 腾讯发布开源MoE大语言模型Hunyuan-Large
腾讯发布开源MoE大语言模型Hunyuan-Large
近日,腾讯公司宣布成功推出业界领先的开源MoE(Mixture of Experts,专家混合)大语言模型——Hunyuan-Large。这款模型不仅在参数量上刷新了业界纪录,更在效果上展现出了卓越的性能,标志着腾讯在自然语言处理领域迈出了重要的一步。
据了解,Hunyuan-Large的总参数量高达389B(即3890亿),这一数字远超当前许多主流的大语言模型。而其激活参数也达到了惊人的52B(即520亿),这意味着模型在处理复杂任务时能够展现出更强的学习能力和泛化性能。
除了参数量上的优势,Hunyuan-Large在训练数据上也下足了功夫。据悉,该模型训练时所使用的token数量达到了7T(即7万亿),这确保了模型能够充分学习到语言的多样性和复杂性。同时,Hunyuan-Large还支持最大上下文长度为256K的文本输入,这一特性使得模型在处理长文本或对话场景时能够更准确地捕捉上下文信息,从而生成更加连贯和自然的回复。
腾讯此次推出的Hunyuan-Large大语言模型,不仅展示了其在人工智能领域的深厚威廉希尔官方网站 积累,也为整个自然语言处理领域的发展注入了新的活力。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
人工智能
+关注
关注
1791文章
47253浏览量
238399 -
腾讯
+关注
关注
7文章
1655浏览量
49430 -
语言模型
+关注
关注
0文章
523浏览量
10274 -
自然语言
+关注
关注
1文章
288浏览量
13348
发布评论请先 登录
相关推荐
腾讯混元大模型开源成绩斐然,GitHub Star数近1.4万
内外部威廉希尔官方网站
的开源共享,旨在促进威廉希尔官方网站
创新与生态发展。 据悉,腾讯混元大模型已经在多个模态上实现了开源,包括语言大
大语言模型开发语言是什么
在人工智能领域,大语言模型(Large Language Models, LLMs)背后,离不开高效的开发语言和工具的支持。下面,AI部落小编为您介绍大
猎户星空发布Orion-MoE 8×7B大模型及AI数据宝AirDS
近日,猎户星空携手聚云科技在北京共同举办了一场发布会。会上,猎户星空正式揭晓了其自主研发的Orion-MoE 8×7B大模型,并与聚云科技联合推出了基于该大模型的数据服务——AI数据宝
昆仑万维开源2千亿稀疏大模型Skywork-MoE
近日,昆仑万维公司宣布开源一款名为Skywork-MoE的稀疏大模型,该模型拥有高达2千亿参数,不仅性能强劲,而且推理成本更低,为人工智能领域带来了新的突破。
浪潮信息发布“源2.0-M32”开源大模型
浪潮信息近日推出了革命性的“源2.0-M32”开源大模型。该模型在源2.0系列基础上,引入了“基于注意力机制的门控网络”威廉希尔官方网站
,构建了一个包含32个专家的混合专家模型(
腾讯云大模型价格调整:混元-lite、混元-standard免费,混元-pro降价
据了解,腾讯混元大模型是腾讯全链路自研的万亿参数大模型,采用混合专家模型(MoE)结构,
Mistral Large模型现已在Amazon Bedrock上正式可用
的 Mistral 7B 和 Mixtral 8x7B模型。今天,Mistral AI最新且最前沿的大语言模型(LLM)Mistral Large又在Amazon Bedrock上正式
Mistral发布Mistral Large旗舰模型,但没有开源
昨夜,被称为“法国版 OpenAI”的 Mistral AI 再放大招,正式发布 Mistral Large 旗舰模型,并且推出对标 ChatGPT 的对话产品:Le Chat,直接杀到 OpenAI 家门口。
昆仑万维发布新版MoE大语言模型天工2.0
昆仑万维科技今日震撼发布全新升级的「天工2.0」MoE大语言模型以及配套的新版「天工AI智能助手」APP。此次更新标志着国内首个搭载MoE架
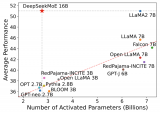
幻方量化发布了国内首个开源MoE大模型—DeepSeekMoE
幻方量化旗下组织深度求索发布了国内首个开源 MoE 大模型 —— DeepSeekMoE,全新架构,免费商用。
机器人基于开源的多模态语言视觉大模型
ByteDance Research 基于开源的多模态语言视觉大模型 OpenFlamingo 开发了开源、易用的 RoboFlamingo 机器人操作
发表于 01-19 11:43
•414次阅读

对标OpenAI GPT-4,MiniMax国内首个MoE大语言模型全量上线
MoE 架构全称专家混合(Mixture-of-Experts),是一种集成方法,其中整个问题被分为多个子任务,并将针对每个子任务训练一组专家。MoE 模型将覆盖不同学习者(专家)的不同输入数据。
大语言模型推断中的批处理效应
随着开源预训练大型语言模型(Large Language Model, LLM )变得更加强大和开放,越来越多的开发者将大语言






 工商网监
工商网监
评论