 AI推理CPU当道,Arm驱动高效引擎
AI推理CPU当道,Arm驱动高效引擎
AI的训练和推理共同铸就了其无与伦比的处理能力。在AI训练方面,GPU因其出色的并行计算能力赢得了业界的青睐,成为了当前AI大模型最热门的芯片;而在 AI 推理方面,具备卓越通用性和灵活性的CPU本应发挥关键作用,但其重要性却常常被忽视。
“对于那些希望将大语言模型(LLM)集成到产品和服务中的企业和开发者来说,CPU 通常是首选”。Arm 中国区业务全球副总裁邹挺在接受采访时表示。为了适应AI推理的应用落地,CPU有针对性的优化必不可少,Arm Neoverse平台通过增加如SVE2指令集使得AI 推理具有更好的性能和效率。

Arm中国区业务全球副总裁 邹挺
CPU对于AI推理的重要性
CPU长期以来广泛应用于传统的AI和机器学习任务,其通用性和灵活性使其在部署AI推理时更具优势。邹挺表示,在AI场景落地初期,专用AI处理器的开发周期较长,因此,高能效CPU 自然成为了推理的核心;随着 AI 威廉希尔官方网站
的深入发展和应用场景的多样化,定制化专用 AI 加速器应运而生。在这一过程中,高能效的CPU不仅作为核心控制单元,还与 GPU、NPU、FPGA、ASIC 等异构单元协同工作,管理和调度系统资源,成为AI推理的“灵魂捕手”。
相比于单纯依赖 GPU 的高成本和高功耗,CPU在推理过程中具有更高的能效比。CPU 的设计更适合处理多任务负载,并且无需复杂的冷却和电力解决方案。这使得CPU在大规模部署中能够以更低的成本运行,特别是在资源受限的环境中,其低功耗的特性尤为显著。这对于那些需要长期、稳定运行的 AI 应用来说,是一个可持续且经济高效的选择。
Arm Neoverse平台集成SVE2威廉希尔官方网站
,对AI计算至关重要
Arm Neoverse CPU在 AI 推理中展现了其独特优势,这一点要从其威廉希尔官方网站
底层开始剖析。
邹挺分析,Armv9架构已经引入 Arm Neoverse 平台,在Armv9架构中Arm 集成SVE2(可扩展向量扩展)指令集。SVE2 作为一种可扩展的向量处理威廉希尔官方网站
,允许处理器同时执行多个数据元素操作,从而提供了更高效的向量计算和AI 硬件加速。
SVE2 在AI推理中的一个关键应用是矩阵运算。矩阵乘法是许多AI任务中的常见计算,而 SVE2 向量指令可以同时处理多个数据元素,使矩阵乘法能够以向量化的方式进行,从而提高了计算效率。
例如,SVE2 中的 FMMLA 指令可以实现 FP32 格式下的矩阵乘法,BFMMLA 指令能够在 BF16 格式下进行高效运算,而 UMMLA、SMMLA 等指令则优化了 INT8 格式下的矩阵运算。通过这些指令和硬件加速功能,AI 推理在Arm架构上能够实现更高效的矩阵运算和更优的能效比。
这种威廉希尔官方网站
不仅提升了 AI 推理中矢量运算的效率,尤其是在深度学习和自然语言处理(NLP)等核心任务上,加快了推理速度,并在能效表现上进行了优化。通过 SVE2 的支持,Arm Neoverse CPU 可以在边缘计算和资源受限的环境中高效运行,从而减少对 GPU 和其他硬件资源的依赖。
基于Arm Neoverse的CPU显著提升推理性能
