来支撑训练和推理过程。其中一些模型有 1000 亿字节的数据,参数量越 大,AI 模型越智能,以 GPT-4 模型为例有近 1.76 万亿参数量。
对于每次重新训练的迭代, 都必须从数据中心背板的磁盘上取出 1000 亿字节的数据并进入计算盒,在为期两个月的训练中,必须来回调取数百万次如此庞大的数据。如果能缩短数据存取,就会大大简化训 练过程。但在过去 20 年中,存储和计算并没有同步发展,硬件的峰值计算能力增加了 90000 倍,而内存/硬件互连带宽却只是提高了 30 倍。
当存储的性能跟不上处理器,对指令和数 据的搬运(写入和读出)的时间将是处理器运算所消耗时间的几十倍乃至几百倍,这就要 打破“内存墙”。此时,高带宽内存 HBM 应运而生,被认为是 AI 计算的首选内存。
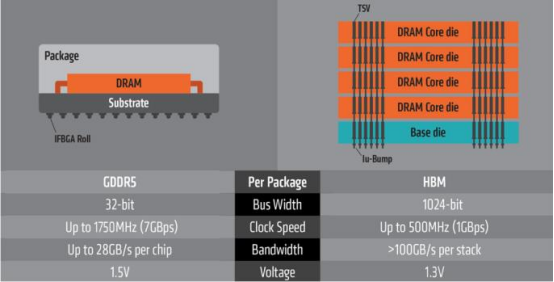
GDDR 与 HBM 性能对比
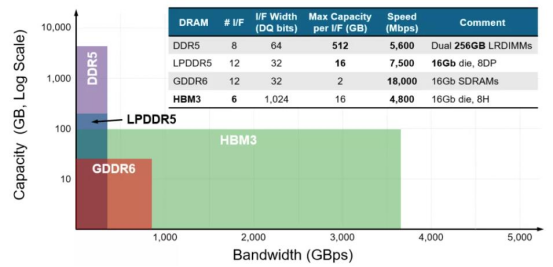
不同内存类型之间 DRAM 容量和带宽的差异 HBM 解决了传统 GDDR 遇到的“内存墙”问题,采用了存算一体的近存计算架构,不通过外部连线的方式与 GPU/CPU/Soc 连接,而是通过中间介质层紧凑快速地连接信号处理器芯片,极大的节省了数据传输所使用的时间与耗能。 而在空间占用上,HBM 采用的堆 栈威廉希尔官方网站 会使得在空间占用要比同比传统 GDDR 节省 94%。在应对目前云端 AI 的多用户, 高吞吐,低延迟,高密度部署需求所带来的计算单位需求,I/O 数量也需要不断突破满足 计算单位的需求。使用 GDDR 所适配的 PCB 威廉希尔官方网站 并不能突破 I/O 数量瓶颈,而 HBM 的 TSV 威廉希尔官方网站 带来的存储器集成度极大提升,使得带宽不再受制于芯片引脚的互联数量,在一定程度上解决了 I/O 瓶颈,成为高算力芯片的首选。

