 软件设计哲学 于延保代码改造中的实践
软件设计哲学 于延保代码改造中的实践
作者:京东保险 王奕龙
本文主要给大家分享软件设计中的两个理念,为什么我称软件设计是“理念”而不是“方法”或“原则”呢?这个想法主要受《A philosophy of software design》的影响,它将软件设计称为“哲学”,而哲学本身没有严格的定论,同样地,我觉得软件设计是每个开发者的理念,相同功能的迭代,往往会有不同的看法或思想,也所谓每个人的代码风格,所以本次分享不求同,只求能给大家带来一点启发。两个理念如下:
没有一蹴而就的设计:软件设计不会停止,需要随着功能迭代(增量开发)更新现有设计,因为在迭代过程中相关开发、业务经验不断累积,必然会产生更好的设计方式,最初的设计通常不是最好的
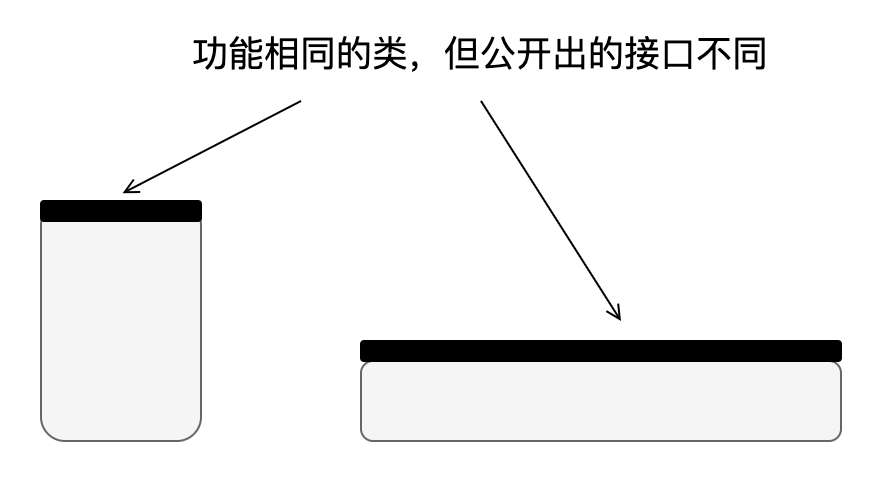
坚持“深”模块设计:“深”这个观点来自 《A philosophy of software design》,它将每个模块看作一个矩形,如下图所示:
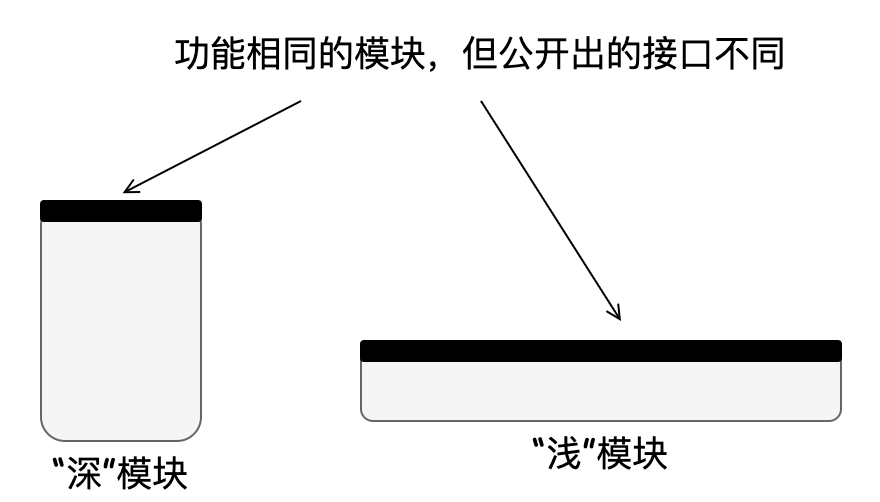
矩形的面积代表模块提供的功能,顶部边缘代表模块公开出的接口,边缘长度代表接口的复杂性,越长接口越复杂。设计较好的模块比较深,因为它在简单的接口后隐藏了许多功能,其内部的复杂性只有一小部分对开发者可见。坚持深模块设计也就意味着提供调用简单但功能强大的接口。
这两个理念,我想通过实际的业务开发:延保补购功能迭代来叙述,在开始之前我想先给大家简单介绍一下什么是延保的补购:
延保补购是购买商品时未购买延保,事后再为该商品购买延保的行为。比如双十一购买了一部手机,期望能用五年,但是下单时,没有一起购买延保,之后再去补购 “五年只换不修” 的延保便是延保的补购。
目前在京东商城“延保服务”频道页能进行补购,大家可以在商城搜索 “延保”点击“京东延保”跳转:
业务逻辑介绍
为方便大家理解,我将其中的逻辑做了一些简化,在查询用户可补购的订单时,它会执行如下逻辑:
/** * AddBuy 作为补购的代码命名定义,定义补购相关门面接口 */ public class AddBuyFacadeServiceImpl implements AddBuyFacadeService { // 补购相关订单查询 Service @Resource private AddBuyOrderQueryService orderQueryService; // 补购相关延保查询 Service @Resource private AddBuyYbQueryService ybQueryService; // 延保结果构建 Service @Resource private AddBuyBuildService buildService; /** * 查询多条可补购延保的订单信息 */ @Override public List< AddBuyResult > queryList(AddBuyListRequest req) { // 1. 查询主商品订单 OrderInfoRequest orderInfoRequest = new OrderInfoRequest(); orderInfoRequest.setUserNo(req.getUserNo()); // ... List< OrderInfo > orderInfoList = orderQueryService.listOrderInfo(orderInfoRequest); // 2. 