 TI:使用CLT工具优化C6000代码
TI:使用CLT工具优化C6000代码
摘要
在C6000 DSP的开发过程中,优化是必不可少的一个环节,根据对象不同可以分为系统,算法,代码以及内存优化。通常,开发者熟悉自己的代码,会从前三个方面修改以获得整体性能的提升,但是对于内存尤其是缓存(Cache)的优化,因为其涉及到芯片本身的架构,Cache的维护由DSP自动完成,用户通常不能干预,所以似乎无从着手;考虑到这些实际的问题,从TI的7.0系列编译器开始支持使用缓存优化工具(Cache Layout Tools)对C6000代码进行优化,通过这一系列的工具,可以很轻松的完成L1P Cache性能的提升,本文详细介绍了该工具的使用方法。
1.引言
目前,使用TI DSP的用户越来越多,在C6000系列DSP中,包含了C64x, C64x+, C66x等。在C6000 DSP的开发过程中,为了充分利用DSP的计算资源,需要对用户程序进行优化的工作,根据对象不同可以分为系统,算法,代码以及内存优化。通常,开发者熟悉自己的系统和代码,可以比较方便的从前三个方面修改以获得整体性能的提升,但是对于内存尤其是缓存(Cache)的优化,因为其涉及到芯片本身的架构,Cache的维护由DSP自动完成,用户通常不能干预,所以似乎无从着手;考虑到这些实际的问题,从TI 的7.0 系列编译器开始支持使用缓存优化工具(Cache Layout Tools)对C6000代码进行优化,通过这一系列的工具,可以很轻松的完成L1P Cache性能的提升,本文详细介绍了该工具的使用方法。
2.C6000 DSP内核缓存机制
C6000系统的存储器结构如下图所示。

Figure 1.C6000存储器结构
存储器分成三级:第一级是L1,包括数据存储器(L1D)和代码存储器(L1P);第二级是代码和数据共用存储器(L2以及MSMC SRAM);第三级是外部存储器,主要是DDR存储器。L1P、L1D和L2的Cache功能分别由相应的L1P 控制器、L1D控制器和L2控制器完成。
在C6000 DSP中通常我们会把L1P全部配置成Cache,当CPU发出取指命令,首先会从L1P里查找,如果L1P找不到,则到下一级Cache或者Memory里查找,当找到需要的地址,则将其读入L1P里,CPU从中读取执行。
因为L1P Cache的大小是有限的(本文以32KB为例),而用户内存空间一般大于32KB,必须采取一种映射的方式使得所有地址都能被L1P缓存;在C6000 DSP中,L1P Cache使用地址直接映射,所有DSP 核可访问的地址对L1P Cache大小(32K)取模就能得到该地址在L1P Cache的偏移值。
如果用户代码在内存排布不合理,可能会在L1P Cache中发生反复的内容替换,下图中的例子是一个极端情况。

Figure 2. 函数的不正确排布
TOP函数中FOR循环反复调用A 函数,而A,B,C三个函数在内存地址的分布上,与32KB边界的偏移地址是一样的,因此,A,B,C将对应L1P里同一个CACHE位置;其运行流程如下
当执行A时,CPU需要把A函数调入到Cache偏移值N的位置上;
A调用B,此时调入B到Cache偏移值N 的位置上,覆盖A的代码;
B调用C,此时调入C到Cache偏移值N 的位置上,覆盖B的代码;
C返回,下一次循环调入A到Cache中覆盖C的代码。
DSP核对L1P,L2,DDR的访问速度差异很大,对L1P的访问通常在1 个时钟周期内完成,而L2平均需要3-5个周期,DDR访问需要的时间更多,因此我们应该尽量避免上述这种反复重写Cache的情况,尽可能的减少函数在Cache中的置换。
如何解决该问题?最好的解决方法则是将A,B,C在内存中连续排放,这样对Cache的操作次数将降到最低,能够有效的提高执行效率,如下图所示,只要A,B,C总的大小不超过32KB,它们在Cache中的偏移值就是连续的,不会发生覆盖的现象,即使其总和大于32KB,发生置换的也仅仅是超过32K的部分。
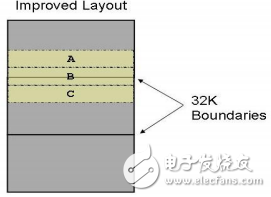
Figure 3. 函数的正确排布
3.内存优化工具
通过上述机制可以看到,对于L1P Cache的优化主要通过分析函数调用关系和其在内存的分布。由于用户代码日益复杂,人工分析代码调用关系和地址排布需要花费大量的时间。因此,从7.0系列编译工具开始,TI提供了一套内存优化工具(Cache Layout Tools)来帮助用户轻松快捷地解决该问题。
该工具的原理是在用户进行程序编译时打开生成分析信息选项,编译器会自动加入分析记录代码到用户程序里,之后用户在TI DSP simulator或者DSP芯片上运行该可执行文件,内置的分析代码会自动记录用户的函数调用关系及调用次数。运行的案例越多,记录的信息会更详细,优化的效果也就越好。
在得到函数运行时信息以后,就可以使用编译器工具对其进行分析,生成函数排布的顺序,最后将此排布顺序输入到编译器里重新编译原代码,生成的可执行文件就已经优化过内存排布,具体的操作可以参照以下实例。
4.实例教程
该实例主要由三个C文件组成,

实例中使用DSP计数器TSCL来统计cycle数,子函数放在sub目录下。
使用实例的步骤如下,
1.编译代码
使用TI编译器对该实例进行编译,为了产生用于profile的信息,需要在编译时增加--gen_profile_info选项。如果使用命令还形式,命令行下运行Compile.bat文件,cl6x的具体参数可以参考spru186和spru187两篇文档,一般可以在编译器的安装目录下找到他们,如C:\Program Files(x86)\Texas Instruments\C6000 Code Generation Tools 7.3.9\doc。
同时在目录下生成OBJ和ASM文件,这个和我们的实验关系不大,可以不用关注。out文件是一会需要下载到芯片里运行的可执行文件,而map文件用于帮助我们定位profile信息存放的内存地址。
如果用户使用CCS编译工具,则需要在Build的属性里指定Feedback选项,然后正常编译即可生成携带分析代码的可执行文件。

Figure 4. CCS初编译的选项
-
C6000代码
+关注
关注
0文章
1浏览量
1174 -
CLT
+关注
关注
0文章
1浏览量
2055
发布评论请先 登录
相关推荐
DSP6000系统介绍
请问有没有针对C6000的功耗估算工具啊?
TI C6000优化startup guide
TI C6000 C674x 全新OMAP-L双核处理器针对

TMS320C6000 DSP 优化应用报告

TMS3C6000 DSP的五个最有效的优化代码详细介绍

CRS编译码原理和在TI C6000 DSP上的优化实现






 工商网监
工商网监
评论