 使用EMBark进行大规模推荐系统训练Embedding加速
使用EMBark进行大规模推荐系统训练Embedding加速
简介
推荐系统是互联网行业的核心系统,如何高效训练推荐系统是各公司关注的核心问题。目前,推荐系统基本上都是基于深度学习的大规模 ID 类模型,模型包含数十亿甚至数百亿级别的 ID 特征,典型结构如图 1 所示。
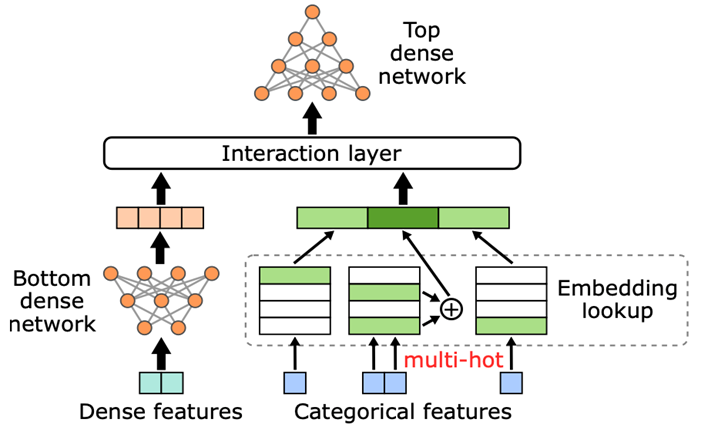
图 1. 典型 DLRM 模型结构图
近年来,以 NVIDIA Merlin HugeCTR 和 TorchRec 为代表的 GPU 解决方案,通过将大规模 ID 类特征的 embedding 存放在 GPU 上,并对 embedding 进行模型并行处理,将其分片到不同 GPU 上,利用 GPU 内存带宽优势,大幅加速了深度推荐系统模型的训练,相较于 CPU 方案有显著提升。
同时,随着训练集群 GPU 使用数量增加(从 8 个 GPU 增加到 128 个 GPU),我们也发现,embedding 部分通信开销占整个训练开销比例越来越大。在一些大规模训练中(比如在 16 节点上)甚至超过一半(51%)。这主要是因为两个原因:
随着集群 GPU 数量增加,每个节点上的 embedding table 数量逐渐减少,导致不同节点负载不均衡,降低训练效率。
相比机内带宽,机间带宽小得多,因此 embedding 模型并行需要进行机间通信耗时较长。
为了帮助行业用户更好地理解问题、解决问题,NVIDIA HugeCTR 团队于今年的 RecSys 大会上提出了 EMBark,通过支持 3D 的自定义 sharding 策略和结合不同的通信压缩策略,能够细粒度的优化大规模集群下深度推荐模型训练的负载不均衡问题,以及减少 embedding 需要的通信时间,其相关代码[1]和论文[2]皆已开源。
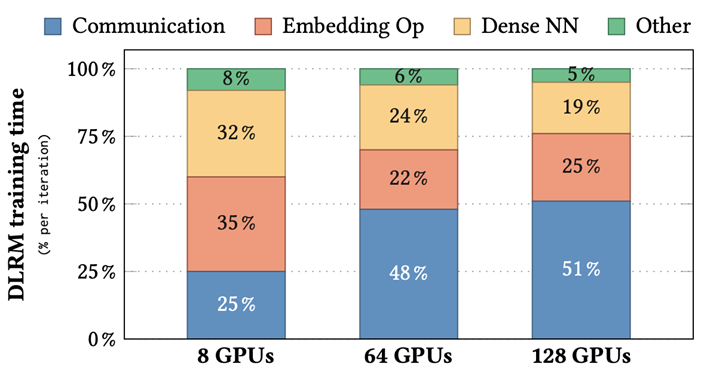
图 2. 不同 cluster 配置下 DLRM 各部分训练耗时占比
EMBark 介绍
EMBark 旨在提高 DLRM 训练中 embedding 在不同集群配置下的性能,并加速整体训练吞吐量。EMBark 是在 NVIDIA Merlin HugeCTR 开源推荐系统框架的基础上实现的,但所描述的威廉希尔官方网站 也可以应用于其他机器学习框架。
EMBark 有三个关键组件:embedding clusters、灵活的 3D 分片方案和分片规划器。下图展示了 EMBark 的整体架构。
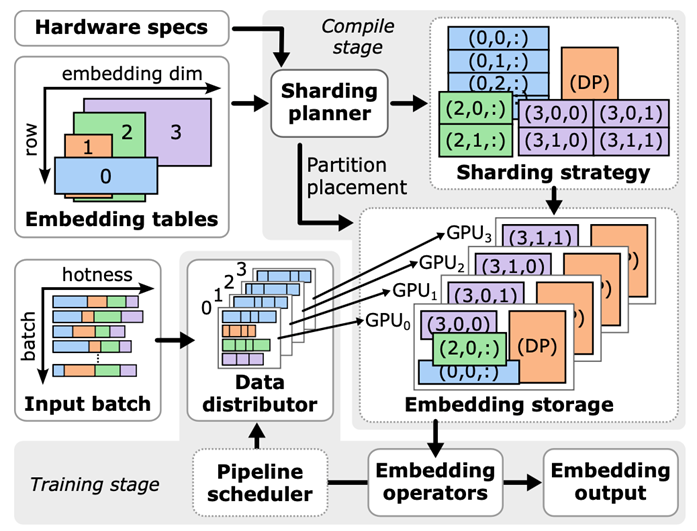
图 3. EMBark 架构图
Embedding Clusters