查询这些订单可购买的延保信息 YbInfoRequest ybInfoRequest = new YbInfoRequest(); ybInfoRequest.setUserNo(req.getUserNo()); // ... // key: orderNo value: ybInfoList Map< String, List< YbInfo >> orderNoYbListMap = ybQueryService.listYbInfo(ybInfoRequest); // 3. 封装订单和推荐延保信息 return buildService.buildRecommendInfo(orderInfoList, orderNoYbListMap); } }
执行步骤如下:
先查询主商品订单
查询这些订单可购买的延保信息
封装订单和推荐延保信息
补购功能会被推广到很多不同的 渠道 使用,渠道指的是补购功能推广的范围,包括微信(WEI_XIN)和PLUS客服推广(PLUS)等等:
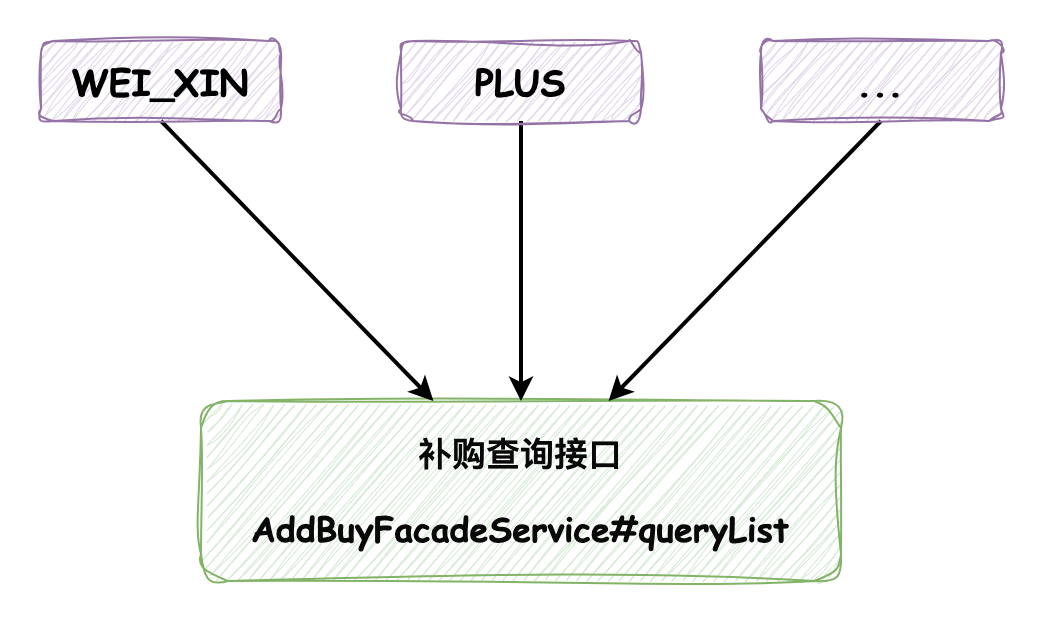
这个渠道值会在查询做标记,如下所示为补购查询请求对象 AddBuyListRequest:
public class AddBuyListRequest { private String userNo; // 渠道值信息 private String channel; // ... }
功能迭代
初期功能并没有针对渠道参数做校验和管理,也就是说前端传什么后端就接什么,导致出现了异常的XXX未知渠道。为了对渠道进行管控,并根据现有渠道做个性化补购,现在便需要在此基础上迭代“渠道管控”的功能:
渠道值校验:校验未知的渠道值,对现有渠道进行管理
个性化补购:指定渠道查询 固定品类 的延保等定制化逻辑,比如规定渠道 “PLUS” 渠道只能查询 “手机” 品类的延保
为满足功能,首先定义 ChannelConfig 渠道配置类,其中包含如下字段:
public class ChannelConfig { /** * 渠道 */ private String channel; /** * 要查询的主品一级类目编码 */ private List< String > mainFirstCategoryCodeList; // ... }
初版设计
初版设计时,定义 channelConfigMap 以 key: channel value: config 的形式维护所有渠道值,在方法 queryList 执行时,会先校验渠道的存在,存在的话继续执行逻辑,并把 config 对象 透传 到各个查询方法中,以执行筛选指定品类等定制化逻辑,如下:
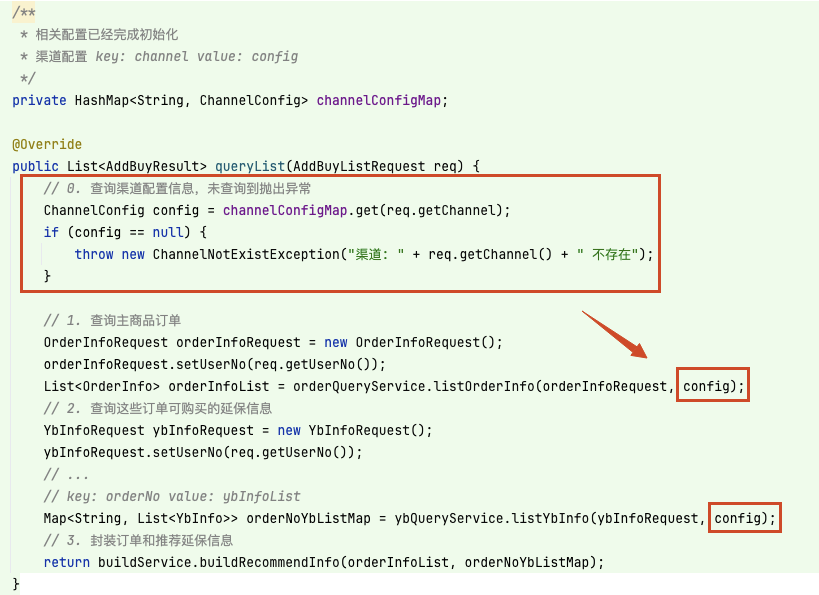
在方法 queryList 中,可以发现渠道配置几乎 贯穿了接口逻辑执行的始终,虽然对该方法的改动并不大,但对于其中的查询方法 listOrderInfo 和 listYbInfo 来说,会使它们的方法复用变得困难。
如果想复用其中查询订单的接口(其中第 1 步逻辑):
