 如何使用 Llama 3 进行文本生成
如何使用 Llama 3 进行文本生成
使用LLaMA 3(Large Language Model Family of AI Alignment)进行文本生成,可以通过以下几种方式实现,取决于你是否愿意在本地运行模型或者使用现成的API服务。以下是主要的几种方法:
方法一:使用现成的API服务
许多平台提供了LLaMA 3的API接口,例如Hugging Face的Transformers库和Inference API。
- 使用Hugging Face Transformers库 :
- 首先,确保你已经安装了
transformers库和torch库。bash复制代码pip install transformers torch - 使用Hugging Face的pipeline进行文本生成。
python复制代码from transformers import pipeline # 加载LLaMA 3模型(注意:实际LLaMA 3模型可能非常大,需要额外下载) generator = pipeline("text-generation", model="meta-research/llama3-7b") # 这里使用7B版本作为示例 # 生成文本 prompt = "Once upon a time, in a faraway kingdom," output = generator(prompt, max_length=50, num_return_sequences=1) for i, text in enumerate(output): print(f"{i+1}: {text['generated_text']}")
- 首先,确保你已经安装了
- 使用Hugging Face Inference API :
- 注册并获取Hugging Face Spaces的API密钥。
- 使用API进行请求。
python复制代码import requests import json HEADERS = { "Authorization": f"Bearer YOUR_API_KEY", "Content-Type": "application/json", } DATA = { "inputs": "Once upon a time, in a faraway kingdom,", "parameters": { "max_length": 50, "num_return_sequences": 1, }, } response = requests.post( "https://api-inference.huggingface.co/models/meta-research/llama3-7b", headers=HEADERS, data=json.dumps(DATA), ) print(response.json())
方法二:在本地运行LLaMA 3
由于LLaMA 3模型非常大(从7B参数到65B参数不等),在本地运行需要强大的计算资源(如多个GPU或TPU)。
- 准备环境 :
- 确保你有一个强大的计算集群,并安装了CUDA支持的PyTorch。
- 下载LLaMA 3的模型权重文件(通常从Hugging Face的模型库中获取)。
- 加载模型并生成文本 :
- 使用PyTorch加载模型并进行推理。
python复制代码import torch from transformers import AutoTokenizer, AutoModelForCausalLM # 加载模型和分词器 tokenizer = AutoTokenizer.from_pretrained("meta-research/llama3-7b") model = AutoModelForCausalLM.from_pretrained("meta-research/llama3-7b") # 准备输入文本 prompt = "Once upon a time, in a faraway kingdom," inputs = tokenizer(prompt, return_tensors="pt") # 生成文本 outputs = model.generate(inputs.input_ids, max_length=50, num_return_sequences=1) # 打印生成的文本 print(tokenizer.decode(outputs[0], skip_special_tokens=True))
- 使用PyTorch加载模型并进行推理。
注意事项
- 计算资源 :LLaMA 3模型非常大,尤其是更高参数版本的模型,需要强大的计算资源。
- 模型加载时间 :加载模型可能需要几分钟到几小时,具体取决于你的硬件。
- API限制 :如果使用API服务,请注意API的调用限制和费用。
通过上述方法,你可以使用LLaMA 3进行文本生成。选择哪种方法取决于你的具体需求和计算资源。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
API接口
+关注
关注
1文章
84浏览量
10437
发布评论请先 登录
相关推荐
如何构建文本生成器?如何实现马尔可夫链以实现更快的预测模型
准确的,内存少(只存储1个以前的状态)并且执行速度快。文本生成的实现这里将通过6个步骤完成文本生成器:1、生成查找表:创建表来记录词频2、将频率转换为概率:将我们的发现转换为可用的形式3
发表于 11-22 15:06
基于生成对抗网络GAN模型的陆空通话文本生成系统设计
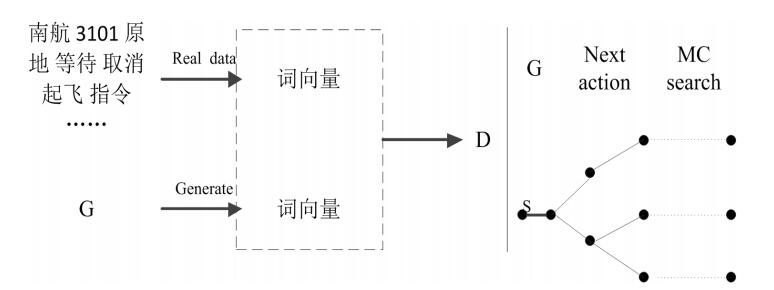
可以及时发现飞行员错误的复诵内容。考虑到训练一个有效的差错校验网络模型需要大量的文本数据,本文提出一种基于生成对抗网络GAN的陆空通话文本生成方法。首先对现有真实的陆空通话文本
发表于 03-26 09:22
•34次下载
基于生成器的图像分类对抗样本生成模型
,并保证攻击成功率。模型将对抗样本生成的过程视为对原图进行图像増强的操作引入生成对抗网络,并改进感知损失函数以增加对抗样本与原图在内容与特征空间上的相似性,采用多分类器损失函数优化训练从而提高攻击效率。实
发表于 04-07 14:56
•2次下载

