 回顾2017年有趣的新发行的数据库
回顾2017年有趣的新发行的数据库
概要:数据库世界并不是每周都有让人不可思议的新闻,但在一年的时间里,我还是惊讶地发现,我们看到了很多新事物,以及该领域坚持不懈地发展。
作为 Database Weekly 的编辑(Database Weekly 是一份关于数据库和数据存储世界新内容的每周时事资讯),我喜欢在新的数据库系统中闲逛,看看在未来的几十年里,哪些想法可能会影响到日常的开发人员。
数据库世界并不是每周都有让人不可思议的新闻,但在一年的时间里,我还是惊讶地发现,我们看到了很多新事物,以及该领域坚持不懈地发展。2017 年也不例外,所以我想回顾一下一些有趣的新发行版,包括一个事务性图表数据库,一个可复制的地理多模型数据库,以及一个新的高性能键/值存储数据库。
TimescaleDB — 一款基于 Postgres 的能自动分区的时间序列数据库
其中一个令人兴奋的新扩展源于 PostgreSQL,Timescale 基于 Apache 2.0 的许可,它是由一个名为 PhD-packed 的机构支持启动的。
Timescale 通过自动分区为 Postgres 添加时间序列存储功能,但是却包含在寻常的 Postgres 界面和工具中。 查询是使用常规的 SQL 对“提供与时间序列数据的接口” 的 “hypertable” 进行的。

Microsoft Azure Cosmos DB — 微软的多模式数据库
Cosmos DB 本质上是 Azure 的旧的 DocumentDB 的品牌重塑和重新构建,但是它很容易实现将全球分布式数据跟 Azure 的多样数据中心交叉。全球分布是 Cosmos DB 的杀手锏,并且它可以将数据库请求路由到包含数据的最近区域,而不需要更改配置。
“多模式”的部分也很重要。虽然一切都在无模式的 JSON 的引擎盖下,但依然有一个 SQL 查询 API ,以及 MongoDB API、Cassandra API,甚至一个图形数据库 API(基于 Gremlin )。
学习更多关于 Cosmos 的较好的方式之一是这个微软的第9频道的 15 分钟视频介绍。
Cloud Spanner — Google 全球分布式关系数据库
Google 的 Cloud Spanner 已经工作了很长一段时间了,起初是在 2012 年一篇非常有趣的学术论文中公开阐释的(虽然开发始于 2007 年)。最初的开发是因为 Google 需要一个全球化分布式的高可用性存储系统,但其现在也向公众开放。
谷歌认识到,使 Cloud Spanner 适合其自身用途的功能对企业也很有吸引力,因此它承诺 99.999% 的可用性、无计划停机时间和“企业级”安全性。
Cloud Spanner 支持 ANSI 2011 SQL ,为已熟悉关系数据库概念的开发人员提供了经过战斗级测试的高可用性水平扩展的关系数据库。