List< OrderInfo > listOrderInfo(OrderInfoRequest orderInfoRequest, ChannelConfig config);
在构建查询入参的时候就难免不对渠道配置 ChannelConfig config 参数产生疑问:“这个入参的作用是什么”?点进去看它的字段:如果发现有很多字段,那么开发者大概率不会去了解每个字段的含义,并且也没办法记住这么多字段的作用是什么,这就会导致开发者直接去看 listOrderInfo 方法的实现,分析其中哪些字段是有用的,哪些是没用的。这使得一件本可以简单查看方法入参 OrderInfoRequest 便能复用该方法的事情变得异常复杂,需要了解太多查询订单信息之外的知识,大大增加了认知负荷。
从本质上去考虑:“在调用查询订单接口时,我们需要了解‘渠道配置’相关的内容吗?”,显然是不需要的,否则为通用查询接口带来的复杂性就太高了,进而使得接口变“浅”。
那么该如何避免这些问题呢?最初我想到两种简单的办法:
详细的配置注释:将配置的每个字段描述的足够清楚,那么使用该接口的研发人员不需要去了解代码实现便能知道根据渠道如何添加一个合适的配置入参
查询方法实现中添加配置默认值兜底:解决调用者不传该参数或者某些字段为空的特殊情况,降低复用难度
但是这样并不解决根本问题,入参中包含渠道配置依然会暴露其带来的复杂性。如果开发者要复用该 listOrderInfo 方法并筛选特定品类的订单,那么需要写如下逻辑:
/** * 复用 listOrderInfo 方法样例 */ public void reuseExample(Request req) { OrderInfoRequest orderInfoRequest = new OrderInfoRequest(); orderInfoRequest.setUserNo(req.getUserNo()); ChannelConfig config = new ChannelConfig(); // 赋值指定的品类编码 config.setMainFirstCategoryCodeList(Collections.singleton("1234")); List< OrderInfo > orderInfoList = orderQueryService.listOrderInfo(orderInfoRequest, config); // ... }
一旦筛选条件中涉及渠道配置中的字段,都要创建一个渠道配置 ChannelConfig 对象,都要去了解这个类中定义了哪些字段。
这时候我就在想,那么为何不将渠道配置 ChannelConfig 中的字段都提出来放到另一个参数 OrderInfoRequest 中呢?那么这样在入参中便能不再传入渠道配置了,如下所示:
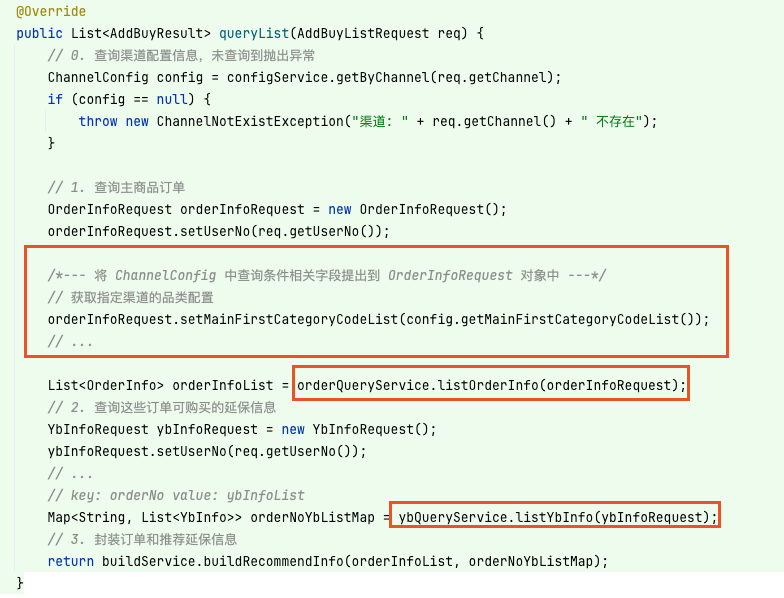
这样当开发者复用 listOrderInfo 方法时,只需关注 OrderInfoRequest 对象并为相关字段赋值即可,这样通用的订单查询接口便无需再关注渠道配置相关的内容了。
但是到这里还没完,有一点值得考虑:渠道配置信息 ChannelConfig 作为 不可变的对象,并不应该被公开出来,而且在一般情况下,开发者会习惯使用 Lombok 的注解 @Data 为类做标注,如下:
@Data public class ChannelConfig { // ... }