基于生成式对抗网络的深度文本生成模型
评论,对音乐作品自动生成评论可以在一定程度上解决此问题。在在线唱歌平台上的评论文本与音乐作品的表现评级存在一定的关系。因此,研究考虑音乐作品评级信息的评论文本自动生成的方为此提出了一种
发表于 04-12 13:47
•15次下载

文本生成任务中引入编辑方法的文本生成
4. FELIX FELIX是Google Research在“FELIX: Flexible Text Editing Through Tagging and Insertion”一文中提出的文本生成

受控文本生成模型的一般架构及故事生成任务等方面的具体应用
来自:哈工大讯飞联合实验室 本期导读:本文是对受控文本生成任务的一个简单的介绍。首先,本文介绍了受控文本生成模型的一般架构,点明了受控文本生成模型的特点。然后,本文介绍了受控文本生成技
基于GPT-2进行文本生成
文本生成是自然语言处理中一个重要的研究领域,具有广阔的应用前景。国内外已经有诸如Automated Insights、Narrative Science以及“小南”机器人和“小明”机器人等文本生成
深度学习——如何用LSTM进行文本分类
简介 主要内容包括 如何将文本处理为Tensorflow LSTM的输入 如何定义LSTM 用训练好的LSTM进行文本分类 代码 导入相关库 #coding=utf-8 import
基于VQVAE的长文本生成 利用离散code来建模文本篇章结构的方法
写在前面 近年来,多个大规模预训练语言模型 GPT、BART、T5 等被提出,这些预训练模型在自动文摘等多个文本生成任务上显著优于非预训练语言模型。但对于开放式生成任务,如故事生成、新闻生成
通俗理解文本生成的常用解码策略
“Autoregressive”语言模型的含义是:当生成文本时,它不是一下子同时生成一段文字(模型吐出来好几个字),而是一个字一个字的去生成。"Autoregressive"
Meta提出Make-A-Video3D:一行文本,生成3D动态场景!
具体而言,该方法运用 4D 动态神经辐射场(NeRF),通过查询基于文本到视频(T2V)扩散的模型,优化场景外观、密度和运动的一致性。任意机位或角度都可以观看到提供的文本生成的动态视频输出,并可以
ETH提出RecurrentGPT实现交互式超长文本生成
RecurrentGPT 则另辟蹊径,是利用大语言模型进行交互式长文本生成的首个成功实践。它利用 ChatGPT 等大语言模型理解自然语言指令的能力,通过自然语言模拟了循环神经网络(RNNs)的循环计算机制。

面向结构化数据的文本生成威廉希尔官方网站 研究
今天我们要讲的文本生成是现在最流行的研究领域之一。文本生成的目标是让计算机像人类一样学会表达,目前看基本上接近实现。这些突然的威廉希尔官方网站
涌现,使得计算机能够撰写出高质量的自然文本,满足特定的需求。

Meta发布一款可以使用文本提示生成代码的大型语言模型Code Llama
今天,Meta发布了Code Llama,一款可以使用文本提示生成代码的大型语言模型(LLM)。

Meta Llama 3基础模型现已在亚马逊云科技正式可用
亚马逊云科技近日宣布,Meta公司最新发布的两款Llama 3基础模型——Llama 3 8B和Llama





 工商网监
工商网监
评论