HBM 在 GPU 中搭配

HBM 与 GPU 集成在一起2 NVIDIA 和 AMD 依靠 HBM 持续提升 GPU 性能HBM 新型存储器较传统 GDDR 具有更高的带宽,更低的延迟和更好的等效比。随着 AI 对算 力的高要求,高带宽内存显然是高性能 GPU 的最佳搭配,AMD 和 NVIDIA 两家尖端的 GPU 都陆续配备了 HBM。
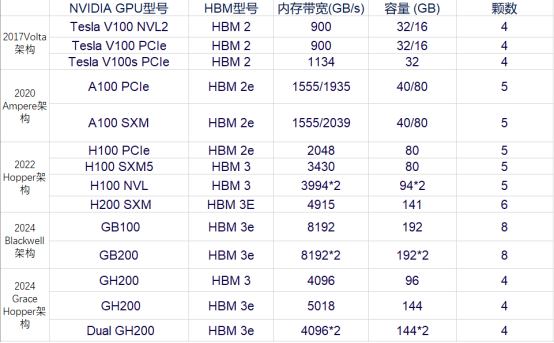
NVIDIA 不同 GPU 型号搭载 HBM 情况
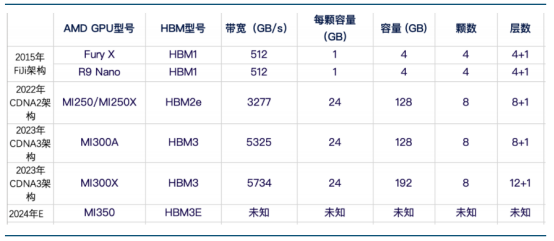
AMD 不同 GPU 型号搭载 HBM 情况 NVIDIA 已在搭载 HBM 的 GPU 型号上迭代 5 次,性能也在不断跟进以适配 AI 模型与训练的 需求。在 7 年时间内,从 V100 架构时代搭载的 HBM2 已经演化到了 GB200 的 HBM3E,而内 存宽带与容量则是在这几年内翻了数倍。
以同一 Hopper 架构下的 H100 SXM 和 H200 SXM 为例,在其他硬件条件与接口协议相同的情况下,搭载了 HBM3E 的 H200 SXM 要比搭载了 HBM3 的 H100 SXM 在带宽速率上提升了 43%,在容量上也是扩增了 76%。而对比落后了一 整代,搭载了 HBM 2E 的 A100 SXM,带宽速率更是提高了 141%,所有的这一切提升都是 HBM 性能迭代带来的优势。
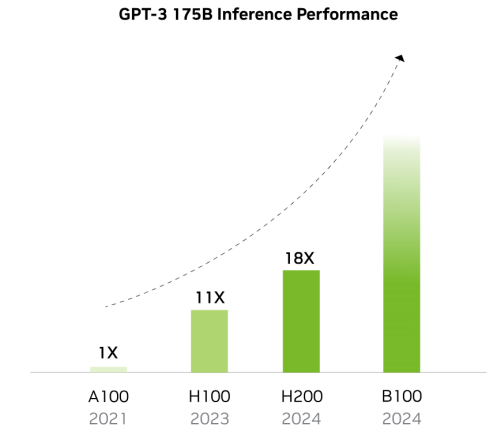
随着搭载 HBM 容量提升 GPU 效能倍数提升
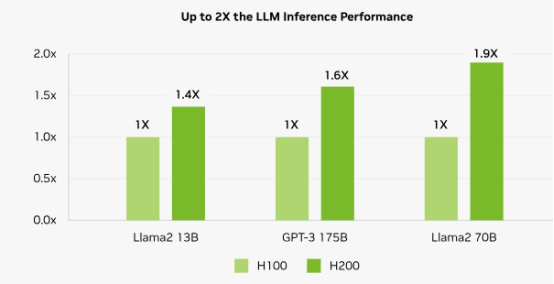
H200 较 H100 在大模型领域性能提升情况 归因于 AI 大模型的逐步迭代,GPU 迭代速度加快。核心供应商 NVIDIA 和 AMD 新品性能竞 争,预计 2025 年加速 HBM 规格需求大幅转向 HBM3e,且将会有更多 12hi 的产品出现,带 动单芯片搭载 HBM 的容量提升。根据 TrendForce 集邦咨询预估,2024 年的 HBM 需求位元 年成长率近 200%,2025 年可望将再翻倍。
-
DRAM
+关注
关注
40文章
2311浏览量
183449 -
存储
+关注
关注
13文章
4298浏览量
85802 -
HBM
+关注
关注
0文章
379浏览量
14746
原文标题:AI时代核心存力 HBM(上)
文章出处:【微信号:闪德半导体,微信公众号:闪德半导体】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
AI算力需求的暴增,HBM和GDDR SDRAM成为AI芯片新的内存方案
HBM抢单大战,才刚刚拉开帷幕

被称为“小号HBM”,华邦电子CUBE进阶边缘AI存储
大模型时代的算力需求
【AD新闻】AI时代,一美元能够买到多强的算力?
AI的核心是什么?
嵌入式系统的核心竞争力是什么
英伟达全球首发HBM3e 专为生成式AI时代打造
全面分析服务器/AI计算的算力框架

算力需求催生存力风口,HBM竞争从先进封装开始
大算力芯片里的HBM,你了解多少?
大模型时代必备存储之HBM进入汽车领域

中国AI芯片和HBM市场的未来
亿铸科技熊大鹏探讨AI大算力芯片的挑战与解决策略
AI时代核心存力HBM(中)





 工商网监
工商网监
评论