这样它每个字段的写(set)操作都是公开(public)的,一旦对原本不可变的数据进行修改,那么因此产生的问题将非常难排查。相对应地,在《重构》一书中,提到过类似观点:“对于所有可变的数据,只要它的作用域超出单个方法,我就会将其封装起来,只允许通过方法访问,数据的作用域越大,封装就越重要,因为这样能够很清楚的知道哪些地方读了这些数据或写了这些数据,如果我们想避免其他开发者修改这个对象的话,那么就可以不公开出 set 方法”。
对 @Data 的观点:@Data 注解实际上有些被滥用,在面向对象的开发中,通常我们都会把类内字段声明为 private,但是又在类上标记 @Data 注解,为每个字段生成 Getter 和 Setter 方法,使得 private 失效。虽然多数时候并不会引发问题,但是更好的做法应该是针对字段指定 Getter 和 Setter 方法,而不是泛泛的生成全部,特别是如果要定义某些不可变的字段时,要尤为注意。此外,当整个对象都不可变时,每次获取该对象时返回它的深拷贝也是很有必要的,否则其被修改后,引发的线上问题非常难定位和排查,这个对象被使用的越多,则越需要警惕。
所以,我们需要将渠道配置对象隐藏起来。
信息隐藏
为了不暴露 ChannelConfig 对象,定义渠道配置服务 ChannelConfigService,并提供校验渠道的方法,如下:
public interface ChannelConfigService { /** * 校验渠道是否存在,否则抛出异常 * * @throws ChannelNotExistException 渠道不存在异常 */ void checkChannelExist(String channel) throws ChannelNotExistException; // ... } @Service public class ChannelConfigServiceImpl implements ChannelConfigService { /** * 渠道配置 key: channel value: config */ private HashMap< String, ChannelConfig > channelConfigMap; @Override public void checkChannelExist(String channel) throws ChannelNotExistException { if (StringUtils.isBlank(channel) || !channelConfigMap.containsKey(channel)) { throw new ChannelNotExistException("渠道: " + req.getChannel() + " 不存在"); } } }
这样将保存渠道配置的 Map channelConfigMap 就下沉到了 ChannelConfigServiceImpl 实现中,queryList 方法中将不再暴露 ChannelConfig 对象,校验渠道值边以方法的形式,如下:

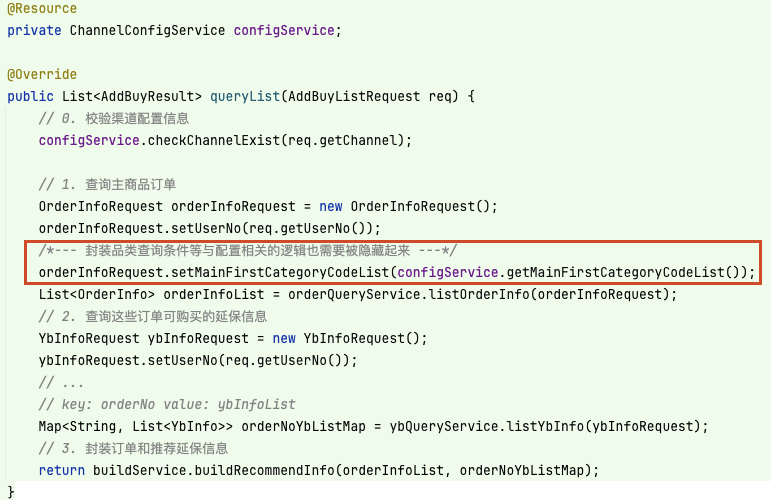
同样地,封装品类查询条件等与配置相关的逻辑也需要被隐藏起来,因为已经没有渠道配置 config对象了,那么这部分该如何处理呢?