亚马逊云服务(AWS)、微软、Google和甲骨文 (Oracle) 等全球最大的 AI 头部云服务提供商们都通过 Arm Neoverse 进行通用计算和基于 CPU 的 AI 推理与训练。Arm Neoverse 不仅为这些头部云服务商提供了定制芯片的灵活性,还优化了严苛的工作负载,确保在每瓦功率的使用上实现更高的计算效率。
例如,基于Arm架构的AWS Graviton,与其他同行业产品相比,Amazon Sagemaker 的 AI 推理性能提高了 25%,Web 应用程序提高了 30%,数据库提高了 40%,效率则提升了 60%。基于 Arm 架构的 Google Cloud Axion,与传统架构相比,其性能和能效分别提高了 50% 和 60%,可为基于 CPU 的 AI 推理和训练、YouTube、Google 地球等服务提供支持。
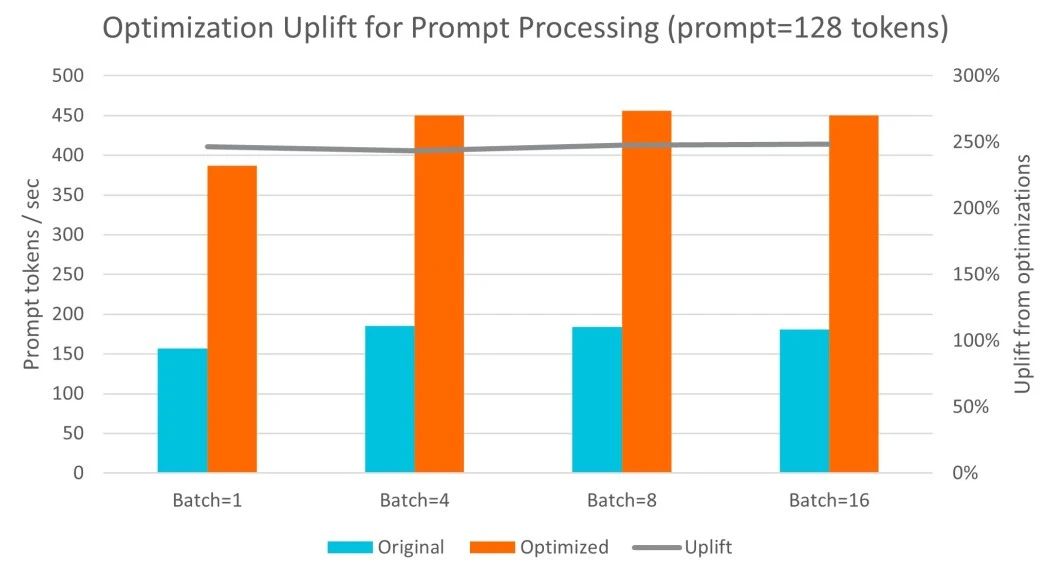
基于 Arm Neoverse N2 架构的阿里云倚天 710,在运行 Llama 3 和 Qwen1.5 等业内标准大语言模型时展现了极高的灵活性和扩展性。通过与 Arm 软件团队的紧密合作,阿里云对 llama.cpp 中的 int4 和 int8 GEMM 内核进行了优化,特别是利用了 SMMLA 指令来提高计算效率。在 ecs.g8y.16xlarge 实例上(配置64个 vCPU 和 256GB 内存),多次实验结果显示,每秒处理的词元数量增加了 2.7 倍。此外,词元生成的吞吐量在处理更大批次数据时最多提高了 1.9 倍。词元生成的延迟对于交互式 LLM 部署非常关键。实验表明,阿里云倚天 710 在单次操作和批量处理场景下均能保持 100 毫秒以内的延迟目标,这符合人们每秒 5-10 个单词的典型阅读速度。因此,这一架构非常适合常规体量的 LLM 部署。
与其他服务器 CPU 的对比中,阿里云倚天 710 的优势显著。在与 Intel Icelake 和 Sapphire Rapids 的对比中,倚天 710 在提示词处理性能上提升了 3.2 倍,词元生成性能则提升了 2.2 倍。这表明,倚天 710 不仅在处理性能上有明显优势,其成本效益也极具吸引力,成为了 LLM 推理应用中的理想选择。
小模型的推理优化
越来越多的企业将开发重心转向小语言模型(Small Language Models, SLM)或小型 LLM,小模型尤其是在处理对话、翻译、摘要、分类等任务时,效率更高且耗能更少。与需要高昂的基础设施成本和复杂漫长的开发部署周期的大语言模型相比,这些模型在训练过程中消耗的电力也相对较低,适合更灵活、可定制的应用场景。
邹挺分析,在提升模型效率方面,量化威廉希尔官方网站
是一个重要的优化手段。通过将神经网络的权重降低到更低的精度,量化威廉希尔官方网站
显著减少了模型的内存和计算需求。比如,将16位浮点数压缩为4位整数,可以大幅降低内存占用和计算成本,同时对精度的影响微乎其微。
以 Llama 2 模型为例,原本拥有 70 亿参数的模型在量化后,从 13.5 GB 缩减至 3.9 GB;130 亿参数的版本从 26.1 GB 缩减至7.3 GB;而700 亿参数模型则从 138 GB 减少至 40.7 GB。这些优化显著提升了模型的运行速度,同时降低了在 CPU 上运行的成本。
结合高效的 Arm CPU 威廉希尔官方网站
,这些优化让轻量级模型可以直接在移动设备上运行,不仅提升了性能,还实现了数据隐私保护和用户体验的优化。