Neptune — Amazon 的全面管理图形数据库服务
Microsoft 和 Google 我们都已经讲到了, 所以怎么能漏了 Amazon 呢? 这是另外一个受限于特定云服务的数据库, Amazon 在最近召开的 re:Invent 大会上展示了 Neptune 的预览。
Neptune 承诺会是一个快速且可靠的图形数据库服务,其目的是能迅速地为开发者提供图形数据库服务,并且不会让他们感到麻烦,当然这些是要付费的。
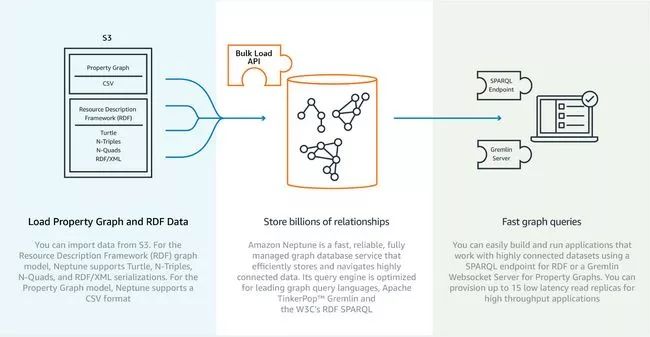
Neptune 支持用两种标准来对你的图形库进行查询, 一个是得到越来越多的支持的 Gremlin 的“黄金”标准,还有就是 SPARQL (你的图形会被当作是一个 RDF )。
YugaByte — 一个开源的云原生数据库
YugaByte 今年因其“隐形模式”脱颖而出,它提供了一个支持 SQL 和 NoSQL 操作模式的数据库。目的是在云中直接使用,充当对容器的有状态补充。
YugaByte 使用 C ++ 构建并开源,支持 Cassandra 查询语言(CQL)以及 Redis 协议。 对 PostgreSQL 协议的支持正在进行中,Spark 应用可在上面运行。
YugaByte 是另一个启动后才受到支持的项目(由扩展了 Apache HBase 平台的一位 Facebook 工程师创建),其业务模式初定是会有一个“企业版”,在开源社区版的基础上增加多云集群协调 ,监视和警报,分层存储和支持等特性。
Peloton — 一个自驱动的 SQL DBMS
Peloton 探索了一些有趣的想法,特别是在使用 AI 来自动优化数据库的领域。它还支持字节寻址 NVM 存储威廉希尔官方网站 ,并且是使用 Apache 许可开源的。
“自驱动”数据库背后的想法是,DBMS 可以自主操作和调整自身。它可以预测工作负载的趋势,并据此做好准备,而无需 DBA 或操作员掌控。
也许毫不奇怪的是,Peloton 源于一个学术项目(特别是来自卡内基梅隆大学),其创建者之一写了一篇关于为什么它被创建的系列文章。它已经开发好几年了,但在 2017 年变得更加开放。
JanusGraph — 一个基于 Java 的分布式图形数据库
JanusGraph 是一个实用的、随时可用的数据库,其中包含大量的集成,并且建立在 TitanDB 的坚实基础之上。它针对可扩展性、存储及查询巨大图形数据库做了优化,同时支持事务和大量并发用户。
它可以使用 Cassandra、HBase、Google Cloud Bigtable 和 BerkeleyDB 作为存储后端,并且可以与 Spark、Giraph 和 Hadoop 直接整合。它甚至支持与 ElasticSearch、Solr 或 Lucene 集成的全文和地理位置检索。