我是这样做的:在渠道配置服务中 ChannelConfigService 定义获取品类配置的方法 getMainFirstCategoryCodeList,这样便无需公开渠道配置对象了:
public interface ChannelConfigService { /** * 获取主品类目编码配置,默认值为空列表对象 */ List< String > getMainFirstCategoryCodeList(String channel); // ... } @Service public class ChannelConfigServiceImpl implements ChannelConfigService { /** * 渠道配置 key: channel value: config */ private HashMap< String, ChannelConfig > channelConfigMap; // ... @Override public List< String > getMainFirstCategoryCodeList(String channel) { ChannelConfig config = channelConfigMap.get(channel); // 默认返回空 List if (config == null || CollectionUtils.isEmpty(config.getMainFirstCategoryCodeList())) { return Collections.emptyList(); } return Collections.unmodifiableList(config.getMainFirstCategoryCodeList()); } }
开发者只需根据接口公开出的方法来获取相应的配置信息即可,并不需要对渠道配置对象 ChannelConfig 做了解,改动如下:
做过头了
还有一种方式是将渠道配置服务 ChannelConfigService 注入到订单查询服务 AddBuyOrderQueryService 中,并添加渠道配置相关的处理逻辑:
@Service public class AddBuyOrderQueryServiceImpl implements AddBuyOrderQueryService { @Resource private ChannelConfigService configService; @Override public List< OrderInfo > listOrderInfo(OrderInfoRequest orderInfoRequest) { // ... // 过滤一级品类,如果没有指定则取渠道配置的一级品类配置 List< String > firstCategoryCodeList; if (CollectionUtils.isNotEmpty(orderInfoRequest.getMainFirstCategoryCodeList())) { firstCategoryCodeList = orderInfoRequest.getMainFirstCategoryCodeList(); } else { firstCategoryCodeList = configService.getMainFirstCategoryCodeList(orderInfoRequest.getChannel()); } processMainFistCategory(firstCategoryCodeList); // ... } }
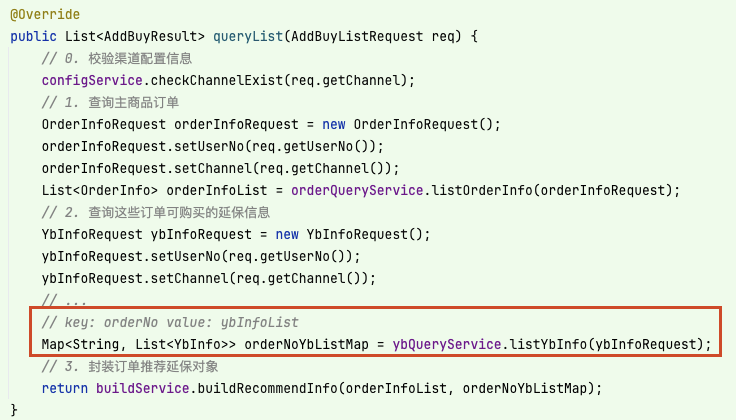
虽然这样做将渠道配置相关信息隐藏得更深,几乎不暴露到补购查询 queryList 逻辑中,如下:

但是有一个问题需要考虑:订单查询接口属于通用查询接口,将渠道配置服务 ChannelConfigService 下沉到其中,便使订单和渠道的知识发生耦合,并且在逻辑中存在依赖,渠道配置的改动可能会影响通用的订单查询。这样做,可能就有些过头了。
扩展性设计对复杂度的管理
随着业务发展,有新的服务方提供延保的查询服务(对应代码中步骤 2),这些服务需要接入现有补购逻辑中,并根据渠道的不同,查询不同的延保服务。
这是非常典型的策略模式应用场景,原有延保查询服务和新增的延保查询服务都将作为不同的策略来实现。借助策略模式实现扩展性并不困难,常见的有两种实现方法,但是它们对策略带来的复杂性处理是不同的:
第一种保持延保查询服务 AddBuyYbQueryService 公开的方法不变,使用静态代理模式在其实现中 AddBuyYbQueryServiceImpl 借助 HashMap 保存所有策略,并根据渠道的不同执行不同的策略:
public interface AddBuyYbQueryService< T > { Map< String, List< T >> listYbInfo(YbInfoRequest ybInfoRequest); } /** * 实现 ApplicationContextAware 用于注入 ApplicationContext 获取想要的策略(Bean) * 实现 InitializingBean 用于在应用启动时,根据策略类型 AddBuyYbQueryStrategy 加载所有的策略 */ @Service public class AddBuyYbQueryServiceImpl implements AddBuyYbQueryService< T >, ApplicationContextAware, InitializingBean { private ApplicationContext applicationContext; private HashMap< String, AddBuyYbQueryStrategy > nameServiceMap; // 渠道配置 Service @Resource private ChannelConfigService configService; @Override public Map< String, List< T >> listYbInfo(YbInfoRequest ybInfoRequest) { String ybType = configService.getYbType(ybInfoRequest.getChannel()); // 通过定义枚举实现 ybType 与具体策略实现的关联 YbQueryStrategyEnum strategyEnum = YbQueryStrategyEnum.parseByType(ybType); AddBuyYbQueryStrategy ybQueryStrategy = nameServiceMap.get(strategyEnum.getQueryServiceName()); return ybQueryStrategy.listYbInfo(ybInfoRequest); } @Override public void afterPropertiesSet() { nameServiceMap = new HashMap< >(); nameServiceMap.putAll(applicationContext.getBeansOfType(AddBuyYbQueryStrategy.class)); } @Override public void setApplicationContext(ApplicationContext applicationContext) throws BeansException { this.applicationContext = applicationContext; } }