Embedding clusters 旨在通过将具有相似特征的 embedding 进行分组并为每个 cluster 应用定制的压缩策略来高效地训练 embedding。每个 cluster 包括 data distributor、embedding storage 和 embedding operators,协同将 feature ID 转换为 embedding 向量。
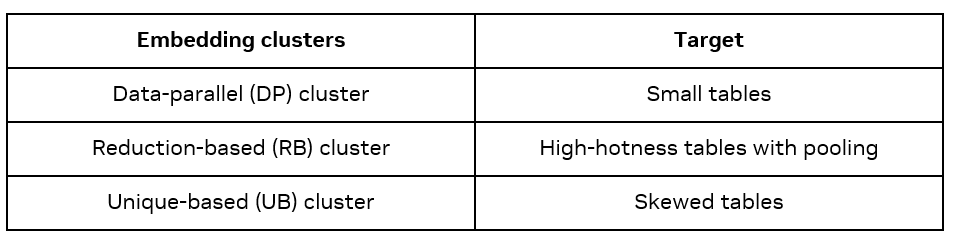
有三种类型的 Embedding clusters:Data-parallel(DP)、Reduction-based(Reduction based)和基于 Unique-based(Unique Based)。每种类型在训练过程中采用不同的通信方法,适用于不同的 embedding。
DP cluster 不压缩通信,因此简单高效,但是因为会将 embedding table 在每个 GPU 上重复,因此仅适用于小表格。
RB cluster 使用归约操作,对于具有池化操作的多 feature 输入表格压缩效果显著。
UB cluster 仅发送唯一向量,有利于处理具有明显访问热点的 embedding table。
灵活的 3D 分片方案
灵活的 3D 分片方案旨在解决 RB cluster 中的工作负载不平衡问题。与固定的分片策略比如 row-wise、table-wise、column-wise 不同,EMBark 使用一个 3D 元组(i, j, k)表示每个分片,其中 I 表示表格索引,j 表示行分片索引,k 表示列分片索引。这种方法允许每个 embedding 跨任意数量的 GPU 进行分片,提供灵活性并实现对工作负载平衡的精确控制。
分片规划器
为了找到最佳分片策略,EMBark 提供了一个分片规划器——一种成本驱动的贪婪搜索算法,根据硬件规格和 embedding 配置识别最佳分片策略。
Evaluation
所有实验均在一个集群上进行,该集群由 NVIDIA DGX-H100[3] 节点组成,每个节点配备 8 张 NVIDIA H100 GPU(总计 640GB HBM,带宽为每节点 24TB/s)。在每个节点内,所有 GPU 通过 NVLink(双向 900GB/s)互连。节点间通信使用 InfiniBand(8x400Gbps)。
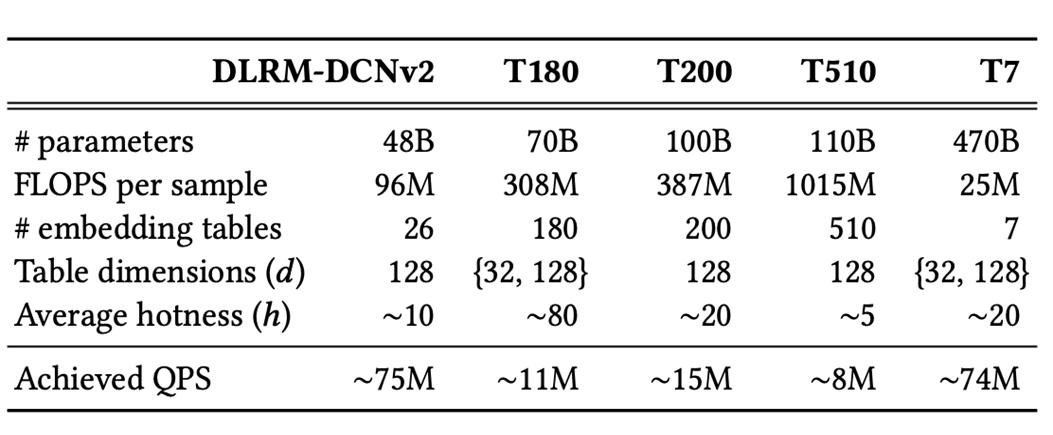
为了展示 EMBark 可以高效训练任何规模的 DLRM 模型,我们测试了使用 MLPerf DLRM-DCNv2 模型并生成了几个具有更大嵌入表和不同属性的合成模型(参见上表)。我们的训练数据集表现出 α=1.2 的幂律偏斜。
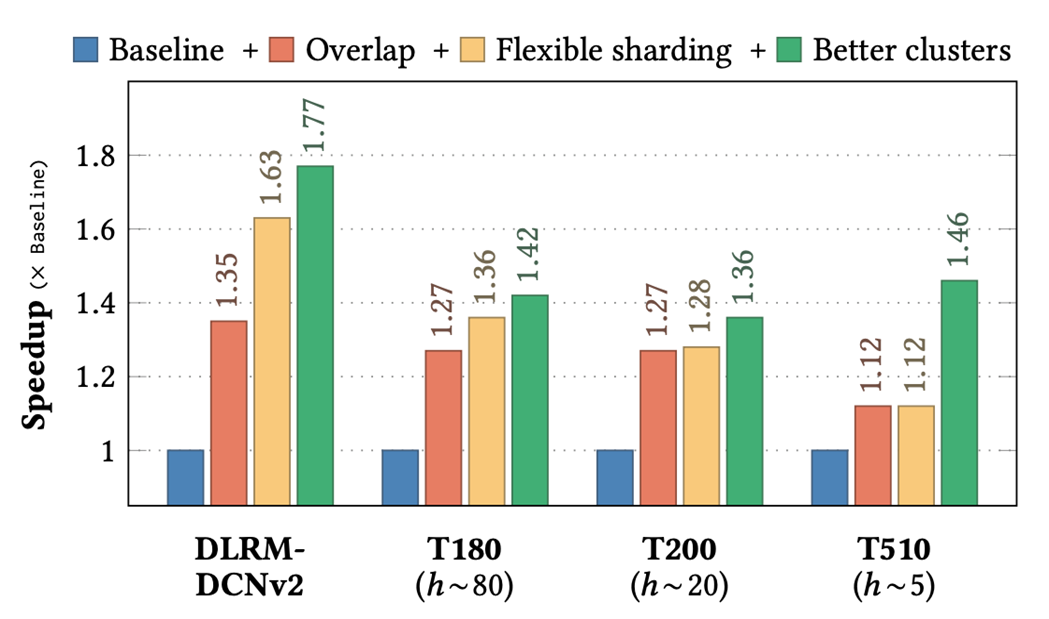
图 4. EMBark evaluation 结果