Aurora Serverless — AWS 上即时可伸缩,“即付即用”的关系型数据库
另一个来自 Amazo re:Invent 会议的公告是他们成功的 Aurora 数据库服务的无服务器版本,Aurora Serverless。
随着整合到“无服务器”平台的最新趋势,这个平台将永远消除你在扩展和操作上的难题,Aurora Serverless背后的理念是许多数据库用例不需要一致的性能或使用水平,相反,你可以“随时付费”(逐秒付费),以便按需调整数据库的大小。
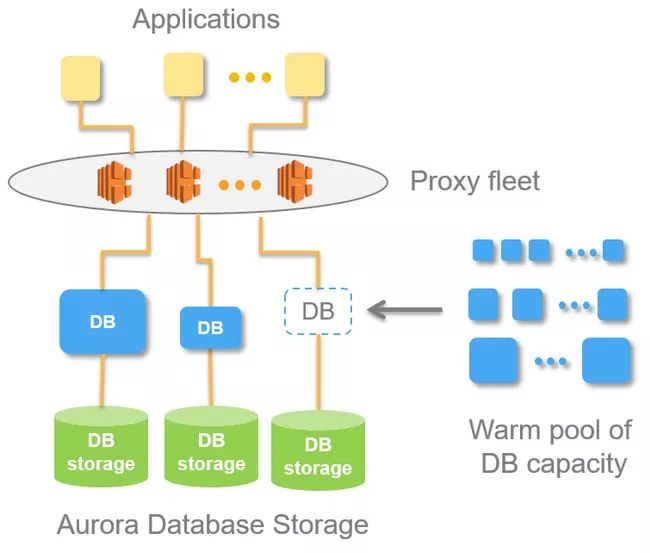
它目前仅是预览版,但承诺在 2018 年会有重大进展。
TileDB — 用于存储大密度及稀疏矩阵数组
TileDB 是起源自麻省理工学院和英特尔的数据库,用于存储多维阵列数据,这是类似基因科学、医学成像和金融时间序列等领域常见的要求。
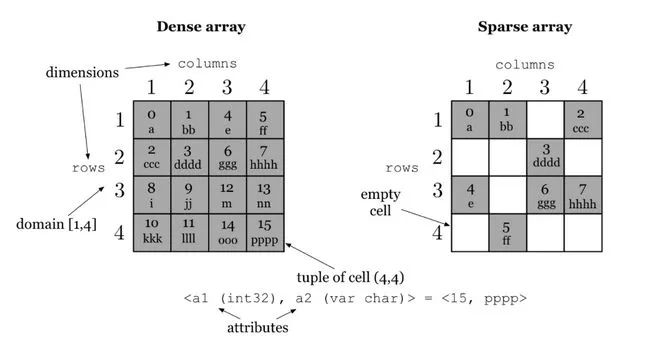
它支持许多压缩机制(如 gzip、lz4、Blosc 和 RLE )和存储后端(如 GFS、S3 和 HDFS )。
Memgraph — 一个高性能、可内存驻留的图形数据库
Memgraph 背后的驱动力是为快速分析和使用来自人造和机器智能的数据以及设备和物联网不断增长的互联性提供工具。因此,优先事项是“速度、可伸缩和简单性”。
在 Memgraph 的生命周期中,它还处于早期阶段,它不是开源的,但可以通过 request 下载。它支持 openCypher 图形查询语言,支持内存中的 ACID 事务,并具有基于磁盘的持久化机制。
-
数据库
+关注
关注
7文章
3798浏览量
64370
原文标题:回顾 2017 年发布的 10 个新数据库系统
文章出处:【微信号:AItists,微信公众号:人工智能学家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
2017双11威廉希尔官方网站 揭秘—阿里巴巴数据库威廉希尔官方网站 架构演进
阿里云云数据库开了一个未来大会,谈了谈2038年的数据库趋势
hadoop最新发行稳定版:DKHadoop版本选择详解
什么是支持数据库,什么是中宏数据库
数据库教程之如何进行数据库设计
数据库学习教程之数据库的发展状况如何数据库有什么新发展
华为正式宣布开源数据库能力,开放openGauss数据库源代码
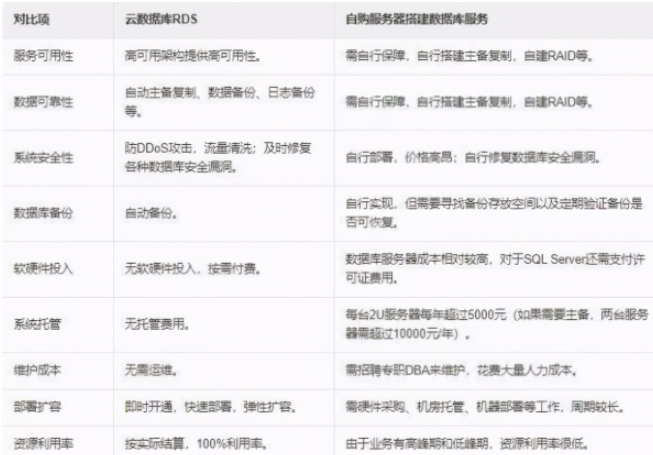
云数据库和自建数据库的区别及应用

华为云数据库-RDS for MySQL数据库
python读取数据库数据 python查询数据库 python数据库连接
2024年,国产数据库正酝酿新变局!
数据库数据恢复—通过拼接数据库碎片恢复SQLserver数据库






 工商网监
工商网监
评论