策略 AddBuyYbQueryStrategy 接口方法签名与延保查询服务 AddBuyYbQueryService 中方法签名一致,它们的类关系图如下所示:
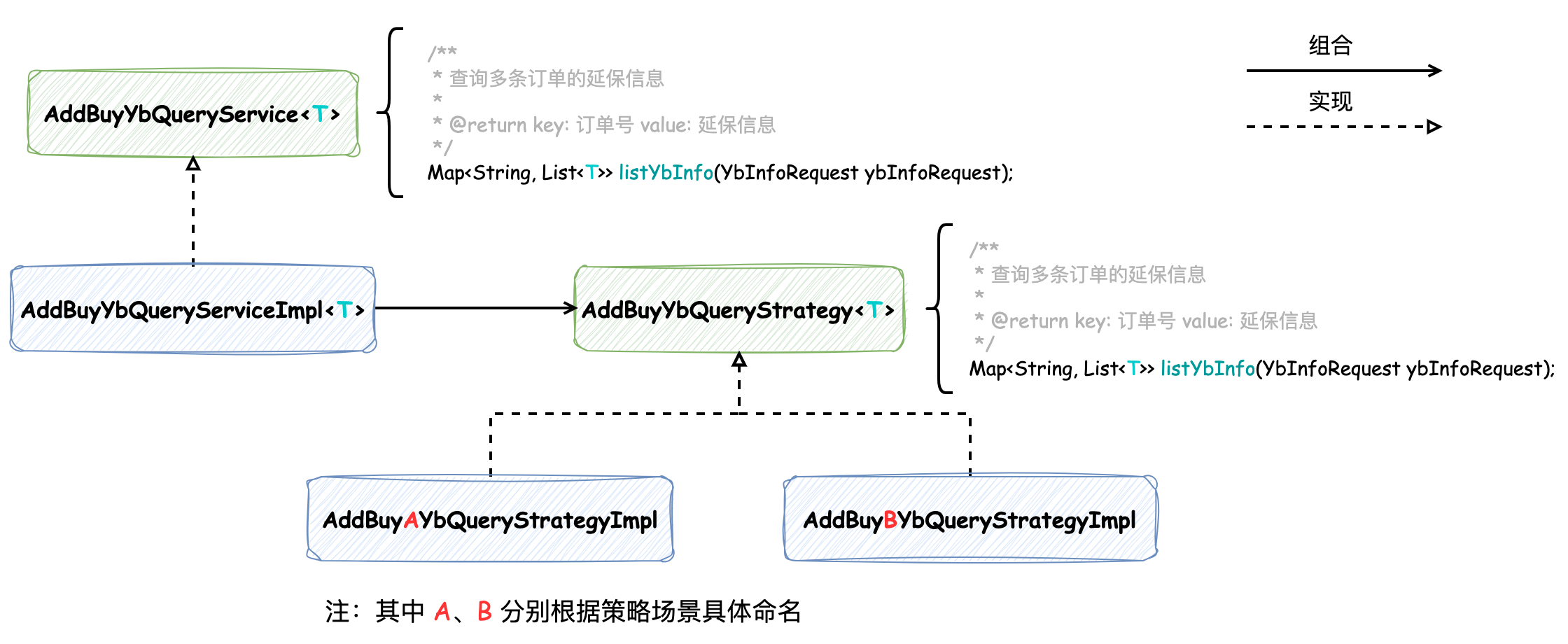
延保查询服务 AddBuyYbQueryService 的 listYbInfo 方法不变,那么 原方法 queryList 逻辑也不需要改变,这样便将策略带来的复杂度隐藏了起来。
第二种是创建策略上下文 AddBuyYbQueryStrategyContext,将对应的策略管理起来并通过调用 getSpecificStrategy 直接暴露具体的策略,如下:
public interface AddBuyYbQueryStrategyContext< T > { AddBuyYbQueryStrategy< T > getSpecificStrategy(YbInfoRequest ybInfoRequest); }
那么这样对原方法的改动如下:
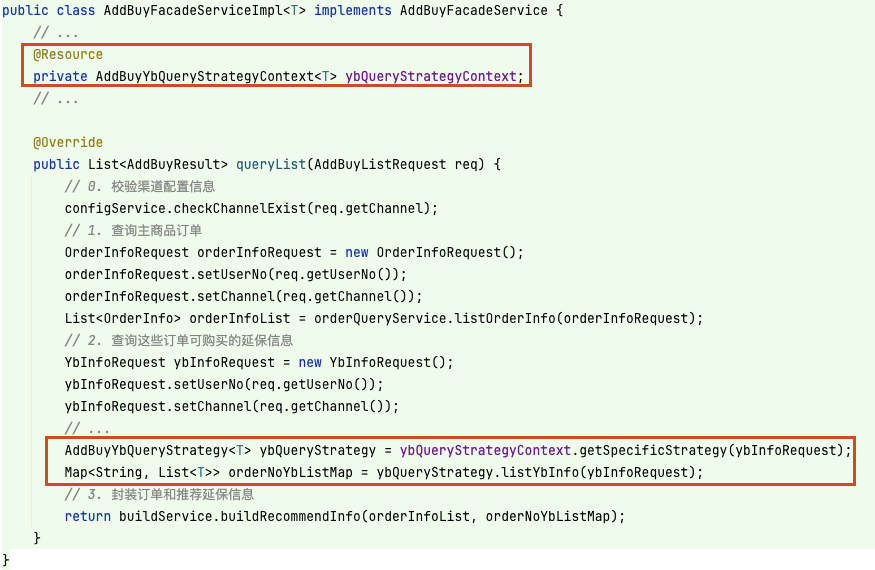
这样会将使用策略模式的复杂度暴露到原方法 queryList 中,实际上开发者在这个方法中不需要了解策略该如何分配等相关逻辑。
封装推荐延保信息的逻辑(其中第 3 步)由于引入了不同类型的延保服务,也需要根据不同的延保对象类型适配相应的策略,同样需要使用策略模式,但实现逻辑类似,不再赘述,不过不同点是该步骤一并使用了模板方法模式:
封装订单和推荐延保信息的 buildRecommendInfo 方法主要步骤为封装订单信息(initialMainOrderInfo)和封装推荐的延保信息(initialRecommendYbInfo),其中封装订单信息的逻辑是通用的,而封装推荐的延保信息步骤需要分别处理不同的延保类型,所以借助了模板方法模式。将后者其定义为抽象方法,由子类不同的策略去分别实现,抽象模板类如下:
public abstract class AbstractAddBuyBuildService< T > implements AddBuyBuildStrategy< T > { @Override public List< AddBuyResult > buildRecommendInfo(List< OrderInfo > orderInfoList, Map< String, List< T >> orderNoYbListMap) { List< AddBuyResult > res = new ArrayList< >(orderNoYbListMap.size()); // Group By OrderNo Map< String, OrderInfo > orderNoOrderInfoMap = orderInfoList.stream().collect(Collectors.toMap(OrderInfo::getOrderid, x -> x)); // orderNoBindListEntry: (key: 订单号;value: 订单对应的延保信息) for (Map.Entry< String, List< T >> orderNoYbListEntry : orderNoYbListMap.entrySet()) { // 订单信息 OrderInfo orderInfo = orderNoOrderInfoMap.get(orderNoYbListEntry.getKey()); // 延保信息 List< T > ybList = orderNoYbListEntry.getValue(); AddBuyResult element = new AddBuyResult(); // 1. 