Baseline 采用串行的 kernel 执行顺序,固定的 table-row-wise 分片策略,以及全部使用了 RB-clusters。实验依次使用了三种优化:overlap、更灵活的分片策略和更好的 clusters 配置。
在四种代表性 DLRM 变体(DLRM-DCNv2、T180、T200 和 T510)中,EMBark 实现了平均 1.5 倍的端到端训练吞吐量加速,比 baseline 快最多 1.77 倍。更详细的实验结果和相关的分析,可以参考论文。
结论
EMBark 针对大规模推荐系统模型训练中 embedding 部分耗时占比过高的问题,通过支持 3D 的自定义 sharding 策略和结合不同的通信压缩策略,能够细粒度的优化大规模集群下深度推荐模型训练的负载不均衡问题以及减少 embedding 需要的通信时间,提高大规模推荐系统模型的训练效率,在四种代表性 DLRM 变体(DLRM-DCNv2、T180、T200 和 T510)中,EMBark 实现了平均 1.5 倍的端到端训练吞吐量加速,比 baseline 快最多 1.77 倍。其中,相关代码和论文皆已开源,希望我们的工作对大家有所帮助。同时,我们也在积极探索 embedding offloading 相关威廉希尔官方网站 和进行 TorchRec 相关优化工作,未来也会及时和大家更新相关进展情况,如果您对这部分感兴趣,也可以联系我们,大家一起交流和探索。
作者简介
刘仕杰
刘仕杰于 2020 年加入 NVIDIA DevTech,主要专注于在 NVIDIA GPU 上性能优化和推荐系统加速。加入 NVIDIA 之后,他主要参与了 Merlin HugeCTR 开发和 MLPerf DLRM 优化等相关工作。
-
NVIDIA
+关注
关注
14文章
4981浏览量
103000 -
推荐系统
+关注
关注
1文章
43浏览量
10075 -
深度学习
+关注
关注
73文章
5500浏览量
121118
原文标题:RecSys’24:使用 EMBark 进行大规模推荐系统训练 Embedding 加速
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
大规模集成电路在信息系统中的广泛应用
大规模特征构建实践总结
大规模MIMO的利弊
大规模MIMO的性能
一个benchmark实现大规模数据集上的OOD检测
Gaudi Training系统介绍

如何使用TensorFlow进行大规模和分布式的QML模拟
使用NVIDIA DGX SuperPOD训练SOTA大规模视觉模型
NVIDIA联合构建大规模模拟和训练 AI 模型
第一个大规模点云的自监督预训练MAE算法Voxel-MAE
PyTorch教程11.9之使用Transformer进行大规模预训练

PyTorch教程-11.9. 使用 Transformer 进行大规模预训练






 工商网监
工商网监
评论