他进一步表示,在针对 FunASR 语音识别模型的优化方面,Arm 充分利用了Armv9 架构中的 SVE2 指令、BF16 数据类型等特性,并引入了动态量化威廉希尔官方网站
,使得 FunASR 模型在 Arm Neoverse 服务器上实现了高效运行。FunASR 是阿里巴巴达摩院开发的开源大模型,基于 Paraformer 架构,具备语音识别、语音端点检测、标点恢复、语言模型、说话人验证和分离等多种功能。
SVE2 指令集在Arm架构处理器中,对 INT8 数据的并行处理非常高效,一次指令周期可以完成 16 个 INT8 的乘累加操作。因此,在对模型执行效率有更高要求的场景下,可以采用 INT8 动态量化来提升效率。此外,INT8 和 BF16 的数据格式组合也进一步优化了模型计算效率,在保持精度的前提下,实现了 1. 5 倍的效率提升。这样的优化确保了 FunASR 等大模型在 Arm 架构上的高效运行,使其能够在特定领域 AI 应用中发挥重要作用。
不断优化AI推理的性能与能耗
当前全球数据中心每年消耗约460太瓦时的电力,随着AI威廉希尔官方网站
和应用的快速发展,这一数字预计在2030年将增长至当前的三倍。目前,数据中心中约有85%的AI负载用于推理任务,这些任务涵盖了众多应用和设备。
Arm Neoverse的架构不仅提升了云端计算的性能和能效,还为大规模云服务提供商和数据中心优化了TCO。例如,基于Arm Neoverse 平台的 AWS Graviton3 在AI推理过程中节约了50%的成本。
据悉,Arm在Neoverse的产品线目前有V、N、E三个平台系列,其中Neoverse V与Neoverse N又进一步推出计算子系统CSS产品,为想快速推出产品,掌握人工智能机遇的合作伙伴,缩减产品开发时间,加速产品上市进程。
迄今为止,合作伙伴基于Arm架构的芯片出货量已达到 3,000 亿颗,这一庞大的市场基础使Arm能够支持各种AI 威廉希尔官方网站
领域的发展,并成为推动AI创新的重要平台。AI 推理正从集中在云端扩展到更多的边缘应用,以实现更广泛的覆盖和更高效的响应。
邹挺说道: “从移动设备到 AI 领域,高性能和出色能效始终是Arm的DNA。Arm 将继续推动 AI 的威廉希尔官方网站
变革,带来更高效、更可持续的计算解决方案,确保我们的威廉希尔官方网站
能够支持合作伙伴在 AI 时代的多样化需求,同时推动 AI 威廉希尔官方网站
在更多领域的广泛落地和普及。”
-
ARM
+关注
关注
134文章
9084浏览量
367390
发布评论请先 登录
相关推荐
Arm成功将Arm KleidiAI软件库集成到腾讯自研的Angel 机器学习框架
CPU推理:AI算力配置新范式

高效大模型的推理综述

NVIDIA助力丽蟾科技打造AI训练与推理加速解决方案

李开复:中国擅长打造经济实惠的AI推理引擎
澎峰科技高性能大模型推理引擎PerfXLM解析

OpenAI开启推理算力新Scaling Law,AI PC和CPU的机会来了
AMD助力HyperAccel开发全新AI推理服务器

Arm CPU如何推动AI创新
基于Arm平台的服务器CPU在LLM推理方面的能力
基于CPU的大型语言模型推理实验







 工商网监
工商网监
评论