封装订单信息 MainOrderInfo mainOrderInfo = initialMainOrderInfo(orderInfo); element.setMainOrderInfo(mainOrderInfo); // 2. 封装推荐的延保信息 List< RecommendYbInfo > recommendYbInfo = initialRecommendYbInfo(ybList); element.setRecommendYbInfoList(recommendYbInfo); res.add(element); } return res; } // 封装订单信息作为私有方法,被各个不同的策略复用 private MainOrderInfo initialMainOrderInfo(OrderInfo orderInfo) { // ... } // 抽象初始化推荐延保的方法,用于子类实现不同的策略 protected abstract List< RecommendYbInfo > initialRecommendYbInfo(List< T > ybList); }
类关系图如下:
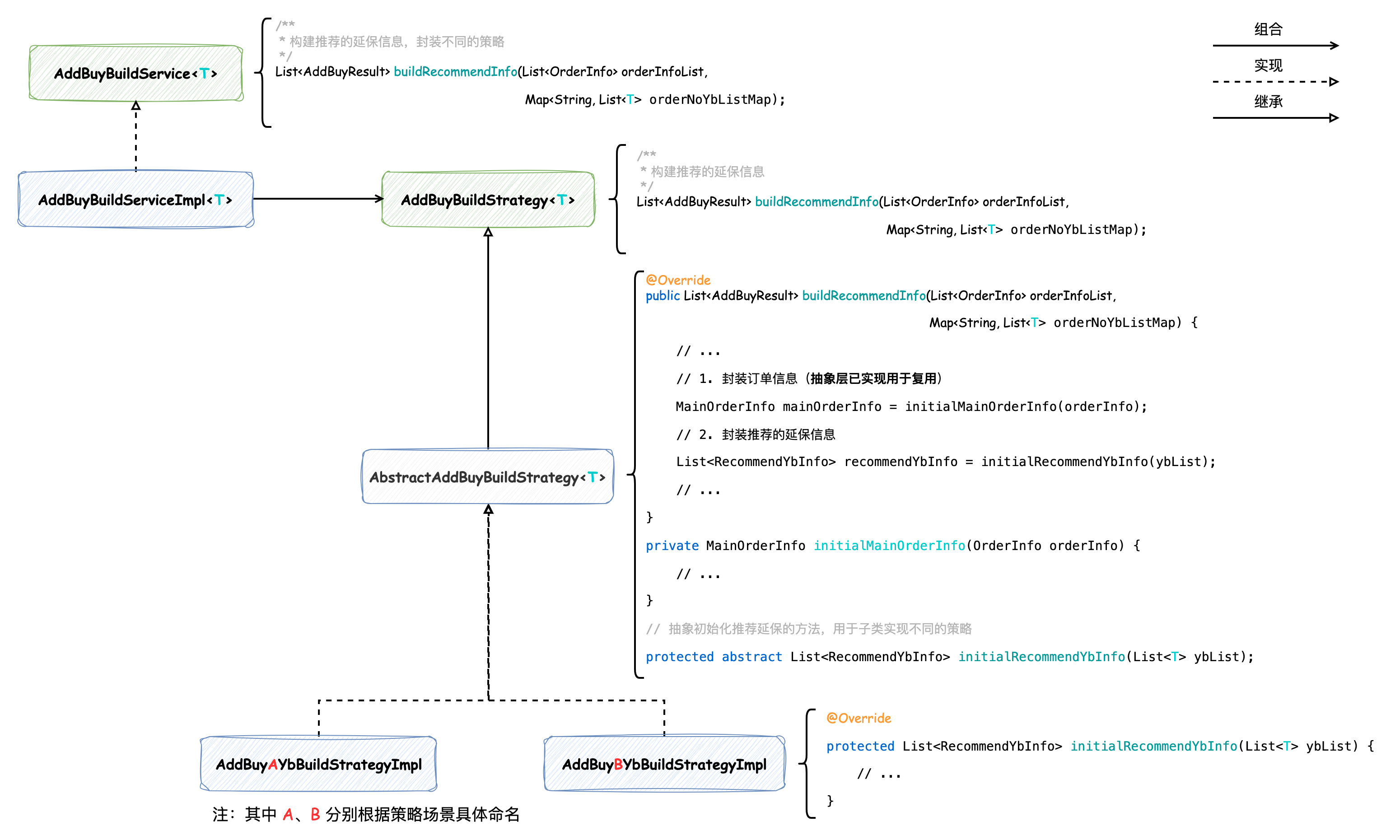
这样便能实现通用逻辑的复用。使用模板方法模式并不复杂,实现这种模式需要借助继承(extends),而继承在设计原则中被强调“少用继承,多用组合”,而且在一些软件设计相关的书中也会经常看到对继承的诟病,比如在《程序员修炼之道》中便将其称为“继承税”,并且举了一个非常好玩的例子:
你想要一根香蕉,但得到的却是一只拿着香蕉的大猩猩,甚至还有整个森林
其表达的意思也不难理解:强调继承使父类中的大量信息发生泄露,让维护在每个类中的知识在继承关系之间 “波动”,暴露了太多的知识出来,做不到抽象和信息隐藏。一方面会使子类获得太多无关的知识,另一方面如果在子类中大量使用这些通用的部分,便会使得耦合加深,父类中信息变更可能为子类带来意想不到的后果。
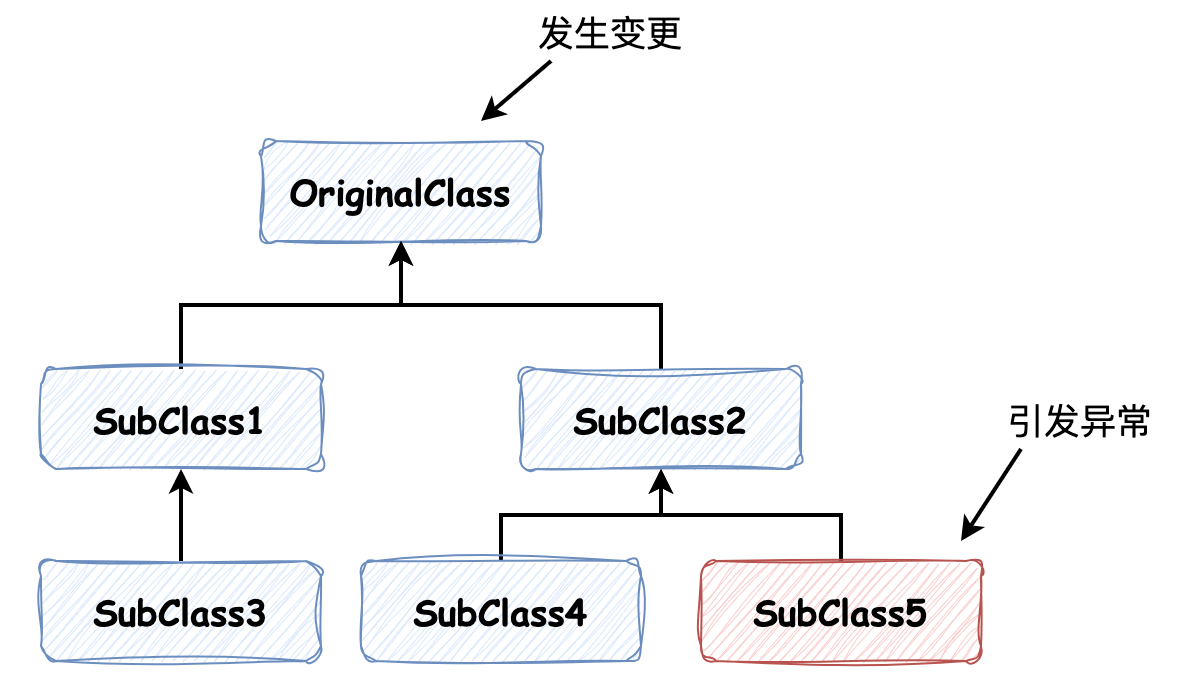
以如上继承关系为例,如果父类中某些内容发生变更,子类中对其使用的话,那么可能会引起子类行为的改变,而如果这种改变并不引起编译期异常的话,便很难发现,使得代码的可维护性大大降低。那么不用继承该怎么办呢?常见的观点有两个:
使用接口实现来代替类的继承,保证多态又不会造成信息的紧耦合
使用组合代替继承:比如想要香蕉,那么直接将包含香蕉的类注入进来,不再通过继承去获取了
但是,我觉得继承也并不能被一票否决,在 Java 源码中常用容器的实现里,都是有抽象层的(AbstractList, AbstractMap 等等),通过继承它们,实现了大量代码复用,为各种不同容器的实现提供了很多方便之处。所以,我觉得继承能被应用需要具备以下前提条件:
保持不变性:父类中抽象出来的供复用的通用方法、字段保持不变
控制继承树的高度:继承树高度越高引入的复杂度越大,所以需要控制树高,限制一层继承关系,那么复杂度便可控
总结
我觉得软件设计更应该站在代码阅读者的角度上,考虑如何降低复杂度,设计更深的模块,并随着功能迭代,不断更新现有设计,而并不是将注意力放在如何改动更简单上,代码的堆叠可能会导致复杂性不断累积,以至于在不能满足业务功能迭代时,花更多的时间去重构。
审核编辑 黄宇
-
软件设计
+关注
关注
3文章
58浏览量
17771 -
代码
+关注
关注
30文章
4788浏览量
68601
发布评论请先 登录
相关推荐
HarmonyOS应用点击完成时延问题定位流程及原理
【软件干货】Android应用进程如何保活?

基于FPA的软件工作量综合评估研究与实践

「重构:改善既有代码的设计」实战篇
TLV3201电流检测电路的时延应该怎么算?
软件设计哲学:新“代码整洁之道”
该如何提高代码容错率、降低代码耦合度?






 工商网监
工商网监
评论